Kubernetes 二进制部署
目录
服务器配置
部署 etcd 集群
准备签发证书环境
部署 docker引擎
flannel网络配置
K8S中Pod网络通信
Overlay Network
VXLAN
Flannel简介
Flannel工作原理
ETCD之Flannel提供说明
Flannel部署
在master01节点上操作
在所有node节点上操作(以node01为例)
修改docker0网卡网段与flannel一致
部署master组件(在master01节点上操作)
编写apiserver.sh/scheduler.sh/controller-manager.sh
apiserver.sh
编写scheduler.sh
编写controller-manager.sh
编写k8s-cert.sh
赋予以上脚本执行权限
创建kubernetes工作目录
生成CA证书、相关组件的证书和私钥
复制CA证书、apiserver相关证书和私钥到kubernetes工作目录的ssl子目录中
下载或上传kubernetes安装包到/opt/k8s目录,并解压
复制master组件的关键命令文件到kubernetes工作目录的bin子目录中
创建bootstrap token认证文件
二进制文件、token、证书都准备好后,开启apiserver服务
检查
检查进程是否启动成功
检查6443端口
检查8080端口
查看版本信息
启动scheduler服务
启动controller-manager服务
查看master节点状态
部署 Worker Node 组件
部署 CNI 网络组件
部署 Calico
部署 CoreDNS

| 服务器 | 主机名 | IP地址 | 主要组件/说明 |
|---|---|---|---|
| master01节点+etcd01节点 | master01 | 192.168.142.21 | kube-apiserver kube-controller-manager kube-schedular etcd |
| node01节点+etcd02节点 | node01 | 192.168.142.22 | kubelet kube-proxy docker flannel |
| node02节点+etcd03节点 | node01 | 192.168.142.23 | kubelet kube-proxy docker flannel |
服务器配置
#关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
iptables -F && iptables -t nat -F && iptables -t mangle -F && iptables -X
#关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
#关闭swap
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
#根据规划设置主机名
hostnamectl set-hostname master01
hostnamectl set-hostname node01
hostnamectl set-hostname node02
#在master添加hosts
cat >> /etc/hosts << EOF
192.168.142.21 master01
192.168.142.22 node01
192.168.142.23 node02
EOF
#调整内核参数
cat > /etc/sysctl.d/k8s.conf << EOF
#开启网桥模式,可将网桥的流量传递给iptables链
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
#关闭ipv6协议
net.ipv6.conf.all.disable_ipv6=1
net.ipv4.ip_forward=1
EOF
sysctl --system
#时间同步
yum install ntpdate -y
ntpdate ntp.aliyun.com部署 etcd 集群
etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd是go语言编写的。
etcd 作为服务发现系统,有以下的特点:
简单:安装配置简单,而且提供了HTTP API进行交互,使用也很简单
安全:支持SSL证书验证
快速:单实例支持每秒2k+读操作
可靠:采用raft算法,实现分布式系统数据的可用性和一致性
etcd 目前默认使用2379端口提供HTTP API服务, 2380端口和peer通信(这两个端口已经被IANA(互联网数字分配机构)官方预留给etcd)。 即etcd默认使用2379端口对外为客户端提供通讯,使用端口2380来进行服务器间内部通讯。
etcd 在生产环境中一般推荐集群方式部署。由于etcd 的leader选举机制,要求至少为3台或以上的奇数台。
准备签发证书环境
CFSSL 是 CloudFlare 公司开源的一款 PKI/TLS 工具。 CFSSL 包含一个命令行工具和一个用于签名、验证和捆绑 TLS 证书的 HTTP API 服务。使用Go语言编写。
CFSSL 使用配置文件生成证书,因此自签之前,需要生成它识别的 json 格式的配置文件,CFSSL 提供了方便的命令行生成配置文件。
CFSSL 用来为 etcd 提供 TLS 证书,它支持签三种类型的证书:
1、client 证书,服务端连接客户端时携带的证书,用于客户端验证服务端身份,如 kube-apiserver 访问 etcd;
2、server 证书,客户端连接服务端时携带的证书,用于服务端验证客户端身份,如 etcd 对外提供服务;
3、peer 证书,相互之间连接时使用的证书,如 etcd 节点之间进行验证和通信。
这里全部都使用同一套证书认证。
在 master01 节点上操作
#准备cfssl证书生成工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -O /usr/local/bin/cfssl
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -O /usr/local/bin/cfssljson
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -O /usr/local/bin/cfssl-certinfo
chmod +x /usr/local/bin/cfssl*
------------------------------------------------------------------------------------------
cfssl:证书签发的工具命令
cfssljson:将 cfssl 生成的证书(json格式)变为文件承载式证书
cfssl-certinfo:验证证书的信息
cfssl-certinfo -cert <证书名称> #查看证书的信息
或使用curl -L下载
curl -L https://pkg.cfssl.org/R1.2/cfssl_linux-amd64 -o /usr/local/bin/cfssl
curl -L https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64 -o /usr/local/bin/cfssljson
curl -L https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64 -o /usr/local/bin/cfssl-certinfo
etcd-cert.sh
### 生成Etcd证书 ###
mkdir /opt/k8s
cd /opt/k8s/
#上传 etcd-cert.sh 和 etcd.sh 到 /opt/k8s/ 目录中
(修改 etcd-cert.sh 里的ip地址)
chmod +x etcd-cert.sh etcd.sh
[root@master01 k8s]# cat etcd-cert.sh
#!/bin/bash
#配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书
cat > ca-config.json <#生成CA证书和私钥(根证书和私钥)
#特别说明: cfssl和openssl有一些区别,openssl需要先生成私钥,然后用私钥生成请求文件,最后生成签名的证书和私钥等,但是cfssl可以直接得到请求文件。
cat > ca-csr.json <:使用 CSRJSON 文件生成生成新的证书和私钥。如果不添加管道符号,会直接把所有证书内容输出到屏幕。
#注意:CSRJSON 文件用的是相对路径,所以 cfssl 的时候需要 csr 文件的路径下执行,也可以指定为绝对路径。
#cfssljson 将 cfssl 生成的证书(json格式)变为文件承载式证书,-bare 用于命名生成的证书文件。
#-----------------------
#生成 etcd 服务器证书和私钥
cat > server-csr.json < etcd.sh
[root@master01 k8s]# chmod +x etcd.sh
[root@master01 k8s]# cat etcd.sh
#!/bin/bash
# example: ./etcd.sh etcd01 192.168.142.21 etcd02=https://192.168.142.22:2380,etcd03=https://192.168.142.23:2380
#创建etcd配置文件/opt/etcd/cfg/etcd
ETCD_NAME=$1
ETCD_IP=$2
ETCD_CLUSTER=$3
WORK_DIR=/opt/etcd
cat > $WORK_DIR/cfg/etcd < /usr/lib/systemd/system/etcd.service < [root@master01 k8s]# mkdir /opt/k8s/etcd-cert
[root@master01 k8s]# mv etcd-cert.sh etcd-cert/
[root@master01 k8s]# cd /opt/k8s/etcd-cert/
[root@master01 etcd-cert]# ./etcd-cert.sh
#生成CA证书、etcd服务器证书以及私钥
[root@master01 etcd-cert]# ls
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem etcd-cert.sh server.csr server-csr.json server-key.pem server.pem
etcd二进制包地址:Releases · etcd-io/etcd · GitHub
#上传 etcd-v3.4.26-linux-amd64.tar.gz 到 /opt/k8s 目录中,启动etcd服务
cd /opt/k8s/
tar zxvf etcd-v3.4.26-linux-amd64.tar.gz
ls etcd-v3.4.26-linux-amd64
Documentation etcd etcdctl README-etcdctl.md README.md READMEv2-etcdctl.md
------------------------------------------------------------------------------------------
etcd就是etcd 服务的启动命令,后面可跟各种启动参数
etcdctl主要为etcd 服务提供了命令行操作
#创建用于存放 etcd 配置文件,命令文件,证书的目录
mkdir -p /opt/etcd/{cfg,bin,ssl}
cd /opt/k8s/etcd-v3.4.9-linux-amd64/
mv etcd etcdctl /opt/etcd/bin/
cp /opt/k8s/etcd-cert/*.pem /opt/etcd/ssl/
cd /opt/k8s/
#启动etcd.sh脚本
./etcd.sh etcd01 192.168.142.21 etcd02=https://192.168.142.22:2380,etcd03=https://192.168.142.23:2380
#进入卡住状态等待其他节点加入,这里需要三台etcd服务同时启动,如果只启动其中一台后,服务会卡在那里,直到集群中所有etcd节点都已启动,可忽略这个情况
#可另外打开一个窗口查看etcd进程是否正常
ps -ef | grep etcd#把etcd相关证书文件、命令文件和服务管理文件全部拷贝到另外两个etcd集群节点
scp -r /opt/etcd/ [email protected]:/opt/
scp -r /opt/etcd/ [email protected]:/opt/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service [email protected]:/usr/lib/systemd/system///在 node01 节点上操作
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd02" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.142.22:2380" #修改
ETCD_LISTEN_CLIENT_URLS="https://192.168.142.22:2379" #修改
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.142.22:2380" #修改
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.142.22:2379" #修改
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.142.21:2380,etcd02=https://192.168.142.22:2380,etcd03=https://192.168.142.23:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#启动etcd服务
systemctl start etcd
systemctl enable etcd
systemctl status etcd//在 node02 节点上操作
vim /opt/etcd/cfg/etcd
#[Member]
ETCD_NAME="etcd03" #修改
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.142.23:2380" #修改
ETCD_LISTEN_CLIENT_URLS="https://192.168.142.23:2379" #修改
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.142.23:2380" #修改
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.142.23:2379" #修改
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.142.21:2380,etcd02=https://192.168.142.22:2380,etcd03=https://192.168.142.23:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#启动etcd服务
systemctl start etcd
systemctl enable etcd
systemctl status etcd#查看etcd集群成员列表
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379" --write-out=table member list
--cert-file:识别HTTPS端使用SSL证书文件
--key-file:使用此SSL密钥文件标识HTTPS客户端
--ca-file:使用此CA证书验证启用https的服务器的证书
--endpoints:集群中以逗号分隔的机器地址列表
cluster-health:检查etcd集群的运行状况部署 docker引擎
//所有 node 节点部署docker引擎
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io
systemctl start docker.service
systemctl enable docker.service flannel网络配置
K8S中Pod网络通信

● Pod内容器与容器之间的通信
在同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命令空间,相当于它们在同一台机器上一样,可以用localhost地址访问彼此的端口。
● 同一个Node内Pod之间的通信
每个Pod都有一个真实的全局IP地址,同一个Node内的不同Pod之间可以直接采用对方Pod的IP地址进行通信,Pod1与Pod2都是通过Veth连接到同一个docker0网桥,网段相同,所以它们之间可以直接通信。
● 不同Node上Pod之间的通信
Pod地址与docker0在同一网段,docker0网段与宿主机网卡是两个不同的网段,且不同Node之间的通信只能通过宿主机的物理网卡进行。
要想实现不同Node上Pod之间的通信,就必须想办法通过主机的物理网卡IP地址进行寻址和通信。因此要满足两个条件:Pod的IP不能冲突,将Pod的IP和所在的Node的IP关联起来,通过这个关联让不同Node上Pod之间直接通过内网IP地址通信。
Overlay Network
叠加网络,在二层或者三层几乎网络上叠加的一种虚拟网络技术模式,该网络中的主机通过虚拟链路隧道连接起来(类似于VPN)。
VXLAN
将源数据包封装到UDP中,并使用基础网络的IP/MAC作为外层报文头进行封装,然后在以太网上传输,到达目的地后由隧道端点解封装并将数据发送给目标地址。
Flannel简介
Flannel的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
Flannel是Overlay网络的一种,也是将TCP源数据包封装在另一种网络包里面进行路由转发和通信,目前支持UDP、VXLAN、host-GW三种数据转发方式。
Flannel工作原理
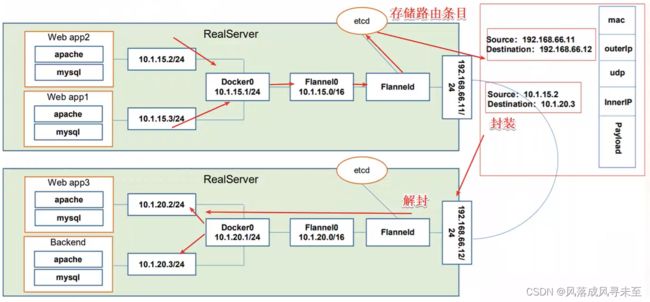
数据从node01上Pod的源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel.1虚拟网卡,flanneld服务监听在flanne.1数据网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表。源主机node01的flanneld服务将原本的数据内容封装到UDP中后根据自己的路由表通过物理网卡投递给目的节点node02的flanneld服务,数据到达以后被解包,然后直接进入目的节点的dlannel.1虚拟网卡,之后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一样由docker0转发到目标容器。
ETCD之Flannel提供说明
存储管理Flannel可分配的IP地址段资源
监控ETCD中每个Pod的实际地址,并在内存中建立维护Pod节点路由表
Flannel部署
在master01节点上操作
添加flannel网络配置信息,写入分配的子网段到etcd中,供flannel使用
[root@master01 ~]# cd /opt/etcd/ssl
[root@master01 ssl]# etcdctl \
> --ca-file=ca.pem \
> --cert-file=server.pem \
> --key-file=server-key.pem \
> --endpoint="https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379" \
> set /coreos.com/network/config '{"Network":"172.17.0.0/16","Backend":{"Type":"vxlan"}}'
查看写入的信息
[root@master01 ssl]# etcdctl \
> --ca-file=ca.pem \
> --cert-file=server.pem \
> --key-file=server-key.pem \
> --endpoint="https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379" \
> get /coreos.com/network/config
{"Network":"172.17.0.0/16","Backend":{"Type":"vxlan"}}
set :给键赋值
set /coreos.com/network/config:添加一条网络配置记录,这个配置将用于flannel分配给每个docker的虚拟IP地址段
get :获取网络配置记录,后面不用再跟参数
Network:用于指定Flannel地址池
Backend:用于指定数据包以什么方式转发,默认为udp模式,Backend为vxlan比起预设的udp性能相对好一些。
在所有node节点上操作(以node01为例)
安装flannel
[root@node01 ~]# cd /opt
[root@node01 opt]# rz -E
#上传flannel安装包flannel-v.0.10.0-linux-amd64.tar.gz到/opt目录中
rz waiting to receive.
flanneld
#flanneld为主要的执行文件
mk-docker-opts.sh
#mk-docker-opts.sh脚本用于生成Docker启动参数
README.md
编写flannel.sh脚本
[root@node01 opt]# cat flannel.sh
#!/bin/bash
#定义etcd集群的端点IP地址和对外提供服务的2379端口
#${var:-string}:若变量var为空,则用在命令行中用string来替换;否则变量var不为空时,则用变量var的值来替换,这里的1代表的是位置变量$1
ETCD_ENDPOINTS=${1:-"http://127.0.0.1:2379"}
#创建flanneld配置文件
cat > /opt/kubernetes/cfg/flanneld < /usr/lib/systemd/system/flanneld.service < 创建kubenetes工作目录
[root@node01 opt]# mkdir -p /opt/kubernetes/{cfg,bin,ssl}
[root@node01 opt]# cd /opt
[root@node01 opt]# mv mk-docker-opts.sh flanneld /opt/kubernetes/bin/
启动flannel服务,开启flannel网络功能
[root@node01 opt]# chmod +x flannel.sh
[root@node01 opt]# ./flannel.sh https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379
[root@node01 opt]# systemctl status flanneld.service
● flanneld.service - Flanneld overlay address etcd agent
Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled)
Active: active (running) since 三 2021-10-27 19:38:31 CST; 10s ago
......
//flannel启动后会生成一个docker网络相关信息配置文件/run/flannel/subnet.env,包含了docker要使用flannel通讯的相关参数修改docker0网卡网段与flannel一致
添加docker环境变量
[root@node01 opt]# vim /lib/systemd/system/docker.service
#13行,插入环境文件
EnvironmentFile=/run/flannel/subnet.env
#14行,添加变量$DOCKER_NETWORK_OPTIONS
ExecStart=/usr/bin/dockerd $DOCKER_NETWORK_OPTIONS -H fd:// --containerd=/run/containerd/containerd.sock
[root@node01 opt]# systemctl daemon-reload
[root@node01 opt]# systemctl restart docker
部署master组件(在master01节点上操作)
编写apiserver.sh/scheduler.sh/controller-manager.sh
apiserver.sh
[root@master01 ~]# cd /opt/k8s
[root@master01 k8s]# cat apiserver.sh
#!/bin/bash
#example: apiserver.sh 192.168.142.21 https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379
#创建 kube-apiserver 启动参数配置文件
MASTER_ADDRESS=$1
ETCD_SERVERS=$2
cat >/opt/kubernetes/cfg/kube-apiserver </usr/lib/systemd/system/kube-apiserver.service < 编写scheduler.sh
[root@master01 k8s]# cat scheduler.sh
#!/bin/bash
#创建 kube-scheduler 启动参数配置文件
MASTER_ADDRESS=$1
cat >/opt/kubernetes/cfg/kube-scheduler </usr/lib/systemd/system/kube-scheduler.service < 编写controller-manager.sh
[root@master01 k8s]# cat controller-manager.sh
#!/bin/bash
#创建 kube-controller-manager 启动参数配置文件
MASTER_ADDRESS=$1
cat >/opt/kubernetes/cfg/kube-controller-manager </usr/lib/systemd/system/kube-controller-manager.service < 编写k8s-cert.sh
[root@master01 k8s]# cat k8s-cert.sh
#!/bin/bash
#配置证书生成策略,让 CA 软件知道颁发有什么功能的证书,生成用来签发其他组件证书的根证书
cat > ca-config.json < ca-csr.json < apiserver-csr.json < admin-csr.json < kube-proxy-csr.json < 赋予以上脚本执行权限
[root@master01 k8s]# chmod +x *.sh
创建kubernetes工作目录
[root@master01 k8s]# mkdir -p /opt/kubernetes/{cfg,bin,ssl}
生成CA证书、相关组件的证书和私钥
[root@master01 k8s]# mkdir /opt/k8s/k8s-cert
[root@master01 k8s]# mv /opt/k8s/k8s-cert.sh /opt/k8s/k8s-cert
[root@master01 k8s]# cd !$
cd /opt/k8s/k8s-cert
[root@master01 k8s-cert]# ./k8s-cert.sh
#生成CA证书、相关组件的证书和私钥
[root@master01 k8s-cert]# ls
admin.csr admin.pem apiserver-key.pem ca.csr ca.pem kube-proxy-csr.json
admin-csr.json apiserver.csr apiserver.pem ca-csr.json k8s-cert.sh kube-proxy-key.pem
admin-key.pem apiserver-csr.json ca-config.json ca-key.pem kube-proxy.csr kube-proxy.pem
//controller-manager和kube-scheduler设置为只调用当前机器的apiserver,使用127.0.0.1:8080通信,因此不需要签发证书
复制CA证书、apiserver相关证书和私钥到kubernetes工作目录的ssl子目录中
[root@master01 k8s-cert]# ls *.pem
admin-key.pem admin.pem apiserver-key.pem apiserver.pem ca-key.pem ca.pem kube-proxy-key.pem kube-proxy.pem
[root@master01 k8s-cert]# cp ca*pem apiserver*pem /opt/kubernetes/ssl/
下载或上传kubernetes安装包到/opt/k8s目录,并解压
[root@master01 k8s-cert]# cd /opt/k8s/
[root@master01 k8s]# rz -E
#上传k8s安装包kubernetes-server-linux-amd64.tar.gz
rz waiting to receive.
[root@master01 k8s]# tar zxvf kubernetes-server-linux-amd64.tar.gz
复制master组件的关键命令文件到kubernetes工作目录的bin子目录中
[root@master01 k8s]# cd /opt/k8s/kubernetes/server/bin/
[root@master01 bin]# ls
apiextensions-apiserver kubeadm kube-controller-manager.docker_tag kube-proxy.docker_tag mounter
cloud-controller-manager kube-apiserver kube-controller-manager.tar kube-proxy.tar
cloud-controller-manager.docker_tag kube-apiserver.docker_tag kubectl kube-scheduler
cloud-controller-manager.tar kube-apiserver.tar kubelet kube-scheduler.docker_tag
hyperkube kube-controller-manager kube-proxy kube-scheduler.tar
[root@master01 bin]# cp kube-apiserver kubectl kube-controller-manager kube-scheduler /opt/kubernetes/bin/
[root@master01 bin]# ln -s /opt/kubernetes/bin/* /usr/local/bin/
创建bootstrap token认证文件
apiserver启动时会调用,然后就相当于在集群内创建了一个这个用户,接下来就可以用RBAC给他授权
[root@master01 bin]# cd /opt/k8s/
[root@master01 k8s]# vim token.sh
#!/bin/bash
#获取随机数前16个字节内容,以十六进制格式输出,并删除其中空格
BOOTSTRAP_TOKEN=$(head -c 16 /dev/urandom | od -An -t x | tr -d ' ')
#生成token.csv文件,按照Token序列号,用户名,UID,用户组的格式生成
cat > /opt/kubernetes/cfg/token.csv <二进制文件、token、证书都准备好后,开启apiserver服务
[root@master01 k8s]# cd /opt/k8s/
[root@master01 k8s]# ./apiserver.sh 192.168.142.21 https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-apiserver.service to /usr/lib/systemd/system/kube-apiserver.service.
检查
检查进程是否启动成功
[root@master01 k8s]# ps aux | grep kube-apiserver
root 3667 12.1 15.6 405152 318232 ? Ssl 15:08 0:06 /opt/kubernetes/bin/kube-apiserver --logtostderr=true --v=4 --etcd-servers=https://192.168.142.21:2379,https://192.168.142.22:2379,https://192.168.142.23:2379 --bind-address=192.168.142.21 --secure-port=6443 --advertise-address=192.168.142.21 --allow-privileged=true --service-cluster-ip-range=10.0.0.0/24 --enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction --authorization-mode=RBAC,Node --kubelet-https=true --enable-bootstrap-token-auth --token-auth-file=/opt/kubernetes/cfg/token.csv --service-node-port-range=30000-50000 --tls-cert-file=/opt/kubernetes/ssl/apiserver.pem --tls-private-key-file=/opt/kubernetes/ssl/apiserver-key.pem --client-ca-file=/opt/kubernetes/ssl/ca.pem --service-account-key-file=/opt/kubernetes/ssl/ca-key.pem --etcd-cafile=/opt/etcd/ssl/ca.pem --etcd-certfile=/opt/etcd/ssl/server.pem --etcd-keyfile=/opt/etcd/ssl/server-key.pem
root 3686 0.0 0.0 112676 984 pts/0 S+ 15:09 0:00 grep --color=auto kube-apiserver
k8s通过kube-apiserver这个进程提供服务,该进程运行在单个master节点上。默认有两个端口6443和8080(新版本为58080)
检查6443端口
安全端口6443用于接收HTTPS请求,用于基于Token文件或客户端证书等认证
[root@master01 k8s]# netstat -natp | grep 6443
tcp 0 0 192.168.142.21:6443 0.0.0.0:* LISTEN 3667/kube-apiserver
tcp 0 0 192.168.142.21:6443 192.168.142.21:50550 ESTABLISHED 3667/kube-apiserver
tcp 0 0 192.168.142.21:50550 192.168.142.21:6443 ESTABLISHED 3667/kube-apiserver
检查8080端口
本地端口8080用于接收HTTP请求,非认证或授权的HTTP请求通过该端口访问API Server
[root@master01 k8s]# netstat -natp | grep 8080
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 3667/kube-apiserver
查看版本信息
必须保证apiserver启动正常,不然无法查询到server的版本信息
[root@master01 k8s]# kubectl version
启动scheduler服务
[root@master01 k8s]# ./scheduler.sh 127.0.0.1
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-scheduler.service to /usr/lib/systemd/system/kube-scheduler.service.
[root@master01 k8s]# ps aux | grep kube-schesuler
root 3942 0.0 0.0 112676 980 pts/0 R+ 15:22 0:00 grep --color=auto kube-schesuler
[root@master01 k8s]# ps aux | grep kube-scheduler
root 3920 0.4 1.0 45616 20704 ? Ssl 15:22 0:00 /opt/kubernetes/bin/kube-scheduler --logtostderr=true --v=4 --master=127.0.0.1:8080 --leader-elect=true
root 3944 0.0 0.0 112676 984 pts/0 S+ 15:23 0:00 grep --color=auto kube-scheduler
启动controller-manager服务
[root@master01 k8s]# ./controller-manager.sh 127.0.0.1
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-controller-manager.service to /usr/lib/systemd/system/kube-controller-manager.service.
[root@master01 k8s]# ps aux | grep controller-manager
root 4029 1.0 3.1 142844 64964 ? Ssl 15:24 0:01 /opt/kubernetes/bin/kube-controller-manager --logtostderr=true --v=4 --master=127.0.0.1:8080 --leader-elect=true --address=127.0.0.1 --service-cluster-ip-range=10.0.0.0/24 --cluster-name=kubernetes --cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem --cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem --root-ca-file=/opt/kubernetes/ssl/ca.pem --service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem --experimental-cluster-signing-duration=87600h0m0s
root 4060 0.0 0.0 112676 980 pts/0 S+ 15:26 0:00 grep --color=auto controller-manager
查看master节点状态
[root@master01 k8s]# kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
部署 Worker Node 组件
//在所有 node 节点上操作
#创建kubernetes工作目录
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#上传 node.zip 到 /opt 目录中,解压 node.zip 压缩包,获得kubelet.sh、proxy.sh
cd /opt/
unzip node.zip
chmod +x kubelet.sh proxy.sh
//在 master01 节点上操作
#把 kubelet、kube-proxy 拷贝到 node 节点
cd /opt/k8s/kubernetes/server/bin
scp kubelet kube-proxy [email protected]:/opt/kubernetes/bin/
scp kubelet kube-proxy [email protected]:/opt/kubernetes/bin/
#上传kubeconfig.sh文件到/opt/k8s/kubeconfig目录中,生成kubelet初次加入集群引导kubeconfig文件和kube-proxy.kubeconfig文件
#kubeconfig 文件包含集群参数(CA 证书、API Server 地址),客户端参数(上面生成的证书和私钥),集群 context 上下文参数(集群名称、用户名)。Kubenetes 组件(如 kubelet、kube-proxy)通过启动时指定不同的 kubeconfig 文件可以切换到不同的集群,连接到 apiserver。
mkdir /opt/k8s/kubeconfig
cd /opt/k8s/kubeconfig
chmod +x kubeconfig.sh
./kubeconfig.sh 192.168.142.21 /opt/k8s/k8s-cert/
#把配置文件 bootstrap.kubeconfig、kube-proxy.kubeconfig 拷贝到 node 节点
scp bootstrap.kubeconfig kube-proxy.kubeconfig [email protected]:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig kube-proxy.kubeconfig [email protected]:/opt/kubernetes/cfg/
#RBAC授权,使用户 kubelet-bootstrap 能够有权限发起 CSR 请求证书
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
#自动批准 CSR 请求
kubectl create clusterrolebinding node-autoapprove-bootstrap --clusterrole=system:certificates.k8s.io:certificatesigningrequests:nodeclient --user=kubelet-bootstrap
kubectl create clusterrolebinding node-autoapprove-certificate-rotation --clusterrole=system:certificates.k8s.io:certificatesigningrequests:selfnodeclient
kubelet 采用 TLS Bootstrapping 机制,自动完成到 kube-apiserver 的注册,在 node 节点量较大或者后期自动扩容时非常有用。
Master apiserver 启用 TLS 认证后,node 节点 kubelet 组件想要加入集群,必须使用CA签发的有效证书才能与 apiserver 通信,当 node 节点很多时,签署证书是一件很繁琐的事情。因此 Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书,kubelet 会以一个低权限用户自动向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署。
kubelet 首次启动通过加载 bootstrap.kubeconfig 中的用户 Token 和 apiserver CA 证书发起首次 CSR 请求,这个 Token 被预先内置在 apiserver 节点的 token.csv 中,其身份为 kubelet-bootstrap 用户和 system:kubelet-bootstrap 用户组;想要首次 CSR 请求能成功(即不会被 apiserver 401 拒绝),则需要先创建一个 ClusterRoleBinding,将 kubelet-bootstrap 用户和 system:node-bootstrapper 内置 ClusterRole 绑定(通过 kubectl get clusterroles 可查询),使其能够发起 CSR 认证请求。
TLS bootstrapping 时的证书实际是由 kube-controller-manager 组件来签署的,也就是说证书有效期是 kube-controller-manager 组件控制的;kube-controller-manager 组件提供了一个 --experimental-cluster-signing-duration 参数来设置签署的证书有效时间;默认为 8760h0m0s,将其改为 87600h0m0s,即 10 年后再进行 TLS bootstrapping 签署证书即可。
也就是说 kubelet 首次访问 API Server 时,是使用 token 做认证,通过后,Controller Manager 会为 kubelet 生成一个证书,以后的访问都是用证书做认证了。
//在 node01 节点上操作
#启动 kubelet 服务
cd /opt/
./kubelet.sh 192.168.142.22
ps aux | grep kubelet
//在 master01 节点上操作,通过 CSR 请求
#检查到 node01 节点的 kubelet 发起的 CSR 请求,Pending 表示等待集群给该节点签发证书
kubectl get csr
#通过 CSR 请求
kubectl certificate approve node-csr-duiobEzQ0R93HsULoS9NT9JaQylMmid_nBF3Ei3NtFE
#Approved,Issued 表示已授权 CSR 请求并签发证书
kubectl get csr
#查看节点,由于网络插件还没有部署,节点会没有准备就绪 NotReady
kubectl get node
NAME STATUS ROLES AGE VERSION
192.168.142.22 NotReady 108s v1.20.11
//在 node01 节点上操作
#加载 ip_vs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#启动proxy服务
cd /opt/
./proxy.sh 192.168.142.22
ps aux | grep kube-proxy部署 CNI 网络组件
//在 node01 节点上操作
#上传 cni-plugins-linux-amd64-v0.8.6.tgz 和 flannel.tar 到 /opt 目录中
cd /opt/
docker load -i flannel.tar
mkdir /opt/cni/bin
tar zxvf cni-plugins-linux-amd64-v0.8.6.tgz -C /opt/cni/bin
//在 master01 节点上操作
#上传 kube-flannel.yml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
kubectl apply -f kube-flannel.yml
kubectl get pods -n kube-system
kubectl get pods -A部署 Calico
#k8s 组网方案对比:
●flannel方案
需要在每个节点上把发向容器的数据包进行封装后,再用隧道将封装后的数据包发送到运行着目标Pod的node节点上。目标node节点再负责去掉封装,将去除封装的数据包发送到目标Pod上。数据通信性能则大受影响。
●calico方案
Calico不使用隧道或NAT来实现转发,而是把Host当作Internet中的路由器,使用BGP同步路由,并使用iptables来做安全访问策略,完成跨Host转发来。
#Calico 主要由三个部分组成:
Calico CNI插件:主要负责与kubernetes对接,供kubelet调用使用。
Felix:负责维护宿主机上的路由规则、FIB转发信息库等。
BIRD:负责分发路由规则,类似路由器。
Confd:配置管理组件。
#Calico 工作原理:
Calico 是通过路由表来维护每个 pod 的通信。Calico 的 CNI 插件会为每个容器设置一个 veth pair 设备, 然后把另一端接入到宿主机网络空间,由于没有网桥,CNI 插件还需要在宿主机上为每个容器的 veth pair 设备配置一条路由规则,用于接收传入的IP包。
有了这样的 veth pair 设备以后,容器发出的IP包就会通过 veth pair 设备到达宿主机,然后宿主机根据路由规则的下一跳地址, 发送给正确的网关,然后到达目标宿主机,再到达目标容器。
这些路由规则都是 Felix 维护配置的,而路由信息则是 Calico BIRD 组件基于 BGP 分发而来。calico 实际上是将集群里所有的节点都当做边界路由器来处理,他们一起组成了一个全互联的网络,彼此之间通过 BGP 交换路由,这些节点我们叫做 BGP Peer。
目前比较常用的时flannel和calico,flannel的功能比较简单,不具备复杂的网络策略配置能力,calico是比较出色的网络管理插件,但具备复杂网络配置能力的同时,往往意味着本身的配置比较复杂,所以相对而言,比较小而简单的集群使用flannel,考虑到日后扩容,未来网络可能需要加入更多设备,配置更多网络策略,则使用calico更好。
//在 master01 节点上操作
#上传 calico.yaml 文件到 /opt/k8s 目录中,部署 CNI 网络
cd /opt/k8s
vim calico.yaml
#修改里面定义Pod网络(CALICO_IPV4POOL_CIDR),与前面kube-controller-manager配置文件指定的cluster-cidr网段一样
- name: CALICO_IPV4POOL_CIDR
value: "192.168.0.0/16"
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-659bd7879c-4h8vk 1/1 Running 0 58s
calico-node-nsm6b 1/1 Running 0 58s
calico-node-tdt8v 1/1 Running 0 58s
#等 Calico Pod 都 Running,节点也会准备就绪
kubectl get nodes
---------- node02 节点部署 ----------
//在 node01 节点上操作
cd /opt/
scp kubelet.sh proxy.sh [email protected]:/opt/
scp -r /opt/cni [email protected]:/opt/
//在 node02 节点上操作
#启动kubelet服务
cd /opt/
chmod +x kubelet.sh
./kubelet.sh 192.168.179.22
//在 master01 节点上操作
kubectl get csr
#通过 CSR 请求
kubectl certificate approve node-csr-BbqEh6LvhD4R6YdDUeEPthkb6T_CJDcpVsmdvnh81y0
kubectl get csr
#加载 ipvs 模块
for i in $(ls /usr/lib/modules/$(uname -r)/kernel/net/netfilter/ipvs|grep -o "^[^.]*");do echo $i; /sbin/modinfo -F filename $i >/dev/null 2>&1 && /sbin/modprobe $i;done
#使用proxy.sh脚本启动proxy服务
cd /opt/
chmod +x proxy.sh
./proxy.sh 192.168.179.23
#查看群集中的节点状态
kubectl get nodes
部署 CoreDNS
//在所有 node 节点上操作
#上传 coredns.tar 到 /opt 目录中
cd /opt
docker load -i coredns.tar
//在 master01 节点上操作
#上传 coredns.yaml 文件到 /opt/k8s 目录中,部署 CoreDNS
cd /opt/k8s
kubectl apply -f coredns.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-5ffbfd976d-j6shb 1/1 Running 0 32s
#DNS 解析测试
kubectl run -it --rm dns-test --image=busybox:1.28.4 sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local