MySQL
MySQL数据库
-
- 数据库概述
-
- 数据存储阶段
- 数据库应用
- 基础概念
- 数据库分类和常见数据库
- 认识关系型数据库和MySQL
- Windows安装MySQL
-
- 第1步:下载安装
- 第2步:解压至任意文件夹
- 第3步:创建配置文件
- 第4步:初始化
- 第5步:启动
- 第6步:测试连接MySQL
- SQL语句
- MySQL 数据库操作
-
- 数据库操作
- 数据表的管理
- 数据行操作
-
- - 新**增**数据
- - **删**除数据
- - 修**改**数据
- - **查**询数据
-
- where子句
- 扩展语句
-
- 排序
- 分页(限制)
- 通配符
- 分组
- having
- distinct
- 主键(primary key)
- auto_incrment
- 整型中括号中得数字的作用
- 外键
- 表与表之间的关系
-
- 一对一
- 一对多
- 一对多的表关系
-
-
-
-
- 多对多
- 多表联查
-
-
-
数据库概述
数据存储阶段
【1】 人工管理阶段
缺点 : 数据无法共享,不能单独保持,数据存储量有限
【2】 文件管理阶段 (.txt .doc .xls)
优点 : 数据可以长期保存,可以存储大量的数据,使用简单
缺点 : 数据一致性差,数据查找修改不方便,数据冗余度可能比较大
【3】数据库管理阶段
优点 : 数据组织结构化降低了冗余度,提高了增删改查的效率,容易扩展,方便程序调用,做自动化处理
缺点 :需要使用sql 或者 其他特定的语句,相对比较复杂
数据库应用
融机构、游戏网站、购物网站、论坛网站 … …
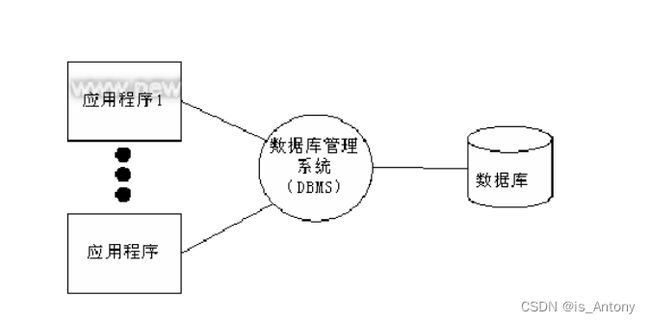
基础概念
数据 : 能够输入到计算机中并被识别处理的信息集合
数据结构 :研究一个数据集合中数据之间关系的
数据库 : 按照数据结构,存储管理数据的仓库。数据库是在数据库管理系统管理和控制下,在一定介质上的数据集合。
数据库管理系统 :管理数据库的软件,用于建立和维护数据库
数据库系统 : 由数据库和数据库管理系统,开发工具等组成的集合
数据库分类和常见数据库
- 关系型数据库和非关系型数据库
关系型: 采用关系模型(二维表)来组织数据结构的数据库
非关系型: 不采用关系模型组织数据结构的数据库
- 开源数据库和非开源数据库
开源:MySQL、SQLite、MongoDB
非开源:Oracle、DB2、SQL_Server
- 常见的关系型数据库
MySQL、Oracle、SQL_Server、DB2 SQLite
认识关系型数据库和MySQL
- 数据库结构 (图库结构)
数据元素 --> 记录 -->数据表 --> 数据库
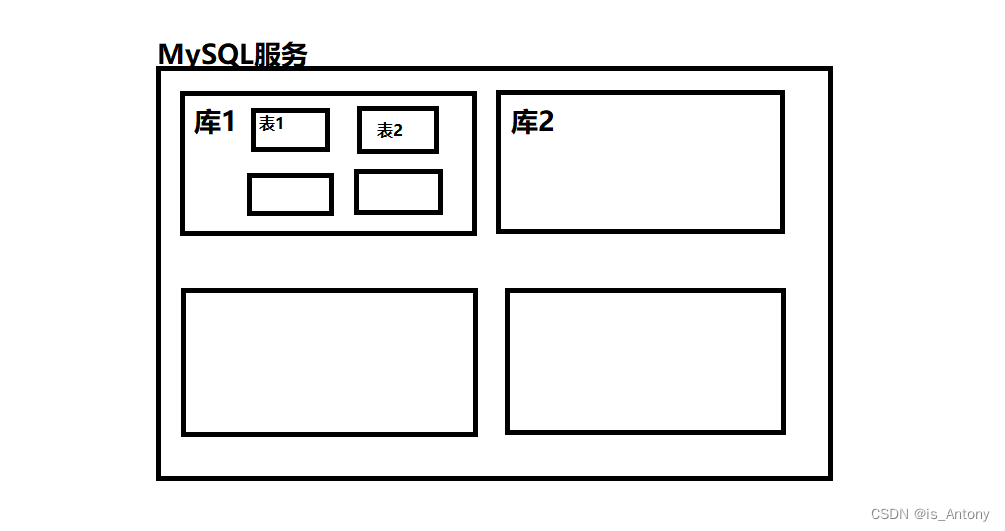
- 数据库概念解析
数据表 : 存放数据的表格
字段: 每个列,用来表示该列数据的含义
记录: 每个行,表示一组完整的数据

- MySQL特点
- 是开源数据库,使用C和C++编写
- 能够工作在众多不同的平台上
- 提供了用于C、C++、Python、Java、Perl、PHP、Ruby众多语言的API
- 存储结构优良,运行速度快
- 功能全面丰富
- MySQL安装
Ubuntu安装MySQL服务
安装服务端: sudo apt-get install mysql-server
安装客户端: sudo apt-get install mysql-client配置文件:/etc/mysql
命令集: /usr/bin
数据库存储目录 :/var/lib/mysql
Windows安装MySQL
第1步:下载安装
https://downloads.mysql.com/archives/community/

第2步:解压至任意文件夹
建议解压至软件安装目录,例如:

第3步:创建配置文件
在MySQL的安装目录下创建 my.ini 的文件,作为MySQL的配置文件。

其实,MySQL的配置文件可以放在很多的目录,下图是配置文件的优先级:

强烈,建议大家还是把配置文件放在MySQL安装目录下,这样以后电脑上想要安装多个版本的MySQL时,配置文件可以相互独立不影响。
注意:如果你电脑的上述其他目录存在MySQL配置文件,建议删除,否则可能会影响MySQL的启动。
第4步:初始化
>>> "C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe" --initialize-insecure
初始化命令在执行时,会自动读取配置文件并执行初始化,此过程主要会做两件事:
- 自动创建data目录,以后我们的数据都会存放在这个目录。
- 同时创建建必备一些的数据,例如默认账户 root (无密码),用于登录MySQL并通过指令操作MySQL。

在windowns安装过程中如果有报错 ( msvcr120.dll不存在 ),请下载并安装下面的两个补丁:
-
vcredist:https://www.microsoft.com/zh-cn/download/confirmation.aspx?id=40784 (主要)
-
dirctx:https://www.microsoft.com/zh-CN/download/details.aspx?id=35
第5步:启动
启动MySQL常见的有两种方式:
-
临时启动
>>> "C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe"
注意:此时程序会挂起,内部就是可以接收客户端发来的MySQL指令,关闭窗口或Ctrl+c 就可以停止运行。
这种启动方式每次开机或想要开启都需要手动执行一遍命令比较麻烦。
-
制作windows服务,基于windows服务管理。
>>>"C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe" --install mysql57
创建好服务之后,可以通过命令 启动和关闭服务,例如:
>>> net start mysql57 >>> net stop mysql57也可以在window的服务管理中点击按钮启动和关闭服务。例如:


在这里插入图片描述
以后不再想要使用window服务了,也可以将制作的这个MySQL服务删除。
>>>"C:\Program Files\mysql-5.7.31-winx64\bin\mysqld.exe" --remove mysql57
第6步:测试连接MySQL
安装并启动MySQL之后,就可以连接MySQL来测试是否已正确安装并启动成功。
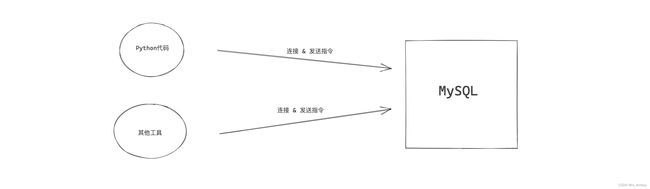
在安装MySQL时,其实也自动安装了一个工具(客户端),让我们快速实现连接MySQL并发送指令。

注意:如果把bin目录加入环境变量,每次在运行命令时,就不用再重新输入绝对路径了。

上述过程如果操作完成之后,证明你的安装和启动过程就搞定了。
- 启动和连接MySQL服务
服务端启动
查看MySQL状态: sudo /etc/init.d/mysql status
启动服务:sudo /etc/init.d/mysql start | stop | restart
客户端连接
命令格式
mysql -h主机地址 -u用户名 -p密码
mysql -hlocalhost -uroot -p123456
本地连接可省略 -h 选项: mysql -uroot -p123456
关闭连接
ctrl-D
exit
SQL语句
什么是SQL
结构化查询语言(Structured Query Language),一种特殊目的的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL语句使用特点
- SQL语言基本上独立于数据库本身
- 各种不同的数据库对SQL语言的支持与标准存在着细微的不同
- 每条命令必须以 ; 结尾
- SQL命令关键字不区分字母大小写
MySQL 数据库操作
数据库操作
1.查看已有库
show databases;
2.创建库(指定字符集)
create database 库名 [character set utf8];
e.g. 创建stu数据库,编码为utf8
create database stu character set utf8;
create database stu charset=utf8;
3.查看创建库的语句(字符集)
show create database 库名;
e.g. 查看stu创建方法
show create database stu;
4.查看当前所在库
select database();
5.切换库
use 库名;
e.g. 使用stu数据库
use stu;
6.删除库
drop database 库名;
e.g. 删除test数据库
drop database test;
7.库名的命名规则
- 数字、字母、下划线,但不能使用纯数字
- 库名区分字母大小写
- 不能使用特殊字符和mysql关键字
数据表的管理
-
表结构设计初步
【1】 分析存储内容
【2】 确定字段构成
【3】 设计字段类型 -
数据类型支持
数字类型:
整数类型(精确值) - INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT
定点类型(精确值) - DECIMAL
浮点类型(近似值) - FLOAT,DOUBLE
比特值类型 - BIT

对于精度比较高的东西,比如money,用decimal类型提高精度减少误差。列的声明语法是DECIMAL(M,D)。
M是数字的最大位数(精度)。其范围为1~65,M 的默认值是10。
D是小数点右侧数字的数目(标度)。其范围是0~30,但不得超过M。
比如 DECIMAL(6,2)最多存6位数字,小数点后占2位,取值范围-9999.99到9999.99。
比特值类型指0,1值表达2种情况,如真,假
-
int[(m)][unsigned][zerofill]int 表示有符号,取值范围:-2147483648 ~ 2147483647 int unsigned 表示无符号,取值范围:0 ~ 4294967295 int(5)zerofill 仅用于显示,当不满足5位时,按照左边补0,例如:00002;满足时,正常显示。mysql> create table L1(id int, uid int unsigned, zid int(5) zerofill) default charset=utf8; Query OK, 0 rows affected (0.03 sec) mysql> insert into L1(id,uid,zid) values(1,2,3); Query OK, 1 row affected (0.00 sec) mysql> insert into L1(id,uid,zid) values(2147483641,4294967294,300000); Query OK, 1 row affected (0.00 sec) mysql> select * from L1; +------------+------------+--------+ | id | uid | zid | +------------+------------+--------+ | 1 | 2 | 00003 | | 2147483641 | 4294967294 | 300000 | +------------+------------+--------+ 2 rows in set (0.00 sec) mysql> insert into L1(id,uid,zid) values(214748364100,4294967294,300000); ERROR 1264 (22003): Out of range value for column 'id' at row 1 mysql> -
tinyint[(m)] [unsigned] [zerofill]有符号,取值范围:-128 ~ 127. 无符号,取值范围:0 ~ 255 -
bigint[(m)][unsigned][zerofill]有符号,取值范围:-9223372036854775808 ~ 9223372036854775807 无符号,取值范围:0 ~ 18446744073709551615 -
decimal[(m[,d])] [unsigned] [zerofill]准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。 例如: create table L2( id int not null primary key auto_increment, salary decimal(8,2) )default charset=utf8;mysql> create table L2(id int not null primary key auto_increment,salary decimal(8,2))default charset=utf8; Query OK, 0 rows affected (0.03 sec) mysql> insert into L2(salary) values(1.28); Query OK, 1 row affected (0.01 sec) mysql> insert into L2(salary) values(5.289); Query OK, 1 row affected, 1 warning (0.00 sec) mysql> insert into L2(salary) values(5.282); Query OK, 1 row affected, 1 warning (0.00 sec) mysql> insert into L2(salary) values(512132.28); Query OK, 1 row affected (0.00 sec) mysql> insert into L2(salary) values(512132.283); Query OK, 1 row affected, 1 warning (0.00 sec) mysql> select * from L2; +----+-----------+ | id | salary | +----+-----------+ | 1 | 1.28 | | 2 | 5.29 | | 3 | 5.28 | | 4 | 512132.28 | | 5 | 512132.28 | +----+-----------+ 5 rows in set (0.00 sec) mysql> insert into L2(salary) values(5121321.283); ERROR 1264 (22003): Out of range value for column 'salary' at row 1 mysql> -
FLOAT[(M,D)] [UNSIGNED] [ZEROFILL]单精度浮点数,非准确小数值,m是数字总个数,d是小数点后个数。 -
DOUBLE[(M,D)] [UNSIGNED] [ZEROFILL]双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
字符串类型:
CHAR和VARCHAR类型
BLOB和TEXT类型
ENUM类型和SET类型
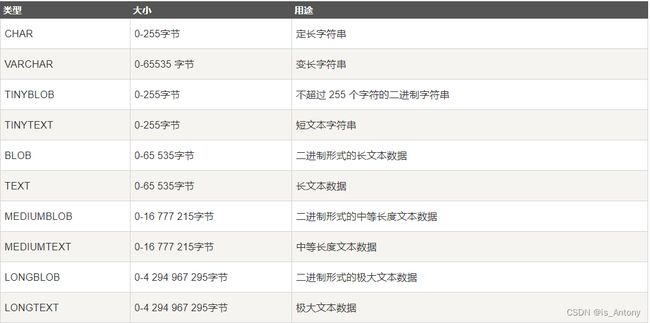
- char 和 varchar
char:定长,效率高,一般用于固定长度的表单提交数据存储,默认1字符
varchar:不定长,效率偏低 ,但是节省空间。
- text 和blob
text用来存储非二进制文本
blob用来存储二进制字节串
- enum 和 set
enum用来存储给出的一个值
set用来存储给出的值中一个或多个值
-
char(m)定长字符串,m代表字符串的长度,最多可容纳255个字符。 定长的体现:即使内容长度小于m,也会占用m长度。例如:char(5),数据是:yes,底层也会占用5个字符;如果超出m长度限制(默认MySQL是严格模式,所以会报错)。 如果在配置文件中加入如下配置, sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" 保存并重启,此时MySQL则是非严格模式,此时超过长度则自动截断(不报错)。。 注意:默认底层存储是固定的长度(不够则用空格补齐),但是查询数据时,会自动将空白去除。 如果想要保留空白,在sql-mode中加入 PAD_CHAR_TO_FULL_LENGTH 即可。 查看模式sql-mode,执行命令:show variables like 'sql_mode'; 一般适用于:固定长度的内容。 create table L3( id int not null primary key auto_increment, name varchar(5), depart char(3) )default charset=utf8; insert into L3(name,depart) values("alexsb","sbalex"); -
varchar(m)变长字符串,m代表字符串的长度,最多可容纳65535个字节。 变长的体现:内容小于m时,会按照真实数据长度存储;如果超出m长度限制((默认MySQL是严格模式,所以会报错)。 如果在配置文件中加入如下配置, sql-mode="NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION" 保存并重启,此时MySQL则是非严格模式,此时超过长度则自动截断(不报错)。 例如: create table L3( id int not null primary key auto_increment, name varchar(5), depart char(3) )default charset=utf8;mysql> create table L3(id int not null primary key auto_increment,name varchar(5),depart char(3))default charset=utf8; Query OK, 0 rows affected (0.03 sec) -- 插入多行 mysql> insert into L3(name,depart) values("wu","WU"),("wupei","ALS"); Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> select * from L3; +----+-------+--------+ | id | name | depart | +----+-------+--------+ | 1 | wu | WU | | 2 | wupei | ALS | +----+-------+--------+ 2 rows in set (0.00 sec) -- 非严格模式下,不会报错。 mysql> insert into L3(name,depart) values("wupeiqi","ALS"); ERROR 1406 (22001): Data too long for column 'name' at row 1 mysql> insert into L3(name,depart) values("wupei","ALSB"); ERROR 1406 (22001): Data too long for column 'depart' at row 1 mysql> -- 如果 sql-mode 中加入了 PAD_CHAR_TO_FULL_LENGTH ,则查询时char时空白会保留。 mysql> select name,length(name),depart,length(depart) from L3; +-------+--------------+--------+----------------+ | name | length(name) | depart | length(depart) | +-------+--------------+--------+----------------+ | wu | 2 | WU | 3 | | wupei | 5 | ALS | 3 | +-------+--------------+--------+----------------+ 4 rows in set (0.00 sec) mysql> -
texttext数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 一般情况下,长文本会用text类型。例如:文章、新闻等。create table L4( id int not null primary key auto_increment, title varchar(128), content text )default charset=utf8; -
mediumtextA TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. -
longtextA TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1)日期时间
-
datetime
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59)
-
timestampYYYY-MM-DD HH:MM:SS(1970-01-01 00:00:00/2037年)对于TIMESTAMP,它把客户端插入的时间从当前时区转化为UTC(世界标准时间)进行存储,查询时,将其又转化为客户端当前时区进行返回。 对于DATETIME,不做任何改变,原样输入和输出。mysql> create table L5( -> id int not null primary key auto_increment, -> dt datetime, -> tt timestamp -> )default charset=utf8; Query OK, 0 rows affected (0.03 sec) mysql> insert into L5(dt,tt) values("2025-11-11 11:11:44", "2025-11-11 11:11:44"); mysql> select * from L5; +----+---------------------+---------------------+ | id | dt | tt | +----+---------------------+---------------------+ | 1 | 2025-11-11 11:11:44 | 2025-11-11 11:11:44 | +----+---------------------+---------------------+ 1 row in set (0.00 sec) mysql> show variables like '%time_zone%'; +------------------+--------+ | Variable_name | Value | +------------------+--------+ | system_time_zone | CST | | time_zone | SYSTEM | +------------------+--------+ 2 rows in set (0.00 sec) -- “CST”指的是MySQL所在主机的系统时间,是中国标准时间的缩写,China Standard Time UT+8:00 mysql> set time_zone='+0:00'; Query OK, 0 rows affected (0.00 sec) mysql> show variables like '%time_zone%'; +------------------+--------+ | Variable_name | Value | +------------------+--------+ | system_time_zone | CST | | time_zone | +00:00 | +------------------+--------+ 2 rows in set (0.01 sec) mysql> select * from L5; +----+---------------------+---------------------+ | id | dt | tt | +----+---------------------+---------------------+ | 1 | 2025-11-11 11:11:44 | 2025-11-11 03:11:44 | +----+---------------------+---------------------+ 1 row in set (0.00 sec) -
dateYYYY-MM-DD(1000-01-01/9999-12-31) -
timeHH:MM:SS('-838:59:59'/'838:59:59')
- 表的基本操作
创建表(指定字符集)
create table 表名(
字段名 数据类型,
字段名 数据类型,
…
字段名 数据类型
);
- 如果你想设置数字为无符号则加上 unsigned
- 如果你不想字段为 NULL 可以设置字段的属性为 NOT NULL, 在操作数据库时如果输入该字段的数据为NULL ,就会报错。
- DEFAULT 表示设置一个字段的默认值
- AUTO_INCREMENT定义列为自增的属性,一般用于主键,数值会自动加1。
- PRIMARY KEY关键字用于定义列为主键。主键的值不能重复。
e.g. 创建班级表
create table class_1 (id int primary key auto_increment,name varchar(32) not null,age int unsigned not null,sex enum('w','m'),score float default 0.0);
e.g. 创建兴趣班表
create table interest (id int primary key auto_increment,name varchar(32) not null,hobby set('sing','dance','draw'),level char not null,price decimal(6,2),comment text);
查看数据表
show tables;
查看已有表的字符集
show create table 表名;
查看表结构
desc 表名;
删除表
drop table 表名;
-
清空表
delete from 表名;或truncate 表名; -
修改表
-
添加列
alter table 表名 add 列名 类型; alter table 表名 add 列名 类型 DEFAULT 默认值; alter table 表名 add 列名 类型 not null default 默认值; alter table 表名 add 列名 类型 not null primary key auto_increment; -
删除列
alter table 表名 drop column 列名; -
修改列 类型
alter table 表名 modify column 列名 类型; -
修改列 类型 + 名称
alter table 表名 change 原列名 新列名 新类型;alter table tb change id nid int not null; alter table tb change id id int not null default 5; alter table tb change id id int not null primary key auto_increment; alter table tb change id id int; -- 允许为空,删除默认值,删除自增。 -
修改列 默认值
ALTER TABLE 表名 ALTER 列名 SET DEFAULT 1000; -
删除列 默认值
ALTER TABLE 表名 ALTER 列名 DROP DEFAULT; -
添加主键
alter table 表名 add primary key(列名); -
删除主键
alter table 表名 drop primary key;
-
数据行操作
数据行操作的相关SQL语句(指令)如下:
- 新增数据
insert into 表名 (列名,列名,列名) values(对应列的值,对应列的值,对应列的值);
insert into tb1(name,password) values('武沛齐','123123');
insert into tb1(name,password) values('武沛齐','123123'),('alex','123');
insert into tb1 values('武沛齐','123123'),('alex','123'); -- 如果表中只有2列
- 删除数据
delete from 表名;
delete from 表名 where 条件;
delete from tb1;
delete from tb1 where name="wupeiqi";
delete from tb1 where name="wupeiqi" and password="123";
delete from tb1 where id>9;
- 修改数据
update 表名 set 列名=值;
update 表名 set 列名=值 where 条件;
update tb1 set name="wupeiqi";
update tb1 set name="wupeiqi" where id=1;
update tb1 set age=age+1; -- 整型
update tb1 set age=age+1 where id=2;
update L3 set name=concat(name,"db");
update L3 set name=concat(name,"123") where id=2; -- concat一个函数,可以拼接字符串
- 查询数据
select * from 表名;
select 列名,列名,列名 from 表名;
select 列名,列名 as 别名,列名 from 表名;
select * from 表名 where 条件;
select * from tb1;
select id,name,age from tb1;
select id,name as N,age, from tb1;
select id,name as N,age, 111 from tb1;
select * from tb1 where id = 1;
select * from tb1 where id > 1;
select * from tb1 where id != 1;
select * from tb1 where name="wupeiqi" and password="123";
where子句
where子句在sql语句中扮演了重要角色,主要通过一定的运算条件进行数据的筛选
MySQL 主要有以下几种运算符:
算术运算符
比较运算符
逻辑运算符
位运算符
算数运算符

e.g.
select * from class_1 where age % 2 = 0;
比较运算符

e.g.
select * from class_1 where age > 8;
select * from class_1 where between 8 and 10;
select * from class_1 where age in (8,9);
逻辑运算符

e.g.
select * from class_1 where sex='m' and age>9;
位运算符
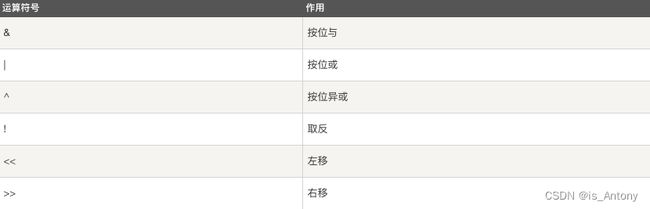

扩展语句
模糊查询和正则查询
LIKE用于在where子句中进行模糊查询,SQL LIKE 子句中使用百分号 %来表示任意0个或多个字符,下划线_表示任意一个字符。
使用 LIKE 子句从数据表中读取数据的通用语法:
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 LIKE condition1
e.g.
mysql> select * from class_1 where name like 'A%';
mysql中对正则表达式的支持有限,只支持部分正则元字符
SELECT field1, field2,...fieldN
FROM table_name
WHERE field1 REGEXP condition1
e.g.
select * from class_1 where name regexp '^B.+';
排序
ORDER BY 子句来设定你想按哪个字段哪种方式来进行排序,再返回搜索结果。
使用 ORDER BY 子句将查询数据排序后再返回数据:
SELECT field1, field2,...fieldN from table_name1 where field1
ORDER BY field1 [ASC [DESC]]
默认情况ASC表示升序,DESC表示降序
select * from class_1 where sex='m' order by age;
分页(限制)
LIMIT 子句用于限制由 SELECT 语句返回的数据数量 或者 UPDATE,DELETE语句的操作数量
带有 LIMIT 子句的 SELECT 语句的基本语法如下:
SELECT column1, column2, columnN
FROM table_name
WHERE field
LIMIT [num]
通配符
模糊查询:没有明确的筛选条件
关键字:like
关键符号:
%:匹配任意个数任意字符
_:匹配单个个数任意字符
show variables like ‘%mode%se’;
分组
分组: 按照某个指定的条件将单个单个的个体分成一个个整体
按照男女分组:男 女
按照年龄分组:20岁以下 20-30 30-40
# 单纯的分组是没有意义的
在MySQL中分组之后,只能够获得分组的依据! 按照哪个字段分组就只能获取这个字段的值,别的字段不能拿到
分组一般配合聚合函数使用:
sum max min avg count
分组的关键字:group by
# 数据分组应用场景:每个部门的平均薪资,男女比例等
# 1.按部门分组
1. 分组之后默认可以获取所有的字段信息
2. 分组之后,展示的数据都是每个组的第一条数据
分组
"""
按照某个指定的条件将单个单个的个体分成一个个整体
eg: 按照男女将人分组
按照肤色分组
按照年龄分组
"""
# 分组之后默认只能够直接过去到分组的依据 其他数据都不能直接获取
针对5.6需要自己设置sql_mode
set global sql_mode = 'only_full_group_by,STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTH';
# 聚合函数
聚合函数主要就是配合分组一起使用
max min sum count avg
# 数据分组应用场景:每个部门的平均薪资,男女比例等
# 1.按部门分组
select * from emp group by post; # 分组后取出的是每个组的第一条数据
select id,name,sex from emp group by post; # 验证
"""
设置sql_mode为only_full_group_by,意味着以后但凡分组,只能取到分组的依据,
不应该在去取组里面的单个元素的值,那样的话分组就没有意义了,因为不分组就是对单个元素信息的随意获取
"""
set global sql_mode="strict_trans_tables,only_full_group_by";
# 重新链接客户端
select * from emp group by post; # 报错
select id,name,sex from emp group by post; # 报错
select post from emp group by post; # 获取部门信息
# 强调:只要分组了,就不能够再“直接”查找到单个数据信息了,只能获取到组名
# 2.获取每个部门的最高工资
# 以组为单位统计组内数据>>>聚合查询(聚集到一起合成为一个结果)
# 每个部门的最高工资
select post,max(salary) from emp group by post;
补充:在显示的时候还可以给字段取别名
select post as '部门',max(salary) as '最高工资' from emp group by post;
as也可以省略 但是不推荐省 因为寓意不明确
# 每个部门的最低工资
select post,min(salary) from emp group by post;
# 每个部门的平均工资
select post,avg(salary) from emp group by post;
# 每个部门的工资总和
select post,sum(salary) from emp group by post;
# 每个部门的人数
select post,count(id) from emp group by post;
统计的时候只要是非空字段 效果都是一致的
这里显示age,salary,id最后演示特殊情况post_comment
分组扩展:
# group_concat 分组之后使用
如果真的需要获取分组以外的数据字段 可以使用group_concat()
# 每个部门的员工姓名
select post,group_concat(name) from emp group by post;
select post,group_concat(name,'|',sex) from emp group by post;
select post,group_concat(name,'|',sex, '|', gender) from emp group by post;
select post,group_concat(distinct name) from emp group by post;
select post,group_concat(distinct name separator '%') from emp group by post;
# concat 不分组使用
select concat(name,sex) from emp;
select concat(name,'|',sex) from emp;
# concat_ws()
select post,concat_ws('|', name, age, gender) from emp group by post;
having
where与having都是筛选功能 但是有区别
where在分组之前对数据进行筛选
having在分组之后对数据进行筛选
1.统计各部门年龄在30岁以上的员工平均薪资,并且保留平均薪资大于10000的部门.
# 先筛选出年龄在30岁以上的
select * from emp where age > 30;
# 在进行分组,按照部门分组
select avg(salary) as avg_salary from emp where age > 30 group by post;
# 保留平均薪资大于10000的部门
select avg(salary) as avg_salary from emp where age > 30 group by post having avg(salary) > 10000;
distinct
distinct:去重
"""带主键的数据去重有没有意义? 没有,主键本身就是唯一的"""
select distinct id,age from emp;
主键(primary key)
主键单纯从约束上来看,它相当于是非空且唯一 unique not null"“”
id unique not null ---------> id primary key
create table t8 (id int primary key);
create table t8 (id int unique not null);
# 主键本身是一种索引,索引能够加快查询速度
DB存储引擎规定每一张表都要有一个主键,但是,我之前创建的表都没有指定主键, 表是怎么创建成功的?
是因为InnoDB存储引擎内部有一个隐藏的主键,这个主键我们看不到,它也不能够加快查询速度,仅仅是为了帮助我们把表创建成功. 所以,以后我们创建表的时候都主动的创建一个主键,我们自己创建的主键能够加快查询速度,因为是一个索引.
“”"
一般情况下,主键应该创建哪个字段? 大多都给id字段加了,所以,每一张表都要有一个id字段,并且一张表中不只是有一个主键,可以有多个主键,但是,大多数情况下,都只有一个
主键一般都给id aid sid uid pid ...
create table t(
id int primary key,
name varchar(32)
)
# 我们可以通过主键确定一张表中得唯一一条记录!!!
auto_incrment
# 自增:每一次主动比上一次加1
"""一般情况下,它配合主键使用"""
create table t9 (
id int primary key auto_increment,
name varchar(32)
);
整型中括号中得数字的作用
id int(10) # 数字不代表的是范围
name varchar(32) # 数字代表的就是存储的范围
create table t1(id int(3));
create table t2(id int(9));
insert into t2 values(9);
create table t3(id int(9) zerofill);
insert into t3 values(9);
外键
外键是数据库中的一种约束,用来连接两个表格之间的关系。在关系型数据库中,一个表格的外键指向另一个表格的主键,从而实现两个表格之间的关联。对于两个具有关联关系的表而言,相关联字段中主键所在的表就是主表(父表),外键所在的表就是从表(子表)。
外键的作用是维护表格之间的一致性和完整性。当我们删除一个表格中的某个记录时,如果这个记录与其他表格有关联,外键会阻止这个删除操作,从而保证数据的完整性。另外,外键还可以保证在插入或修改数据时,所引用的数据是存在的,从而保证数据的一致性。
创建外键的语法如下
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
表与表之间的关系
一对一
在MySQL中,一对一关系是一种关系型数据模型,表示两个实体之间的一种关系,其中每个实体只能最多拥有一个与另一个实体相关联的实体。
以作者表和作者详情表为例
以作者表和作者详情表为例
外键关系建在哪里?
# 两张表都可以,但是,推荐建在查询频率较高的一张表
在SQL层建立一对一的关系
create table author1(
id int primary key auto_increment,
name varchar(32),
gender varchar(32),
author_detail_id int unique,
foreign key(author_detail_id) references author_detail(id)
on update cascade
on delete cascade
);
create table author_detail(
id int primary key auto_increment,
qq varchar(32),
email varchar(32)
);
一对多
一对多关系是指一个实体在另一个实体上具有多个关联实体。例如,一个订单可能对应多个订单项,但每个订单项只能属于一个订单。在关系数据库中,可以使用外键来实现一对多关系。
一对多的表关系
“”“如何判断表关系:换位思考法”“”
以员工表和部门表为例
先站在员工表
问:一个员工能否有多个部门?
答:不能
在站在部门表
问:一个部门能否有多个员工?
答:可以
# 结论:一个可以,一个不可以,表关系就是:一对多, 表关系中没有多对一
“”“针对于一对多,外键字段要建在多的一方”“”
如何在SQL层面建立一对多的关系: 先把基础表的中基础字段建立出来,然后在考虑外键字段
create table emp(
id int primary key auto_increment,
name varchar(32),
age int,
dep_id int,
foreign key(dep_id) references dep(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade # 级联删除
);
create table dep(
id int primary key auto_increment,
dep_name varchar(32),
dep_desc varchar(32)
);
# 录入数据
insert into emp(name, age, dep_id) values('kevin', 20, 1);
insert into dep(dep_name,dep_desc) values('人事部', '管理人才');
多对多
多对多关系是指两个实体之间存在多个关联实体。例如,一个作者可以写多个书籍,同时一本书也可能有多个作者。
以图书表和作者表为例
我们站在图书表的角度
问:一本图书能不能有多个作者?
答:可以
我们再站在作者表的角度
问:一个作者能不能写多本书
答:可以
得出结论:如果两个都可以,那么表关系就是’多对多’
“”“针对于多对多的表关系,外键字段建在第三张表中”“”
针对多对多表关系,外键字段如何创建?
在SQL层面建立多对多的表关系
create table book(
id int primary key auto_increment,
title varchar(32),
price decimal(8,2)
);
create table author(
id int primary key auto_increment,
name varchar(32),
addr varchar(32)
);
create table book2author(
id int primary key auto_increment,
book_id int,
author_id int,
foreign key(book_id) references author(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade, # 级联删除
foreign key(author_id) references book(id) # 让两张表建立了外键关系
on update cascade # 级联更新
on delete cascade
);
insert into book(title, price) values('金瓶梅', 1000);
insert into book(title, price) values('西游记', 2000);
insert into author(name, addr) values('zhangsan', 'beijing');
insert into author(name, addr) values('lisi', 'shanghai');
insert into book2author(book_id, author_id) values(1, 1);
insert into book2author(book_id, author_id) values(1, 2);
insert into book2author(book_id, author_id) values(2, 1);
insert into book2author(book_id, author_id) values(2, 2);
表关系中创建外键需要遵守以下规则:
1 主表必须已经存在于数据库中,或者是当前正在创建的表。如果是后一种情况,则主表与从表是同一个表,这样的表称为自参照表,这种结构称为自参照完整性。
2 必须为主表定义主键。
3 主键不能包含空值,但允许在外键中出现空值。也就是说,只要外键的每个非空值出现在指定的主键中,这个外键的内容就是正确的。
4 在主表的表名后面指定列名或列名的组合。这个列或列的组合必须是主表的主键或候选键。
5 外键中列的数目必须和主表的主键中列的数目相同。
6 外键中列的数据类型必须和主表主键中对应列的数据类型相同。
多表联查
- 子查询
所谓子查询也可称为嵌套查询,即将一个查询的结果作为另一个查询的条件
select *from dep where id = (select dep_id from emp where name='kevin';);
- 联表查询
即将两张即以上的表在内存中通过连接成为一张大的虚拟表,后续查询即对该表查询
专业的连表语法:
inner join # 内连接,查询的是两张表中都有的数据
left join # 左连接,以左表为基准,查询左表中所有的数据,右表没有的数据,使用NULL填充
right join # 右连接,以右表为基准,查询右表中所有的数据,右表没有的数据,使用NULL填充
union # 连接两个SQL语句的结果
select * from emp left join dep on emp.dep_id=dep.id
union
select * from emp right join dep on emp.dep_id=dep.id;
"""连表可以连很多张表,不只是两张,大多数都是两张"""
select * from emp left join dep on emp.dep_id=dep.id inner join A on A.id=dep.A_id where ...;