基于深度学习的语音识别算法的设计与实现
收藏和点赞,您的关注是我创作的动力
文章目录
- 概要
- 一、课题内容
- 二、需求分析
- 2.1 算法需求分析
- 2.2 语音录制
- 2.3 声学模型
- 2.4 语言模型
- 2.5 训练集和测试集
- 2.6 深度神经网络
- 三 算法设计原理
- 3.1 语音识别系统
- 3.1.1 声学模型
- 3.1.2 语言模型
- 3.1.3 发音词典
- 四 简单问答功能
- 1.界面展示:
- 2.录音模块的功能:
- 3.语音解码功能:
- 4.语音问答功能:
- 5.翻译功能:
- 五 结 论
- 目录
概要
语音识别(Speech Recognition)是一种让机器通过识别音频把语音信号转变为相
应的文本或命令的技术语音识别技术主要有模式匹配识别法,声学特征提取,声学模型
建模 ,语言模型建模等技术组成。借助机器学习领域中的深度学习的发展,语音识别技
术在这几年发展突飞猛进。随着互联网发展,语音识别在移动终端上得到广泛应用。本
文在机器学习领域的神经网络算法、机器翻译技术等基础上,设计实现了基于深度学习
的语音识别算法应用。该算法应用使用了深度学习下的神经网络为主要架构,结合 CTC、
LSTM 等算法,使用 pycharm community edition 为主要开发软件,实现了具有中文语音
问答、中英文本或语音翻译功能的算法应用。
关键词:语音识别;声学模型;机器学习;深度学习;神经网络算法;CTC;LSTM;
一、课题内容
本课题设计期望达到的技术要求是:算法的识别效率、识别准确率等要在现有标准上有一个提升。问答系统能基本做到进行日常问答,翻译系统能准确翻译识别到的文本信息。
本课题设计使用 python3 语言构建算法,以 keras(开源人工神经网络库)和tensorflow(机器学习算法库)为依赖,搭建神经网络算法,使用 CTC 损失函数,LSTM 长短期记忆网络结构等技术构建模型文件。
本课题设计的研究目标:如何让机器读取音频文件并将其转为音频信号用于识别,音频信号处理时对声学特征的提取的方法,不同特征对识别效果是否有影响。深层网络的搭建所用到的基本元件有哪些,通过训练规划设置超参数,如 learning rate学习率、iteration 迭代数、隐藏层数 L、隐藏神经元数目、使用的激活函数activation funtion。如何把隐马尔可夫模型应用到算法当中,如何基于马尔科夫链将拼音转换为中文文本输出。怎样把数据集分割成训练集和测试集,怎样分割数据比例能让算法效率最大化。应该选择什么优化算法加快训练模型速度。如何防止神经网络的过拟合问题,如何减少梯度消失或梯度爆炸问题的影响。怎么样使算法不陷入局部最优以解决准确率不足问题;声学模型和语言模型训练的选择,如何确保使用的模型性能稳定又优秀,模型文件的结构处理怎么样的;问答系统能不能做到同一个问题能有多种或无限种答案,回答的语句是否符合说话人问题的形式,如果答非所问的次数过多是否有哪些方法对其进行优化;翻译系统如果不使用基于网络上开源的翻译工具,通过构建机器翻译神经网络算法来得出翻译,翻译的完成率和准确率是
否能达标,如何结合实际改进算法等等。 诸如总总问题都是本次课题设计需要解决的问题。
二、需求分析
2.1 算法需求分析
本课题设计是语音识别算法,算法程序中除了算法要基于深度学习人工神经网络搭
建外,还需要基于 pyaudio 的 python 录音程序,基于隐马尔可夫的声学模型文件,处理音频信息和转换音频信号的算法程序,训练语音模型的算法程序,测试语音模型的文件,机器翻译算法等。本课题设计基本功能为可以录制一段简短的话,通过算法程序转换成计算机能识别处理的信号,然后通过语言模型转换为文本文字输出,按照说话人的要求,算法识别对这段文字作出回应或进行翻译。
2.2 语音录制
使用简单的语音处理 python 库编写一个使用麦克风录制一小段语音的程序,录音结束后自动播放一遍看一下录音效果。保存文件形式为 wav 或 pcm 文件便于处理,单声道,采样率暂定为 16khz,录音时间长度为 10 秒左右。保存的音频如下图 2.1 所示。
图 2.1 音频文件
2.3 声学模型
由于本课题设计是基于深度学习下进行的,而用于声学建模的结构最好的就DNNHMM声学模型结构。利用深度神经网络处理语音音频信息,筛选并提取声音特征,隐马尔可夫模型对语音信号的序列进行处理,把得到语音波形进行采样处理,分割成等长的语音帧,对每一个语音帧进行计算得到其对应的状态标描述。
2.4 语言模型
语言模型的建立需要大量的经过分词的文本来进行训练,训练得到的模型性能标准用 PPL 评价,PPL 越小表示该模型预测的性能越好(PPL 指通过上下文联系来预测出下一个词的候选词个数)。建立语言模型,可以识别某个句子或某个词语出现的概率,帮助语音识别系统和翻译系统能输出最接近真实值或者最优解的句子。
2.5 训练集和测试集
利用 GitHub 上开源的语音库,中文语音数据集,中文普通话语料库,英文语料库等数据集进行模型训练。要对数据集进行比例分割成训练集和测试集。图 2.2 所示为部分数据集样例。

图 2.2 数据集样本
2.6 深度神经网络
深度神经网络下循环神经网络和卷积神经网络对语音识别都有不一样的优点。可以用不同的神经网络结构构建算法。对深度神经网络的网络结构参数进行确定:输入层、隐藏层、输出层的神经元个数,神经网络的激活函数(sigmoid,relu 和 tanH)的选择,如何初始化参数,计算正向和反向传播的代价函数、损失函数,确定算法中的 learning rate(学习率)、iterations(梯度下降法循环的数量)、mini batch size(批量梯度下降的大小)等超参数的最优值,如何避免搭建深度神经网络会出现的诸如梯度消失、过拟合等影响算法的现象,出现这些现象时的使用什么优化算法,优化算法要更新模型的参数。如下图 2.3,是一个简单的神经网络模型结构图。
图 2.3 神经网络模型
三 算法设计原理
3.1 语音识别系统
语音识别系统,输入一段语音经过系统处理后输出一个与语音匹配程度最高的文本
内容。语音识别系统示例图如下图 3.1 所示
图 3.1 语音识别系统流程图
3.1.1 声学模型
指的是对发音进行建模,将语音输入信息转换成语音信号。通过计算这段语音信号
与音素、音节等发音的匹配程度,给出对应的概率。通过把语音信号分割成许多等分的帧,进行傅里叶变换等操作,转换成特征向量。在语音识别中,声学模型的性能对语音识别系统的优劣有很大的影响。
DNN-HMM 模型中,深度神经网络结构克服了传统声学模型 GMM 不太能够描述复杂语音信号的情况和分类能力,同时把 HMM 的优秀的时序建模能力充分发挥出来,提高了语音识别系统对外围环境噪声干扰的鲁棒性,而且可以把多种特征进行融合后输入给深度神经网络,深度神经网络在对大量的训练样本进行训练时,时长较长的情况下还能保持一个较为优秀的性能。DNN-HMM 的原理图如下图 3.2 所示。
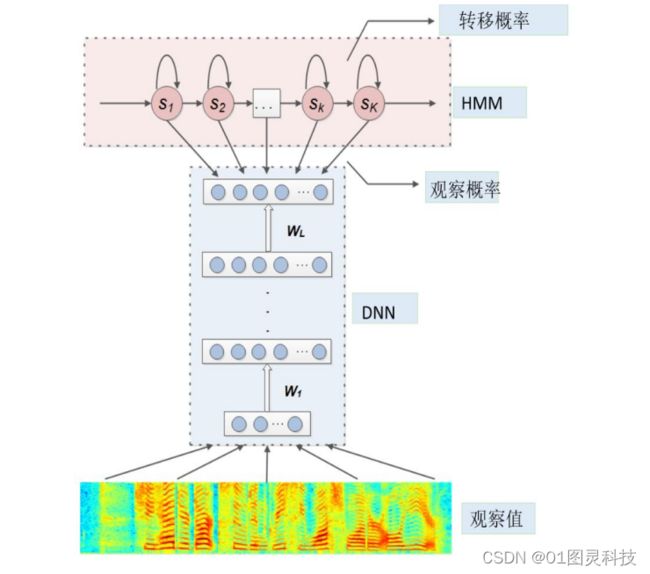
图 3.2 DNN-HMM 模型图
HMM 中的 s 指的是当前时刻的状态,s(1,k)指向 DNN 的箭头是指 HMM 的某个状态的观察概率由 DNN 的某一个输出节点决定,和 GMM-HMM 模型对比,DNN 代替了 GMM 输出了观察概率;在监督学习中, 转移概率可以看作是根据观察值去求状态值,而深度神经网络 DNN 恰好是一个根据观察值去逆向传播的过程。 长短期记忆网络 LSTM(Long-Short Term Memory)是用来改良循环神经网络的。深度神经网络一般来说层与层之间都是全连接的,在语音识别中对于预测下文或者下个词语时,一般的深度神经网络结构无法起到作用来整理描述时序信息,而循环神经网络的
结构恰好能克服这个缺点,每一层的输出都包含了上一层的输出以及这一层的输出。但是循环神经网络在应用时候,它本身的记忆能力在网络层数加深的情况下会出现下降,也就是我们常说的神经网络中的梯度消失现象。LSTM 就是用来弥补这种能力上的缺失所提出的循环神经网络神经元改进型,它可以使得神经网络单元对信息能够进行长时间的保存,能处理一些足够长的序列数据。而一般的由长短期记忆网络构成的模型如下图3.1.2 所示。
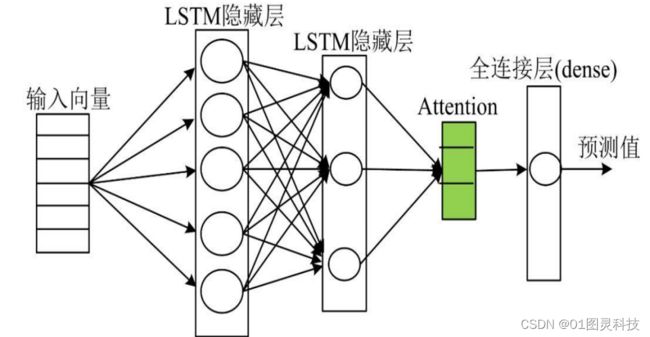
图 3.3 LSTM 网络结构
3.1.2 语言模型
语言模型又被称为语言学模型,用来描述我们的语言习惯以及使用的词语之间的联系。从机器学习上来讲,对于一个 w1,w2…,wN 序列,语言模型的作用就是计算这个序列可能出现情况的概率,从而判断这个句子是否正常。从数学角度来讲,语言模型对一个语言序列进行计算,统计其中各个词语出现以及词语组合的频率,从而判断词语间排列的关系。 语言模型一般采用链式法则,常见的是基于马尔可夫模型的 N-Gram 模型,中文名又叫汉语语言模型,N-Gram 是一种按词语自身来进行划分的语言模型,可以在不带空格的连续的拼音符号转换为文字时,计算出概率最大的语句,其基于当前词语出现的概率只和前 N-1 个词有关联,与其他词没有关系的假设而建立。
3.1.3 发音词典
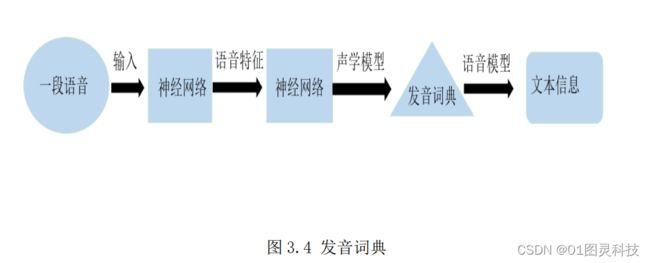
发声词典基于声学和语言学,描述的是词与发音字母之间的关联。以中文发声词表为例子,通过规定词表中的词与拼音对应的关系,用声韵母基元加音节基元组成语音识别词典,能够把音频信号转换成拼音符号,对拼音转汉字解码,处理过后得出对应的中文词。发音词典在深度神经网络语音识别中的作用如下图 3.4 所示
四 简单问答功能
1.界面展示:
一个简易的登录界面,输入昵称等信息,点击 login 登录就会弹出功能界面。界面如下图 5.3 所示
图 5.3 登录界面
2.录音模块的功能:
可以录制 10 秒的语音,声音基本清晰。如果把录音数值中的声道改为双声道,字节大小改为 1,同时减少采样率,会使得录音效果奇差无比,录音内容全被杂音覆盖。录音示例如下图 5.4 所示,点击按钮就可以说话,进度条显示时间长短,控制在 10 秒以内。

图 5.5 录音示例
3.语音解码功能:
基本能正常识别录音中的内容,在大量训练的情况下转换为中文的内容基本吻合。但是测试过程中有个别时候会出现因为口音问题而使得某个字词识别输出成了与其发音相似的词,就好像“说话”变成了“嗦话”。
4.语音问答功能:
可以进行基本日常问答,同一个问题重复询问后的回答不会出现多于判断算法文件中所包含的情况,基本能做到根据关键词语回答对应问题,设计实时信息的内容无法做答(比如询问天气、今天的运程等会无法理解),可以试着添加互联网实时获取信息的功能。下图 5.5 所示为简易的问答显示界面
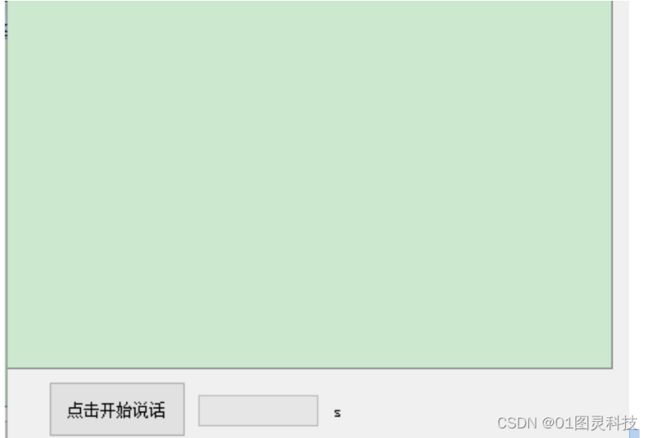
图 5.5 简易的问答界面
点击按钮录音后,后台脚本运行,进度条走完,上方文本框显示识别的语音以及系统回答的结果,如下图 5.6 所示。
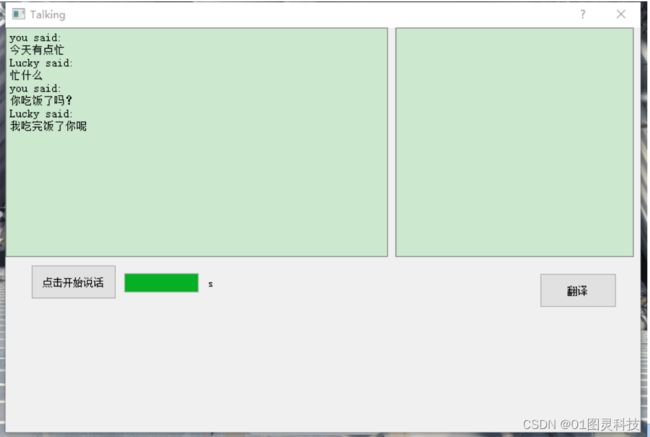
图 5.6 问答情况
5.翻译功能:
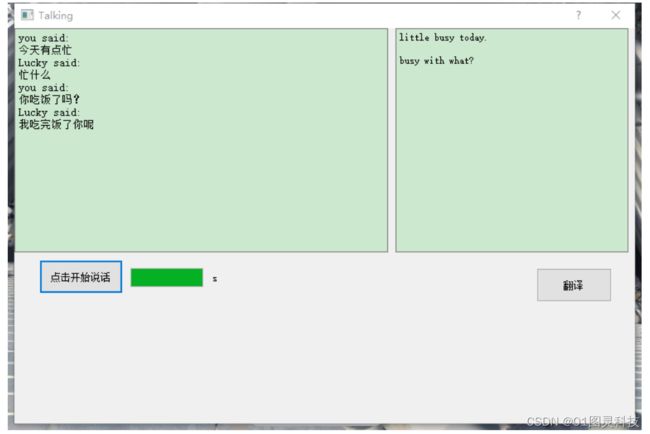
基于翻译词典,能把识别到的语音转换为文本信息后,对文本信息进行翻译。如下图 5.7 所示,点击翻译就能把保存在文本中的对话内容进行翻译,每点一次翻译一句,仅对对话内容进行翻译。
五 结 论
进入互联网时代多年的我们,已经习惯了互联网快速多元的一面。每过一段时间,总会有新兴的技术诞生。计算机刚刚诞生的那个时代,语音识别技术对于人们来说只能算是一种冷门而又困难的研究方向,那个时候只能识别个别的字母,少量的词汇。自从人工智能领域的开始兴起以后,语音识别技术开始大放异彩,让人耳熟能详的小米智能音箱、Iphone 自带的语音助手 Siri、微软系统的 Cortana 都是我们能经常看到的优秀的语音产品。我们似乎离那个想象中,动动嘴巴就能让机器代替我们完成所需工作的时代不远了。
这个课题设计和我之前所接触到的设计完全不一样,由于本人对新兴的人工智能领域有着浓郁的兴趣,所以才接触并学习过简单基本的机器学习的神经网络,一般称为Back Propagation Neural Network(BP 人工神经网络)。与深度神经网络不同,它是机器学习的基本算法之一,搭建起来也比较简单,只需确定 3 层网络结构、参数等数值就能运行。
选择开发的软件为 pycharm community,这是对比需要收费的 pycharm 而言免费又好用的一款开源的 python 开发软件,相比 python3.7 自带的 idle 或者 jupyter,pycharm整合了很多 python 的库,下载调用很简单。总所周知,python 是一个代码十分简洁的编程语言,正因为有许多业界大佬或者企业把开发的东西打包封装到库里面,使得python 调用极其方便。在 tensorflow 和 keras 中,有许多封装好的简单的神经网络构建函数,只要调用它的函数,能省去很多搭建框架的烦恼。因为 python 的简洁性,使得编写代码不会出现太多重复问题,对于复杂机器学习算法来说,重复问题会极其影响到维护修改代码。
目录
目 录
1 绪论 … 1
1.1 课题背景 … 1
1.2 本设计在国内外的发展概况及存在的问题 … 1
1.3 课题内容 … 2
1.4 论文结构 … 3
2 需求分析 … 4
2.1 算法需求分析 … 4
2.2 语音录制 … 4
2.3 声学模型 … 5
2.4 语言模型 … 5
2.5 训练集和测试集 … 5
2.6 深度神经网络 … 6
3 算法设计原理 … 7
3.1 语音识别系统 … 7
3.1.1 声学模型 … 7
3.1.2 语言模型 … 9
3.1.3 发音词典 … 9
3.2 深度神经网络 … 10
3.2.1 神经网络 … 10
3.2.2 循环神经网络(Recurrent Neural Network) … 12
3.2.3 卷积神经网络(Convolutional Neural Networks) … 14
3.2.4 LSTM(Long-Short Term Memory) … 15
3.3 涉及的技术 … 16
3.3.1 CTC 技术… 16
3.3.2 encoder-encoder 结构 … 16
3.4 问答系统 … 17
3.5 功能设计 … 18
3.5.1 语音录制 … 18
3.5.2 语音数据集的处理 … 19
3.5.3 搭建神经网络 … 19
3.5.4 问答系统 … 20
3.5.4 翻译系统 … 20
北京理工大学珠海学院 2020 届本科生毕业设计
3.5.4 系统界面 … 21
4 系统实现 … 23
4.1 语音录制 … 23
4.2 模型训练 … 23
4.3 模型测试 … 25
4.4 简单问答功能 … 26
4.4 简单翻译功能 … 27
5 算法系统测试 … 29
5.1 测试环境 … 29
5.2 测试内容及结果 … 30
总结与展望 … 34
引用 … 35
参考文献 … 36
谢 辞 … 37
附 录 … 38