scikit-multilearn 笔记 第四节 scikit-multilearn存储库
英文原文: 点我.
声明:此博文为对原英文文章的翻译加个人的理解,一方面为自己学习所用,另一方面为需要中文scikit-multilearn文档的小伙伴提供便利。
侵删
scikit-multilearn存储库
最初在MULAN数据存储库中提供的以下基准数据集以训练,测试和未划分的变体形式提供。 在训练/测试分割之前,未分割的变体包含完整的数据集。
from skmultilearn.dataset import available_data_sets
data_set = set([x[0] for x in available_data_sets().keys()])
print(data_set)
data_set_1 = set([x[1] for x in available_data_sets().keys()])
print(data_set_1)
输出的结果为{‘rcv1subset5’, ‘rcv1subset4’, ‘yeast’, ‘mediamill’, ‘genbase’, ‘birds’, ‘scene’, ‘tmc2007_500’, ‘delicious’, ‘medical’, ‘bibtex’, ‘enron’, ‘rcv1subset2’, ‘rcv1subset3’, ‘rcv1subset1’, ‘Corel5k’, ‘emotions’},与文档中不一样,应该是应为版本的问题。输出结果图片如下:

Scikit-multilearn可以为你自动下载数据集,类似scikit-learn数据集的API。
数据默认存储在SCIKIT_ML_LEARN_DATA环境变量的子文件夹scikit_ml_learn_data 中,如果没有设置环境斌拉,数据将存储在~/scikit_ml_learn_data文件夹下。
下载数据集使用下面这个方法:load_dataset 函数
from skmultilearn.dataset import load_dataset
X, y,feature_names,label_names = load_dataset('scene', 'train')
print(X.shape, y.shape, feature_names,label_names)
![]()
4.1 ARFF文件
存储多标记数据最普通的方式是ARFF文件格式,是由WEKA library创造的。你可以在MULAN data repository 上找到很多ARFF格式的基准数据集。
加载密集的和稀疏的ARFF文件在 scikit-multilearn中是简单的,仅需使用函数load_from_arff,就象这样:
from skmultilearn.dataset import load_from_arff
加载多标记ARFF文件需要额外的信息,因为标记的数量或者位置在这种格式下并不会直接指出。
path_to_arff_file = '_static/example.arff'
label_count = 7
不同的软件需要ARFF文件的不同部分中的标签:
- MEKA 需要标记出现在文件的开头。
- MULAN 需要标记出现在文件的结尾。
例如来自MULAN的.arff文件,我们需要设置标记位置为结尾。
label_location = 'end'
保存ARFF数据有两种方式:
- 密集的:其中文件包含逐行完整的数据集转储,包括值为0的位置
- 稀疏的:如关键字字典一样,只列出非零元素的索引。
举的例子中文件为稀疏的,所以要将load_sparse设置为False,或者你需要元数据: feature and label names。
from skmultilearn.dataset import load_from_arff
path_to_arff_file = '_static/example.arff'
label_count = 7
label_location = 'end'
arff_file_is_sparse = False
X, y, feature_names, label_names = load_from_arff(
path_to_arff_file,
label_count=label_count,
label_location=label_location,
load_sparse=arff_file_is_sparse
)
print(X.shape, y.shape, feature_names[:3],label_names[:3])
运行结果如下,显示没有此文件。
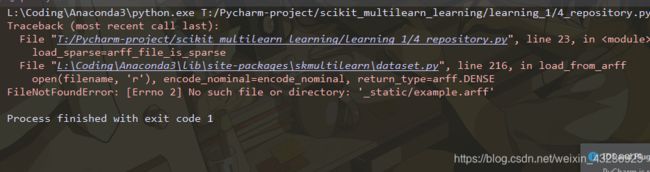
正如您所看到的,scikit-multilearn默认将名义类型编码为整数,并将输入空间转换为浮点数,而输出空间转换为二进制指示符0/1表示为整数。 要更改此行为,请按API文档中的说明指定自己的load_from_arff参数。
如果你想保存ARFF文件,你可以使用这个方法:save_arff 函数,这个函数返回一个包含数据集的ARFF转储的字符串或者在传递filename参数时将其保存到提供的文件中。将数据的子集以稀疏的方式保存,并且标记在文件的开头。
from skmultilearn.dataset import save_to_arff
print(save_to_arff(X[:10,:4], y[:10, :3], label_location='start', save_sparse=True))
个人能力有限,望各位批评指正。