认识Redis
目录
redis是什么
关于分布式系统
单机架构
应用服务和数据库服务分离
应用服务集群
读写分离/主从分离架构
引入缓存/冷热数据分离
垂直分库
微服务架构
微服务的优势
微服务的劣势
分布式系统中的常见概念
redis是什么
关于redis,我们可以在redis官网中,看到这样一句话.

这句话简明概述了redis是什么和redis是用来做什么的.接下里,我们来解读一下这句话.
首先,redis是一个开放的资源,它最大的亮点就是在内存中来存储数据.它能够作为数据库,缓存,流式引擎和消息中间件等.
redis的初心就是用来作为一个"消息中间件",是一个分布式系统下的生产者消费者模型,但是当前很少会直接使用redis来作为消息中间件,因为目前业界内有更多更专业的消息中间件来供我们使用.
接下来会有一个问题,直接定义变量,不就是在内存中存储数据吗,为什么还要使用redis?
redis是在分布式系统中,才能发挥其存储数据的优势.如果只是在单机程序下,直接通过变量存储数据的方式,是比redis更加有优势的.因为redis是基于网络的,本质上是进程间的通信.
redis作为数据库相对于mysql有哪些优劣呢?
mysql最大的问题就是访问速度比较慢,因为是读写硬盘相对于内存和cpu会慢很多.而有些互联网产品对于性能的要求是比较高的.那redis作为数据库最大的亮点就是"快".因为redis是直接将数据存储在内存中的,读取内存是比读取硬盘快很多很多的.从定性的角度,可以知道redis快很多,但是很难定量去衡量redis到底比mysql快多少倍.但是redis和mysql相比,redis最大的劣势就是存储空间有限!
关于分布式系统
要想深入的学习redis,我们必须要了解什么是分布式系统.
单机架构
只有一台服务器,这个服务器负责所有的工作.(此处假设是一个电商网站)

应用服务就是我们写的服务器程序,数据库服务是mysql的本体mysql服务器(存储和组织数据的地方).
如果业务进一步扩大,用户量和请求量都大大增加,此时一台主机是难以应付的,此时就需要引入更多的主机,引入更多的硬件资源.
因为一台主机的硬件资源是有上限的,包括不限于:cpu,内存,硬盘,网络等等.服务器每次收到一个请求,都是需要消耗上述资源的.如果同一时刻,处理的请求多了,此时就可能会导致某个硬件资源不够用了,无论是哪个方面不够用了,都会导致服务器处理请求的时间变长,甚至于是处理出错.
当一台主机的硬件拓展到达极限了(主板的扩展能力有限),此时只能引入更多的主机了.一旦引入更多的主机了,我们的系统就可以称为是"分布式系统".
一旦引入分布式,系统的复杂程度会大大提高,出现bug的概率也会提高.
应用服务和数据库服务分离

将应用和数据分离,可以以最小的代价提高系统的承载能力.此种架构将数据库服务独立部署在同一个数据中心的其他服务器上,应用服务通过网络来访问数据.
此种架构也更有利于我们进行硬件的选配,使其达到最佳的性价比.
应用服务器,里面包含很多的业务逻辑,是比较吃cpu和内存的,此时我们就可以将cpu和内存上一个等级,对于硬盘来说,满足基本的业务需求即可.
存储服务器,作为数据库服务器,需要更大的硬盘空间和更快的数据访问速度,此时我们就可以配置更大的硬盘的服务器,甚至可以上固态硬盘.
应用服务集群
引入更多的应用服务器节点.

应用服务器会比较吃cpu和内存,如果把cpu和内存吃没了,此时的一台应用服务器就不够用了.引入更多的应用服务器可以有效解决上述问题.
此时用户的请求会先到达负载均衡器(单独的服务器),引入新的组件负载均衡是为了解决用户流量向哪台应用服务器分发的问题,需要一个专门的系统组件做流量分发.
流量调度的算法有很多种,比如Round-Robin 轮询算法,即⾮常公平地将请求依次分给不同的应⽤服务器;Weight-Round-Robin 轮询算法,为不同的服务器(⽐如性能不同)赋予不同的权(weight), 能者多劳;⼀致哈希散列算法。通过计算⽤⼾的特征值(⽐如 IP 地址)得到哈希值,根据哈希结果做分发,优 点是确保来⾃相同⽤⼾的请求总是被分给指定的服务器。
负载均衡器承担了所有的请求,所以负载均衡器对于请求量的承担能力,要远超过应用服务器.
一台负载均衡器顶不住了,也可以引入更多的负载均衡器.
读写分离/主从分离架构
无论扩展多少台应用服务器,这些请求最终还是会从数据库读写数据,当到达一定程度之后,数据库的压力就成为了系统承载能力的瓶颈点.
那么,我们可以向扩展应用服务器那样扩展数据库服务器吗>
答案是不能的,因为数据库服务有一定的特殊性,如果将数据分散到各台服务器之后,数据的一致性将无法得到保障.
所以我们要保留一个主要的数据库作为写入数据库,其他的数据库作为从属数据库.从库的所有数据全部来自主库的数据,经过同步之后,从库可以维护这与主库一致的数据.然后为了分担数据库的压力,可以将写的数据请求全部交给主库处理,读的数据请求分散到各个从库中.在一般的场景中,读的频率是远大于写的.

主服务器一般是一个,从服务器可以是多个.(一主多从)
引入缓存/冷热数据分离
随着访问量的持续增加,我们发现业务中的一些数据的读取频率是远大于其他数据的读取频率的,我们就把这部分数据称为热点数据,与之对应就是冷数据.针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热门商品的信息以及热门商品的html页面等.通过缓存能把绝大多数请求在读写数据前拦截掉,从而大大降低数据库的压力.通常使⽤memcached作为本地缓存,使⽤ Redis 作为分布式缓存.

垂直分库
引入分布式系统,不止能去应对更高的请求量,同时也要去应对更大的数据量.
当一个服务器存储不下更多的数据的时候,就需要更多的主机来存储.

针对数据库进一步的拆分.
本来一个数据库服务器,这个数据库服务器上有多个库,现在就可以引入多个数据库服务器,每个数据库服务器来存储一个或者一部分库.
如果某个表特别大,大到一台主机存不下,也可以针对表进行拆分.这要根据业务场景来具体实践.
微服务架构
将业务分给不同的开发团队去维护,每个团队独立实现自己的微服务,然后互相之间对数据的直接访问进行隔离,实现互相之间的调用关联.可以把一些类似用户管理,安全管理,数据采集等业务提供成公共服务.
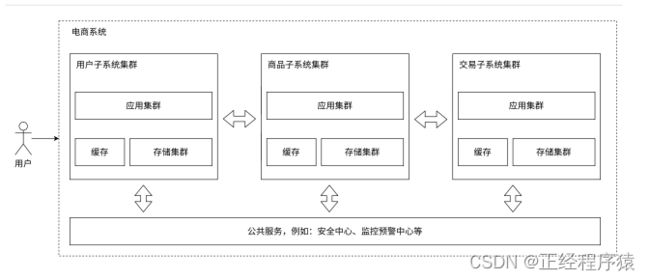
之前的应用服务器,一个服务器里面做了很多的业务,这就可能会导致一个服务器的代码变得越来越复杂.为了更加方便的进行代码维护,就可以把这样一个复杂的服务器,拆分成更多的,功能更加单一,但是更小的服务器,这样的服务器就叫做微服务.微服务中服务器的种类和数量增加了.
注意,微服务本质上是在解决"人"的问题.
当应用服务器复杂了,势必就需要更多的人来维护了,当人员增多后,就需要配套的管理,来将这些人给组织好.划分组织结构,分成多个组,每个组都配备领导进行领导,分成多个组后,就需要进行分工.
按照功能,拆分成多组微服务,就可以有利于上述人员的组织结构的分配了.
微服务的优势
1.解决了人员管理的问题.
2.使用微服务,可以方便功能的复用.
3.可以给不同的服务进行不同的部署.
微服务的劣势
1.系统的性能下降.拆分出来的更多的服务,多个功能之间要依赖网络通信,网络通信的速度相对于硬盘是比较慢的.
2.系统的复杂程度提高,系统的可用性下降.服务器更多了,出现问题的概率也就更大了.这就需要一系列的手段来保证系统的可用性,比如引入更加丰富的监控报警系统和配套的运维人员.
分布式系统中的常见概念
应用/系统
为了完成一整套服务的一个程序或者一组相配合的程序群.一个应用就是一个/组服务器程序.
模块/组件
当应⽤较复杂时,为了分离职责,将其中具有清晰职责的、内聚性强的部分,抽象出概念,便于理解。
分布式
集群
吞吐和并发