自动化测试入门 —— 自动化测试概论
整篇论述总的来讲会很长,从自动化的思维、模型、工具,到各层次的自动化测试技术、测试框架、测试平台,包括面向未来的自动化技术都将涉及,因此打算拆成几个部分去写。此外,由于涉及的范围比较广泛,部分内容还是有些深度的,我尽量通过完整描述上下文,以便大家能够理解,如果有不清晰或错误(知识总是有限的)的地方,也请大家指正。
01. 自动化测试思维

熟悉我的读者应该知道,我习惯在写具体的应用之前,先讲思维。因为我认为任何事情首先要抓的是它的本质,了解了本质以后,再去看现象就会容易很多。可以这么说:一流的测试做思维,二流的测试做模型,三流的测试做工具(这里的“测试”是动词,不是指人,轻拍)。
一提到自动化测试体系设计,很多人的反应就是金字塔模型。但是测试理论发展到今天,金字塔模型的适用度已经不高了(后面会具体展开讲),我们不能光抱着旧模型旧思想不放。业务中需要采用什么模型,或者能够诞生出什么样的新模型,都是由自动化测试思维来指导的。很多团队将自动化应用的失败,归咎于模型的错误,这有失偏颇。有问题的不是模型,而是缺乏模型背后的思维。
什么是自动化测试思维?字面上的意思就是把测试工作做成由机器自动执行的形式,关于这点大伙应该都能理解,而问题出在想法和实践的关联上,理解并不代表会用。举个例子,大家觉得生产环境的机器监控是不是自动化测试?必须是啊,它也是通过系统的形式在解决错误验证的问题,不论是从手段还是目的上,妥妥的是自动化测试的一种。那为什么还有很多人认为它是运维的一部分呢?
所以我们在讲自动化测试的时候,不能光是局限于单元测试、接口自动化、UI 自动化,而是在方方面面上,都要思考是否可以形成自动化测试的能力,以及采用这种能力之后的投入产出比,做出综合判断,这才是自动化测试思维。至今为止,自动化测试思维最为成功的应用,我觉得有两个,一个是流量回放技术,另一个是图像识别和机器学习结合的自动化技术。先别着急,后面都会具体讲到。
02. 自动化测试模型
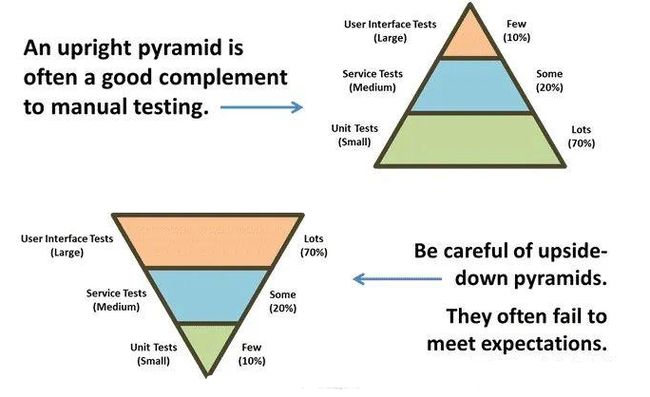
说到自动化测试模型,金字塔模型一定是一个绕不开的槛,10->20->70 的比例被奉为自动化实践的金科玉律。但现在离金字塔模型提出已经过去十几年了,现今的业务形态、测试理论、自动化技术早已发生了巨大的变化。实际一点问,诸位的团队有几个是在严格使用这个模型的?难道只是因为国内理念没跟上吗?
首先,我们要看下自动化最大的挑战是什么。我们都知道,自动化的目的是为了节约人工成本,那如果实现自动化本身要消耗的成本就很高,你还觉得它有意义吗?当然没有。所以从过去到现在,自动化的技术发展一直是在跟成本这个课题做斗争。仔细回忆一下,录制回放、流量回放、屏幕比对、图像识别等等,哪个不是为了降低自动化成本而诞生的。所以,金字塔模型的基础,是建立在受当时技术限制而采用这种模型成本最优的前提下。
但现在已经是 2023 年了,流量回放技术让 API(其实流量回放可以用于多个层面,后面再细说)自动化回归的成本接近于 0,新的基于图像识别的机器学习技术也让 UI 自动化回归的成本接近于 0,这两个技术的采用,使得模型直接演变成了纺缍形甚至是倒三角形,我们能说它不合理吗?显然不能。因此,成本才是决定这个模型是个什么“形状”的核心要素,金字塔也好,纺缍也好,倒三角也好,只要 ROI 高,都是好模型。
额外说一点,即便是金字塔,现存的图形也是画得五花八门。集成测试和接口测试混为一谈,界面测试和端到端测试混为一谈。比如端到端,其实还是对原本的“系统测试”概念做了一些扩展,对于 Paas/Iaas 型业务,端点往往不是界面而是接口,或干脆就是命令行。所以我们不能认为端到端就是界面,不是一回事。
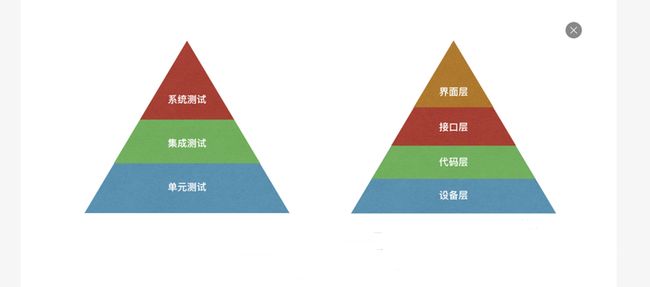
严格来说,金字塔的结构有两类:一类是基于颗粒度的,比如单元测试->集成测试->系统测试(端到端);另一类是基于层次深度的,比如设备层->编码层->接口层->界面层。这里并不是指每一层都一定存在,需要根据自己的业务具体分析。
03. 自动化测试覆盖
我们有了模型之后,是否只要根据模型每一层的“胖瘦”来决定它们的覆盖率就可以了呢?或者说在有条件的情况下,覆盖率是不是越高越好?我们习惯把各个层级的自动化单独对待,分别去制定它们的覆盖率指标,很少有人会去思考层级和层级之间的关系。考虑下面这个例子,不同的商品价格给予不同的折扣,假定业务代码如下并对外包装了一个访问接口:
public float getDiscount(float commodityPrice) {
float discount;
if (commodityPrice >= 500.0) {
discount = 0.3;
} else if (commodityPrice >= 300.0) {
discount = 0.2;
} else if (commodityPrice >= 100.0) {
discount = 0.1;
} else {
discount = 0.0;
}
return discount;
}这段逻辑不论是代码(单元)测试,或者是接口测试,实现起来都很容易,四个用例(暂不考虑边界和异常)即可搞定,所以大部分人都会追求代码测试和接口测试的自动化 100% 覆盖(代码四个+接口四个),毕竟成本不高嘛。但是从有效性来讲,冗余度高达 75%。因为业务逻辑已经在代码层做掉了,对于接口测试而言,我们只需要保证接口链路是通的即可,没有必要对各个逻辑分支再做一遍重复校验。

打个比方,我们家里用的净水器,一般会有 3~5 层的过滤网,先从泥沙等较大的物体开始,直至细菌等微小的目标,每一层都有其目的和作用。如果我们从第一层开始就采用最精细的过滤材料,势必会导致材料浪费和成本提升。
自动化分层也是这个道理,我们应当先从实现成本最低的层级(再说一次,不一定是代码层)开始,覆盖尽可能多的用例,之后根据成本排序依次对前一个层级未能覆盖的部分,结合层级本身的特点进行补充。因此,自动化分层思想其实是一个互补思想,而不要独立去看待。
需要特别提醒一点的是,不要过度相信高覆盖率。比如以下代码:
public float test(float divisor) {
return 100.0/divisor;
}我们只需要 test(10.0) 就可以达到 100% 的覆盖率,但很明显代码并未处理除数为 0 的情况,因此我们不能说 100% 的(代码)覆盖率就是无 Bug 的。所以覆盖率分业务覆盖率和代码覆盖率,对测试有效性也有很多手段可以采用,比如变异测试、混沌工程等等。由于测试有效性和自动化没有硬性关联,本文中提及相关内容时可能会略微做介绍,其他就不过多讲解了。今天关于自动化的内容暂时先讲到这,我们下周继续 : )
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!
