Java程序员面试核心知识--Java基础知识(一)

目录
一、Java程序初始化顺序
二、Java的Clone方法作用
三、 OverLoad(重载)与Override(重写)区别
四、abstract class(抽象类)与interface(接口)的异同
五、String、StringBuffer、StringBuilder区别
六、“==”、equals和hashCode的区别
七、字符串创建与存储的机制
一、Java程序初始化顺序
结论:父类静态变量->父类静态代码块->子类静态变量->子类静态代码块->父类非静态变量->父类非静态代码块->父类构造方法->子类非静态变量->子类非静态代码块->子类构造方法
代码例题,请写出下面程序的运行结果
package com.alphamilk.Example101;
class Father{
static String staticString = "a";
static {
System.out.println(staticString);
System.out.println("b");
}
public String NonString = "c";
{
System.out.println(NonString);
System.out.println("d");
}
}
class Son extends Father{
static String SonstaticString = "e";
static {
System.out.println(SonstaticString);
System.out.println("f");
}
public String SonNonString = "g";
{
System.out.println(SonNonString);
System.out.println("h");
}
}
public class javaDemo {
public static void main(String[] args) {
Son son = new Son();
}
}
二、Java的Clone方法作用
由于Java在处理基本数据类型(如int、double、char等)时候,都是采用按值传递,除此之外的数据类型都是按照引用传递方式执行。
这就会导致数据类型的备份出现问题,基本数据类型可以通过值传递快速备份,而对象引用会传递对象的地址,这样会导致对备份的操作影响到原本的数据。如下案例:
// 其它类型数据
class Person{
public String name;
public int age;
Person(String name ,int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name:"+name+" age:"+age;
}
}
public class JavaDemo {
public static void main(String[] args) {
// 基本数据类型与备份
int a = 10;
int b;
b = a;
// 对备份操作
b = 100;
System.out.println(a);
System.out.println(b);
// 其它类型与"="引用
Person person = new Person("小红",100);
Person person1 = person;
// 对备份进行操作
person1.name = "小黄";
System.out.println(person);
System.out.println(person1);
}
}
可以看到由于对象类型的“=”是引用传递,传递的是对象的地址,所以对备份的操作实际上就是对本体的操作.
所以想要使用备份就需要Object类中的Clone方法。而Object类是所有类的父类,所以可以如下实现
1.实现Cloneable接口 2.覆写Clone方法 3.调用方法
//1.实现 Cloneable 接口
class Person implements Cloneable{
public String name;
public int age;
Person(String name ,int age){
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "name:"+name+" age:"+age;
}
// 2. 实现克隆方法
public Person Clone(){
Person per = null;
try {
// 强制转型
per = (Person)super.clone();
}catch (CloneNotSupportedException e){
e.printStackTrace();
}
return per;
}
}
public class JavaDemo {
public static void main(String[] args) {
Person person = new Person("小红",100);
// 3.调用Clone()方法
Person person1 = person.Clone();
// 对备份对象进行操作
person1.name = "小黄";
person1.age=12;
// 输出对象
System.out.println(person);
System.out.println(person1);
}
}注意:上述代码克隆是在对象中仅存在基本数据类型下,这样的拷贝被称为浅拷贝。而一旦对象中还存在其它对象,则需要用深拷贝实现拷贝内容.
Clone分为浅拷贝和深拷贝
浅拷贝:仅仅拷贝对象中只存在基本数据类型
深拷贝:可以拷贝对象中包含的对象
深拷贝如下案例:
class Student implements Cloneable{
// 基本数据类型
int id;
// 其它引用对象类型Date
private Date birthDay = new Date();
public Date getBirthDay() {
return birthDay;
}
// 更改BirthDay方法
public void ChangedBirthDay(){
long intervalTime = 3600*30;
long time = birthDay.getTime();
birthDay.setTime(time+intervalTime);
}
// 覆写克隆方法
public Student Clone(){
Student student = null;
// 浅层拷贝
try {
student = (Student) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException(e);
}
// 深层拷贝
student.birthDay = (Date) this.getBirthDay().clone();
return student;
}
@Override
public String toString() {
// 输出对象
return "Student's id:"+id+" birthday is " +birthDay;
}
}
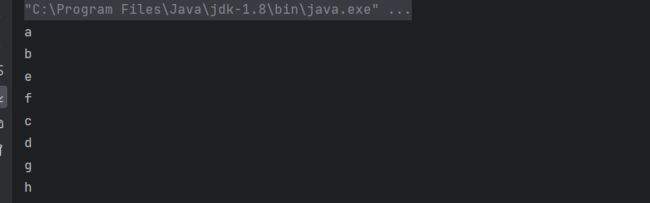
public class JavaDemo2 {
public static void main(String[] args) {
Student student1 = new Student();
student1.id = 10;
Student student2 = student1.Clone();
student2.id = 11;
student2.ChangedBirthDay();
System.out.println(student1);
System.out.println(student2);
}
深层拷贝相比与浅层拷贝,需要额外对引用对象中其它对象进行拷贝。
三、 OverLoad(重载)与Override(重写)区别
overload 与 override 都是Java多态性的不同表现,其中overload是类中多态性的显现,
Overload重载
重载指的是同一个类中有多个方法名称相同,但是参数不同的方法,因此可以在编译时候就确定具体调用哪个方法。它是一种编译时候的多态,重载可以看作一个类的多态。
Override重写
子类可以重写父类的方法,因此同样的方法在父类和子类中有着不同的表现形式,在Java语言中,基类的引用变量不仅可以指向其实现类的实例对象,也可以指向其子类的实例对象。同样,接口的引用变量中可以指向其实现类的实例对象。
案例代码:
class Person{
String race;
// 父类方法
public String printfInfo(String race){
return "种族"+race;
}
}
class Student extends Person{
int id;
String name;
// 实现构造方法重载(OverLoad)
// 1.无参构造方法
Student(){}
// 2.单参构造方法
Student(String name){
this.name = name;
}
// 3,多参构造
Student(String name ,int id){
this.name = name;
this.id = id;
}
// 覆写方法
/*
* 注意,覆写时候参数也需要一致*/
@Override
public String printfInfo(String race) {
return "种族"+race+" , 名称:"+name +" id"+id;
}
}
public class JavaDemo {
public static void main(String[] args) {
Student student = new Student("Alpha",01);
System.out.println(student.printfInfo("人类"));
}
}区别:
1.覆写是子类和父类之间的关系,是垂直关系,而重载是同一个类中方法之间的关系,是水平关系。
2.覆写只能由一个方法或者一对方法产生关系,方法的重载是多个方法之间的关系。
3.覆写要求参数列表相同,而重载要求参数列表不同。
4.覆写关系中,调用方法体是根据对象的类型(对象对应存储空间类型)来决定的,而重载关系是根据调用时的实参列表和形参列表来选择方法体的。
四、abstract class(抽象类)与interface(接口)的异同
抽象类
如果一个类中包含抽象方法,那么这个类就是抽象类。在Java中可以通过某些类或者是类中的方法声明为abstract(abstract只能用来修饰类或者方法,不能用来修饰属性)来表示一个类是抽象类。只要包含一个抽象方法的类就必须声明为抽象类,抽象类可以仅仅申明方法的存在而不去实现它,被声明为抽象的方法不能包含方法体。在实现的时候,必须包含相同的或者更低的访问级别(public -> protectd ->private ).抽象类在使用的过程中不能被实例化,但是可以创建一个对象使其指向具体子类的一个示例,抽象类的子类为父类中所有的抽象方法提供具体的实现。否则子类也将是抽象类。
接口
接口就是一个方法的集合,在Java中,接口是通过关键字interface来实现的,在Java8之前,接口中既可以定义方法也可以定义变量,其中变量必须是public、static、final的。而且方法必须是public abstract 的。由于这些修饰符都是默认的。
在Java8之后,可以通过关键字default给接口中的方法添加默认实现,此外接口中还可以定义静态方法。
案例代码:
interface category{
// 输出物种信息
public void printInfo();
}
interface Breath{
// 生物进行呼吸
public void Breath();
}
abstract class behavior{
// 定义抽象方法
public abstract void shout();
// 定义普通方法
public void jump(){
System.out.println("进行跳跃");
}
}
//只能继承一个抽象类
//但是能继承多个接口
class Person extends behavior implements Breath,category{
// 覆写抽象类中的抽象方法
@Override
public void shout() {
System.out.println("人类进行嚎叫");
}
// 实现接口category中的方法
@Override
public void printInfo() {
System.out.println("种族,人类");
}
// 实现接口Breath方法
@Override
public void Breath() {
System.out.println("呼吸类型:有氧呼吸与无氧呼吸");
}
}
public class JavaDemo {
public static void main(String[] args) {
Person person = new Person();
// 执行覆写的方法
person.printInfo();
person.Breath();
person.shout();
}
}不同点
抽象类
- 抽象类只能被继承(通过extend),并且一个类只能继承一个抽象类。
- 抽象类强调所属关系,其设计理念为is-a关系。
- 抽象类更倾向于充当公共类的角色,不适与日后重新对立面的代码进行修改。
- 除了抽象方法以外,抽象类中还可以包含具体数据和具体方法(可以由方法的实现)。
- 抽象类不能被实例化,其子类如果实现了继承中抽象类中的抽象方法后可以,实例化子类,否则子类也是抽象类不能被实例化。
接口
- 接口需要通过实现(implements),一个类可以实现多个接口。
- 接口用于实现比较常用的功能,以便于日后的维护和方法的增删。
- 接口不是类,而是一种对类的一组需求描述,这些类需要遵循接口描述的统一格式进行定义。
- 接口中所有的方法都是public的,因此,再实现接口的类中必须把方法声明为public,因为默认类中访问属性是包可见的。而不涉及public,这就相当于在子类中降低了方法的可见性,会导致编辑错误。
五、String、StringBuffer、StringBuilder区别
在Java中,可以操作字符串的有几大类,包括String、StringBuffer、StringBuilder。
String是不可变类,也就意味着一旦String对象一旦创建,其值无法被改变,而StringBuffer是可以改变的。所以当一个字符串需要经常修改的时候,最好用StringBuffer来实现。因为不可变类,其值在修改的时候,其实原来的数据并没有被删除,而是堆上创建了一个新的不可变类String的对象,并且栈上对象指向了新的对象,所以如果字符串大量修改的话,就会产生大量的浪费资源的无用对象。最后被垃圾回收器回收。虽然这在小的项目里影响微乎其微,但是在大项目中是会有非常大的效率问题。
StringBuilder也是可以被修改的字符串,与StringBuffer相似,都是字符串的缓冲区,但是StringBuilder是线程不安全的。如果只是在单线程的情况下进行操作,那么StringBuilder的效率是最快的。而多线程使用的时候StringBuffer使用是最好的。因为StringBuffer在有需要的时候可以进行方法的同步。
String与StringBuffer还有一点不同是在于初始化对象上,String有两种初始化方式第一种是直接赋值,第二种是通过构造函数赋值,而StringBuffer只能通过构造函数创建对象。
使用的案例代码:
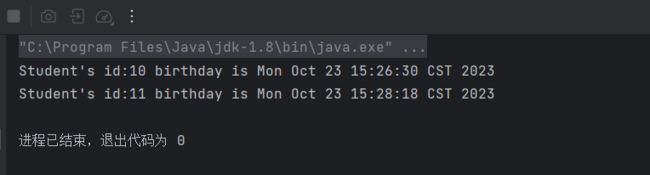
public class JavaDemo {
public static void main(String[] args) {
// 创建有序map,查看效率排名
Map map = new TreeMap<>();
// String的两种初始化对象方式
String a ="String A";
String b =new String("String B");
// StringBuffer唯一初始化对象方式
StringBuffer buffer = new StringBuffer("String C");
// StringBuilder初始化方式
StringBuilder builder = new StringBuilder("String D");
// 单线程下分别测试效率
// String字符串
long start = System.currentTimeMillis();
for (int i = 0;i<10000;i++){
a = a + "Add String";
}
long end = System.currentTimeMillis();
long internal1 = end - start;
map.put(internal1,"String类型运行时间");
// StringBuffer
long start2 = System.currentTimeMillis();
for (int i=0;i<10000;i++){
// 调用StringBuffer内方法append,即添加字符串
buffer = buffer.append("Add String");
}
long end2 = System.currentTimeMillis();
long internal2 = end2 - start2;
map.put(internal2,"StringBuffer类型运行时间");
// StringBuilder
long start3 = System.currentTimeMillis();
for (int i=0;i<10000;i++){
builder = builder.append("Add String");
}
long end3 = System.currentTimeMillis();
long internal3 = end3 - start3;
map.put(internal3,"StringBuilder类型运行时间");
System.out.println(map);
}
} 可以多次运行代码或者提高循环次数,查看平均值
单线程保证线程安全下 效率速度: StringBuilder>StringBuffer>String
六、“==”、equals和hashCode的区别
“==”运算符在基本数据类型中是用于判断两个变量的值是否相同,但是如果两个变量是引用数据类型,那么“==”就是两个变量对应的引用地址的比较。
equals是Object类中提供的方法,由于所有类都继承了Object主类,所以所有对象都是可以调用equals方法。相比于“==”运算符,equals方法的特殊之处就是在于它是可以被覆盖的,也就意味着它并不是比较引用的地址,而是比较对象中的属性。
hashCode方法是从Object类中继承过来的,他也是用来鉴定两个对象是否相等。Object类中的hashCode()方法返回对象在内存中的地址并转换成一个int值,所以如果没有重写hashCode()方法,任何对象的hashCode方法都是不相等的。也即是哈希值唯一的。
请你写出下面程序的执行结果:
class Person{
String name;
Person(String name){
this.name = name;
}
}
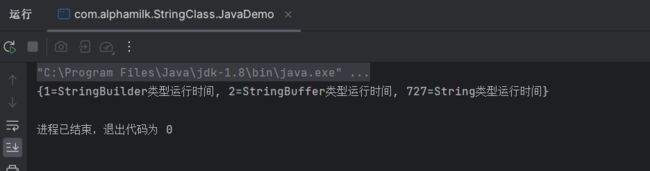
public class JavaDemo {
public static void main(String[] args) {
String a = new String("content");
String b = new String("content");
String c = "content";
String d = "content";
System.out.println("1:"+ (a==b));
System.out.println("2:"+a.equals(b));
System.out.println("3:"+(c == b));
System.out.println("4:"+ (c == a));
System.out.println("5:"+ (d == c));
int base1 = 1 ,base2 = 1;
Integer integer = 1;
Integer integer1 = 1;
System.out.println("6:"+ (base1==base2));
System.out.println("7:"+ integer1.equals(integer));
Person person = new Person("张三");
Person person1 = new Person("张三");
System.out.println("8:"+(integer.hashCode() == integer1.hashCode()));
System.out.println("9:"+(c.hashCode() == a.hashCode()));
System.out.println("10:"+(person.hashCode() == person1.hashCode()));
}
}
注意:
9:true 解释 --String类是一个特殊的类,它有一个特殊的属性,即字符串常量池(String Pool)。当我们使用字面量创建字符串时,例如String c = "content",Java会首先检查字符串常量池中是否已经存在相同内容的字符串,如果存在,则直接返回该字符串的引用;如果不存在,则在常量池中创建一个新的字符串对象,并返回其引用。因此,在这段代码中,虽然
a和b是通过new关键字创建的两个不同的字符串对象,但它们的内容相同。而c和d则是通过字面量创建的字符串,它们的内容也相同。由于字符串常量池的存在,c和d实际上是指向同一个字符串对象的引用,因此它们的地址是相同的。10:true解释 --对于
Integer类型的对象,Java在内部维护了一个缓存池,用于缓存-128 ~ 127之间的整数对象。当我们通过Integer.valueOf()方法创建一个整数对象时,如果该整数在缓存池中已经存在,则直接返回该整数对象的引用;否则,在堆内存中创建一个新的整数对象,并将其加入到缓存池中,然后返回其引用。
七、字符串创建与存储的机制
在Java语言中,对String对象提供给了专门的存储机制。
public class StringPool {
public static void main(String[] args) {
// 第一种存储
// 将abc放到常量区abc,在编译时候产生
String s = "abc";
// 将ab与c转为字符串常量“abc”并存在常量区
String s1 = "ab"+"c";
// 第二种存储
// 在堆中创建新的对象,堆中对象指向常量区
String s2 = new String("abc");
String s3 = new String("abc");
// 分别输出四个常量地址
System.out.println("s地址"+s.hashCode());
System.out.println("s1地址"+s1.hashCode());
System.out.println("s2地址"+s2.hashCode());
System.out.println("s3地址"+s3.hashCode());
}
}
第一种存储String s = "abc"
在当创建一个字符常量的时候,会首先在字符串常量池中进行查找是否已经有相同的字符串常量。具体原理就是通过调用方法equals方法进行一 一匹配 ,如果不存在则需要先进行创建一个对象,然后将其加入字符串池中,再将它引用返回。而如果存在的话,直接获取对其的引用。而能够设置一个常量池的原因在于String类是一个不可变类,无法对其进行修改,日常对其进行修改本质是创建了一个新的字符串。
第二种存储String s1 = new String("abc");
有区别第一种,第二种存储需要对其操作进行拆分,其多了一个new操作,这个操作是在堆上创建一个对象,并将值存放在堆中。是独立进行存储的,与常量池无关。
从分析中可以看出,在创建字符串对象时候,会根据不同的情况来确定字符串是存储在堆中还是常量池中。而intern方法就是用于将字符串存入常量池中。 所以通过intern方法可以将new关键字创建堆内的字符串对象存入字符串常量池中。
但是要注意的是intern方法随着JDK的更新,方法也随着更新。以下是其JDK1.6以下和JDK1.7以后的一些区别。
- 在 JDK 1.6 及之前的版本中,调用
intern()方法会将字符串复制一份到字符串常量池,并返回字符串常量池中的引用。如果字符串常量池中已经存在相同值的字符串,intern()方法会返回常量池中的引用;否则,会在常量池中创建一个新的实例并返回该引用。- 而在 JDK 1.7 及之后的版本中,调用
intern()方法会检查字符串常量池中是否存在相同值的字符串。如果存在,则返回常量池中的引用;如果不存在,则将字符串的引用直接存储到字符串常量池中,并返回该引用。换句话说,对于 JDK 1.7 及之后的版本,如果原始字符串已经在常量池中存在,调用intern()方法不会创建新的实例,而是直接返回常量池中的引用。