【Go】Go语言数据类型
文章目录
- 一、为什么要为数据区分类型?
- 二、Go语言中有哪些数据类型?
-
- 1. 基本数据类型:
-
- (1)数值型
- (2)字符型(byte和rune类型)
- (3)字符串类型
-
- 字符串定义
- 字符串转义符
- 多行字符串
- 字符串的常用操作
- (4)布尔型
- 2. 派生数据类型:
-
- - 聚合类型
-
- (1)数组(array)
- (2)结构化类型(struct)
- - 引用类型
-
- (1)指针类型(Pointer)
- (2)切片类型(slice)
- (3)Map 类型
- (4)函数类型(func)
- (5)Channel 类型
- - 接口类型(interface)
- 三、值类型和引用类型
- 四、大佬的奇妙总结,来自Rayjun
- 五、总结:Go语言 "内置"类型和函数
-
- 1. 内置类型
- 2. 内置函数
- 3. 内置接口 error
- 参考链接
一、为什么要为数据区分类型?
数据类型的出现是为了把数据分成所需 内存大小不同 的数据,编程的时候需要用大数据的时候才需要申请大内存,就可以 充分利用内存 。
在 Go 编程语言中,数据类型用于声明函数和变量。
二、Go语言中有哪些数据类型?

如图,Go的数据类型分为基本数据类型与复杂数据类型(派生数据类型)。
1. 基本数据类型:
(1)数值型
Go 的数值型数据主要是 整型 数字 int 和 浮点型 数字float,并且支持 复数 ,其中位的运算采用补码。
(1)整型

整型分为两个大类:
按长度分为:int8、int16、int32、int64,
对应的无符号整型:uint8、uint16、uint32、uint64
其中,uint8 就是我们熟知的 byte 型,int16 对应C语言中的short 型,int64 对应C语言中的 long 型。
(2)浮点型和复数

- 浮点型
Go语言支持两种浮点型数:float32 和 float64 。
这两种浮点型数据格式遵循IEEE 754标准:
- float32 的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。
- float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
- 复数
Go原生支持复数:complex64 和 complex128
复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
其实字符型也算是数值型数据的一种:(具体原因你会在介绍字符时理解)
(3)字符:byte,rune(这个会在后面详细介绍)

int uint的大小与使用者的电脑操作系统位数有关。
多一嘴 ( 不指定时的默认情况 ) :
(1)Golang中,如果变量没有显式声明为何种整数类型,则默认为int类型:
func main() {
//没有显式声明数据类型
var num = 123
//显式声明数据类型
var num2 int = 123
fmt.Printf("num的类型为%T\n", num)
fmt.Printf("num的类型为%T\n", num2)
}
输出结果:
num的类型为int
num的类型为int
(2)Golang中,如果没有显式声明何种浮点数类型,则默认为float64:
func main() {
//没有显式声明数据类型
var num = 20.19
//显式声明数据类型
var num2 float64 = 20.19
fmt.Printf("num的类型为%T\n", num)
fmt.Printf("num的类型为%T\n", num2)
}
输出结果:
num的类型为float64
num的类型为float64
(2)字符型(byte和rune类型)
使用单引号 ’ ’ 定义字符型数据,字符指的是单个字符。有两种字符 byte 和 rune :
byte:单字节字符,是 uint8(无符号8位整型) 的别名。用于存储 ASCII 字符集 字符,一个 byte 代表了ASCII码的一个字符。
rune:多字节字符,是 int32 (有符号32位整型)的别名。用于存储 unicode 字符集 字符。一个 rune 代表了一个 UTF-8 字符。
当需要处理 中文、日文或者其他复合字符 时,则需要用到 rune 类型。rune 类型实际是一个 int32。 Go 使用了特殊的 rune 类型来处理 Unicode,让基于 Unicode 的文本处理更为方便。
在类型推导时,推导的字符型为 rune。(就是说,如果声明变量时,不明确声明变量类型,例如通过赋值表达式的方式给变量赋一个字符,那么系统在自动推导其数据类型时,会推导为rune)
byte需要在定义变量时强制声明,见下面的程序。
字符的默认值是0。字符的本质就是整数型,根据字符集得到对应的字符。
另一个大佬的解释:
字符常量是用单引号 ’ ’ 括起来的单个字符。
Golang 中没有专门的字符类型,如果要存储单个字符(字母),一般使用 byte 来保存 (如果我们保存的字符对应码值大于 255,这时我们可以考虑使用 int 类型保存)。
由于字符型是用 byte 存储的,相当于 uint8 ,直接输出的话会输出整型,需要格式化输出(%c)才能输出字符:
func main() {
var b1 byte = 'a'
var b2 byte = 'b'
var b11 byte = 97
var b22 byte = 98
//Go中允许使用转义字符'\’来将其后的字符转变为特殊字符型常量
var b3 byte = '\n'
//字符对应码值大于 255,这时我们可以考虑使用int类型保存
var b4 int = '国'
//直接输出的话,是整型(字符的ASCII码值)
fmt.Println(b1, b2)
fmt.Println(b11, b22)
//需要使用格式化字符输出,才能输出字符
fmt.Printf("%c%c\n", b1, b2)
fmt.Printf("%c%c\n", b11, b22)
fmt.Printf("%c", b3)
fmt.Printf("%c\n", b4)
}
输出结果:
97 98
97 98
ab
ab
国
说明:
1)在 Go 中,字符的本质是一个整数,直接输出时,是该字符对应的 UTF-8 编码的码值。
2)可以直接给某个变量赋一个数字,然后按格式化输出时 %c ,会输出该数字对应的 unicode 字符。
3)字符类型是可以进行运算的,相当于一个整数,因为它都对应有 Unicode 码。
在这里引出一点字符串的知识:(读(3)的时候可以和这里串起来)
字符串也是 Go 中的一个数据类型,字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由单个字节连接起来的。也就是说对于传统的字符串是由字符组成的,而 Go 的字符串不同,它是由字节组成的(因为在 Go 中,字符串是由字符连接起来的,而单个字符是由单个字节存储的)。
使用 byte 型进行默认字符串处理,性能和扩展性都有照顾:
// 遍历字符串
func traversalString() {
s := "pprof.cn博客"
for i := 0; i < len(s); i++ { //byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}
输出结果:
112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 229(å) 141() 154() 229(å) 174(®) 162(¢)
112(p) 112(p) 114(r) 111(o) 102(f) 46(.) 99(c) 110(n) 21338(博) 23458(客)
因为 UTF8 编码下一个中文汉字由3~4个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte数组,所以可以和 []byte 类型相互转换。字符串是不能修改的,字符串是由 byte 字节组成,所以字符串的长度是 byte 字节的长度。 rune 类型用来表示 utf8 字符,一个rune字符由一个或多个byte组成。
硬性修改字符串:
如果一定要修改字符串,需要先将其转换成 []rune或 []byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
实例:
package main
import (
"fmt"
)
func main() {
s1 := "hello"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'H'
fmt.Println(string(byteS1))
s2 := "博客"
runeS2 := []rune(s2)
runeS2[0] = '狗'
fmt.Println(string(runeS2))
}
输出结果:
Hello
狗客
(3)字符串类型
字符串定义
Go 原生支持字符串 string 。
Go语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。
字符串就是一串固定长度的字符连接起来的字符序列。Go 的字符串是由 单个字节 连接起来的(因为字符串是由单个字符连接起来的,Go中的单个字符是由单个字节保存的)。Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。
组成每个字符串的元素叫做 “字符”(我们在(2)中已经做过介绍),可以通过遍历或者单个获取字符串元素获得字符。 字符是用单引号(’)包裹起来的。
字符串 的值为 双引号 (")中的内容:
func main() {
//字符串能识别转义字符\n
var str1 string = "Hello,world\n"
fmt.Printf(str1)
}
输出结果:
Hello,world
由于 Go 语言的字符串的字节使用 UTF-8 编码标识 Unicode 文本。所以可以在Go语言的源码中直接添加非ASCII码字符,例如:
package main
import (
"fmt"
)
func main() {
s1 := "hello\n"
s2 := "你好\n"
fmt.Printf(s1)
fmt.Printf(s2)
}
输出结果:
hello
你好
字符串使用注意事项:
1)字符串一旦定义则不可改变,不能去修改字符串中的字符(如果要修改请参考(2)中的方法)
2)利用 “+” 运算符可以实现字符串拼接(多个字符串需要跨行拼接时,每行要以符号“+”结尾)
字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义 | 含义 |
|---|---|
| \r | 回车符(返回行首) |
| \n | 换行符(直接跳到下一行的同列位置) |
| \t | 制表符 |
| \’ | 单引号 |
| \" | 双引号 |
| \ | 反斜杠 |
举个例子,我们要打印一个Windows平台下的一个文件路径:
package main
import (
"fmt"
)
func main() {
fmt.Println("str := \"c:\\pprof\\main.exe\"")
}
输出结果:
str := "c:\pprof\main.exe"
多行字符串
Go语言中要定义一个多行字符串时,就必须使用 反引号 字符:
package main
import (
"fmt"
)
func main() {
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
}
输出结果:
第一行
第二行
第三行
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
字符串的常用操作
| 方法 | 介绍 |
|---|---|
| len(str) | 求长度 |
| + 或 fmt.Sprintf | 拼接字符串 |
| strings.Split | 分割 |
| strings.Contains | 判断是否包含 |
| strings.HasPrefix,strings.HasSuffix | 前缀/后缀判断 |
| strings.Index(),strings.LastIndex() | 子串出现的位置 |
| strings.Join(a[]string, sep string) | join操作 |
(4)布尔型
Go语言中以 bool 类型进行声明布尔型数据,布尔型数据只有 true(真)和 false(假)两个值。
布尔型的值只可以是常量 true 或者 false。
一个简单的例子:var b bool = true。
布尔型主要应用于 if 条件分支语句,for循环控制语句。
func main() {
var b1 bool = true
fmt.Printf("b1的数据类型为%T\n", b1)
}
输出结果:
b1的数据类型为bool
注意事项:
-
布尔类型变量的默认值为false。
-
Go 语言中不允许将整型强制转换为布尔型。
-
布尔型无法参与数值运算,也无法与其他类型进行转换。
2. 派生数据类型:
复杂数据类型又分为聚合类型、引用类型和接口类型:
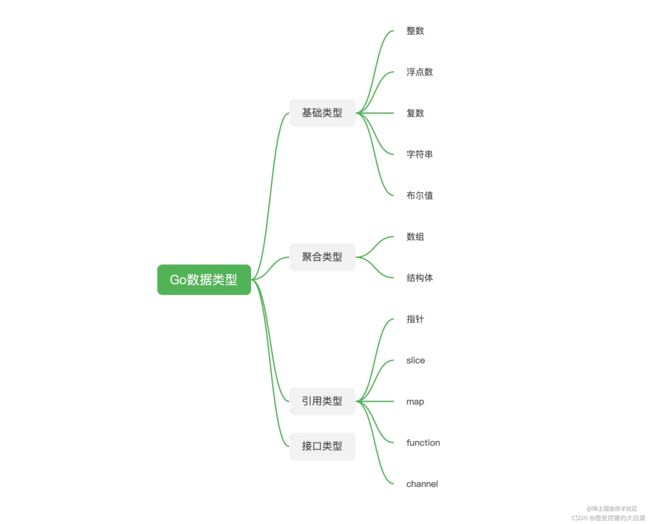
- 聚合类型
聚合类型的值由内存中的一组变量构成。
聚合类型包括数组和结构体,数组和结构体的长度都是固定的。
数组中的元素类型必须都相同,而结构体中的元素可以不同。
数组和结构体都是 值类型 的数据结构。
(1)数组(array)
数组是一段长度固定的连续内存区域,拥有0 个或多个(不超过数组长度)相同数据类型的数据项序列。其中元素类型支持任意内置类型,这种类型可以是任意的原始类型例如整型、字符串或者自定义类型。
数组在声明(使用 [长度]类型 进行声明)的时候必须指定长度,可以修改数组元素,但是不可修改数组长度。
数组元素可以通过索引(位置)来读取(或者修改),索引从 0 开始,第一个元素索引为 0,第二个索引为 1,以此类推。
数组的声明:
Go 声明数组需要指定元素类型及元素个数,一维数组的声明,语法格式:
var name [SIZE]type
多维数组的声明:
var name [SIZE1][SIZE2]...[SIZEN]type
更多详细讲解请参考我的另一篇文章:【Go】Go语言 数组
(2)结构化类型(struct)
结构体是由任意个任意类型的 变量 组合在一起的数据类型,和其他语言中类的概念相似。
Go语言使用结构体来描述现实业务逻辑中实体。是自定义类型。
结构体是由一系列数据构成的数据集合,一系列数据类型可以不同。
定义结构体,使用struct关键字: type 结构体名 struct { 成员1 类型 成员2 类型 … }
type Student struct {
Name string
age int
}
Go 语言是一个面向对象的语言,但却又抛弃了 Java 中类和对象的概念,结构体是 Go 语言实现面向对象的基础之一,还有一部分是接口,下面会聊到。
在 Go 的面向对象中,已经摒弃了继承的概念,但在结构体中,通过结构体嵌套,也算是实现了部分继承的功能。
结构体的可比较性也取决于其中变量的可比较性。
- 引用类型
引用是另外一种数据类型,很多 Go 语言的高级功能都依赖引用。引用都间接指向变量或者状态,通过引用来操作数据会让该数据的全部引用都受影响。
Go 语言中的引用类型光声明是不能使用的,还要初始化(分配内存)才能使用,详情请见【Go】Go语言中的 new 和 make 函数。
(1)指针类型(Pointer)
指针是一种数据类型,指针的值是一个变量的地址。对于一个变量来说,可以有多个指针,通过其中任意一个指针来修改数据,通过其他指针也会获取到最新修改的值。
指针是可比较的。
指针类型用于存储变量地址。使用运算符 & , *完成操作。
使用运算符&可以获取变量的地址。
指针的数据格式类似0xc0000b9528,是一个内存地址的16进制表示。
使用运算符 *可以获取指针所指向的变量的值。
(2)切片类型(slice)
slice 是一个拥有 相同元素 的 可变长度 序列。 slice 看起来与数组很像,但本质上不同。(切片也被称之为动态数组,因为元素相同而长度可变)
slice 依赖数组,没有数组,就没有 slice。它通过内部指针和相关属性引用数组片段,以实现变长方案。
一个 slice 有三个属性,指针,长度和容量。其中指针指向数组中的某个元素(不一定是第一个),这是 slice 可以访问的第一个元素。
长度是 slice 中元素的个数,不能超过容量,容量通常是指 slice 指针的位置到底层数组的最后一个元素的位置的长度。
slice 不可比较, 只能和 nil 比较。
可以从数组或切片生成新切片: slice [开始索引:结束索引]
slice 表示目标切片对象。
开始索引和结束索引对应目标切片的索引,不包含结束索引对应的元素。
若缺省开始索引,表示从头到结束索引。
若缺省结束索引,表示从开始索引到末尾。
两者同时缺省时,全部切取,与切片本身等效。
两者同时为0时,等效于空切片,一般用于切片复位。
以从数组创建切片为例,理解切片:

切片的实现是由一个底层数组以及其上面的动态位置、尺寸来实现。内部由指向起始元素的指针、元素数量 length 和容量 capacity 组成。其中: 指针 ptr,用于指向切片在底层数组的起始位置。 尺寸len,用于记录切片内元素数量。 容量cap,当前切片最大容量,也就是底层数组的容量。可以动态分配。
切片为引用类型。 切片的默认初始值为nil。
切片支持: len() 尺寸, cap() 容量, append() 追加元素等操作。
(3)Map 类型
(1)简介
Map(映射)是一种无序的键值对(key->value)的集合。Map 最重要的一点是通过 key 来快速检索数据,key 类似于索引,指向数据的值。其中,map 的 key 必须是可比较的,如果 key 不可比较,那就无法通过 key 查询到响应的 value,value 的类型是没有限制的,可以是任意值。
Map 是一种集合,所以我们可以像迭代数组和切片那样迭代它。不过,Map 是无序的,我们无法决定它的返回顺序,这是因为 Map 是使用 hash 表来实现的。
(2)声明(不初始化)
可以使用map 关键字和内建函数 make 来定义 Map:
/* 声明变量,默认 map 是 nil */
var mapname map[key_type]value_type
/* 使用 make 函数创建一个空的map */
mapname := make(map[key_type]value_type)
或
var mapname = make(map[string]string)
如果不初始化 map,那么就会创建一个 nil map。nil map 不能用来存放键值对。
(3)声明的同时初始化
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
(4)删除map内的元素
delete() 函数用于删除集合的元素, 参数为 map 和其对应的 key。实例如下:
countryCapitalMap := map[string]string{"France": "Paris", "Italy": "Rome", "Japan": "Tokyo", "India": "New delhi"}
/*删除元素 "France": "Paris"*/
delete(countryCapitalMap, "France")
(4)函数类型(func)
function 就是函数,在写 Go 的 helloworld 程序时,就会用到函数。
函数实际上也是一种数据,他们具有自己的值和类型。
函数是一种引用类型。
function 本身不可比,只能和 nil 比较,但是可以通过反射获取函数指针进行比较。
Go语言中,函数可以作为数据存储变量,此时变量为函数类型func()。可以通过该变量访问到这个函数。
在结构体上定义一个函数就变成了Go语言中的另一个概念——方法。
(5)Channel 类型
Go 语言天然支持搞并发,而 channel 就是其中关键一环。
goroutine 用来并发执行任务,而 channel 则用来连接不同的 goroutine。(goroutine和channel是Go并发的两大基石)
channel 也是属于引用类型。
channel 是可比较的。
- 接口类型(interface)
-
介绍
接口是 Go 实现面向对象的关键。
Go 的接口类型很特别,你不需要去显式的实现一个接口,只要把接口中的方法实现,就默认实现了这个接口。
接口类型是可比较的。
接口是一种协议(Protocol),用来规范方法的定义和调用的协议,目的是保证设计的一致性,便于模块化开发以及通讯。 -
定义接口
每个接口类型由数个方法组成。接口的形式代码如下:type 接口名 interface{ 方法名1( 参数列表1 ) 返回值列表1 方法名2( 参数列表2 ) 返回值列表2 … }说明:
接口名:Go语言的接口在命名时,一般会在单词后面添加 er,如有写操作的接口叫 Writer,有字符串功能的接口叫 Stringer,有关闭功能的接口叫 Closer 等。
方法名:当方法名首字母是大写时,且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以被忽略。
三、值类型和引用类型
-
值类型
所有像 int、float、bool 和 string 这些基本类型都属于值类型,除此之外,数组和结构体这两个聚合类型也是值类型。使用值类型的变量直接指向存在内存中的值。当使用等号 = 将一个变量的值赋值给另一个变量时,如:j = i,实际上是在内存中将 i 的值进行了拷贝(拷贝值,深拷贝)。
你可以通过 &i 来获取变量 i 的内存地址,例如:0xf840000040(每次的地址都可能不一样)。值类型的变量的值存储在栈中。内存地址会根据机器的不同而有所不同,甚至相同的程序在不同的机器上执行后也会有不同的内存地址。因为每台机器可能有不同的存储器布局,并且位置分配也可能不同。
-
引用类型
更复杂的数据通常会需要使用多个字,这些数据一般使用引用类型保存。引用都间接指向变量或者状态,通过引用来操作数据会让该数据的全部引用都受影响。很多 Go 语言的高级功能都依赖引用。Go 语言中的引用类型见前述五种:指针、切片、map、函数、channel。
与值类型不同,Go 语言中的引用类型光声明是不能使用的,还要初始化(分配内存)才能使用,详情请见【Go】Go语言中的 new 和 make 函数。
一个引用类型的变量 r1 存储的是 r1 的值所在的内存地址,或内存地址中第一个字所在的位置。这个内存地址称之为指针,这个指针实际上也被存在另外某一个值中。同一个引用类型的指针指向的多个字可以是在连续的内存地址中(内存布局是连续的),这也是计算效率最高的一种存储形式;也可以将这些字分散存放在内存中,每个字都指示了下一个字所在的内存地址。
当使用赋值语句 r2 = r1 时,只有引用(地址)被复制(拷贝地址,浅拷贝)。
如果 r1 的值被改变了,那么这个值的所有引用都会指向被修改后的内容,在这个例子中,r2 也会受到影响。
关于深拷贝和浅拷贝的具体内容,请参见我的另一篇文章:【Go】深拷贝与浅拷贝
四、大佬的奇妙总结,来自Rayjun
Go 的数据类型设计简洁,但扩展性很好,开发者可以根据自己的需要动态的扩展数据,不只是对于结构体这种聚合数据类型,即使对于基础数据类型,也可以根据需要进行扩展。
另外 Go 自带对 JSON、xml 以及 Protocol Buffer 的支持,不需要引入外部的库,这就使得写程序时会很轻量级,可以尽可能少的引入依赖包。
五、总结:Go语言 "内置"类型和函数
这节的重点在于Go的 内置 !
1. 内置类型
(1)值类型:
bool
int(32 or 64), int8, int16, int32, int64
uint(32 or 64), uint8(byte), uint16, uint32, uint64
float32, float64
string
complex64, complex128
array --固定长度的数组
(2)引用类型:(指针类型)
slice --序列数组(最常用)
map --映射
chan --管道
2. 内置函数
Go 语言拥有一些 不需要进行导入操作 就可以使用的内置函数。它们有时可以针对不同的类型进行操作,例如:len、cap 和 append,或必须用于系统级的操作,例如:panic。因此,它们需要直接获得编译器的支持。
append -- 用来追加元素到数组、slice中,返回修改后的数组、slice
close -- 主要用来关闭channel
delete -- 从map中删除key对应的value
panic -- 停止常规的goroutine (panic和recover:用来做错误处理)
recover -- 允许程序定义goroutine的panic动作
real -- 返回complex的实部 (complex、real imag:用于创建和操作复数)
imag -- 返回complex的虚部
make -- 用来分配内存,返回Type本身(只能应用于slice, map, channel)
new -- 用来分配内存,主要用来分配值类型,比如int、struct。返回指向Type的指针
cap -- capacity是容量的意思,用于返回某个类型的最大容量(只能用于切片和 map)
copy -- 用于复制和连接slice,返回复制的数目
len -- 来求长度,比如string、array、slice、map、channel ,返回长度
print、println -- 底层打印函数,在部署环境中建议使用 fmt 包
3. 内置接口 error
type error interface { //只要实现了Error()函数,返回值为String的都实现了err接口
Error() String
}
参考链接
- 菜鸟教程 | Go 语言数据类型
- Golang学习之基本数据类型
- 一文看懂 Go 的数据类型
- Go语言的数据类型
- Golang内置类型和函数
- 基本类型