探究跨域问题(同源策略、跨域问题解决方案(未写详细配置方法只说了思路)、提出问题及探究结果);js以及回调函数的探究、一个完整的URL及参数讲解
1.为什么可以通过callback拿到异步数据,如何理解回调函数?
开始的时候就知道回调函数能拿到异步数据,但是一直不是很确定他拿到数据的方法,今天看了一个博主的解释很好,其实很好理解,回调函数字面意思就是回头再调用,callback字面意思就是打回来,回调函数一般是有个基本条件,将一个函数作为参数传递给另一个函数,比如函数A作为参数传递给函数B,那么A就是B的回调函数
2.那么回调函数有什么用?以及为什么可以拿到异步数据呢?
回调函数可以保证我们函数的执行,比如你想先打印 1 再打印2,如果1是一个耗时操作,根据js的事件循环我们知道,结果会是2 1,因为耗时操作也就是异步操作会被抛给游览器等待执行,但是如果将打印2作为打印1函数的回调就能保证函数的执行顺序,始终是 1 2,那么第二个为什么他可以拿到异步数据呢?这里我一直有个误区,我以为回调函数也是异步任务,所以可以拿到异步数据,其实不然,回调函数是一个同步任务,但是由于他放在了异步任务里面,虽然他是同步代码但是包裹他的是一个异步任务,相当于是明天再做,即使同步今天也没法体现,还没轮到他,就像下面示例的代码,callback()是一个同步任务,但是放在了setTimeout这个异步的方法里面了,所以他不会立马执行,等待执行异步任务的时候,立马有两个同步任务一个console(1)一个是调用callback函数,这也是他为什么能拿到异步数据的原因,就相当于你去一个咖啡店点单,因为做咖啡是一个耗时的过程,你肯定不能点完一个咖啡立马就获得,那你没办法,你留下了你的电话号码,然后去逛街,等好了就叫他callback,如此等待的时间就能拿来逛街了,这里留下的电话号码就是callback()函数,只有当咖啡做好了才去打你的电话,就相当于调用函数,电话号码就是你写好的函数,店员打给你就是执行他。
代码示例:
function print1(){
console.log(1)
}
function print2(){
console.log(2)
}
耗时操作:
function print1(){
setTimeout(()=>{
console.log(1)
},500)
}
函数作为参数(保证函数的执行顺序):
function print1(callback){
setTimeout(()=>{
console.log(1)
callback()
},500)
}
function print2(){
console.log(2)
}
print1(print2)3.为什么JavaScript是单线程的?
因为JavaScript的主要用途是和用户互动和操作DOM的,如果用户添加一个信息然后再去删除,肯定是先生成这个信息才能去进行删除操作的,单线程的操作代步同时时间只能进行一件事,那么有些任务是非常耗时的,会阻塞代码的执行,比如你在看一个打开一个视频的时候,可能视频加载需要时间,但是你依旧可以进行点赞和投币操作的,所以我们把代码又分成了同步代码和异步代码,同步代码是会立即加入JS引擎(js主线程)执行,并且会原地等待,而异步代码是先放入宿主环境中(一般是游览器环境来处理异步任务),不必等待,不阻塞主线程,异步结果将来执行
4.什么是宏任务?什么是微任务?
代码分为同步代码和异步代码,异步代码又分为宏任务和微任务
宏任务包括:script(整体代码)、seTimeout、setInterval、setImmediate、I/O(Ajax的请求和数据传给后台都是宏任务)等
微任务:promise.then() catch() (promise本身是同步的,异步的是他的then和catch)process.nextTick()(node)、async/await、object.observe等等
下图解释什么是js的事件循环,同时也解释为什么会有事件循环:

跨域问题:
跨域问题是基于游览器的,由于游览器的同源策略的存在,首先介绍什么是同源策略,同源策略是游览器的一个重要安全策略,源是由协议、主机名、端口号组成的,一般前端在请求后台数据的时候都需要配置接口,我们请求的接口其实就是由Baseurl+接口名称组成的,那么Baseurl是什么呢?这是我喜欢叫的一个名称,比如我需向http://test.yee.com/auth/role/list地址请求我需要的数据,那么我们

分析一个这个url,前面的是协议名,我们一般见的比较多的就是http和https,接下来就是域名(主机名),域名(主机名)就是我们请求资源的地方,可以理解成为我们提供资源的ip,如果是自己测试的时候,自己在本地写了个服务器提供数据,那么这个域名(主机名)ip就是我们自己的计算机ip,通俗来说就是给我们资源的地址,后面虚拟目录部分就是前端接触比较多的地方,这个就是我们在API中配置的接口地址,其实完全可以类比成本地目录来理解,由于网络请求存在安全性和验证等问题的存在,所以前面多了协议,其实协议+域名(主机名)理解成本地目录就是根目录,然后虚拟地址就是我们平时取一些本地资源要选取的一些路径,访问url就是我们向外部服务器拿数据了,url就是一个取数据的路径,拿到资源后,至于怎么展示给用户看,就是前端的工作部分了;那么回去介绍完一个完整的url,一个完整的url一般类似这样:http://www.example.com:8080/role/list?name=123&password=123456#people
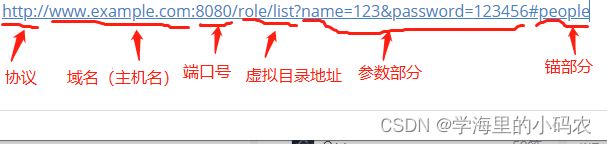
一个完整的url,这就是他的全部组成部分了。
1.协议:
协议一般就是http和https较为常见,http传输的数据一般是明文的方式,这样的风险就是一旦数据被劫持了,对方不费吹灰之力就能读懂你的信息,所以这种不适合传输一些较为机密的信息,比如银行卡密码等等,而https就是http的加密版本,他将传输的信息使用SSL进行加密处理,这样即使对方劫持了数据,也无法直观的读懂信息的内容,需要密钥才能将密文转换成明文,其中值得探索的东西还很多,对称加密、非对称加密、数字证书、单双向认证等等,结尾以//作为分隔符.
2.域名(主机名):
www.example.com就是url的域名部分,域名一般都有一定的辨识度,例如www.bilibili.com,www.baidu.com等等,但是这里有个需要注意的点,比如我们本地启动服务器,那么我们域名或者说主机号就是我们的ip,比如192.168.31.1这个就是我们的主机号,我们可以直接向这里请求数据,但是这里的域名还不是主机号或者ip地址,这里又涉及到了一个知识点,就是DNS域名解析,那么他的作用其实就是将我们的域名解析成对应了IP地址,因为我们正在去建立通讯的两个IP之间的,根据域名找到对应IP地址,有些像映射关系,为什么要这么做也很好理解,比如www.bilibili.com你可能一会就记住了但是如果是www.192.168.31.1.com辨识度就非常低也不容易区分,所以有了这一步,这也为什么你输入域名就能找到对应网站,是因为中间有一个DNS域名解析的过程
3.端口:
对于端口,我没有较为深层次的理解,端口号默认是:80或者8080,我在用nodejs写服务端代码的时候,开始就需要写一个检测的端口号,这里提供一个帮助理解的,在硬件领域,端口又称接口。
4.虚拟目录部分:(非url必须部分)
从域名的第一个/开始直到最后一个/为止,虚拟目录对于前端开发来说就是接口地址,对于使用电脑的人可以理解成本地目录,他并非必须的部分,比如这里不写一般就是访问一个网站的首页或者登录页
5.参数部分:
参数部分是从?开始带#部分,又称为搜索部分、查询部分。参数一般允许多个参数,参数与参数之间使用&作为分隔,http://www.baidu.com/?wd=空腹能吃饭吗? 这里就是一个例子,其中空腹能吃饭吗就是我们的参数部分由参数名wd和参数值组成,但是这里一般不能用来传输账号密码这种数据,因为一般是明文展示的很不安全,我图中举例就是,明文显示别人一眼就知道你的重要信息了,不过我刚刚发现一个神奇的地方,我在百度复制一段含有明文的url下来,粘贴出来就是加密后的,应该是做了简单的加密,使得不容易得到明文内容。
6.锚部分:(未找到较为详细得解释)
在#开始到最后就是,在css中有个叫做锚点跳转,就是将div得class属性命名为id=“people”,然后为对于a链接指定href=“#prople”,然后点击即可跳转到对于div位置,那么我理解这里应该是在你进入一个页面得时候将你的屏幕定格在哪?一般不会设置,就是最上面,如果定义到底部元素,那么可能一进来就自动划到最底部了,我猜应该是这个意思(个人感觉)
这里介绍完了一个url得完整组成部分,主要就是想要引入端口号,因为一般在我们网址处和网址复制粘贴过程中见不到端口号,可能会有点陌生,我们的跨域问题主要相关的就是协议、域名、端口号,任何一个不同都不同源,因为前面介绍了源就是由这三个共同决定的,那么为什么要有这个安全策略呢?因为在游览器中有一些比较重要的信息,虽然我们的账号密码等是存在服务器的,但是游览器中存储了一个重要的东西叫做cookie,当你和服务器第一次建立连接后,为了方便后续的继续,服务器会返回一个cookie给客户端,客户端拿着这个cookie下次就不需要验证直接就可以向服务器请求数据了,假设游览器没有同源策略,那么一个服务器通过js代码操作本地游览器拿到与另一个服务器之间的cookie,那么他就可以和绕过登录和另一个服务器建立连接了,这样他就可以用你的身份干一些不好的事情,为了防止这种情况的发生,游览器制定了同源策略,同源策略是基本的防护。
如何应对跨域问题呢?一般有三种解决策略
1.JSONP原理: