mysql---索引
概要
索引:排序的列表,列表当中存储的是索引的值和包含这个值的数据所在的行的物理地址
作用:加快查找速度
注:索引要在创建表时尽量创建完全,后期添加影响变动大。
索引也需要占用磁盘空间,innodb表数据文件本身也是索引,myisam索引和数据文件是分离的。
更新一个有索引的表比更新一个无索引表,花费的时间更多。更新了值,也就是更新索引。
索引的作用:
1、利用索引数据库可以快速定位,大大加快查询速度
2、表的数据很多,查询需要关联多个表,此时索引提高查询速度
3、加快表与表连接的速度
4、使用分组和排序时,可以大大减少时间
5、提高数据库恢复数据时的速度
索引创建的原则:
1、有索引,数据会先进行索引查询,然后定位数据,索引使用不当,反而会增加数据库的负担
主键,外键必须有索引(创建好了主键和外键自动就是索引,而不需要额外的声明)
2、一个表超过300行记录,必须要有索引,否则会遍历表的所有数据
3、互相之间有关联的表,在关联字段应该设置索引
4、唯一性太差的字段,不适合做索引
5、更新太频繁的字段,不适合做索引
6、经常被where条件匹配的字段,表数据比较多的应该是创建索引
7、在经常进行group by (分组) order by(排序)的字段上要建立索引
8、索引的列的字段越小越好,长文本字段不适合建立索引
索引的类型
1、B-树索引 BTREE
树型结构的索引,大部分数据库的默认索引类型。
根节点:书的最顶端的分支节点
分支节点:指向索引里其他的分支节点,也可以是叶子节点
2、哈希索引
散列索引 把任意长度的输入,通过散列算法变换成固定长度的输出。散列值---分别对应数据里的列和行,不能排序(排序时索引是失效的)
mysql 默认引擎 innodb 也就是btree
memory引擎可以支持hash,也是默认索引
先算散列值,然后再对应,速度比较慢,比btree
hash的索引匹配: = in () <= >
3、orcale
默认都是树形结构的索引
创建索引及索引类型(默认innodb)
格式:create index 索引名 on 表名 (属性) USING hash;
修改引擎类型
格式:alter table 表名 engine=innodb/memory;
查看表索引
格式:show index from 表名;
Non_unique 可唯一为0 可重复为1
新增普通索引
格式:alter table 表名 add index 索引名(属性名);
索引类型
创建表时创建索引的格式
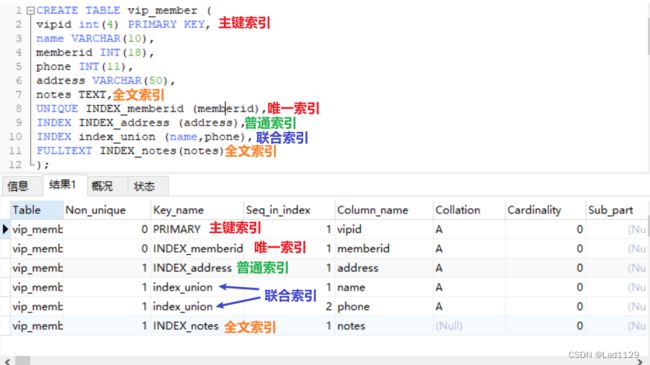
1、普通索引
普通索引:添加格式
格式:ALTER TABLE 表名 add index 索引名(属性名);
格式:CREATE INDEX 索引名 ON 表名 (属性名);
2、主键索引
创建表的指定的主键就是索引,添加主键自动的就是主键索引。
主键要素:值唯一 一个表只能有一个主键 不允许有空值 创建主键,自动主键索引。
主键索引:添加格式
格式:ALTER TABLE 表名 primary key (属性名);
3、唯一索引
与普通索引类似,唯一索引的每个值都是唯一,唯一值允许为空值,空值多了就会失效
唯一索引:添加格式
unique 与普通索引类似,唯一索引的每个值都是唯一,唯一值允许为空值,空值多了就会失效
格式:CREATE UNIQUE INDEX 索引名 on 表名 (属性名);
格式:ALTER TABLE 表名 add unique 索引名(属性名);
4、全文索引
适合在模糊查询的时候使用,可以在一边文章中检索文本。
全文索引:添加格式
格式:alter table 表名 add FULLTEXT 索引名(属性名);
格式:CREATE FULLTEXT INDEX 索引名 on 表名 (属性名);
5、联合索引
指定一个索引名,一个索引名对应多个列名。
联合索引,从左到右侧开始,不能跳过索引,否则索引会失效。
联合索引:添加格式
格式:alter table 表名 add INDEX 索引名(属性名1,属性名2);
格式:create index 索引名 on 表名 (属性名1,属性名2);
查看是否用到索引(EXPLAIN)
EXPLAIN SELECT语句;
例:EXPLAIN SELECT * from 表名 where 列名 like '模糊过滤条件';
删除索引
格式:DROP index 索引名 on 表名;
索引失效的几种情况
1、范围查询,有可能右侧的索引会失效。
2、如果索引是字符串,不加引号,索引会失效
3、使用or 语句索引一定会失效,使用or作为条件,mysql 无法同时使用多个索引。
4、有时候索引会失效 where is null 数据的绝大多数都是空值,索引失效
where is not null 数据多数为不空,索引失效
in age 索引生效
not in age 索引失效
如果检索响应时间过长,怎么办?(三步走)
1、首先查缓存,是否请求到后端数据库
2、再看索引,请求的列值不是默认索引,添加即可 用explain 查看索引的使用情况
3、指定判定内容过多
创建表的因素(四个点)
·关联程度3张表,选好关联字段
·每个字段的长度
·设置合理的索引列
·表数据要控制在合理的范围之内,可以在牺牲一定的性能的条件下,满足需求即可。大于5s考虑,大于10s一般是出了问题(缓存失效、缓存击穿、缓存雪崩)