Python爬取读书网的图片链接和书名并保存在数据库中
一个比较基础且常见的爬虫,写下来用于记录和巩固相关知识。
一、前置条件
本项目采用scrapy框架进行爬取,需要提前安装
pip install scrapy
# 国内镜像
pip install scrapy -i https://pypi.douban.com/simple由于需要保存数据到数据库,因此需要下载pymysql进行数据库相关的操作
pip install pymysql
# 国内镜像
pip install pymysql -i https://pypi.douban.com/simple同时在数据库中创立对应的表
create database spider01 charset utf8;
use spider01;
# 这里简单创建name和src
create table book(
id int primary key auto_increment,
name varchar(188),
src varchar(188)
);二、项目创建
在终端进入准备存放项目的文件夹中
1、创建项目
scrapy startproject scrapy_book创建成功后,结构如下:

2、跳转到spiders路径
cd scrapy_book\scrapy_book\spiders3、生成爬虫文件
由于涉及链接的提取,这里生成CrawlSpider文件
scrapy genspider -t crawl read Www.dushu.com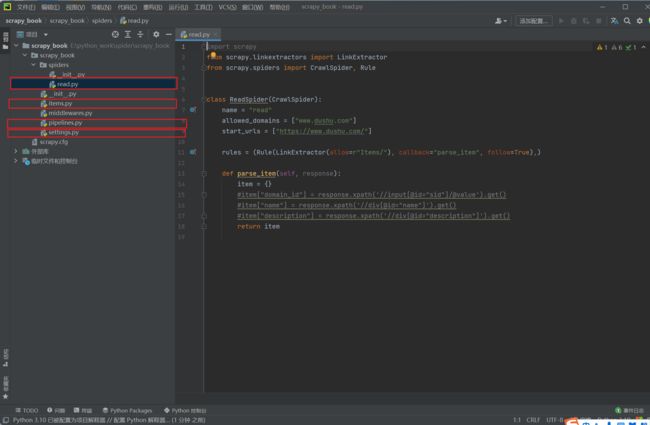
注意:先将第11行中follow的值改为False,否则会跟随从当前页面提取的链接继续爬取,避免过度下载
4、项目结构说明
接下来我们一共要修改4个文件完成爬取功能:
- read.py: 自定义的爬虫文件,完成爬取的功能
- items.py: 定义数据结构的地方,是一个继承自scrapy.Item的类
- pipelines.py: 管道文件,里面只有一个类,用于处理下载数据的后续处理
- setings.py: 配置文件 比如:是否遵循robots协议,User-Agent协议
三、网页分析
1、图书分析
读书网主页:

在读书网中,随便选取一个分类,这里以外国小说为例进行分析
这里我们简单爬取它的图片和书名,当然也可扩展
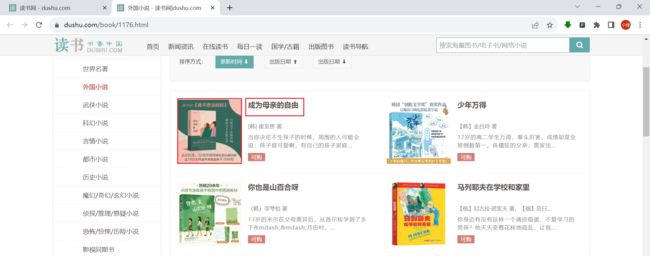
使用xpath语法对第一页的图片进行分析

由上图可以知道
书名://div[@class="bookslist"]//img/@alt
书图片地址://div[@class="bookslist"]//img/@data-original 不是src属性是因为页面图片使用懒加载
2、页码分析
第一页:外国小说 - 读书网|dushu.com 或 https://www.dushu.com/book/1176_1.html
第二页:外国小说 - 读书网|dushu.com
第三页:外国小说 - 读书网|dushu.com




发现规律,满足表达式:r"/book/1176_\d+\.html"
四、项目完成
1、修改items.py文件
自己定义下载数据的结构
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ScrapyBookItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 书名
name = scrapy.Field()
# 图片地址
src = scrapy.Field()2、修改settings.py文件
将第65行的ITEM_PIPELINES的注释去掉,并在下面新增自己数据库的相关配置

3、修改pipnelines.py文件
进行下载数据的相关处理
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
# 加载settings文件
from scrapy.utils.project import get_project_settings
import pymysql
class ScrapyBookPipeline:
# 最开始执行
def open_spider(self,spider):
settings = get_project_settings()
# 获取配置信息
self.host = settings['DB_HOST']
self.port = settings['DB_PORT']
self.user = settings['DB_USER']
self.password = settings['DB_PASSWROD']
self.name = settings['DB_NAME']
self.charset = settings['DB_CHARSET']
self.connect()
def connect(self):
self.conn = pymysql.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password,
db=self.name,
charset=self.charset
)
self.cursor = self.conn.cursor()
# 执行中
def process_item(self, item, spider):
# 根据自己的表结构进行修改,我的是book表
sql = 'insert into book(name,src) values("{}","{}")'.format(item['name'], item['src'])
# 执行sql语句
self.cursor.execute(sql)
# 提交
self.conn.commit()
# 结尾执行
def close_spider(self, spider):
self.cursor.close()
self.conn.close()4、修改read.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
# 导入时可能有下划线报错,是编译器问题,可以正常使用
from scrapy_book.items import ScrapyBookItem
class ReadSpider(CrawlSpider):
name = "read"
allowed_domains = ["www.dushu.com"]
# 改为第一页的网址,这样都能满足allow的规则,不遗漏
start_urls = ["https://www.dushu.com/book/1176_1.html"]
# allow属性提取指定链接,下面是正则表达式 callback回调函数 follow是否跟进就是按照提取连接规则进行提取这里选择False
rules = (Rule(LinkExtractor(allow=r"/book/1176_\d+\.html"), callback="parse_item", follow=False),)
def parse_item(self, response):
item = {}
# item["domain_id"] = response.xpath('//input[@id="sid"]/@value').get()
# item["name"] = response.xpath('//div[@id="name"]').get()
# item["description"] = response.xpath('//div[@id="description"]').get()
# 获取当前页面的所有图片
img_list = response.xpath('//div[@class="bookslist"]//img')
for img in img_list:
name = img.xpath('./@alt').extract_first()
src = img.xpath('./@data-original').extract_first()
book = ScrapyBookItem(name=name, src=src)
# 进入pipelines管道进行下载
yield book
5、下载
终端进入spiders文件夹,运行命令:scrapy crawl read
其中read是spiders文件夹下read.py中name的值



6、结果



一共下载了40(每一页的数据) * 13(页) = 520条数据
将read.py中的follow改为True即可下载该类书籍的全部数据,总共有100页,如果用流量的话谨慎下载,预防话费不足。
![]()
5、结语
这个爬虫项目应该可以适用于挺多场景的,不是特别多, 跟着写一下也没啥坏处。如果有代码的需求的话,日后会把项目的代码地址给出。因为自己学爬虫没多久,记录一下梳理下思路,也可以为以后有需要的时候做参考。