《Python网络爬虫实战》读书笔记2
文章目录
- 更强大的爬虫
-
- 网站反爬虫
- 多进程编程与异步爬虫抓取
- 用异步的形式抓取数据
- 更多样的爬虫
-
- 编写Scrapy爬虫
-
- 新建一个Scrapy项目
- 创建爬虫
- Scrapyd
- 使用Gerapy部署和管理爬虫
-
- 添加主机(在本机可以创建多个主机,只需要修改cfg文件的端口)
- 爬虫实践:下载网页中的小说和购物评论
-
- 爬取小说网的内容
- 下载京东购物评论
- 爬虫实践:保存感兴趣的图片
- 爬虫实践:网上影评分析
- 爬虫实践:使用PySpider爬虫框架
- 全文所涉及的代码下载地址
- 参考链接
更强大的爬虫
网站反爬虫
网站的反爬虫策略有如下几种
- 1.识别request headers信息
- 2.使用AJAX和动态加载
- 3.验证码
- 4.更改服务器返回的信息
- 5.限制或封禁IP
- 6.修改网页或URL内容
- 7.账号限制
下面的示例通过获取西刺代理的公开ip,然后用获取到的ip通过requests访问csdn的blog链接,比较好用的代码是获取代理信息
# 增加博客访问量
import re, random, requests, logging
from lxml import html
from multiprocessing.dummy import Pool as ThreadPool
logging.basicConfig(level=logging.DEBUG)
TIME_OUT = 6 # 超时时间
count = 0
proxies = []
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/36.0.1985.125 Safari/537.36',
}
PROXY_URL = 'http://www.xicidaili.com/'
def GetProxies():
global proxies
try:
res = requests.get(PROXY_URL, headers=headers)
except:
logging.error('Visit failed')
return
ht = html.fromstring(res.text)
raw_proxy_list = ht.xpath('//*[@id="ip_list"]/tr[@class="odd"]')
for item in raw_proxy_list:
if item.xpath('./td[6]/text()')[0] == 'HTTP':
proxies.append(
dict(
http='{}:{}'.format(
item.xpath('./td[2]/text()')[0], item.xpath('./td[3]/text()')[0])
)
)
# 获取博客文章列表
def GetArticles(url):
res = GetRequest(url, prox=None)
html = res.content.decode('utf-8')
rgx = '[ \n\t]*'
ptn = re.compile(rgx)
blog_list = re.findall(ptn, str(html))
return blog_list
def GetRequest(url, prox):
req = requests.get(url, headers=headers, proxies=prox, timeout=TIME_OUT)
return req
# 访问博客
def VisitWithProxy(url):
proxy = random.choice(proxies) # 随机选择一个代理
GetRequest(url, proxy)
# 多次访问
def VisitLoop(url):
for i in range(count):
logging.debug('Visiting:\t{}\tfor {} times'.format(url, i))
VisitWithProxy(url)
if __name__ == '__main__':
global count
GetProxies() # 获取代理
logging.debug('We got {} proxies'.format(len(proxies)))
BlogUrl = input('Blog Address:').strip(' ')
logging.debug('Gonna visit{}'.format(BlogUrl))
try:
count = int(input('Visiting Count:'))
except ValueError:
logging.error('Arg error!')
quit()
if count == 0 or count > 200:
logging.error('Count illegal')
quit()
article_list = GetArticles(BlogUrl)
if len(article_list) == 0:
logging.error('No articles, eror!')
quit()
for each_link in article_list:
if not 'https://blog.csdn.net' in each_link:
each_link = 'https://blog.csdn.net' + each_link
article_list.append(each_link)
# 多线程
pool = ThreadPool(int(len(article_list) / 4))
results = pool.map(VisitLoop, article_list)
pool.close()
pool.join()
logging.DEBUG('Task Done')
多进程编程与异步爬虫抓取
上面用的是ThreadPool,其实并没有多进程高效,下面的例子是使用单进程与多进程的对比
import requests
import datetime
import multiprocessing as mp
def crawl(url, data): # 访问
text = requests.get(url=url, params=data).text
return text
def func(page): # 执行抓取
url = "https://book.douban.com/subject/4117922/comments/hot"
data = {
"p": page
}
text = crawl(url, data)
print("Crawling : page No.{}".format(page))
if __name__ == '__main__':
start = datetime.datetime.now()
start_page = 1
end_page = 50
# 多进程抓取
# pages = [i for i in range(start_page, end_page)]
# p = mp.Pool()
# p.map_async(func, pages)
# p.close()
# p.join()
# 单进程抓取
page = start_page
for page in range(start_page, end_page):
url = "https://book.douban.com/subject/4117922/comments/hot"
# get参数
data = {
"p": page
}
content = crawl(url, data)
print("Crawling : page No.{}".format(page))
end = datetime.datetime.now()
print("Time\t: ", end - start)
使用单进程速度为:
Time : 0:00:02.607331
更改为多进程后速度:
Time : 0:00:01.261326
速度在page越多的情况下,相差会越大
用异步的形式抓取数据
在提高抓取性能方面,还可以引入异步机制(比如asyncio库、aiohttp库等实现),这种方式利用了异步的原理,使得程序不必等待HTTP请求完成后再执行后续任务,在大批量网页抓取中,这种异步的方式对于爬虫性能尤为重要
import aiohttp
import asyncio
# 使用aiohttp访问网页的例子
async def fetch(session, url):
# 类似 requests.get
async with session.get(url) as response:
return await response.text()
# 通过async实现单线程并发IO
async def main():
# 类似requests中的Session对象
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://httpbin.org/headers')
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
更多样的爬虫
编写Scrapy爬虫
请参考blog文:《用Python写网络爬虫》读书笔记3
常用的命令如下
- startproject:创建一个新项目
- genspider:根据模板生成一个新爬虫
- crawl:执行爬虫
- shell:启动交互式抓取控制台
新建一个Scrapy项目
scrapy startproject example
创建爬虫
cd进入到example文件夹中,执行如下命令
scrapy genspider hupu_link https://bbs.hupu.com/xuefu --template=crawl
在目录中出现一个文件hupu_link.py,里面就是我们的代码,补充上如下内容
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.http import Request
from ..items import HupuItem
class HupuLinkSpider(CrawlSpider):
name = 'hupu_link'
allowed_domains = ['https://bbs.hupu.com/']
start_urls = ['https://bbs.hupu.com/xuefu-1/']
def parse(self, response):
# 本来这里是要取到最后一页的页码的,为了简单,直接设置为4页
page_max = 4
append_urls = ['https://bbs.hupu.com/xuefu-%d' % (i + 1) for i in range(page_max)]
for url in append_urls:
yield Request(url, callback=self.parse_item, dont_filter=True)
# 得到当前页面的title和link
def parse_item(self, response):
item = HupuItem()
all_item_class = response.xpath("//div[@class='titlelink box']")
for item_class in all_item_class:
link = 'https://bbs.hupu.com' + item_class.xpath("a/@href").extract()[0]
title = item_class.xpath("a/text()").extract()[0]
item["title"] = title
item["link"] = link
yield item
print(title, link)
再来修改items.py
import scrapy
class HupuItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
pipelines.py,作用是把每一个items保存到csv中
import pandas as pd
class HupuPipeline(object):
def process_item(self, item, spider):
data = pd.DataFrame(dict(item), index=[0])
data.to_csv('hupu.csv', mode='a+', index=False, sep=',', header=False, encoding="gbk")
return item
在settings.py中,加入如下内容
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 3
CONCURRENT_REQUESTS_PER_DOMAIN = 1
ITEM_PIPELINES = {
'example.pipelines.HupuPipeline': 300,
}
在example文件夹下,用如下命令执行爬虫
scrapy crawl hupu_link
可以看到如下内容

同时出现hupu.csv文件
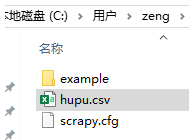
Scrapyd
安装使用如下命令
pip install scrapyd
执行直接在命令行运行scrapyd

默认情况下scrapyd 监听 0.0.0.0:6800 端口,运行scrapyd 后在浏览器http://localhost:6800/ 即可查看到当前可以运行的项目:http://localhost:6800/

api是使用curl提交命令来操作scrapyd,官网参考文档如下:https://scrapyd.readthedocs.io/en/latest/api.html
修改工程目录下的 scrapy.cfg 文件,可以设定端口号个project,例如下面的
[deploy]
#url = http://localhost:6800/
#project = example
url = http://127.0.0.1:6800/
project = example
如果本机有多个项目,直接修改不同的端口号
官方还提供了一个scrapy-client,能够更方便的执行打包(打包各位为egg)和执行命令,不过后面使用的Gerapy比这个client更加方便
使用Gerapy部署和管理爬虫
安装命令
pip install gerapy
初始化gerapy
gerapy init
可以看到有一个gerapy文件夹
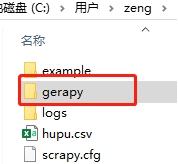
进入该文件夹后执行数据库初始化命令,在木事生成一个dbs
gerapy migrate
创建用户名和密码
gerapy createsuperuser
启动服务
gerapy runserver
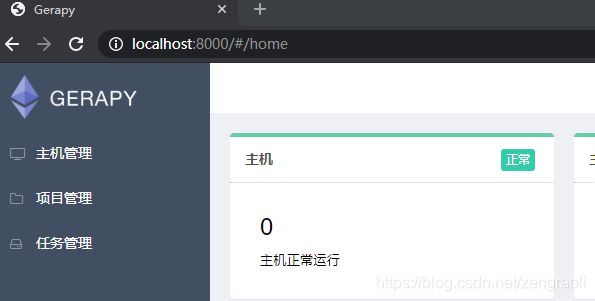
在浏览器中访问
http://localhost:8000/
登录后的界面如下
添加主机(在本机可以创建多个主机,只需要修改cfg文件的端口)
点击主机管理选项卡下面的新建,填入如下内容
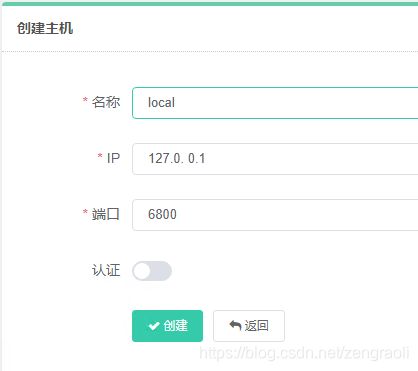
查看状态是否正常,如果不正常需要修改
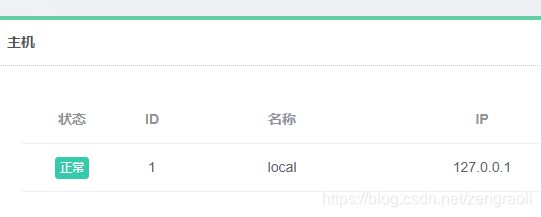
把scrapy项目拷贝到gerapy的projects文件夹下,可以在项目管理中看到项目

点击部署,先去打包,左边会有打包的信息

批量部署到主机中

可以看到项目example下有对应的egg文件
再回到主机管理中,最后有一个调度,就可以开始执行任务了

运行后可以看到如下信息,执行结束后,可以看到还有结束时间

这里的显示内容,跟scrapyd的log是一样的

爬虫实践:下载网页中的小说和购物评论
爬取小说网的内容
首先新建一个chrome_driver,打开小说的全部章节link放到list中,循环此list,按个去获取原文内容,保存到txt中
import selenium.webdriver, time, re
from selenium.common.exceptions import WebDriverException
class NovelSpider():
def __init__(self, url):
self.homepage = url
self.driver = selenium.webdriver.Chrome(r'C:\Users\zeng\AppData\Local\Google\Chrome\Application\chromedriver.exe')
self.page_list = []
def __del__(self):
self.driver.quit()
def get_page_urls(self): # 获取章节页面的列表
homepage = self.homepage
self.driver.get(homepage)
self.driver.save_screenshot('screenshot.png') # 截图保存网页
self.driver.implicitly_wait(5)
elements = self.driver.find_elements_by_tag_name('a')
for one in elements:
page_url = one.get_attribute('href')
pattern = '^http:\/\/book\.zhulang\.com\/\d{6}\/\d+\.html'
if re.match(pattern, page_url):
print(page_url)
self.page_list.append(page_url)
def looping_crawl(self):
homepage = self.homepage
filename = self.get_novel_name(homepage) + '.txt'
self.get_page_urls() # 得到小说的全部章节
pages = self.page_list
# print(pages)
for page in pages: # 循环章节link
self.driver.get(page)
print('Next page:')
self.driver.implicitly_wait(3)
title = self.driver.find_element_by_tag_name('h2').text
res = self.driver.find_element_by_id('read-content')
text = '\n' + title + '\n'
for one in res.find_elements_by_xpath('./p'):
text += one.text
text += '\n'
self.text_to_txt(text, filename) # 取出章节信息,存放到txt中
time.sleep(1)
print(page + '\t\t\tis Done!')
def get_novel_name(self, homepage): # 获取书名并转化为TXT文件名
self.driver.get(homepage)
self.driver.implicitly_wait(2) # 隐式等待,设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步
res = self.driver.find_element_by_tag_name('strong').find_element_by_xpath('./a')
if res is not None and len(res.text) > 0:
return res.text
else:
return 'novel'
def text_to_txt(self, text, filename): # 保存抓取到的正文内容
if filename[-4:] != '.txt':
print('Error, incorrect filename')
else:
with open(filename, 'a') as fp:
fp.write(text)
fp.write('\n')
if __name__ == '__main__':
# hp_url = input('输入小说“全部章节”页面:')
hp_url = "http://book.zhulang.com/740053/"
try:
sp1 = NovelSpider(hp_url)
sp1.looping_crawl()
del sp1
except WebDriverException as e:
print(e.msg)
下载京东购物评论
通过chrome得到京东获取评论的链接,进行拼接,就能得到上面的评论

使用requests.session能保持上一次的会话,在用requests.get请求时,加上params而不是在url后面拼接,显得更加高级,比如下面的代码
p_data = {
'callback': 'fetchJSON_comment98vv242411',
'score': 0,
'sortType': 3,
'page': 0,
'pageSize': 10,
'isShadowSku': 0,
}
response = ses.get(comment_json_url, params=p_data)
从json中得到评论信息后,保存到csv文件中,对获取到的所有评论追加到content_sentences字符串中,接着用jieba.analyse.extract_tags提取前20个关键词信息、示例全部代码如下
import requests, json, time, logging, random, csv, lxml.html, jieba.analyse
from pprint import pprint
from datetime import datetime
# 京东评论 JS
class JDComment():
_itemurl = ''
def __init__(self, url, page):
self._itemurl = url
self._checkdate = None
logging.basicConfig(
# filename='app.log',
level=logging.INFO,
)
self.content_sentences = ''
self.max_page = page
def go_on_check(self, date, page):
go_on = self.date_check(date) and page <= self.max_page
return go_on
def set_checkdate(self, date):
self._checkdate = datetime.strptime(date, '%Y-%m-%d')
def get_comment_from_item_url(self):
comment_json_url = 'https://sclub.jd.com/comment/productPageComments.action'
p_data = {
'callback': 'fetchJSON_comment98vv242411',
'score': 0,
'sortType': 3,
'page': 0,
'pageSize': 10,
'isShadowSku': 0,
}
p_data['productId'] = self.item_id_extracter_from_url(self._itemurl)
ses = requests.session()
go_on = True
while go_on:
response = ses.get(comment_json_url, params=p_data)
logging.info('-' * 10 + 'Next page!' + '-' * 10)
if response.ok:
r_text = response.text
r_text = r_text[r_text.find('({') + 1:]
r_text = r_text[:r_text.find(');')]
# print(r_text)
js1 = json.loads(r_text)
# print(js1['comments'])
for comment in js1['comments']:
go_on = self.go_on_check(comment['referenceTime'], p_data['page'])
logging.info('{}\t{}\t{}\t'.format(comment['content'], comment['referenceTime'],
comment['nickname']))
self.content_process(comment)
self.content_sentences += comment['content']
else:
logging.error('Status NOT OK')
break
p_data['page'] += 1
self.random_sleep() # delay
def item_id_extracter_from_url(self, url):
item_id = 0
prefix = 'item.jd.com/'
index = str(url).find(prefix)
if index != -1:
item_id = url[index + len(prefix): url.find('.html')]
if item_id != 0:
return item_id
def date_check(self, date_here):
if self._checkdate is None:
logging.warning('You have not set the checkdate')
return True
else:
dt_tocheck = datetime.strptime(date_here, '%Y-%m-%d %H:%M:%S')
if dt_tocheck > self._checkdate:
return True
else:
logging.error('Date overflow')
return False
def content_process(self, comment):
with open('jd-comments-res.csv', 'a') as csvfile:
writer = csv.writer(csvfile, delimiter=',')
writer.writerow([comment['content'], comment['referenceTime'],
comment['nickname']])
def random_sleep(self, gap=1.0):
# gap = 1.0
bias = random.randint(-20, 20)
gap += float(bias) / 100
time.sleep(gap)
def get_keywords(self):
content = self.content_sentences
kws = jieba.analyse.extract_tags(content, topK=20)
return kws
if __name__ == '__main__':
# url = input("输入商品链接:")
url = "https://item.jd.com/6088552.html"
# date_str = input("输入限定日期:")
date_str = "2019-10-10"
# page_num = int(input("输入最大爬取页数:"))
page_num = int(4)
jd1 = JDComment(url, page_num)
jd1.set_checkdate(date_str)
print(jd1.get_comment_from_item_url())
print(jd1.get_keywords())
检查日期是大于还是小于也比较有意思,使用的是下面的代码(如果是我来操作,可能是先转成linux时间戳再比较大小)
dt_tocheck = datetime.strptime(date_here, '%Y-%m-%d %H:%M:%S')
if dt_tocheck > self._checkdate:
return True
爬虫实践:保存感兴趣的图片
本例子是通过登录douban,访问个人的观影记录,下载对应的pic(由于本人没有这些信息,所以跳过)。常规的操作,访问login链接登录豆瓣,如果出现验证码让,执行show_an_online_img,显示出来,让用户进行输入
def show_an_online_img(self, url):
path = self.download_img(url, 'online_img')
img = Image.open(path)
img.show()
os.remove(path)
调用部分代码为:
if len(response1.xpath('//*[@id="captcha_image"]')) > 0:
self._captcha_url = response1.xpath('//*[@id="captcha_image"]/@src')[0]
print(self._captcha_url)
self.show_an_online_img(url=self._captcha_url)
captcha_value = input("输入图中的验证码")
login_data['captcha-solution'] = captcha_value
爬虫实践:网上影评分析
下面的例子是获取豆瓣电影上面的某一个电影,取出前15的评论,用jieba提起词频
import jieba, numpy, re, time, matplotlib, requests, logging, snownlp, threading
import pandas as pd
from pprint import pprint
from bs4 import BeautifulSoup
from matplotlib import pyplot as plt
from queue import Queue
from lxml.html import fromstring
matplotlib.rcParams['font.sans-serif'] = ['KaiTi']
matplotlib.rcParams['font.serif'] = ['KaiTi']
HEADERS = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36',
}
NOW_PLAYING_URL = 'https://movie.douban.com/nowplaying/beijing/'
logging.basicConfig(level=logging.DEBUG)
class MyThread(threading.Thread):
CommentList = []
Que = Queue()
def __init__(self, i, MovieID):
super(MyThread, self).__init__()
self.name = '{}th thread'.format(i)
self.movie = MovieID
def run(self):
logging.debug('Now running:\t{}'.format(self.name))
while not MyThread.Que.empty():
page = MyThread.Que.get()
commentList_temp = GetCommentsByID(self.movie, page + 1)
MyThread.CommentList.append(commentList_temp)
MyThread.Que.task_done()
def MovieURLtoID(url):
res = int(re.search('(\D+)(\d+)(\/)', url).group(2))
return res
def GetCommentsByID(MovieID, PageNum):
result_list = []
if PageNum > 0:
start = (PageNum - 1) * 20
else:
logging.error('PageNum illegal!')
return False
url = 'https://movie.douban.com/subject/{}/comments?start={}&limit=20'.format(MovieID, str(start))
logging.debug('Handling :\t{}'.format(url))
resp = requests.get(url,headers=HEADERS)
resp.content.decode('utf-8')
html_data = resp.text
tree = fromstring(html_data)
all_comments = tree.xpath("//span[@class='short']//text()")
for comment in all_comments:
result_list.append(comment)
time.sleep(2) # Pause for several seconds
return result_list
def DFGraphBar(df):
df.plot(kind="bar", title='Words Freq', x='seg', y='freq')
plt.savefig("output.jpg")
plt.show()
def WordFrequence(MaxPage=15, ThreadNum=8, movie=None):
# 循环获取电影的评论
if not movie:
logging.error('No movie here')
return
else:
MovieID = movie
for page in range(MaxPage):
MyThread.Que.put(page)
threads = []
for i in range(ThreadNum):
work_thread = MyThread(i, MovieID)
work_thread.setDaemon(True)
threads.append(work_thread)
for thread in threads:
thread.start()
MyThread.Que.join()
CommentList = MyThread.CommentList
# print(CommentList)
comments = ''
for one in range(len(CommentList)):
new_comment = (str(CommentList[one])).strip()
new_comment = re.sub('[-\\ \',\.n()#…/\n\[\]!~]', '', new_comment)
# 使用正则表达式清洗文本,主要是去除一些标点
comments = comments + new_comment
pprint(SumOfComment(comments)) # 输出文本摘要
# 中文分词
segments = jieba.lcut(comments)
WordDF = pd.DataFrame({'seg': segments})
# 去除停用词
stopwords = pd.read_csv("stopwordsChinese.txt",
index_col=False,
names=['stopword'],
encoding='utf-8')
WordDF = WordDF[~WordDF.seg.isin(stopwords.stopword)] # 取反
# 统计词频
WordAnal = WordDF.groupby(by=['seg'])['seg'].agg({'freq': numpy.size})
WordAnal = WordAnal.reset_index().sort_values(by=['freq'], ascending=False)
WordAnal = WordAnal[0:40] # 仅取前40个高频词
print(WordAnal)
return WordAnal
def SumOfComment(comment):
s = snownlp.SnowNLP(comment)
sum = s.summary(5)
return sum
# 执行函数
if __name__ == '__main__':
DFGraphBar(WordFrequence(movie=MovieURLtoID('https://movie.douban.com/subject/1291575/')))
所输出的词频信息如下(因为停用词字典不太好,有些词完全是没有意义的)
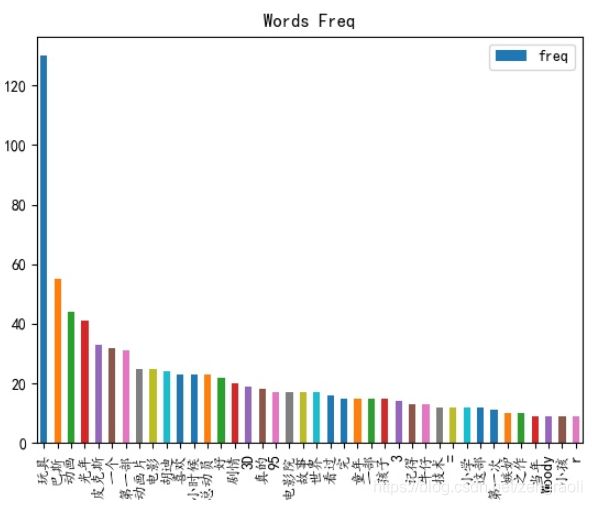
爬虫实践:使用PySpider爬虫框架
用
pip install pyspider
进行安装
安装后,用
pyspider all
启动服务,从http://localhost:5000/访问服务,启动服务时候可能会遇到问题,那么请参考:解决pyspider:ValueError: Invalid configuration

下面的示例获取hupu上面的链接
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2020-04-23 21:06:24
# Project: hupu
from pyspider.libs.base_handler import *
import re
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('https://bbs.hupu.com/xuefu', fetch_type='js', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^=http]').items():
url = each.attr.href
if re.match(r'^http\S*://bbs.hupu.com/\d+.html$', url):
self.crawl(url, fetch_type='js', callback=self.detail_page)
next_page_url = response.doc(
'#container > div > div.bbsHotPit > div.showpage > div.page.downpage > div > a.nextPage').attr.href
if int(next_page_url[-1]) > 30:
raise ValueError
self.crawl(next_page_url,
fetch_type='js',
callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('#j_data').text(),
}
将代码拷贝到右侧,save保存,左边点击run,选择底下的follows,最后绿色箭头运行
可以看到如下结果,detail_page方法获得其标题和链接,index_page方法则执行抓取任务,你还可以选择下一页等

回到主页面中,选择status为RUNNING,再执行Run,任务就开始了

稍微等一下,点击页面的result,就能看到结果了

全文所涉及的代码下载地址
https://download.csdn.net/download/zengraoli/12366948
参考链接
- DEBUG: Filtered offsite request to
- scrapy xpath 从response中获取li,然后再获取li中img的src
- scrapyd部署scrapy项目(windows)
- scrapy学习第四篇:windows下安装scrapyd
- Scrapyd使用教程
- 使用scrapyd 管理爬虫
- Scrapyd使用教程
- 分布式爬虫管理框架Gerapy安装及部署流程
- 使用Gerapy部署爬虫
- python爬虫之Gerapy安装部署
- Gerapy的简单使用
- Gerapy分布式管理
- Accept-Encoding 引起乱码的问题
- 【资源】stopwords.txt下载百度云(中英文)
- 解决pyspider:ValueError: Invalid configuration