Scrapy爬取豆瓣图书详情存入CSV并导入MySQL
目录
前言
一、新建爬虫工程
二、修改settings.py文件
三、编写items.py
四、编写pipelines.py
五、编写book.py
六、存储到MySQL
七、爬取结果
八、后言
前言
利用Scrapy爬虫框架爬取豆瓣图书内容
主要思路:
- 进入 https://book.douban.com/tag/ ,该页面展示了豆瓣图书的全部分类标签
- 依次进入每一个标签来爬取数据,每个标签爬取100条
- 根据书名超链接进入到每一个图书详情页,爬取详细信息和简介信息
- 将爬取下来的数据存入CSV文件
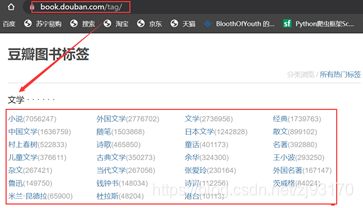 爬取入口
爬取入口
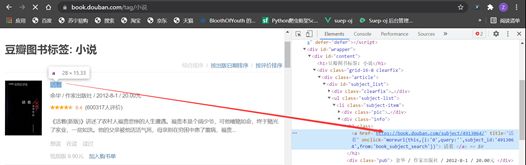 爬取书籍超链接
爬取书籍超链接
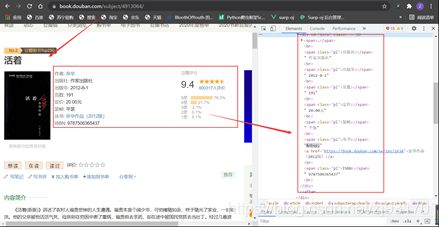 爬取书籍详情
爬取书籍详情
一、新建爬虫工程
scrapy startproject bookScrapy
cd bookScrapy
scrapy genspider book book.douban.com #创建爬虫所需的脚本文件book.py;book.douban.com设置允许爬取的网页范围(allow_domains)
二、修改settings.py文件
设置User-Agent伪装浏览器
关闭遵守爬虫协议
禁用本地Cookie
开启ITEM_PIPELINES功能使得pipelines.py文件生效
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'bookScrapy.pipelines.BookscrapyPipeline': 300,
}三、编写items.py
import scrapy
# 书籍的详细信息
class BookItem(scrapy.Item):
book_name = scrapy.Field() # 书名
book_img = scrapy.Field() # 封面
author = scrapy.Field() # 作者
publisher = scrapy.Field() # 出版社
ISBN = scrapy.Field() # ISBN
book_rate = scrapy.Field() # 评分
book_rate_number = scrapy.Field() # 评分人数
book_summary = scrapy.Field() # 简介
author_intro = scrapy.Field() # 作者简介
detail_tags = scrapy.Field() # 更精细的标签
# 大小标签的对应信息,标签与ISBN的对应关系
class TagItem(scrapy.Item):
book_big_tag = scrapy.Field() # 大标签
book_small_tag = scrapy.Field() # 小标签
ISBN = scrapy.Field() # ISBN
四、编写pipelines.py
from itemadapter import ItemAdapter
from scrapy.exceptions import DropItem
from .items import BookItem, TagItem
import re
import pymysql
import decimal
import csv
class CSVPipeline:
def __init__(self):
self.bookFile = open('book.csv', 'a', encoding='utf-8-sig', newline='')
self.tagFile = open('tag.csv', 'a', encoding='utf-8-sig', newline='')
self.bookFieldnames = ['book_name', 'book_img', 'author', 'publisher', 'ISBN',
'book_rate', 'book_rate_number', 'book_summary', 'author_intro',
'detail_tags']
self.tagFieldnames = ['book_big_tag', 'book_small_tag', 'ISBN']
# 指定文件的写入方式为csv字典写入,参数1为指定具体文件,参数2为指定字段名
self.bookWriter = csv.DictWriter(self.bookFile, fieldnames=self.bookFieldnames)
self.tagWriter = csv.DictWriter(self.tagFile, fieldnames=self.tagFieldnames)
def process_item(self, item, spider):
# ------------- 存储为csv格式 -------------
# 写入spider传过来的具体数值
if isinstance(item, BookItem):
self.bookWriter.writerow(item)
if isinstance(item, TagItem):
self.tagWriter.writerow(item)
return item
def close_spider(self, spider):
# 关闭文件
self.bookFile.close()
self.tagFile.close()
五、编写book.py
import time
from copy import deepcopy
import scrapy
from ..items import BookItem, TagItem
class BookSpider(scrapy.Spider):
name = 'book'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/tag/']
i = 0
def parse(self, response):
# 获取爬取的区域
big_tags = response.xpath("//div[@class='article']/div[2]/div")
for big_tag in big_tags:
# 实例化 TagItem 对象
tagItem = TagItem()
# 提取每一个大标签
tagItem["book_big_tag"] = big_tag.xpath("./a/@name").get()
# 获取每一个小标签区域
small_tags = big_tag.xpath("./table[@class='tagCol']/tbody")
# for small_tag in small_tags:
for small_tag in small_tags:
# 获取每一个区域的小标签
tags = small_tag.xpath('./tr/td/a/text()').getall()
for tag in tags:
# 解析出每一个小标签
tagItem['book_small_tag'] = tag
# 将解析出来的标签进行拼接,得到我们更进一步爬虫的url
for i in range(5):
tag_url = 'https://book.douban.com/tag/%s' % tag + '?start=%s&type=T' % str(i * 20)
yield scrapy.Request(url=tag_url, callback=self.book_brief,
meta={'tagItem': deepcopy(tagItem)})
# 爬取每个标签下书籍的超链接
def book_brief(self, response):
tagItem = response.meta['tagItem']
# 获取爬取的区域
contents = response.xpath("//ul[@class='subject-list']")
# 获取书籍的链接
params = contents.css(".subject-list .subject-item .info h2 a::attr(href)").getall()
for param in params:
book_url = param
yield scrapy.Request(url=book_url,
callback=self.book_detail,
meta={'tagItem': deepcopy(tagItem)})
# 爬取书籍详情页信息
def book_detail(self, response):
time.sleep(2)
tagItem = response.meta.get('tagItem')
# 实例化 BookItem 对象
bookItem = BookItem()
bookItem['book_name'] = fix_field(response.css('#wrapper > h1 > span::text').extract_first())
bookItem['book_img'] = fix_field(response.css('#mainpic > a > img::attr(src)').extract_first())
bookItem['author'] = fix_author(response)
bookItem['publisher'] = fix_field(response.xpath(
u'//span[contains(./text(), "出版社:")]/following::text()[1]').extract_first())
bookItem['ISBN'] = fix_field(response.xpath(
u'//span[contains(./text(), "ISBN:")]/following::text()[1]').extract_first())
bookItem['book_rate'] = response.css(".rating_self .ll::text").get()
bookItem['book_rate_number'] = response.xpath("//div[@class='rating_right ']/div[@class='rating_sum']/span/a["
"@class='rating_people']/span/text()").extract_first()
bookItem['book_summary'] = fix_summary(response)
bookItem['author_intro'] = fix_author_intro(response)
bookItem['detail_tags'] = fix_detail_tags(response)
tagItem['ISBN'] = bookItem.get('ISBN')
print(bookItem)
print(tagItem)
yield tagItem
yield bookItem
def fix_field(field):
return field.strip() if field else ''
def fix_author(response):
# 不同页面的author html有所不同
author = response.css('#info > a:nth-child(2)::text').extract_first()
if not author:
author = response.css('#info > span > a::text').extract_first()
# 部分书籍没有作者
return author.replace('\n', '').strip() if author else '无'
def fix_summary(response):
summary_list = response.css('#link-report > div:nth-child(1) > div > p::text').extract()
summary = ''
for s in summary_list:
summary += s
return summary
def fix_author_intro(response):
author_intro_list = response.css('.related_info > div:nth-of-type(3)') # 先定位到作者信息的div
author_intro_list = author_intro_list.xpath('.//p/text()').extract() # 利用xpath获取div下所有p标签中的内容
author_intro = ''
for s in author_intro_list:
author_intro += s
return author_intro
def fix_detail_tags(response):
tags = response.css('.indent span .tag::text').extract()
detail_tags = '|'.join(tags)
return detail_tags
六、存储到MySQL数据库
import csv
import pandas as pd
import pymysql
# 连接本地数据库
conn = pymysql.connect(host='localhost',
user='zhou',
password='123456',
database='book_db',
charset='utf8')
cur = conn.cursor()
def writeBook():
with open('book3.csv', 'r', encoding='utf-8') as f:
read = csv.reader(f)
for line in list(read):
i = tuple(line)
print(i)
try:
sql = "insert into book(book_name, book_img, author, publisher, ISBN, book_rate, book_rate_number, book_summary, author_intro, detail_tags) values" + str(i)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
conn.commit()
cur.close()
conn.close()
writeBook()
def writeTag():
with open('tag3.csv', 'r', encoding='utf-8') as f:
read = csv.reader(f)
for line in list(read):
i = tuple(line)
print(i)
try:
sql = "insert into tag(book_big_tag, book_small_tag, ISBN) values" + str(i)
cur.execute(sql)
conn.commit()
except Exception as e:
print(e)
conn.commit()
cur.close()
conn.close()
writeTag()七、爬取结果

八、后言
作者水平有限,爬取时被封了好几次IP,最后只爬了八百多条
可以设置随机延时/IP代理
有部分代码参考自scrapy爬取豆瓣读书数据 - 简书 (jianshu.com)