c语言代码
目录
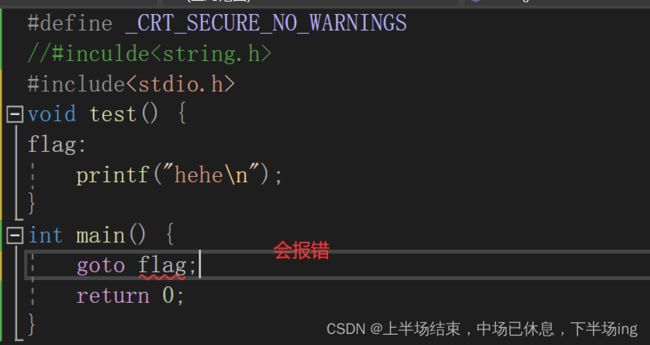
1.利用goto的关机程序
2.交换两个整数(容易出现的错误)
2.1 错误示范
2.1.1 错误的原因
3.函数调用进行折半查找
3.1错误版本
3.1.1错误原因
4.写一个函数,每调用一次这个函数,就会将num的值增加1。
4.1使用传值进去
5.有关print的操作题
6.字符串比较
7.编写函数不允许创建临时变量,求字符串的长度。
7.1创建count变量来实现代码
7.2 利用递归来正确实现代码
8.求第n个斐波那契数。(不考虑溢出)
8.1 利用递归(效率很慢)
8.2 利用循环(不考虑栈溢出,因为这里输入小一点的数正确,大一点就会栈溢出,结果错误,但是效率很快)
9.冒泡排序
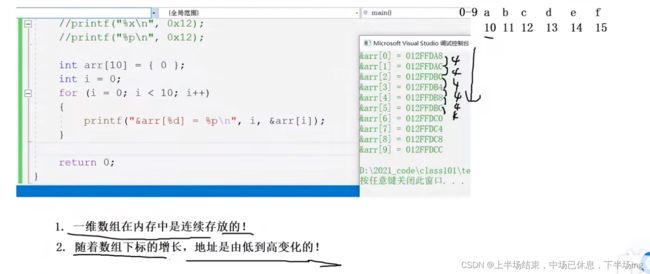
10.数组名的不同
11.操作符
11.1 /
11.2 << >>
11.3 按位与 &
11.4 按位或 |
11.5 按位异或
11.6例题
11.7求传参的地址大小
11.8按位与&&的计算
11.9逗号表达式
11.10整形提升
11.11算数转换
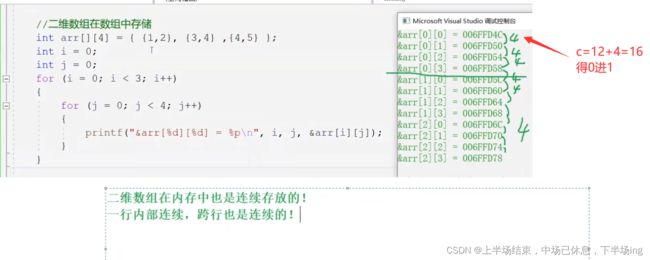
12.数组的习题
12.1
12.2
12.3
12.4实现函数init ()初始化数组为全0实现print()打印数组的每个元素,实现reverse ()函数完成数组元素的逆置。
13.指针类型不同带来的差异
1.指针无论定义为什么类型,都是占用内存4个字节(32位),8个字节(64位)
2.指针类型决定了指针解引用的权限有多大
3.指针类型决定了,指针走一步,能走多远(步长)
13.1野指针
13.2如何避免野指针
13.3指针相减
13.4
14.1
14.2数组名+1不一样
14.3数组和指针传参做题
14.4指针数组、数组指针
14.5 指针数组和数组指针在概念和用途上有明显的区别。
14.6一维数组传参
14.7二维数组传参
1.利用goto的关机程序
#define _CRT_SECURE_NO_WARNINGS
//#inculde 部分版本需要引用这个头文件
#include
int main() {
system("shutdown - s - t 60");
char arr[20] = { 0 };
flag:
printf("电脑在1分钟内关机,请输入我是猪来取消关机!");
scanf("%s", arr);
if (strcmp(arr, "我是猪") == 0) {
system("shutdown -a");
}
else {
goto flag;
}
return 0;
} 上述代码简单修改,利用while循环来实现关机.
#define _CRT_SECURE_NO_WARNINGS
//#inculde
#include
int main() {
system("shutdown - s - t 60");
char arr[20] = { 0 };
while (1) {
printf("电脑在1分钟内关机,请输入我是猪来取消关机!");
scanf("%s", arr);
if (strcmp(arr, "我是猪") == 0) {
system("shutdown -a");
break;
}
}
return 0;
} !!!! goto语句只能在一个函数范围内跳转,不能跨函数
2.交换两个整数(容易出现的错误)
2.1 错误示范
#define _CRT_SECURE_NO_WARNINGS
//#inculde
#include
int swap(int x, int y) {
int z = 0;
z = x;
x = y;
y = z;
}
int main() {
int a = 10;
int b = 20;
printf("交换前:a=%d b=%d\n", a, b);
swap(a, b);
printf("交换后:a=%d b=%d\n", a, b);
return 0;
} 
2.1.1 错误的原因
之所以出现错误是因为函数传参的过程中,a b本身是有地址空间的,但是x y也开辟了地址空间,这就导致他们的地址空间并不一样!
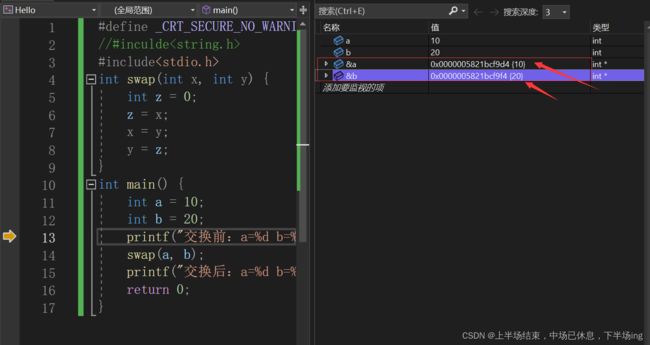
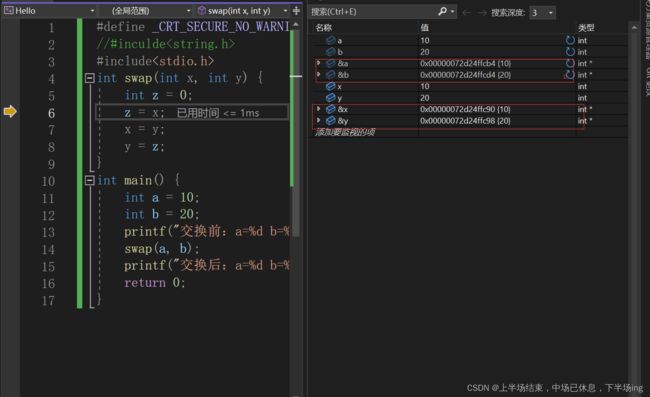
这里相当于给x y开辟了空间,x中放的是10,y中放的是20.然后z也开辟了空间,在执行swap函数中,尽管x y实现了互换,但是根本没有影响a b的值,跟a b都不是一个空间的地址。所以导致了a b的值没有实现互换!
2.1.2 修改正确的版本(利用指针)
举例
#include
int main() {
int a = 10;//4个字节的空间
int* pa = &a;//pa就是一个指针变量
*pa = 20;
printf("%d\n", *pa);
printf("%d", a);
return 0;
} 正确版本
#include
void swap(int *pa, int *pb) {//void 不用写返回,也可以直接写人return;
int z = *pa;
*pa = *pb;
*pb = z;
}
int main() {
int a = 10;
int b = 20;
printf("交换前:a=%d b=%d\n", a, b);
swap(&a, &b);//传入地址
printf("交换后:a=%d b=%d\n", a, b);
return 0;
} 
3.函数调用进行折半查找
#include
int binary_search(int a[], int k, int s) {
int left = 0;
int right = s - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (a[mid] > k) {
right = mid - 1;
}
else if (a[mid] < k) {
left = mid + 1;
}
else {
return mid;
}
}
return -1;
}
int main(){
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int key = 7;
int sz = sizeof(arr) / sizeof(arr[0]);
int ret = binary_search(arr,key,sz);
if (-1 == ret) {
printf("找不到\n");
}
else {
printf("找到了,下标是:%d\n",ret);
}
return 0;
} 3.1错误版本
#define _CRT_SECURE_NO_WARNINGS
#include
int binary_search(int a[], int k) {
int sz = sizeof(a) / sizeof(a[0]);//求数组个数,错误
int left = 0;
int right = sz - 1;
while (left <= right) {
int mid = (left + right) / 2;
if (a[mid] > k) {
right = mid - 1;
}
else if (a[mid] < k) {
left = mid + 1;
}
else {
return mid;
}
}
return -1;
}
int main(){
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int key = 7;
int ret = binary_search(arr,key);//不传sz,错误
if (-1 == ret) {
printf("找不到\n");
}
else {
printf("找到了,下标是:%d\n",ret);
}
return 0;
} ![]()
3.1.1错误原因
数组arr传参,实际传递的不是数组的本身,仅仅传过去了数组首元素的地址
实际上 int binary_search(int a[], int k)就等于 int binary_search(int *a, int k);int a[ ]就是挂羊头卖狗肉,实际上就是个指针,因此int sz = sizeof(a) / sizeof(a[0]);求得的sz就是4/4=1;再往下进行代码计算就肯定不对了!
而在int binary_search(int a[], int k)中int a[ ]中没写大小,如int a[10]是因为数组都没传过来,这里创建一个数组也没意义!
!!!!!所以函数内部需要参数部分传过来数组的个数,一定是在外面求好这个数组个数在传过去,而不是在函数内部在去求!实际上数组传参就是一种传址的效果!
4.写一个函数,每调用一次这个函数,就会将num的值增加1。
#include
void Add(int* p) {
(*p)++;
}
int main() {
int num = 0;
Add(&num);
printf("%d\n", num);
Add(&num);
printf("%d\n", num);
Add(&num);
printf("%d\n", num);
return 0;
} 
函数内部想改变函数外部,一般都采用传址操作!
4.1使用传值进去
#include
int Add(int p) {
p++;
return p;
}
int main() {
int num = 0;
int a=Add(num);
printf("%d\n", a);
int b = Add(num);
printf("%d\n", b);
int c = Add(num);
printf("%d\n", c);
return 0;
} 
5.有关print的操作题
#include
int main()
{
printf("%d", printf("%d",printf("%d", 43)));
return 0;
} ![]()
结果是4321;原因是因为print返回值类型为

函数返回的是打印在屏幕上的字符的个数
所以
6.字符串比较
字符串比较时,1.如
不能直接用 == ,这里需要引入头文件 #incolude
而如果出现两个字符串比较,如str1=“abcd”,str2=“abce”,比较结果为<0,因为字符串比较,实际上比较的是ascii码值,比较的结果有3个为<0,>0,=0.
2.如果定义的是一个数组,那么在scanf中不用加&取地址符。因为对应的password就是数组名,数组名本身就是一个地址了。

3.
这里红色方框比较的是两个字符串的首字符的地址,并没有比较内容。地址比较是没有意义的!
7.编写函数不允许创建临时变量,求字符串的长度。
7.1创建count变量来实现代码
#include
int my_strlen(char* str)//*str解引用得到值
{
int count = 0;
while (*str != '\0') {
count++;
str++;//str代表的数组下标,也就是字母的地址
}
return count;
}
int main()
{
char arr[] = "cxs";
//['c']['x']['s']['\0']
//模拟实现一个strlen函数
printf("%d\n",my_strlen(arr));//数组传参,传的是数组的首地址
return 0;
} 7.2 利用递归来正确实现代码

#include
int my_strlen(char* str)
{
if(*str != '\0') {
return 1 + my_strlen(str + 1);//也可以是str+1对应的是下一个字母的地址,然后在传给char *atr
}
else {
return 0;
}
}
int main()
{
char arr[] = "cxs";
//['c']['x']['s']['\0']
//模拟实现一个strlen函数
printf("%d\n",my_strlen(arr));//数组传参,传的是数组的首地址
return 0;
} 8.求第n个斐波那契数。(不考虑溢出)
8.1 利用递归(效率很慢)
#include
int Fib(int n) {
if (n <= 2) {
return 1;
}
else {
return Fib(n - 1) + Fib(n - 2);
}
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d\n", ret);
return 0;
} 8.2 利用循环(不考虑栈溢出,因为这里输入小一点的数正确,大一点就会栈溢出,结果错误,但是效率很快)
#include
int Fib(int n) {
int a = 1;
int b = 1;
int c = 1;//c赋值为1;是因为n<2时,直接返回c的值刚好是1!
while (n > 2) {
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main()
{
int n = 0;
scanf("%d", &n);
int ret = Fib(n);
printf("%d\n", ret);
return 0;
} 
9.数组部分
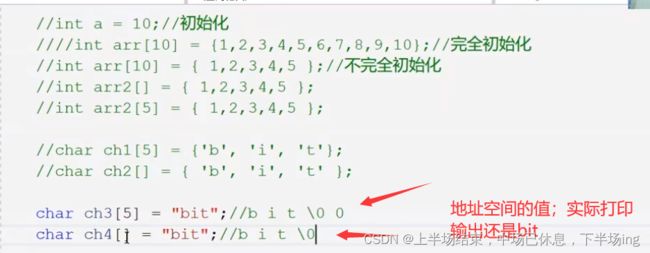

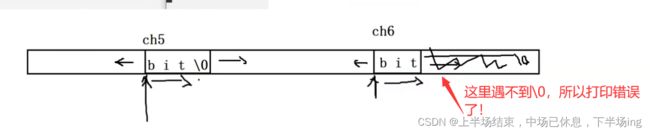
也会导致求长度不对


#include
int main(){
int arr[3][4] = { {1,2},{3,4},{5,6} };
int i = 0;
int j = 0;
int a = arr[0][0];
int* p = &arr[0][0];//这里可以看出p是指针,*p解引用是一个值,但是arr想要与指针比较,默认也是指针,需要&解引用
for (i = 0; i < 3; i++) {
for (j = 0; j < 4; j++) {
printf("%d", *p);
p++;
}
}
printf("\n%d", a);
return 0;
} 
9.冒泡排序
#include
void mao_pao(int a[], int k) {
int i = 0;
int temp;
for (i; i < k - 1; i++) {//会比较9轮
int j = 0;
for (j; j < k - 1 - i; j++) {//每轮会比较的次数
if (a[j] > a[j + 1]) {
temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
}
}
int main() {
int arr[] = { 9,8,7,6,5,4,3,2,1,0 };
int len = sizeof(arr) / sizeof(arr[0]);
mao_pao(arr, len);
for (int i = 0; i < len; i++) {
printf("%d", arr[i]);
}
return 0;
} 10.数组名的不同

尽管我们看到三个的地址都一样,但是实际上2和3才是真正意义一样的,因为1虽然代表的是整个数组,但是他的地址也是从第一个元素开始,因此地址才和2 3一样!下面通过例子看看1和2 3 是不一样的!

可以看出,1中的&arr+1,因为是数组地址加1,50-28=28,但是是16进制,就是0x28换算十进制就是40,但是2中的arr+1,是数组首元地址加1,十进制是4。也就是说1中的&arr+1是整个数组地址加1,而2中的arr+1是首元地址+1.
11.操作符
11.1 /

可以看出在求b的时候,尽管是float类型,得到的仍然是1,这是因为6/5得到的是1,然后1用float的类型输出就是1.000000.
11.2 << >>
左移操作符:左边丢弃,右边补0

右移操作符:如果移动的为正数

右移操作符:如果移动的为负数

而程序运行会发现结果为-1,走的是算术右移!,也就是最高位补的是原符号位!
!!!对于正数,原码补码反码相同
11.3 按位与 &

11.4 按位或 |

11.5 按位异或
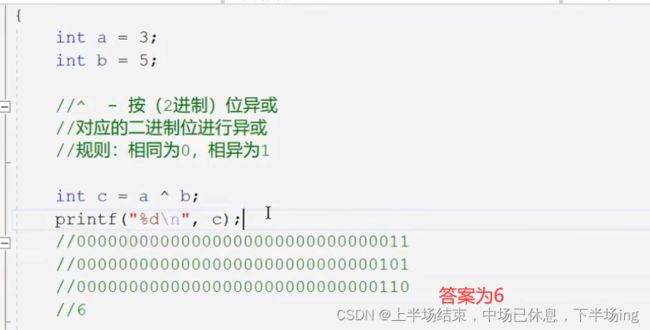
注意 :他们3个必须是整数来进行操作
11.6例题
不使用第三方变量,进行a,b交换
方法一:(有缺陷,因为整数的值有上限,当a b的值几乎快达到上限时,相加的话一定超出上限,就肯定不对 )

方法二:利用异或(没有产生进位,永远不会溢出)

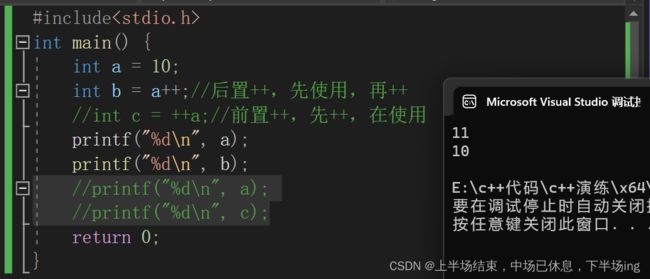
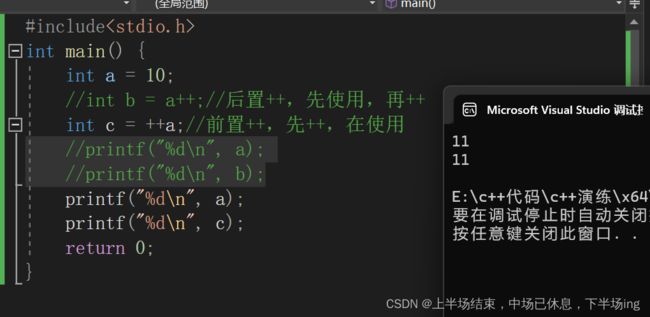
11.7 a++和++a
11.7求传参的地址大小

这里(1)是40,(3)是10
传地址过去后,(2)在32位系统下地址大小是4,64位是8,(4)在32位系统下地址大小是4,64位是8.这里需要知道(4)的地址传过去,虽然是char类型, 但是指针大小不论类型,不管什么类型的指针变量,都是用来存放地址的,只有32位二进制序列或者64位的二进制序列,所以大小都是那么大,不是4就是8。
11.8按位与&&的计算

结果为1 2 3 4;
这是因为在&&中,只要有一个假,那结果就是假,也就是说a&&b,如果a是假,那就没有必要去计算b,因此int c=a&&b;a是0,b无论是那个整数,结果c都是0;
因此i=a++&&++b&&d++中,a++先使用,再++,a是0,在++是1.右面的&&++b&&d++没必要计算了,直接得到i=0;所以计算结果就相当于i=a++;所以i=0;a=1;b=2;c=3;d=4.
而如果把a改为等于1;结果就是2 3 3 5;
这是因为i=a++&&++b&&d++中,a为先使用在++,a为1,为真,在++是2.那么后面的&&++b&&d++也要计算,后面都为真,因此i=1;a=2;++b,b=3;d++,d=5.
11.9按位|的计算

结果为2 2 3 4;
这是因为在||中,只要有一个真,那结果就是真,也就是说a&&b,如果a是真,那就没有必要去计算b,因此int c=a&&b;a是1,b无论是那个整数,结果c都是1;
因此i=a++&&++b&&d++中,a++先使用,再++,a是1,右面的&&++b&&d++没必要计算了,直接得到i=1;所以计算结果就相当于i=a++;所以i=1;a=2;b=2;c=3;d=4.

而如果把a改为等于0;结果就是1 3 3 4;
这是因为i=a++&&++b&&d++中,a为先使用在计算0,为假,在计算就是1.那么还要计算后面的&&++b&&d++,结果&&++b是先计算在使用为3,为真,那么后面的&&d++就不用计算了,因为相当于计算的是i=a++&&++b,,因此i=1;a=1;b=3;
11.9逗号表达式

巧妙的使用方式

11.10整形提升

在计算 char c=a+b;a和b都是一个字符串类型,没有达到整型的大小,因此需要进行整型提升,整型提升,要提升它的二进制,a=3,但是a放在char类型中,只能放8位,因此是00000011;b为01111111;在计算c=a+b;整型提升,是提升高位,因此a为0000000,00000000,00000000,00000011,b为00000000,00000000,00000000,01111111,c为:
00000000,00000000,00000000,00000011
00000000,00000000,00000000,01111111
00000000,00000000,00000000,100000010
c里面也只能存放8个比特位,截断后为100000010。,c不是个整型,进行整型提升
提升高位为
11111111,11111111,11111111,100000010---补码
11111111,11111111,11111111,100000001---反码
100000000,00000000,00000000,01111110---原码
因为计算机内存中存的是补码,控制台输出的是原码。
!计算时都是要用补码计算a,b的,这里因为a,b的值都是正的,所以在计算截断后的8位直接就写出了它们的原码形式来做,因为正数三码都一样,要是负数,就不能直接写原码来求截断在补高位提升为整型,需要计算出补码在求截断在补高位提升为整型,
这里其实就两个类型需要整型提升,一个是short,还有一个是char。

这里+c,-c参与 整型计算,所以大小为整型大小。而在求!c的时候,vs编译器给出的答案是1,实际上应该是4,gcc编译器比较标准为4
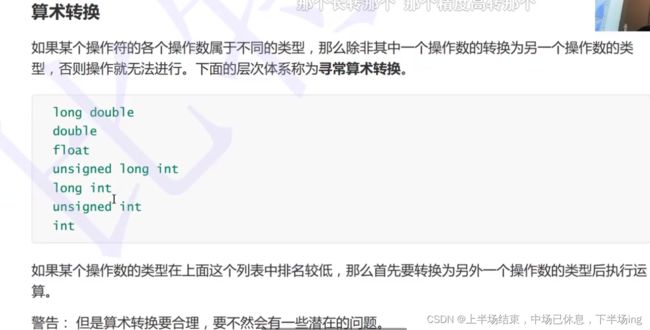
11.11算数转换
12.数组的习题
12.1

这里(3,4)是逗号表达式,实际上就等于4!
12.2

答案为10 9
12.3

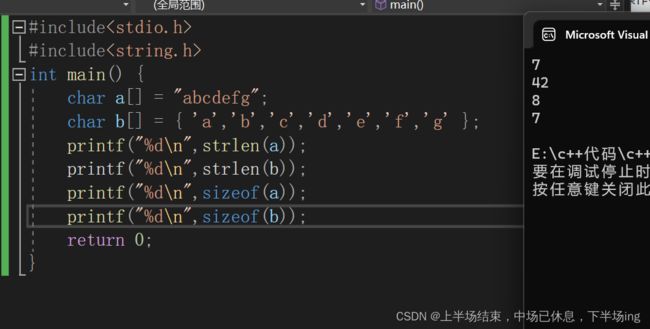
我们可以看出双引号中的字符串是默认带\0的,因此求长度是7,但是b中是大括号是没有遇到\0的,因此他的长度是随机值!求sizeof求的是内存中的字节数,a中多一个\0,所以数组的长度大于b!字符串数组求长度实际就是求内存字节数(不一定对)
另外一个例子: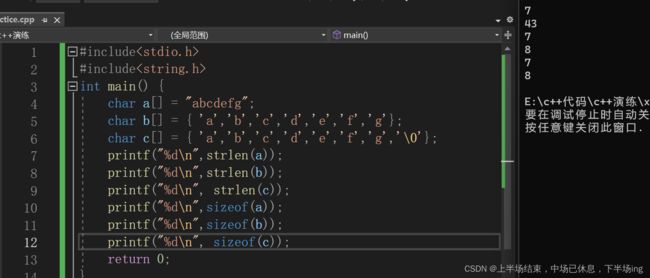
12.4实现函数init ()初始化数组为全0实现print()打印数组的每个元素,实现reverse ()函数完成数组元素的逆置。
#include
#include
void init(int a[], int s) {
for (int i = 0; i < s; i++) {
a[i] = 0;
}
}
void print(int b[], int s) {
for (int i = 0; i < s; i++) {
printf("%d", b[i]);
}
printf("\n");
}
void reserve(int c[], int s) {
int left = 0;
int right = s - 1;
while (left < right) {
int tmp = c[right];
c[right] = c[left];
c[left] = tmp;
left++;
right--;
}
}
int main() {
int arr[] = { 1,2,3,4,5,6,7,8,9,10 };
int sz = sizeof(arr) / sizeof(arr[0]);
print(arr, sz);
reserve(arr, sz);
print(arr, sz);
init(arr, sz);
print(arr, sz);
return 0;
} 13.指针类型不同带来的差异
1.指针无论定义为什么类型,都是占用内存4个字节(32位),8个字节(64位)
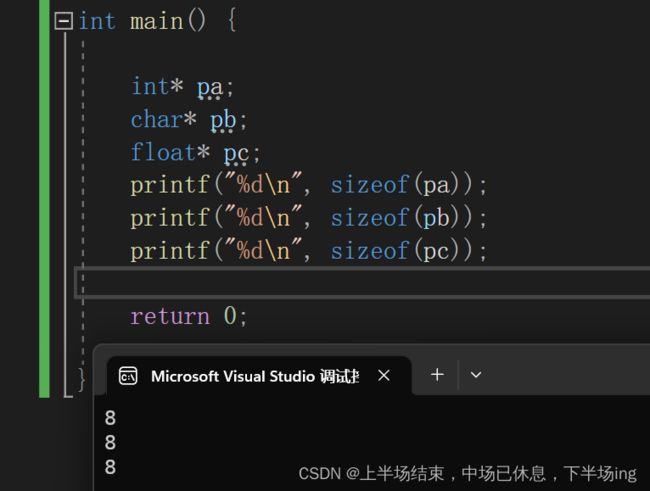
2.指针类型决定了指针解引用的权限有多大
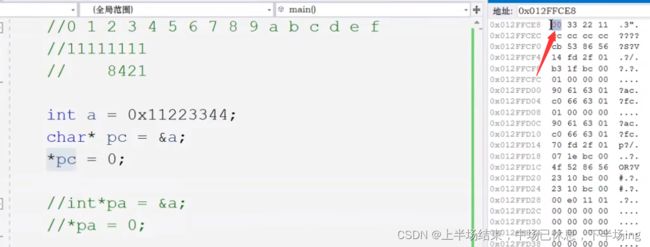
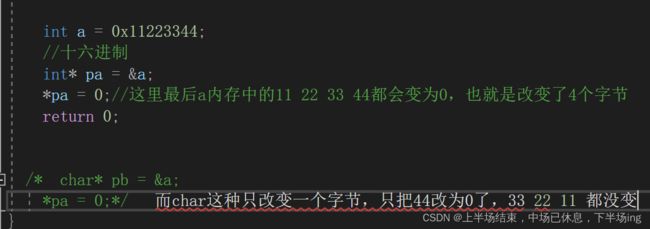
3.指针类型决定了,指针走一步,能走多远(步长)

举例子:
#include
using namespace std;
int main() {
int arr[10] = { 0 };
int* p = arr;//这里定义为int *p,改变的话就是跳过4个字节,下面的赋值1,会直接就是每个数组下标内存对应的的值都是1,因为int型,4个字节对应一个下标
int i = 0;
for(i = 0; i < 10; i++) {
*(p + 1) = 1;
}
return 0;
} #include
using namespace std;
int main() {
int arr[10] = { 0 };
char * p = arr;//这里定义为char *p,改变的话就是1个字节,下面的赋值1,会直接就是每个数组下标内存对应的4个字节00 00 00 00一个一个改为01,也就是循环4次相当于才赋值一个数字下标对应的值
int i = 0;
for(i = 0; i < 10; i++) {
*(p + 1) = 1;
}
return 0;
} 
也就是说指针跳过几个字节,跟指向的数组类型没关系,跟定义指针类型有关系!
13.1野指针
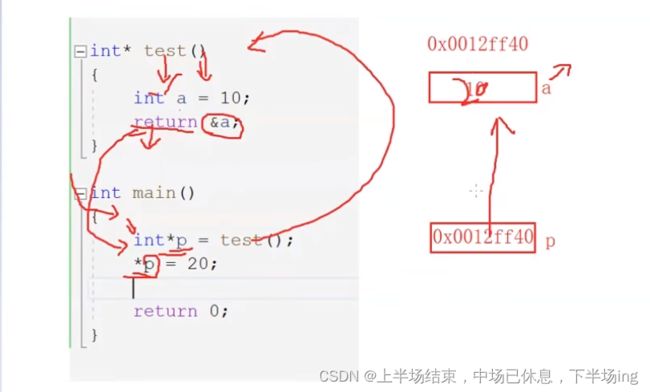
*p放的是a的地址,而a出了函数就被释放。因为它是局部变量。被释放就意味着这个地址不再是a的了,而在想修改20去找这个地址就不行了,它已经是一个野指针了!
13.2如何避免野指针

所以最好的方法就是当一个指针,你不知道指向哪里的时候,你可以指向空指针,当它指向的空间被释放后,也可以指向空指针,当他指向一个有效空间的时候,就给他一个有效的地址!
13.3指针相减
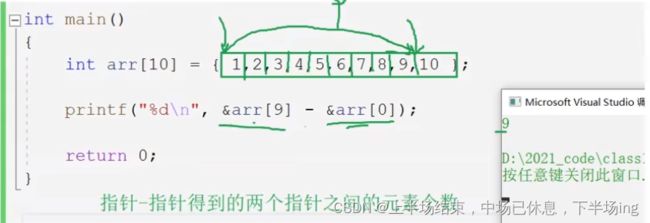
需要注意的是

13.4
(1)求字符串长度(计数器的方法)
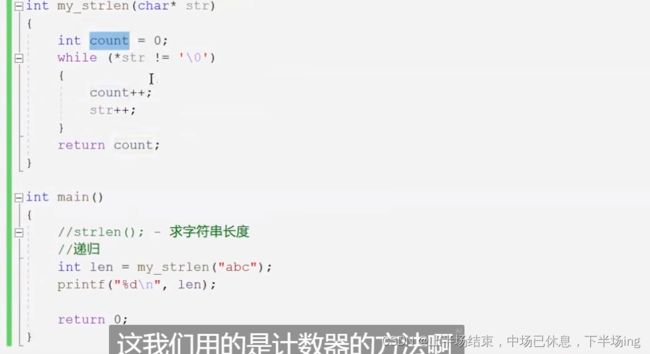
这里传的过去的是字符串的首地址!
(2)利用指针-指针来求长度

14.指针进阶
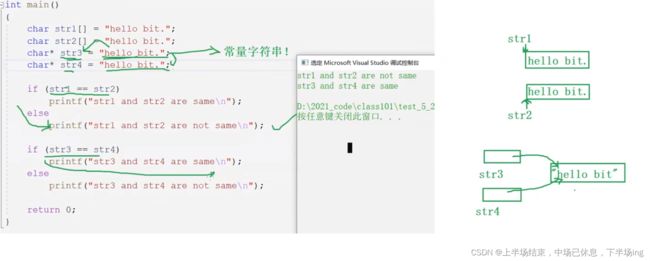
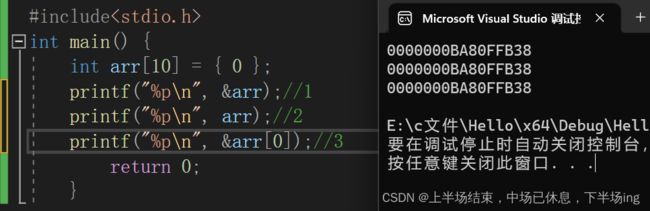
这里是因为1 2分贝分配了空间来存储hello bit。地址肯定不一样;
14.1

这里我们可以从1 2看到对应的写法,
3 中定义了一个整型数组,然后对数组采用指针的写法,&arr,那么钱前面就应该是*parr,但是数组指针也要有[10];但是直接写成*parr[10]是不对的,因为parr会与后面的[10]的结合,所以这就需要加上括号,表示是一个数组的指针(*parr)[10],然后因为前面定义的是一个数组,类型是int,所以最终是int (*parr)[10]=&arr;
4 中定义的是一个指针数组,double* d[5];
在这个声明中,d是一个数组,而数组的每个元素都是一个double*类型的指针。double*是一个指针,它指向一个double类型的值。所以,double*d[5]表示一个包含5个double*类型指针的数组。
你可以将这个数组想象成包含5个“链接”或“地址”的列表,每个“链接”都指向一个double类型的值。你可以通过数组的索引(从0开始)来访问这些指针,进而通过这些指针来修改或访问它们所指向的double类型的
因此&d前面应该是(*pa)[5];,但是前面是指针类型的double,因此最终是double*( *pd)[ 5] = &d;
在这个语句中,pd是一个指向包含5个元素的数组的指针。每个数组的元素是一个double*类型的指针,这样的指针可以存储double类型变量的地址。因此,整个数组可以用于存储一系列指向double类型变量的指针。
然后,&d获取变量d的地址,这个地址被赋值给了指针数组pd。所以,pd现在存储的是变量d的地址。
总的来说,double*( *pd)[5] = &d;创建了一个指针数组并将d的地址存储在了这个数组中。
14.2数组名+1不一样
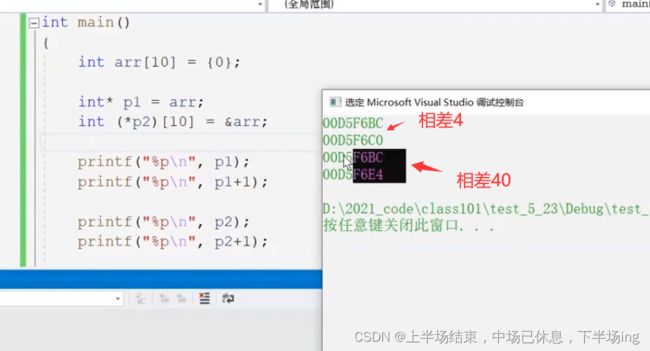
虽然第一个地址都一样,但是可以看出实质上他们还是不一样的,p1+1是相差一个整型,p2+1相差的是一个数组类型大小!
14.3数组和指针传参做题

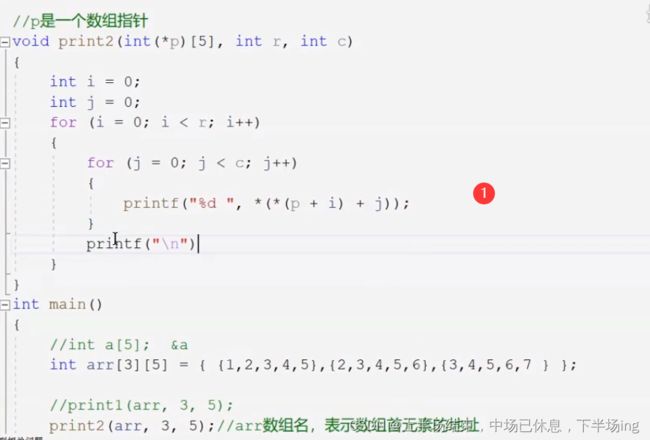
可以看出1和2不同,1是利用二维数组做的,2是利用地址做的。
arr既可以代表整个数组传过去,也可以作为第一个元素或者第一个地址,2中利用arr传过去是数组中第一个元素中的地址,也就是第一行的地址。即{1,2,3,4,5}的地址传过去。
而 中,i代表行,j代表列,p是传过来的第一行元素的地址,p+i相当于某一行,在解引用*(p+i)就找到了某一行的数组名,如arr[0];arr[1];arr[2];再加上j对应的是每一行元素的地址,再解引用就是元素值。
中,i代表行,j代表列,p是传过来的第一行元素的地址,p+i相当于某一行,在解引用*(p+i)就找到了某一行的数组名,如arr[0];arr[1];arr[2];再加上j对应的是每一行元素的地址,再解引用就是元素值。
14.4指针数组、数组指针


(*parr3[10]):这表示parr3是一个数组,包含10个元素,每个元素是一个指针。这些指针指向的数组必须具有5个整型元素。int parr2[10][5] = { {1, 2, 3, 4, 5}, {6, 7, 8, 9, 10}, //... }; int (*parr3[10])[5] = { parr2[0], parr2[1], //... };
14.5 指针数组和数组指针在概念和用途上有明显的区别。
-
数组指针是一个指向数组的指针。换句话说,它是一个指针变量,其值是一个数组的首地址。例如,在C语言中,你可能有如下的定义:
int arr[5] = {1, 2, 3, 4, 5}; int *ptr = arr;这里,
ptr是一个指针,它指向数组arr。如果你有一个数组指针p,例如,上述例子中,p+1将会指向数组的第二个元素arr[1]。 -
指针数组则完全不同,它是一个数组,其元素是指针变量。也就是说,每个数组元素都是一个指针。例如,在C语言中,你可能有如下的定义:
int a = 10, b = 20, c = 30; int *ptr[3] = {&a, &b, &c};这里,
ptr是一个数组,该数组的每个元素都是一个指针,分别指向a、b和c。总的来说,数组指针是用来指向整个数组的,而指针数组则是存储多个指针的数组。这两者在内存中的存储方式和用途是不同的。
14.6一维数组传参
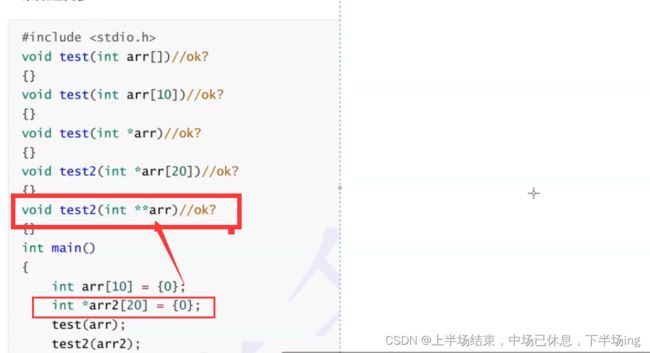
以上都是对的!
最后一个数组名存放第一个首元素的地址,就是int*的地址,(因为arr2是指针数组,数组中每个元素都是指针),int*的地址就是一级指针的地址,你取了一级指针的地址那不就是二级指针**arr(通俗来说int *arr[20]是整型指针数组,,里面的20个都是整型指针,那进行传址,所以test2就应该是int **arr)这里要注意:[]的优先级要高于*号的,所以就相当于是int *(arr[20])

14.7二维数组传参
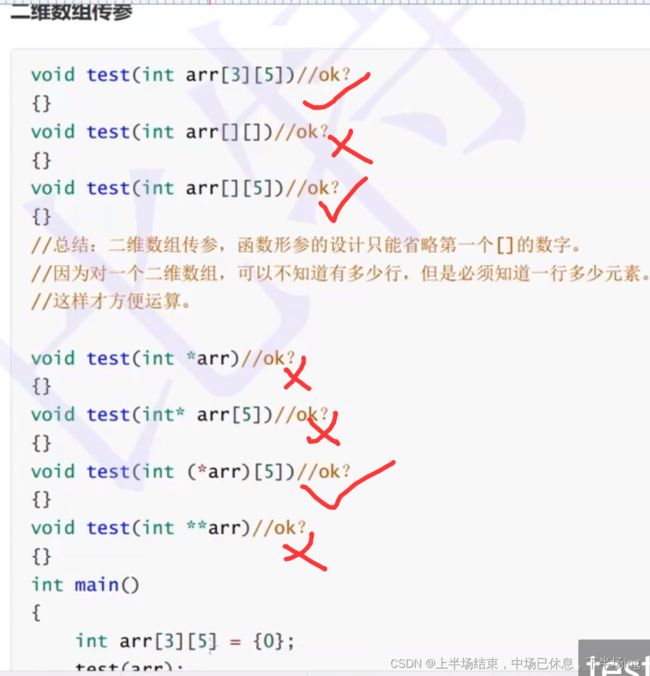
*arr 数组名表示首元素的地址应该是第一行的地址,因此肯定不对
Int *arr[5]写的是一个指针数组,(解释:代表每个元素是一个指针)。不是个数组的指针,又不是二维数组,肯定不行
Int(*arr)[5]是数组的指针,代表*arr是个指针,指向一维数组的5个元素,每个元素是整型,而数组arr代表首元地址,就是一维数组的地址,又正好是5个整型元素,刚好搭配!
不能写成二级指针,因为传过去的是一维数组的地址
14.8二级指针传参实列

15.函数指针
#include
int sum(int x, int y) {
return x + y;;
}
int main() {
//printf("%p\n",sum); //00007FF6B76D1429 一样
//printf("%p\n", &sum); //00007FF6B76D1429.
int (*p)(int, int) = ∑//函数指针;或者int (*p)(int, int) = sum;
int ret = (*p)(3, 5);//解引用
printf("%d", ret);
return 0;
} int (*p)(int, int) = ∑//函数指针;或者写为int (*p)(int, int) = sum;说明sum能放到p里面去;前提我们可以写为int ret=sum(3,5);因为p是个指针,&sum=p;sum=&sum,所以sum=p;(这里不懂,可以参考数组指针那种定义,int(*p)[5]=&arr.p就是指向数组的指针!)那么我们也可以写为int ret=p(3,5);所以就有3种写法: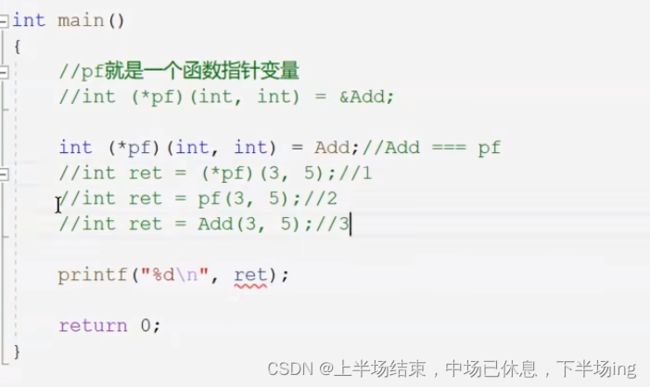
数组名!=&数组名(数组名代表的是首元素的地址,尽管他们第首元素地址一样,但是后面计算就不一样)
函数名==&函数名
//例子2
#include
void test(char* s) {
}
int main() {
void (*p)(char*) = &test;
return 0;
} 15.2(* (void(*)())0)();

15.3函数指针数组
#include
int sum(int x, int y) {
return x + y;;
}
int a(int x, int y) {
return x - y;;
}
int main() {
int (*p1)(int, int) = sum;
int (*p2)(int, int) = a;
int (*parr[2])(int, int) = { sum,a };//函数指针数组(可以放同类型的函数指针)
return 0; 15.4各类求大小(区分数组大小,元素大小,地址大小,在注意双引号和单引号)







 上面的图其实就是这样的!
上面的图其实就是这样的!

--------------------------------------------------------------------------------------------------------------------------------

1.//48 解释:3*4*sizeof(int)
2.//4 解释:代表第一行第一个元素的大小
3.//16解释:a[0]单独放到sizeof内部,表示第一行的地址,第一行4个元素所以16
4.//4解释:a [0]作为数组名并没有单独放在sizeof内部,也没取地址,所以a [0]就是第一行第一个元素的地址,a [0]+1,就是第一行第二个元素的地址
5.//4 解释:* (a [0]+ 1)是第—行第二个元素
6.// 4 解释:a是二维数组的数组名,并没有取地址也没有单独放在sizeof内部,所以a就表示二维数组首元素的地址,即:第一行的地址。 a + 1就是二维数组第二行的地址
7./ / 16解释: a+1是第二行的地址,所以*(a+1)表示第二行,所以计算的就是第2行的大小
8./ / 4解释: a [0]是第一行的数组名,&a [0]取出的就是第一行的地址,&a [0]+1就是第二行的地址
9. / /16 &a [0]+1就是第二行的地址* (&a [0]+1)就是第二行,所以计算的第二行的大小
10. //16解释: a作为二维数组的数组名,没有&,没有单独放在sizeof内部// a就是首元素的地址,即第一行的地址,所以*a就是第一行,计算的是第一行的大小
11. / / 16解释: a[3]其实是第四行的数组名(如果有的话) 所以其实不存在,也能通过类型计算大小的
15.5笔试题
15.5.1

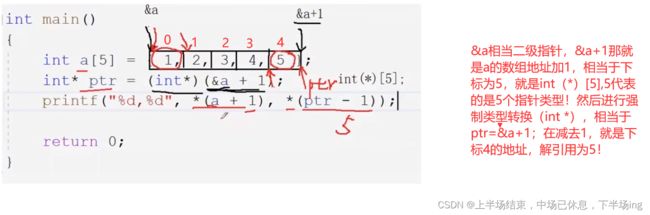
&a是整个数组的地址,+1就是&a+1的地址,地址就是编号,然后强制类型转换,为什么要转换呢,因为取地址取出的是数组的地址。数组的地址它应该是数组指针类型,所以进行转换
16.内存
16.1字符分类函数和字符转换函数

16.2内存函数-memcpy
 这里指的是把arr1的20个字节放到arr2中去。即arr2就变为{1,2,3,4,5,0,0,0,0,0};
这里指的是把arr1的20个字节放到arr2中去。即arr2就变为{1,2,3,4,5,0,0,0,0,0};
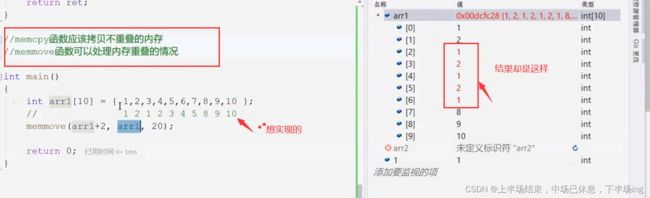
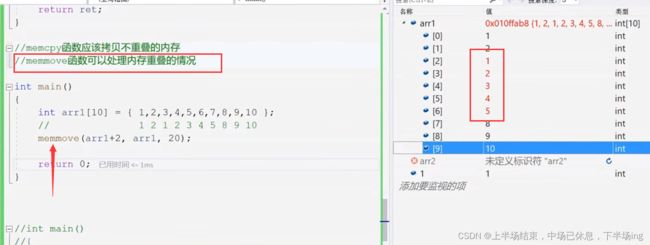
16.3memeove函数
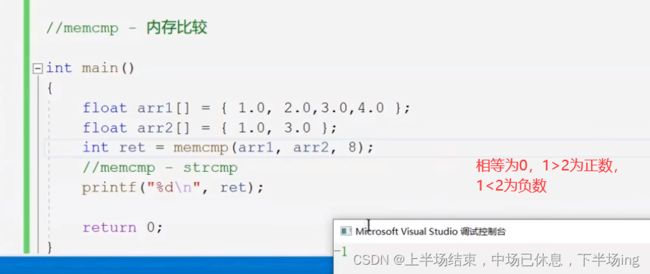
16.4memcmp内存比较
16.5memset

c++系列
17.结构体
17.1
