实战——幂等性+海量数据处理
文章目录
- 前言
- 一、服务幂等
-
- 1.防止订单重复下单
-
- 1.1 场景如下:当用户在提交订单的时候
- 1.2 重复下单解决方案
- 1.3案例一幂等性总结
- 2 防止订单ABA问题
-
- 2.1 场景如下:当在修改订单用户信息的时候发生服务器或者网络问题导致的重试
- 2.2 ABA问题解决方案
- 2.3 业务ABA问题总结
- 二、海量数据处理
-
- 1.读写分离
- 2.分库分表
- 3 读写分离和分库分表实现方式
- 4. 归档历史数据(拆)
- 总结
前言
在微服务架构中,我们要考虑网络或者服务器中各种不确定的因素导致重试给我们系统带来的问题(对于重试机制是不可避免的,所以我们要考虑到服务幂等性)。
一、服务幂等
对于服务幂等性,我们大致有两大类方式:
- 通过设计,保证我们的操作一直是幂等的。如update tableA set count = 10 where id = 1(这条sql就一直是幂等的执行无数次结果都是10。这种的局限性比较大,难试用于各种业务)
- 通过三方的一致性存储,如mysql的主键冲突,引入版本号
1.防止订单重复下单
1.1 场景如下:当用户在提交订单的时候
- I:用户连续点击两次
- II: 当服务器或者网络波动时候,导致我们的请求重试

网络或者服务器导致重试的机制的例子

1.2 重复下单解决方案
使用三方存储的一致性,主键冲突,保证下单的一致性
-
- 前端按钮置灰–该方案
仅能解决用户侧产生错误操作造成的问题
- 前端按钮置灰–该方案
-
- 归根到头来我们还是需要通过后端来解决网络重试的问题
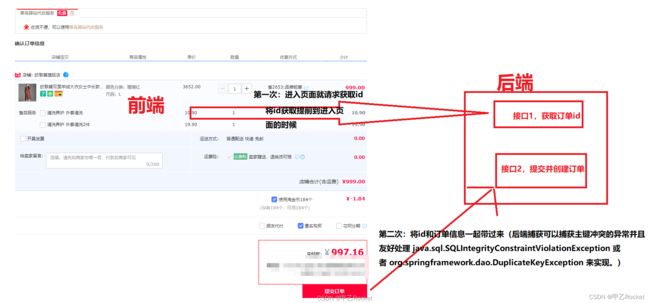
- 2.1 使用mysql的
一致性存储来解决问题,主键冲突来控制。并且我们要把订单id的获得进行提前,不是在提交生成订单的时候获得id,而是在进入订单页面的时候就获取id,给到前端。在提交订单的时候,同时把id当作参数传过来。
1.3案例一幂等性总结
- 以订单生成为例子,通过数据库的主键冲突来完成,保证幂等性
- 以此类推,以后我们也有一些场景为了保证幂等性,我们也可以用三方存储的一致性完成,如以下的业务场景
- 2.1 支付场景
- 2.2 某些保证要保证幂等性的增删改操作
2 防止订单ABA问题
此业务的ABA问题和并发中的ABA问题有异曲同工之妙
2.1 场景如下:当在修改订单用户信息的时候发生服务器或者网络问题导致的重试
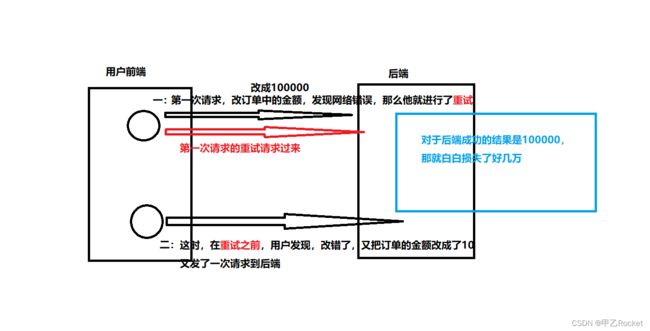
2.2 ABA问题解决方案
-
- 在并发时我们解决ABA的问题是通过版本号来解决并发ABA问题的
-
- 对于这种订单场景造成的ABA问题我们同样可以使用版本号的问题来解决

注意:
对订单表中添加version字段

- 对于这种订单场景造成的ABA问题我们同样可以使用版本号的问题来解决
主要的sql具体的 SQL 语句参考如下:
UPDATE orders_table set tracking_number = 666,version = version + 1 WHERE version = ?;
// 这个version就是我们在编辑页面后端返回的值版本,同时更新的时候版本号加一,如果重复的的话,根据条件更新不能成功
2.3 业务ABA问题总结
对这种订单、支付等重要业务我们要解决ABA问题,也是保证幂等性问题的一种(在多次操作只能有一种结果)
二、海量数据处理
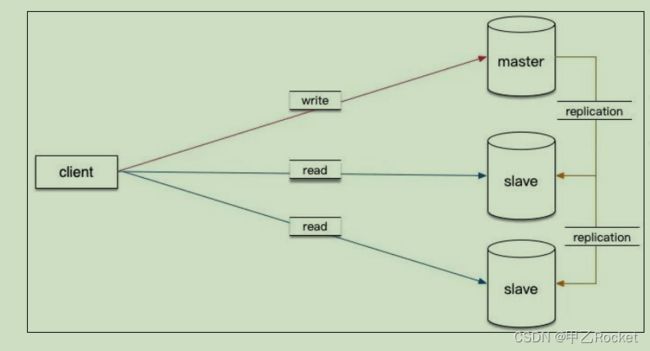
1.读写分离
当系统的用户数越来越多时,读写分离应该是首要考虑的
扩容方案。读写分离是提升 MySQL 并发能力的首选方案。
- 将写请求打到主库中
- 将读请求,打到不同的从库中。(因为大部分的系统读写比例大致是9:1)
注意点:读写分离的数据不一致问题
- 对应这种读写分离的架构,我们很难保证主库和从库之间数据的强一致性(mysql的复制【半同步和异步】都不能保证主库和从库之间的强一致性)。
- 所以对应上面的问题,我们可以从业务上来解决,比如当我们订单支付成功的情况下,我们先跳转到支付成功页面,然后再跳转到订单页面。保证用户看到的数据的正确性
2.分库分表
分库分表:分不同的数据库实例,分不同的表。分库分表这种方案是对应数据实在没办法处理的情况最后没办法才会去使用。原则:能不拆就不拆,能少拆就少拆。(越多这种维护越复杂)。我们大部分使用缓存来解决,分库分表是最后的选择。
分库分表条件
第一点如果数据量太大,就分表;第二点如果并发请求量高,就分库- 如果是那些
数据更新后需要立刻查询的业务,当这种业务过多并且没办法避免的情况下
-
分库分表的预估
结合我们的订单数据量和B+树来解决(B+树是三层比较快)
在设计系统,我们预估订单的数量每个月订单 2000W,一年的订单数可达2.4 亿。而每条订单的大小大致为 1KB,按照我们在 MySQL 中学习到的知识,为了让 B+树的高度控制在一定范围,保证查询的性能,每个表中的数据不宜超过2000W。在这种情况下,为了存下 2.4 亿的订单,我们似乎应该将订单表分为 16(12 往上取最近的 2 的幂)张表。
但是这样设计,有个问题,我们只考虑了订单表,没有考虑订单详情表。我们预估一张订单下的商品平均为 10 个,那既是一年的订单详情数可以达到 24亿,同样以每表 2000W 记录计算,应该订单详情表为 12(120 往上取最近的 2的幂)张,而订单表和订单详情表虽然记录数上是一对一的关系,但是表之间还是一对一,也就是说订单表也要为 128 张。经过再三分析,我们最终将订单表和订单详情表的张数定为 32 张。 -
分片键选择
因为我们要把不同的数据,分开存储到不同的表中,那我们就需要一个分片键来完成分表的效果。那对我们的分片键就很重要
如图
- 我们在存储的时候要完成分表
- 在查询的时候为了避免每张表不全部扫描,我们的的分片键就特别重要了。
考虑的点如下:
- 1 长度,因为作为id,长度不能太长
- 2 我们在查询的时候,有哪些条件。以淘宝为例
订单id+用户id+商家id组装成id进行分片通过基因法进行分表
// 这里也比较容易看出来,就是拿会员id和订单id进行拼装完成分片键
@Override
public Long generateOrderId(Long memberId) {
// 短的订单id
String leafOrderId = unqidFeignApi.getSegmentId(OrderConstant.LEAF_ORDER_ID_KEY);
// 会员id
String strMemberId = memberId.toString();
String OrderIdTail = memberId < 10 ? "0" + strMemberId
: strMemberId.substring(strMemberId.length() - 2);
log.debug("生成订单的orderId,组成元素为:{},{}", leafOrderId, OrderIdTail);
return Long.valueOf(leafOrderId + OrderIdTail);
}

2. 分表查询(分片键算法实现类)
public class OmsOrderShardingAlgorithm implements ComplexKeysShardingAlgorithm<String> {
/* 订单编号列名 */
private static final String COLUMN_ORDER_SHARDING_KEY = "id";
/* 客户id列名*/
private static final String COLUMN_CUSTOMER_SHARDING_KEY = "member_id";
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
ComplexKeysShardingValue<String> complexKeysShardingValue) {
/*处理 = 以及 in */
if (!complexKeysShardingValue.getColumnNameAndShardingValuesMap().isEmpty()) {
Map<String, Collection<String>> columnNameAndShardingValuesMap
= complexKeysShardingValue.getColumnNameAndShardingValuesMap();
if(columnNameAndShardingValuesMap.containsKey(COLUMN_ORDER_SHARDING_KEY)
||columnNameAndShardingValuesMap.containsKey(COLUMN_CUSTOMER_SHARDING_KEY)){
/*获取订单编号*/
Collection<String> orderSns = complexKeysShardingValue.getColumnNameAndShardingValuesMap()
.getOrDefault(COLUMN_ORDER_SHARDING_KEY, new ArrayList<>(1));
/* 获取客户id*/
Collection<String> customerIds = complexKeysShardingValue.getColumnNameAndShardingValuesMap()
.getOrDefault(COLUMN_CUSTOMER_SHARDING_KEY, new ArrayList<>(1));
/*合并订单id和客户id到一个容器中*/
List<String> ids = new ArrayList<>(16);
if (Objects.nonNull(orderSns)) ids.addAll(ids2String(orderSns));
if (Objects.nonNull(customerIds)) ids.addAll(ids2String(customerIds));
return ids.stream()
/*截取 订单号或客户id的后2位*/
.map(id -> id.substring(id.length() - 2))
/* 去重*/
.distinct()
/* 转换成int*/
.map(Integer::new)
/* 对可用的表名求余数,获取到真实的表的后缀*/
.map(idSuffix -> idSuffix % availableTargetNames.size())
/*转换成string*/
.map(String::valueOf)
/* 获取到真实的表*/
.map(tableSuffix -> availableTargetNames.stream().
filter(targetName -> targetName.endsWith(tableSuffix)).findFirst().orElse(null))
.filter(Objects::nonNull)
.collect(Collectors.toList());
}
}
/*处理类似between and 范围查询*/
else if(!complexKeysShardingValue.getColumnNameAndRangeValuesMap().isEmpty()){
log.info("[MyTableComplexKeysShardingAlgorithm] complexKeysShardingValue: [{}]", complexKeysShardingValue);
Set<String> tableNameResultList = new LinkedHashSet<>();
int tableSize = availableTargetNames.size();
/* 提取范围查询的范围*/
Range<String> rangeUserId = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get(COLUMN_ORDER_SHARDING_KEY);
Long lower = Long.valueOf(rangeUserId.lowerEndpoint());
Long upper = Long.valueOf(rangeUserId.lowerEndpoint());
/*根据order_sn选择表*/
for (String tableNameItem : availableTargetNames) {
if (tableNameItem.endsWith(String.valueOf(lower % (tableSize -1 )))
|| tableNameItem.endsWith(String.valueOf(upper % (tableSize -1 )))) {
tableNameResultList.add(tableNameItem);
}
if (tableNameResultList.size() >= tableSize) {
return tableNameResultList;
}
}
return tableNameResultList;
}
log.warn("无法处理分区,将进行全路由!!");
return availableTargetNames;
}
/*转换成String*/
private List<String> ids2String(Collection<?> ids) {
List<String> result = new ArrayList<>(ids.size());
for(Object id : ids){
String strId = Objects.toString(id);
String idFact = strId.length()==1 ? "0"+strId : strId;
result.add(idFact);
}
return result;
}
}
3 读写分离和分库分表实现方式
1)纯手工方式:修改应用程序的 DAO 层代码,定义多个数据源,在代码中
需要访问数据库的每个地方指定每个数据库请求的数据源。
2)组件方式:使用像 Sharding-JDBC 这些组件集成在应用程序内,用于代
理应用程序的所有数据库请求,并把请求自动路由到对应的数据库实例上。
3)代理方式:在应用程序和数据库实例之间部署一组数据库代理实例,比如
Atlas 或 Sharding-Proxy。对于应用程序来说,数据库代理把自己伪装成一个单节点
的 MySQL 实例,应用程序的所有数据库请求都将发送给代理,代理分离请求,然后将分离后的请求转发给对应的数据库实例
推荐使用Sharding-JDBC 组件
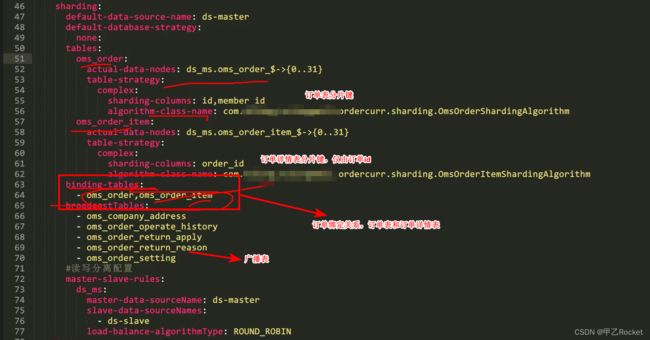
通过配置文件+自定义分片算法的方式,找到对应的物理表来完成分库分表
- 分片主键算法,具体是由上面的实现类来完成

- 总体配置注释
4. 归档历史数据(拆)
像订单数据热尾效应,越远的订单数据我们使用的越少,所以可以进行归档,放到别的里面中,如ES或别的存储系统(所以在上面我们在计算数据量订单和订单详情的时候,按道理订单详情会使用更多的表,但是我们数据库的数据太多会导致数据库越慢,所以可以定时去将历史数据进行归档)
注意点如下
- 一定要先备选
- 由于这里存在大批量的delete和select,所以mysql的IO开销是非常大的(因为这里会有数据库的B+树中,
页的分裂与合并必然的结果)
=》那么针对第二点,我们使用批量多次处理+随机sleep的方式,让数据库的io负载降下来,并且在请求小的时候进行 - 在数据迁移的时候,我们不需要分片,是每个表都要遍历,就是order_table_1,order_table_2…这样依次遍历
/*完成单表从MySQL到MongoDB的一轮(Round)数据迁移,依然需要分次进行,
每次的数据条数由FETCH_RECORD_NUMBERS控制,
该控制阈值可以写入配置中心动态调整,建议不要超过10000*/
@Override
public String migrateSingleTableOrders(int tableNo) {
try {
/*获得3个月前的时间*/
Calendar calendar = Calendar.getInstance();
//calendar.add(Calendar.MONTH, -3);
calendar.add(Calendar.DATE, -1);
Date maxDate = calendar.getTime();
String factTableName = OrderConstant.OMS_ORDER_NAME_PREFIX + tableNo;
/*本轮处理数据的最小ID和最大ID*/
long roundMinOrderId = operateMgDbService.getMaxOrderId(factTableName);
long roundMaxOrderId = roundMinOrderId;
// TODO XUSJ 注意这里删除的时候使用id范围的方式进行删除,保证数据尽可能在数据结构上的一页上,快
log.info("本轮表[{}]数据迁移查询记录起始ID = {}",factTableName,roundMinOrderId);
/*开始迁移*/
while(roundOnOff.get()){
/*获得上次处理的最大OrderId,作为本次迁移的起始ID*/
long currMaxOrderId = operateMgDbService.getMaxOrderId(factTableName);
log.info("本次表[{}]数据迁移查询记录起始ID = {}",factTableName,currMaxOrderId);
List<OmsOrderDetail> fetchRecords = operateDbService.getOrders(currMaxOrderId,
tableNo,maxDate,FETCH_RECORD_NUMBERS);
if(!CollectionUtils.isEmpty(fetchRecords)){
int fetchSize = fetchRecords.size();
/*更新最大OrderId,记录本次迁移的最小ID*/
currMaxOrderId = fetchRecords.get(fetchRecords.size()-1).getId();
long curMinOrderId = fetchRecords.get(0).getId();
log.info("开始进行表[{}]数据迁移,应该迁移记录截止时间={},记录条数={},min={},max={}",
factTableName,maxDate,fetchSize,curMinOrderId,currMaxOrderId);
operateMgDbService.saveToMgDb(fetchRecords,currMaxOrderId,factTableName);
/*更新本轮处理数据的最大ID*/
roundMaxOrderId = currMaxOrderId;
log.info("表[{}]本次数据迁移已完成,准备删除记录",factTableName);
operateDbService.deleteOrders(tableNo,curMinOrderId,currMaxOrderId);
/*TODO XUSJ 考虑到数据库的负载,每次迁移后休眠随机数时间*/
int rnd = ThreadLocalRandom.current().nextInt(DB_SLEEP_RND);
log.info("表[{}]本次数据删除已完成,休眠[{}]S",factTableName,rnd);
TimeUnit.SECONDS.sleep(rnd);
}else{
log.info("表[{}]本轮数据迁移已完成,数据截止时间={},min={},max={}",
factTableName,maxDate,roundMinOrderId,roundMaxOrderId);
break;
}
}
return OrderConstant.MIGRATE_SUCCESS;
} catch (Exception e) {
log.error("表[{}]本次数据迁移异常,已终止,请检查并手工修复:",
OrderConstant.OMS_ORDER_NAME_PREFIX + tableNo,e);
return OrderConstant.MIGRATE_FAILURE;
}
}
// 删除保证在一页的方式
<delete id="deleteMigrateOrdersItems">
delete from ${orderItemTableName} ot
WHERE ot.order_id >= #{minOrderId} and ot.order_id <= #{maxOrderId}
</delete>
总结
-
- 服务幂等性考虑
- 网络或者服务器的问题必然会产生重试的机制,那我们必须对重要的业务考虑幂等性
- 方案一:存储设备一致性的来解决
- 方案二:代码设计(局限性大)
-
- 海量数据的存储
- 高并发,分库
- 大数据分表
- 使用 Sharding-JDBC 这些组件定义分片算法/定义配置文件来解决
- 考虑大数据量操作对数据库带来的损耗。1:数据越多越慢;2:大数据del数据库分裂合并io损耗高,可以批量多次解决,可以随机sleep