Java修仙传之神奇的ES(基础使用)
前言
ES是什么:一款强大的搜索引擎
ES拓展:elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)
kibana:可视化
ES:搜索引起
Logstash:数据抓取,数据同步
ES为什么搜索快:核心:倒排索引
ES的底层:Java语言的搜索引擎类库Lucene
ES的竞品:solr,splunk等
什么是elasticsearch?
一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析、系统监控等功能
什么是elastic stack(ELK)?
是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch
什么是Lucene?
是Apache的开源搜索引擎类库,提供了搜索引擎的核心API
倒排索引
正向索引
有没有正向索引呢?
有。mysql id查询,全表扫描,模糊搜索等。
特征:逐条搜索,依次递进举例:模糊搜索x表中,携带手机的数据
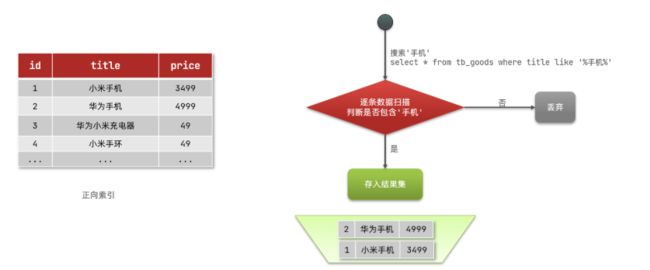
流程概述:逐条搜索,逐条比对
1)用户搜索数据,条件是title符合"%手机%"
2)逐行获取数据,比如id为1的数据
3)判断数据中的title是否符合用户搜索条件
4)如果符合则放入结果集,不符合则丢弃。回到步骤1
如果添加一个条件 id = x
1:id查询
2:拿到数据比对
3:符合返回,不符合为空
备注:随着数量增加,即使增加了索引,速度也会逐渐变慢倒排索引(根据词条查询,发挥最大效果)
备注:根据关键字查询时,发挥最大效果
本质:就是一个词条库,一词条对应N个ID。变相的id查询。
关键字输入->分词->获取文档id->根据文档id查询
概念了解:
一个es,有多个索引库
一个索引库下,有N条数据(每条数据叫一个文档)
一条文档,可以被分为N个词条倒排索引,正是基于词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
- 将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引
倒排索引流程
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。

总结
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
ES的一些概念
索引库(=MYSQL的库)
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

举例:
MYSQL用户表 = ES用户索引库
MYSQL订单表 = ES订单索引库

字段(=MYSQL列名)

文档(=MYSQL一条数据)
一个文档=MYSQL一条数据

映射(=MYSQL约束(唯一非空等))
DSL语句(=SQL语句)
大白话:ES的操作语句
概念总结
| MySQL |
Elasticsearch |
说明 |
| Table |
Index |
索引(index),就是文档的集合,类似数据库的表(table) |
| Row |
Document |
文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column |
Field |
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema |
Mapping |
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL |
DSL |
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
ES跟MYSQL区别
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算使用场景
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性

备注:这里数据同步用的就是Logstash
IK分词器
:w - 保存文件,不退出 vim
:w file -将修改另外保存到 file 中,不退出 vim
:w! -强制保存,不退出 vim
:wq -保存文件,退出 vim
:wq! -强制保存文件,退出 vim
:q -不保存文件,退出 vim
:q! -不保存文件,强制退出 vim
:e! -放弃所有修改,从上次保存文件开始再编辑1:添加配置
2:定义文件,添加词语(要分为一组的)
备注:就是写个文件,直接把词加进去。文件名=上面配置的
3:重启es,kibana,测试即可
SDL语句
索引库操作
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}GET /索引库名PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
删除索引库:DELETE /索引库名- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 添加字段:PUT /索引库名/_mapping文档操作
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}GET /{索引库名称}/_doc/{文档id}DELETE /{索引库名}/_doc/id值// 备注:这种方式相当于覆盖了原文档(全量修改)
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}
// 备注:这种方式修改了指定id匹配的文档中的部分字段
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}# 查询全部文档
GET 索引库名/_search
- 创建文档:POST /{索引库名}/_doc/文档id { json文档 }
- 查询文档:GET /{索引库名}/_doc/文档id
- 删除文档:DELETE /{索引库名}/_doc/文档id
- 修改文档:
- 全量修改:PUT /{索引库名}/_doc/文档id { json文档 }
- 增量修改:POST /{索引库名}/_update/文档id { "doc": {"字段名":"新值"}}


RestHighLevelClient
依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
1.8
7.12.1
索引库:创建,删除,判断是否存在
private RestHighLevelClient client;
//总结下流程:
//1:基于配置文件或者代码连接到ES集群
//2:初始化RestHighLevelClient
//3:使用RestHighLevelClient来操作索引库(记得关闭连接)
//3.1:不同的需求,写不同的api
//3.2:发送给ES集群的请求,都是Request对象
//判断索引库是否存在
@Test
void testExistsHotelIndex() throws IOException {
boolean exists = client.indices().exists(new org.elasticsearch.client.indices.GetIndexRequest("hotel"), RequestOptions.DEFAULT);
System.out.println("索引库是否存在:" + exists);
}
//删除索引库
@Test
void testDeleteHotelIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
//创建索引库
@Test
void createHotelIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2.准备请求的参数:DSL语句
request.source(HotelConstants.MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
//如果提示过时, CreateIndexRequest导包需要导入短的那个,长的那个过时了
CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println("索引库创建结果是:" + response.isAcknowledged());
}
//在每一个测试方法(@Test)之前都会运行
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
//ip因人而异
HttpHost.create("http://192.168.200.130:9200")
));
}
//在每一个测试方法(@Test)之后都会运行
@AfterEach
void tearDown() throws IOException {
this.client.close();
}文档:新增,删除,查询,修改,批量操作
@Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
//批量新增(BulkRequest增删改都是用)
@Test
void testBulkRequest() throws IOException {
// 批量查询酒店数据
List hotels = hotelService.list();
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备参数,添加多个新增的Request
for (Hotel hotel : hotels) {
// 2.1.转换为文档类型HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
// 2.2.创建新增文档的Request对象
IndexRequest hotel1 = new IndexRequest("hotel").id(hotelDoc.getId().toString());
hotel1.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
request.add(hotel1);
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}
//修改文档
// POST /索引库名/_update/文档id
// {
// "doc"{
// "name": "四钻",
// "price": "952"
// }
// }
// }
//全量修改:根据id覆盖
//增量修改:根据id修改对应数据
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("hotel", "61083");
//准备请求参数
request.doc(
"price", "952",
"startName", "四钻"
);
//发送请求
client.update(request, RequestOptions.DEFAULT);
}
//删除文档 DELETE /hotel/_doc/{id}
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request
DeleteRequest request = new DeleteRequest("hotel", "61083");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}
//查询文档 GET /hotel/_doc/{id}
@Test
void testQueryDocument() throws IOException {
//准备req对象
GetRequest request = new GetRequest("hotel").id("61083");
//发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//解析响应结果
if (response.isExists()) {
String sourceAsString = response.getSourceAsString();
HotelDoc hotelDoc = JSON.parseObject(sourceAsString, HotelDoc.class);
System.out.println(hotelDoc);
}
}
//新增文档
// POST /{索引库名}/_doc/1
// {
// "name": "Jack",
// "age": 21
// }
//数据库数据导入es
@Test
void testAddDocument() throws IOException {
// 1.根据id查询酒店数据(从mysql中获取一条记录)
Hotel hotel = hotelService.getById(61083L);
// 2.转换为文档类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3.将HotelDoc转json
String json = JSON.toJSONString(hotelDoc);
//准备req对象
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2.准备Json文档
request.source(json, XContentType.JSON);
//发送请求
client.index(request, RequestOptions.DEFAULT);
//简化版
// client.index(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(json, XContentType.JSON), RequestOptions.DEFAULT);
}
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.200.130:9200")
));
}
@AfterEach
void tearDown() throws IOException {
this.client.close();
} // 创建一个BulkRequest对象
BulkRequest request = new BulkRequest();
// 添加索引操作
IndexRequest indexRequest1 = new IndexRequest("索引库名").id("文档id").source("field1", "value1");
request.add(indexRequest1);
// 添加更新操作
UpdateRequest updateRequest1 = new UpdateRequest("my_index", "2").doc("field2", "value2");
request.add(updateRequest1);
// 添加删除操作
DeleteRequest deleteRequest1 = new DeleteRequest("my_index", "3");
request.add(deleteRequest1);
// 执行批量操作
BulkResponse response = client.bulk(request, RequestOptions.DEFAULT);