Oracle——基础知识汇总
注意:在Oracle数据库的SQL命令中,关键字、表名和字段名都不区分大小写,语法是标准的 sql写法
参考链接
一、字符串类型
char:固定长度字符串,会用空格填充来达到最大长度。
varchar2:变长度字符串,不补充空格,可以存储32767字节的内容。
二、汉字的存储
每个汉字占多少字节要看具体的编码方式,如UTF-8(1-3字节)、GB2312(2字节)、GBK(2字节)、GB18030(1、2、4字节)。
三、数字类型
Oracle用number类型来存放数字,存储精度最多达38位。
number( m,n ),m表示总长度,n表示小数位的精度,如果存入的数据的小数位的精度超过了n,则取四舍五入后的值。
例如:number(10,3),10是总长度,3是小数后的位数,如123.456。
如果存入123.4567,实际际将是123.457。
如果存入12345679.899,总长度超出了10,Oracle将提示错误。
如果打算存入整数,用number(m)就可以了,m表示可以存入数据的最大位数。
四、日期类型
Oracle采用date类型表示日期和时间,这是一个7字节的固定宽度的数据类型,有7个属性,包括:世纪、世纪中哪一年、月份、月中的哪一天、小时、分钟和秒。
对编程语言来说,日期和时间是用字符串来显示和书写的,Oracle提供了to_date和to_char两个函数在date类型和字符串类型之间转换。
例如:
insert into T_GIRL(name,birthday) values('西施',to_date('2000-01-01 01:12:35','yyyy-mm-dd hh24:mi:ss'));
select name,to_char(birthday,'yyyy-mm-dd hh24:mi:ss') from T_GIRL where name='西施';
五、clob和blob类型
clob类型:
存放单字节字符串或多字节字符串数据,如文本文件、xml文件。
变长的字符串大对象,最长可达4GB;
clob可以存储单字节字符串或多字节字符串数据;
clob被认为是一个更大的字符串。当数据库的字符集发生转换时,clob类型会受到影响。
blob类型:
存放非结构化的二进制数据,如图片、音频、视频、office文档等。
变长的二进制大对象,最长可达4GB;
blob主要用于保存带格式的非结构化数据,如图片、音频、视频、Office文档等;
当数据库的字符集发生转换时,blob类型不会受到影响,Oracle数据库不关心存放的是什么内容。
六、rowid类型
rowid是Oracle数据库专有的数据类型,与其它的数据库不兼容。
Oracle数据库中每个表的每行记录都有一个存储的物理位置,即表的rowid伪列,
采用rowid作为where条件的访问效率最高。
rowid的访问效率虽然是最高的,但是,在实际应用中要谨慎,
需要注意两个问题:
1)rowid存放的是表记录的物理位置,在数据整理、数据备份和迁移的时候,
记录的物理位置会发生改变;
2)rowid是Oracle数据库专有的数据类型,与其它的数据库不兼容。
七、Oracle提供了22中不同的SQL数据类型
char:定长字符串,会用空格填充来达到最大长度。非null的char(10)包含10个字节信息。char字段最多可以存储2000个字节信息。
nchar:包含unicode格式数据的定长字符串。nchar字段最多可存储2000字节的信息。
varchar2:是varchar的同义词。这是一个变长字符串,与char类型不同,它不会用空格将字段或变量填充至最大长度。varchar(10)可能包含0~10字节的信息,最多可存储4000字节信息。从12c起,可以存储32767字节信息。
nvarchar2:包含unicode格式数据的变长字符串。最多可存储4000字节信息。从12c起,可以存储32767字节信息。
raw:一种变长二进制数据类型,采用这种数据类型存储的数据不会发生字符集转换。
number:能存储精度最多高达38位的数字。这种类型的数据会以变长方式来存储,长度在0~22字节。
binary_float:32位单精度浮点数,可以支持至少6位精度,占用磁盘上5个字节的存储空间。
binary_double:64位双精度浮点数,可以支持至少15位精度,占用磁盘上9个字节的存储空间。
long:这种类型能存储最多2GB的字符数据
long raw:long raw类型能存储多达2GB的二进制信息
date:这是一个7字节的定宽日期/时间数据类型,其中包含7个属性:世纪、世纪中的哪一年、月份、月中的哪一天、小时、分钟、秒。
timestamp:这是一个7字节或11字节的定宽日期/时间数据类型,它包含小数秒。
timestamp with time zone:这是一个13字节的timestamp,提供了时区支持。
timestamp with local time zone:这是一个7字节或11字节的定宽日期/时间数据类型,在数据的插入和读取时会发生时区转换。
interval year to month:这是一个5字节的定宽数据类型,用于存储一个时段。
interval day to second:这是一个11字节的定宽数据类型,用于存储一个时段。将时段存储为天/小时/分钟/秒数,还可以有9位小数秒。
blob:这种类型能够存储最多4GB的数据。
clob:这种类型能够存储最多4GB的数据。当字符集发生转换时,这种类型会受到影响。
nclob:这种类型能够存储最多4GB的数据。当字符集发生转换时,这种类型会受到影响。
bfile:这种数据类型可以在数据库列中存储一个oracle目录对象和一个文件名,我们可以通过它来读取这个文件。
rowid:实际上是数据库表中行的地址,它有10字节长。
urowid:是一个通用的rowid,没有固定的rowid的表。
八、表相关
- 建表
标准的 sql写法
1)在create table时指定。
create table T_GIRL
(
id char(4) not null, -- 编号
name varchar2(30) not null, -- 姓名
yz varchar2(20) null, -- 颜值
sc varchar2(20) null, -- 身材
weight number(4,1) not null, -- 体重
height number(3) not null, -- 身高
birthday date not null, -- 出生时间
memo varchar2(1000) null, -- 备注
primary key(id) -- 指定id为表的主键
);
2)修改已经建好的表,增加主键约束。
alter table 表名 add constraint 主键名 primary key(字段名1,字段名2,......字段名n);
例如:
alter table T_GIRL add constraint PK_GIRL primary key(id);
-------------------------相关约束知识:----------------------------
1.非空约束
not null
2.唯一性约束
主键
3.检查约束
检查约束是指检查字段的值是否合法。
示例:
create table TT
(
c1 number(6) constraint CKC_C1_TT check (c1 >= 10),
c2 number(6) constraint CKC_C2_TT check (c2 <= 20),
c3 number(6) constraint CKC_C3_TT check (c3 in (1,2,3))
);
创建表TT,c1字段的最小值是10,c2字段的最大值是20,C3字段的取值必须在(1,2,3)中取其一。
插入时如果值不符合约束要求就会报错。
-------------------------字段的缺省值----------------------------
在创建表的时候,可以为字段指定缺省值。
create table TT
(
name varchar2(10) not null,
crttime date default sysdate not null,
rsts number(1) default 1 not null constraint CKC_RSTS_TT check (rsts in (1,2))
);
创建表,字段crttime的缺省值是sysdate(当前时间),rsts的缺省值是1。
-------------------------表的存储空间----------------------------
1、查看当前用户的缺省表空间
2、指定表的表空间
语法如下:
create table 表名
(
...... -- 字段列表
) tablespace 表空间名;
例如创建T_GIRL表,指定使用USERS表空间。
create table T_GIRL
(
id char(4) not null, -- 编号
memo varchar2(1000) null -- 备注
) tablespace USERS;
-------------------------修改表结构----------------------------
1、增加字段
语法:
alter table 表名 add 字段名 数据类型 其它选项;
例如:
alter table T_GIRL add rsts number(1) constraint CKC_RSTS_GIRL check (rsts in (1,2));
2、修改字段的属性
语法:
alter table 表名 modify 字段名 数据类型 其它选项;
例如:
alter table T_GIRL modify address varchar2(100);
3、修改字段名
语法:
alter table 表名 rename column 列名 to 新列名;
例如:
alter table T_GIRL rename column memo to remark;
4、删除字段
语法:
alter table 表名 dorp column 字段名;
例如:
alter table T_GIRL drop column rsts;
5、修改表名
语法:
alter table 表名 rename to 新表名;
例如:
alter table T_GIRL rename to T_BEAUTY;
6、删除表
语法:
drop table 表名;
示例:
drop table T_GIRL;
- 插入
标准的 sql写法
①insert into命令用于向表中插入记录,语法如下:
insert into 表名 (字段名1, 字段名2,...... 字段名n) values (字段1的值, 字段2的值,..... 字段n的值);
注意,表名后的字段名列表与values后面字段值列表必须一一对应。
②插入数据的SQL语句还有一种写法,如下:
insert into 表名 values (字段1的值, 字段2的值,..... 字段n的值);
这种写法省略了字段名列表,但是,这种写法一定不能出现在程序中,
因为只要表结构发生改变,或字段的位置改变,SQL语句就会出错。
在上面的insert语句中,字段的值如果是字符串,要用单引号包含起来,日期字段要用to_date函数转换,数字直接书写。
- 修改
标准的 sql写法
update命令用于修改表中的记录,语法如下:
update 表名 set 字段名1=值1,字段名2=值2,......字段名n=值n where 条件1 and 条件2 ...... 条件n;
where关键字后面是条件表达式,如果没有条件表达式,就会更新表中全部的记录。
- 删除
标准的 sql写法
delete命令用于删除表中的记录,语法如下:
delete from 表名 where 条件1 and 条件2 ...... 条件n;
where关键字后面是条件表达式,如果没有条件表达式,就删除表中全部的记录。
- 查询
标准的sql写法
select命令用于从表中查询记录,语法如下:
select 字段名1,字段名2,......字段名n from 表名 where 条件1 and 条件2 ...... 条件n;
select * from 表名 where 条件1 and 条件2 ...... 条件n;
九、oracle的序列生成器
设计数据表的时候会把某些字段定义成一个自动增长的、唯一的流水号,例如记录编号、日志编号等,MySQL和SQL Server采用的是自增字段,Oracle和PostgreSQL采用了更灵活的序列生成器。
1.创建序列
语法如下:
create sequence 序列名
[minvalue n]
[maxvalue n]
[increment by n]
[start with n]
[cache n|nocache]
[order|noorder]
[cycle|nocycle];
参数说明:
Oracle的序列分为递增序列和递减序列,本文假设序列是递增序列。
序列名:序列名是标志符,建议以SEQ_打头,例如为T_OPERLOG表的logid字段创建一个序列,可以把它命名为SEQ_OPERLOG(或SEQ_OPERLOG_LOGID),增加数据结构的可读性,这是我的个人经验,并不是Oracle数据库的要求。
[minvalue n]:序列的最小值,缺省值是1。
[maxvalue n]:序列的最大值,缺省值是9999999999999999999999999999。
[increment by n]:序列递增的步长,缺省值是1。
[start with n]:序列的起始值,缺省值是minvalue,如果n小于minvalue,创建序列会报语法错误。
[cache n|nocache]:是否采用缓存机制,nocache不采用缓存,缺省cache 20,数据库每次会生成20个值放在缓存中,如果缓存中有数据,就不需要再查数据库了,采用缓存机制可以提升效率。
[order|noorder]:获取序列的时候是否按顺序给值,如果多用户一起获取序列的值,使用order可以保证序列值的顺序按访问序列的事件排序,缺省是noorder。
[cycle|nocycle]:是否循环,缺省不循环,如果不循环,序列值到了maxvalue后将不可用。
2.在SQL语句中使用序列
create table T_GIRL
(
name varchar2(10), -- 姓名
keyid number(10) -- 记录编号
);
1)在insert语句中使用序列。
insert into T_GIRL(name,keyid) values('西施' ,SEQ_GIRL.nextval);
insert into T_GIRL(name,keyid) values('妲已' ,SEQ_GIRL.nextval);
2)在update语句中使用序列。
update T_GIRL set keyid=SEQ_GIRL.nextval+100;
序列不产生事务,序列可能产生裂缝。
3.修改序列的语法如下:
alter sequence 序列名
[minvalue n]
[maxvalue n]
[increment by n]
[start with n]
[cache n|nocache]
[order|noorder]
[cycle|nocycle];
修改序列的参数与创建序列的参数相同,不同的是,修改序列时没有缺省值。
alter sequence SEQ_GIRL increment by 10 cycle;
4.删除序列
语法如下:
drop sequence 序列名;
5.利用dual虚表使用序列
select SEQ_GIRL.nextval from dual; -- 获取序列SEQ_GIRL的下一个值。
select SEQ_GIRL.currval from dual; -- 获取序列SEQ_GIRL的当前值。
十、函数
-
常用系统函数
参考链接 -
自定义函数
1、创建函数
create or replace function 函数名(参数1 模式 数据类型,......) return 数据类型
as
-- 定义局部变量。
变量1 数据类型;
......
begin
-- 实现函数功能的PL/SQL代码。
......
exception
-- 异常处理的PL/SQL代码。
......
end;
/
1)参数的模式有三种:
in:只读模式,在函数中,参数只能被引用/读取,不能改变它的值。
out:只写模式,参数只能被赋值,不能被引用/读取。
in out:可读可写。
参数的模式可以不写,缺省为in,out和in out两种模式极少使用。
2)as/is二选一,在这里没有区别。
3)可以不定义局部变量。
4)可以没有异常(exception)处理代码段。
示例,创建自定义函数maxvalue,用于比较两个数字的大小,返回较大值:
create or replace function maxvalue(val1 number,val2 number) return number
as
val number; -- 定义局部变量,存放返回值。
begin
if (val1>val2) then -- 判断传入参数的大小。
val:=val1; -- 赋值是":=",不是"="。
else
val:=val2;
end if;
return val; -- 返回
end;
/
删除自定义函数:
drop function 函数名;
十一、存储过程
1.创建存储过程
create or replace procedure 存储过程名(参数1 模式 数据类型,......)
as/is
-- 定义局部变量
变量1 数据类型;
......
begin
-- 实现存储过程功能的PL/SQL代码。
......
exception
-- 异常处理的PL/SQL代码。
......
end;
/
1)参数的模式有三种:
in:只读模式,在函数中,参数只能被引用/读取,不能改变它的值。
out:只写模式,参数只能被赋值,不能被引用/读取。
in out:可读可写。
参数的模式可以不写,缺省为in,out和in out两种模式极少使用。
2)as/is二选一,在这里没有区别。
3)可以不定义局部变量。
4)可以没有异常(exception)处理代码段。
示例:
create or replace procedure girlinfo(in_id varchar2)
is
s_name varchar2(30); -- 姓名
s_yz varchar2(20); -- 颜值
s_height number(3); -- 身高
begin
select name,yz,height into s_name,s_yz,s_height from T_GIRL where id=in_id;
dbms_output.put_line('姓名:'||s_name||'颜值:'||s_yz||'身高:'||s_height);
exception
when others then
dbms_output.put_line('输入的id('||in_id||')不正确,查询无结果。');
end;
/
在上面创建的存储过程中用到了 dbms_output ,在sqlplus中要先执行 set serveroutput on; 才能输出内容。
2.存储过程的调用
exec 存储过程名(参数,……);
execute 存储过程名(参数,……);
3.删除存储过程
drop procedure 存储过程名;
4.存储过程的权限
储过程是数据库对象,Oracle对它权限管理方式与其它数据库对象相同。
如果getinfo函数是用scott用户创建的,其它用户调用时需要加scott用户名前缀,并且具备相应的权限,否则会出现“PLS-00201: 必须声明标识符 'GIRLINFO'”的错误。
十二、触发器
参考链接
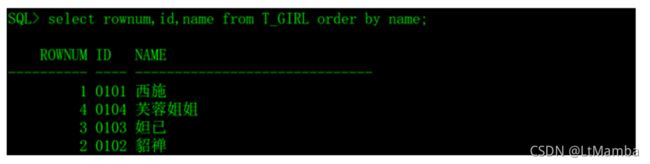
十三、伪列rownum
参考链接
因为rownum的是在从数据库中取数据的时候产生的序号,order by时会出现如下效果:
十四、索引
参考链接
十五、外键
创建外键的语法:
alter table 从表名
add constraint 外键名 foreign key (从表字段列表)
references 主表名 (主表字段列表)
[on delete cascade|set null];
十六、用户和权限管理
参考资料
- 用户管理
1. **创建用户**
--创建用户的命令是create user,它的选项非常多,在这里我介绍一些常用的选项。
--语法:
create user 用户名 identified by 密码
[default tablespace 表空间名]
[temporary tablespace 表空间名]
[quota 大小 on 表空间名]
[profile 用户配置文件];
--参数说明:
create user 用户名 identified by 密码:指定登录数据库的用户名和密码。
[default tablespace 表空间名]:指定用户的永久表空间,该用户全部的数据库对象(表、索引)将存放在该表空间中。
[temporary tablespace 表空间名]:指定用户的临时表空间,临时表空间主要用于排序、运算、管理索引、存放临时数据等,当任务完成之后系统会自动清理。
[quota 大小 on 表空间名]:表空间配额,用户使用表空间的大小,单位有[K|M|G|T|P|E],缺省是unlimited,无限制。
[profile 用户配置文件]:用户的配置文件,它是密码限制,资源限制的命名集合,利用profile 可以对数据库用户进行基本的资源管理,密码管理,缺省是default profile,无限制。
--注意,创建用户时,如果不指定default tablespace/ temporary tablespace选项,则使用系统缺省的永久/临时表空间,
--用以下SQL可以查看系统缺省的永久/临时表空间。
select property_value from DATABASE_PROPERTIES where
property_name in ('DEFAULT_PERMANENT_TABLESPACE','DEFAULT_TEMP_TABLESPACE');
2. **修改用户的密码**
alter user 用户名 identified by 新密码;
--普通用户只能修改自已的密码,DBA可以修改其它用户的密码。
3. **锁定/解锁用户**
alter user 用户名 account lock;
alter user 用户名 account unlock;
--锁定/解锁用户需要DBA权限。
4. **修改用户表空间配额**
alter user 用户名 quota 大小 on 表空间;
修改用户表空间配额需要DBA权限。
5. **删除用户**
drop user 用户名 [cascade];
--drop user 只有在用户下没有任何数据库对象的时候才能删除用户,否则会提示错误。
--采用cascade选项删除用户以及用户下全部的数据库对象,包括表、视图、函数、同义词、过程等。
- 权限管理
权限是指用户执行特定命令或操作数据库对象的权利。Oracle的用户权限分系统权限和对象权限。
1.**系统权限**
Oracle有两百多种系统权限,通过下面语句可查:
select * from SYSTEM_PRIVILEGE_MAP;
2.**对象权限(九种)**
select、insert、update、delete、alter、execute、index、reference、all;
index权限:允许在表上创建索引。
reference权限:允许在表上创建完整性约束,如外键。
all:对象的全部权限(上面列出的全部权限)。
3.**角色(三种)**
1)connect角色: 只可以登录Oracle(仅具有创建SESSION的权限),不可以创建实体,不可以创建数据库结构。
2)resource角色: 可以创建数据库对象,和对本用户的数据库对象拥有全部的操作权限。
3)DBA角色: 拥有全部特权,是系统最高权限。
4.**授于/收回权限**
①对象权限授予/收回
grant 对象权限列表 on 对象名 to { public | 角色名 | 用户名 },……;
revoke 对象权限列表 on 对象名 from { public | 角色名 | 用户名 },……;
例:
grant select,insert on scott.T_GIRL to girl,scott;--将scott.T_GIRL表的select和insert权限授于girl和scott用户。
revoke select,insert on scott.T_GIRL from girl,scott;--将scott.T_GIRL表的select和insert权限收回girl和scott用户。
grant all on scott.T_GIRL to resource;--将scott.T_GIRL表的全部权限授于resource角色。
②系统权限和角色权限授于/收回用户
grant { 系统权限 | 角色 }, …… to { public | 角色名 | 用户名 },……;
revoke { 系统权限 | 角色 }, …… from { public | 角色名 | 用户名 },……;
示例:
grant connect,resource to 用户名;--新建数据库用户后,都会习惯性的给用户授权connect角色和resource角色
grant select any table to public;--将select any table权限授于全部用户。
revoke select any table from public;--将select any table权限收回全部用户。
grant select any table to connect;--将select any table权限(就是select权限)授于connect角色。
5.**查询权限**
从数据字典中可以查询当前用户拥有的权限和角色。
1)查询当前用户拥有的角色:
select * from USER_ROLE_PRIVS;
2)查询当前用户拥有的系统权限:
select * from USER_SYS_PRIVS;
3)查询当前用户拥有的对象权限:
select * from USER_TAB_PRIVS;
十七、数据库的启动和关闭
参考链接
Oracle数据库实例的启动要经历三个阶段:
1.startup nomount; --启动实例(Start an instance)
2.alter database mount; --装载数据库(Mount the database)
3.alter database open; --打开数据库(Open the database)
--直接启动数据库,相当于以上三个步骤,open可以省略不写
startup open;
Oracle的关闭也要经历三个阶段:关闭数据库、卸载数据库和关闭实例
1.shutdown immediate --推荐使用immediate方式关闭数据库。
使用immediate方式关闭数据库时:
1)新的用户不能登录数据库;
2)未提交的事务将会被回滚;
3)Oracle不会等待所有的用户(连接)退出数据库。
特点:
1)这种关闭方式可能会造成数据丢失;
2)数据库重启时不需要实例恢复。
2.shutdown transactional
以transactional方式关闭数据库时:
1)不允许新的用户登录数据库;
2)不允许建立新的事务
3)所有的事务完成以后才关闭数据库;
4)一个用户(会话)执行完当前的事务后将被强行断开与数据库的连接。
特点:
1)这种关闭方式不会造成数据丢失;
2)数据库重启时不需要实例恢复;
3)这是最安全的关闭方式。
3.shutdown abort
以abort方式关闭数据库时:
1)不允许建立新的连接和新的事务;
2)客户端的SQL语句立刻终止;
3)未提交的事务不被回滚;
4)Oracle立刻终止所有连接(会话)。
特点:
1)只有数据库出现问题时候,才使用这种方式关闭数据库;
2)这是一种最不安全的关闭方式,数据库重启时需要实例恢复。
4.shutdown normal
使用normal方式关闭数据库时:
(1)允许新的用户注登录数据库;
(2)要等所有的用户自动退出Oracle以后,Oracle才关闭数据库。如果有未退出的用户,那么Oracle就一直等待,直到这个用户退出才关闭数据库。
normal是最慢的数据库关闭方式,不推荐。
5.startup force
重启数据库(Reset)。相当于shutdown abort和startup。