Swin Transformer升级版来了,30亿参数,刷榜多项视觉任务,微软亚研原班人马打造
微软亚洲研究院升级了 Swin Transformer,新版本具有 30 亿个参数,可以训练分辨率高达 1,536×1,536 的图像,并在四个具有代表性的基准上刷新纪录。欢迎收藏学习,喜欢点赞支持。
在不久之前公布的 ICCV 2021 论文奖项中,来自微软亚洲研究院的研究者凭借论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》斩获 ICCV 2021 马尔奖(最佳论文)。这篇论文的作者主要包括中国科学技术大学的刘泽、西安交通大学的林宇桐、微软的曹越和胡瀚等人。该研究提出了一种新的 vision Transformer,即 Swin Transformer,它可以作为计算机视觉的通用骨干。
相比之前的 ViT 模型,Swin Transformer 做出了以下两点改进:其一,引入 CNN 中常用的层次化构建方式构建分层 Transformer;其二,引入局部性(locality)思想,对无重合的窗口区域内进行自注意力计算。在 Swin Transformer 论文公开没多久之后,微软官方也在 GitHub 上开源了代码和预训练模型,涵盖图像分类、目标检测以及语义分割任务。
近日,该团队又提出一种升级版 SwinTransformer V2。

论文地址:https://arxiv.org/pdf/2111.09883.pdf
通常来讲,Transformer 适用于扩展视觉模型,但它还没有像 NLP 语言模型那样得到广泛的探索,部分原因是因为在训练和应用方面存在以下困难:
-
视觉模型经常面临扩展不稳定问题;
-
许多下游视觉任务需要高分辨率的图像或窗口,目前尚不清楚如何有效地将在低分辨率下预训练的模型转换为更高分辨率的模型;
-
当图像分辨率较高时,GPU 内存消耗也是一个问题。
为了解决上述问题,该团队将 SwinTransformer 作为基线提出了几种改进技术,具体表现在:
-
提出后归一化(post normalization)技术和缩放余弦注意力(scaled cosine attention)方法,来提高大型视觉模型的稳定性;
-
提出 log-spaced 连续位置偏差技术,可有效地将在低分辨率图像和窗口中预训练的模型迁移到更高分辨率对应模型。
此外,该研究还介绍了关键实现细节,这些细节可显着节省 GPU 内存消耗,使得常规 GPU 训练大型视觉模型成为可能。使用这些技术和自监督预训练,该团队训练了一个具有 30 亿参数的 Swin Transformer 模型,并将其有效地迁移到高分辨率图像或窗口的各种视觉任务中,在各种基准上实现了 SOTA 性能。
通过扩展容量和分辨率,Swin Transformer V2 在四个具有代表性的基准上刷新纪录:在 ImageNet-V2 图像分类任务上 top-1 准确率为 84.0%,COCO 目标检测任务为 63.1 / 54.4 box / mask mAP,ADE20K 语义分割为 59.9 mIoU,Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。

部分刷榜截图。图源:https://paperswithcode.com/sota
Swin Transformer V2
研究者观察到 Swin Transformer 在扩展模型容量和窗口分辨率时存在以下两个问题。
其一,扩展模型容量的不稳定问题。如下图 2 所示,当我们将原始 Swin Transformer 模型从小到大扩展时,更深层的激活值急剧增加。具有最高和最低振幅的层之间的偏差达到了 10^4 的极值。

当我们进一步将其扩展到一个巨大的规模(6.58 亿参数)时,Swin Transformer 无法完成训练,如下图 3 所示。

其二,跨窗口分辨率迁移模型时性能下降。如下表 1 第一行所示,当我们通过双三次插值方法,在更大的图像分辨率和窗口大小直接测试预训练 ImageNet-1K 模型(分辨率 256 × 256,窗口大小 8 × 8)的准确率时,发现准确率显著下降。这可能值得去重新检查原始 Swin Transformer 中的相对位置偏差方法。

扩展模型容量
在本节内容中,研究者介绍了上述两个问题的解决方法,包括如下:
-
使用后归一化和缩放余弦注意力解决不稳定性问题;
-
使用 log-spaced 连续位置偏差方法解决跨窗口分辨率迁移问题。
一方面,为了缓解扩展模型容量时的不稳定问题,研究者使用了后归一化方法,如下图 1 所示。在这种方法中,每个残差块的输出在合并回主分支之前被归一化,并且当层数越深时,主分支的振幅不会积聚。

又如上图 2 所示,这种方法的激活幅度变得比原始预归一化配置温和得多。在研究者最大的模型训练中,他们每 6 个 Transformer 块都会在主分支上额外引入一个层归一化单元,以进一步稳定训练和振幅。
另一方面,在原始的自注意力计算中,像素对的相似项被计算为查询向量和关键向量的点积。研究者发现将这种方法用于大型视觉模型时,特别是在 post-norm 配置中,一些块和头部学得的注意力图经常由几个像素对主导。为了缓解这个问题,他们提出了一种缩放余弦注意力方法,它通过缩放余弦函数计算像素对 i 和 j 的注意力对数:

扩展窗口分辨率
在本节中,研究者介绍了一种 log-spaced 连续位置偏差方法,以使得相对位置偏差可以在窗口分辨率之间平滑地迁移。连续位置偏差方法不是直接优化参数化偏差,而是在相对坐标上引入一个小的元(meta)网络:

元网络![]() 为任意相对坐标生成偏差值,因此可以自然地迁移到具有任意变化窗口大小的微调任务。对于推理任务,每个相对位置的偏差值可以预先计算并存储为模型参数,这样在推理时与原始参数化偏差方法一样方便。
为任意相对坐标生成偏差值,因此可以自然地迁移到具有任意变化窗口大小的微调任务。对于推理任务,每个相对位置的偏差值可以预先计算并存储为模型参数,这样在推理时与原始参数化偏差方法一样方便。
当在变化很大的窗口大小之间迁移时,将有很大一部分相对坐标范围需要外推。为了缓解这个问题,研究者提出使用 log-spaced 坐标替代原始 linear-spaced 坐标:

节省 GPU 内存的实现
另一个问题在于当容量和分辨率都很大时,常规实现的 GPU 内存消耗难以承受。为了解决内存问题,研究者采用以下几种实现方法:
-
零冗余优化器(Zero-Redundancy Optimizer, ZeRO)
-
激活检查点(Activation check-pointing)
-
顺序自注意力计算(Sequential self-attention computation)
通过这些实现,研究者成功地使用 Nvidia A100-40G GPU 训练了一个 3B(30 亿参数) 模型,既可以用于输入图像分辨率为 1,536×1,536 的 COCO 目标检测,也可用于输入分辨率为 320 × 320 × 8 的 Kinetics-400 动作分类。
实验结果
该团队在 ImageNet-1K 图像分类(V1 和 V2)、COCO 目标检测和 ADE20K 语义分割进行了实验。此外,对于 30 亿参数模型实验,该研究还报告了 Swin Transformer V2 在 Kinetics400 视频动作识别上的准确率 。
SwinV2-G 实验设置:预训练采用 192×192 图像分辨率,以节省训练成本,实验采用 2-step 预训练方法:首先,在 ImageNet-22K-ext 数据集上使用自监督方法对模型进行 20epoch 的预训练。其次,在 ImageNet-1K V1 和 V2 分类任务上,继续将模型进行 30epoch 预训练。
ImageNet-1K 图像分类结果:表 2 将 SwinV2-G 模型与之前在 ImageNet-1K V1 和 V2 分类任务上的最大 / 最佳视觉模型进行了比较。SwinV2-G 是之前所有密集(dense)视觉模型中最大的。它在 ImageNet V2 基准测试中达到了 84.0% 的 top-1 准确率,比之前最好的 ViT-G (83.3%) 高 0.7%。但是,SwinV2-G 在 ImageNet-1K V1 上的准确率比 CoAtNet-7 略低(90.17% 比 90.88%)。

COCO 目标检测结果:表 3 将 SwinV2-G 模型与之前在 COCO 目标检测和实例分割任务上取得最佳性能模型进行了比较。SwinV2-G 在 COCO test-dev 上实现了 63.1/54.4 box/max AP,比 SoftTeacher(61.3/53.0) 提高了 + 1.8/1.4。这表明扩展视觉模型有利于目标检测任务中的密集视觉识别任务。

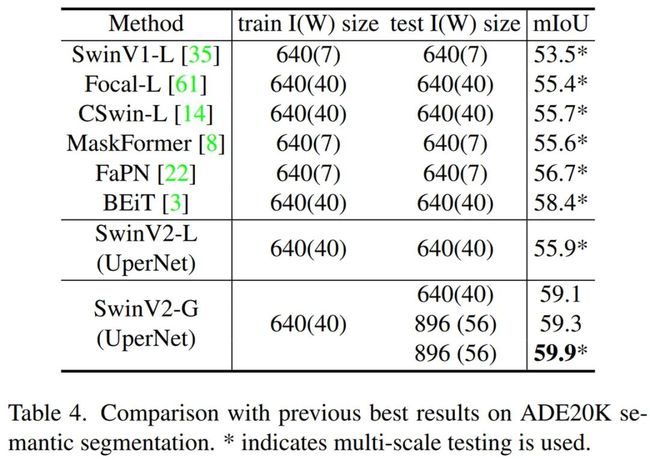
ADE20K 语义分割结果:下表 4 将 SwinV2-G 模型与之前在 ADE20K 语义分割基准上的 SOTA 结果进行了比较。Swin-V2-G 在 ADE20K val 集上实现了 59.9 mIoU,比之前的 SOTA 结果(BEiT)58.4 高了 1.5。这表明扩展视觉模型有益于像素级视觉识别任务。在测试时使用更大的窗口大小还可以带来 +0.2 的增益,这可能归功于有效的 Log-spaced CPB 方法。
Kinetics-400 视频动作分类结果:下表 5 将 SwinV2-G 模型与之前在 Kinetics-400 动作分类基准上的 SOTA 结果进行了比较。可以看到,Video-SwinV2-G 实现了 86.8% 的 top-1 准确率,比之前的 SOTA (TokenLearner)85.4% 高出 +1.4%。这表明扩展视觉模型也有益于视频识别任务。在这种场景下,在测试时使用更大的窗口大小也可以带来额外增益 ( +0.2% ),这也要归功于有效的 Log-spaced CPB 方法。

post-norm 和缩放余弦注意力的消融实验:下表 6 展示了 post-norm 和缩放余弦注意力方法应用于原始 Swin Transformer 方法的性能表现。可以看到,这两种方法都提高了 Swin-Tiny、Swin-Small 和 Swin-Base size 的准确率,整体提升分别为 +0.2%、+0.4% 和 +0.5%,表明它们对更大的模型更有益。
