大型互联网高可用&高并发业务架构设计(2)
大型互联网高可用&高并发业务架构设计
- 高并发业务架构设计实践
-
- 软件架构中的高并发思考
-
- 什么是高并发?
- 高并发下系统设计问题的思考
- 如何保障系统的高并发?
-
- 数据层优化
- 应用层优化
- 前端优化
- 多级缓存应用
- 连接池详解
- 线程池详解
-
- Java线程池
- Tomcat线程池
-
- 配置方式一
- 配置方式二
- 线程数计算
- 异步并发
-
- 异步Future
- 异步Callback
- 服务扩容
- 队列MQ应用
-
- 缓冲队列
- 任务队列
- 消息队列
- 系统性能优化实践
-
- 性能问题的来源
- 常见的性能分析方法
-
- load average
-
- 单核CPU
- 4核CPU
- 60s快速排错
-
- 系统异常
- 业务异常
- 实现高性能系统考虑的问题
高并发业务架构设计实践
软件架构中的高并发思考
什么是高并发?
- 高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
- 高并发相关常用的一些指标有响应时间(Response Time)、吞吐量(Throughput)、每秒查询率QPS(Query Per Second)、并发用户数等。
- 响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
- 吞吐量:单位时间内处理的请求数量(并发数量)。
- QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
- 并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
- 重点:
- QPS:每秒查询数量。
- TPS:每秒事务数量,一个接口请求从发送请求到接收到响应为止,代表一个 TPS。
- 吞吐量:每秒请求数量。
- QPS、TPS、吞吐量有何区别?
- 在大多数情况下:QPS = TPS = 吞吐量
- 但是例如,一次访问一个页面 index.html(里面可能还有css、js),那么 QPS = 3,TPS = 1。
高并发下系统设计问题的思考
- 大家也许开发过高并发的系统或者一些高并发类似秒杀程序,但肯定都有接触过,像电商平台的秒杀、抢购等活动,还有12306春运抢票。
- 互联网公司,做一些有奖活动,而且数量有限,奖品给力,如果是先到先得的策略,那就类似秒杀系统了。
- 这类系统最大的问题就是活动周期短,瞬间流量大(高并发),很少人可以成功下单,绝大多数人都是很遗憾。所以从运营体验上,没有成功下单的人,心里肯定是不好受的,如果这时候,因为技术、网络问题,影响用户体验,那就更是骂声一片。
下面是基本的概念的建立
- 第一、高并发:技术要做的事,一方面优化程序,让程序性能最优,单次请求时间能从50ms优化到25ms,那就可以在一秒钟内成功响应翻倍的请求了。另一方面就是增加服务器,用更大的集群来处理用户请求,设计好一个可靠且灵活扩充的分布式方案就更加重要了。
- 总结就是:加机器,高性能机器,架构、性能优化。
- 第二、时间短:火热的秒杀活动,真的是一秒钟以内就会把商品抢购一空,而大部分用户的感受是,提交订单的过程却要等待好几秒、甚至十几秒,更糟糕的当然是请求报错。那么一个好的秒杀体验,当然希望尽可能减少用户等待时间,准确的提示用户当前是否还有商品库存。而这些,也是需要有优秀的程序设计来保证的。
- 第三、系统容量预估:系统设计的时候,都需要有一个容量预估,那就是要提前计算好,我们设计的系统,要承载多大的数量级。
- 例如:8核16G内存服务器,订单处理能力 100ms。那么,QPS = 1000ms/100ms * 8 = 80 QPS ---- 单台服务器,非常低。
- 优化程序后,订单处理耗时 10ms。那么,QPS = 1000ms/10ms * 8 = 800 QPS。
- 订单业务:判断库存——默认库存是无限的——下单时间:1ms
- 第四、好的分布式方案:一个好的分布式方案,首先当然是稳定可靠,不要出乱子,然后就是方便扩充,最好的效果当然是增加一台服务器,并发处理量可以1:1线性增长。
- 例如:单机QPS : 1000;10台服务器: 1w;100台服务器:10w/s。
- 第五、关注系统的瓶颈:大家先有几个基本的共识,系统的处理速度:
程序内数据读写 > redis > mysql > 磁盘,单机网络请求 > 局域网内请求 > 跨机房请求。我们优化程序的时候,尽量用最快的方式,尽量用最简短的逻辑。用redis替代mysql来保存订单处理中依赖的数据,用程序中的提交的数据代替从redis中二次获取数据,比如:商品库存信息,用户订单信息。逻辑处理中,把速度快且提前中断的逻辑放在最前面,比如:验证登录,验证问答。我们做分布式方案的时候,尽量把资源调用放在最近的地方。前端服务器依赖的数据尽量就在局域网内,如果能在单机都有读的redis服务当然更好,程序维护数据响应会复杂些。 - 不要出现跨机房网络请求,不要出现跨机房网络请求,不要出现跨机房网络请求,重要的事情说三遍。
如何保障系统的高并发?
- 服务尽量进行拆分部署(分布式:SOA、微服务); — 业务纵向拆分,化整为零,资源拆分,横向扩展
- 尽量将请求拦截在系统上游(越上游越好); — 限流,缓存
- 读多写少多使用缓存(缓存抗读压力); — 读缓存,写异步
- 浏览器和APP:做限速(漏桶原理) — 限速,限流
- 站点层:按照uid做限速,做页面缓存
- 服务层:按照业务做写请求队列控制流量,做数据缓存 – 队列缓冲
- 数据层:压力就小了,无忧无虑 –-数据库优化
- 其他方面:结合业务做优化
具体解决方案:
- 缓存(应用级别缓存、http缓存、多级缓存)
- 连接池
- 异步
- 扩容
- 队列
- 项目简单逻辑分层图示结构:优化策略具体可以分为 数据层优化,应用层优化,前端优化
数据层优化
1、数据库优化 — RT — 吞吐量
- 集群(分表、分库、读写分离【解决读压力】)
- 索引
- 开启缓存
- SQL优化
- 冗余设计
- 防止写复杂SQL
- 冷热数据分离
2、分布式文件系统: - 开源文件系统FastDFS
- 云服务
3、日志数据/搜索数据/简单业务数据: - ElasticSearch ms
- Redis缓存
应用层优化
- web服务器优化 (线程池,连接队列)
- JVM优化
- 代码结构优化(code review)
- 分布式拆分(提高吞吐量,提高集群部署网络数量)
- 异步架构
- 异步并发编程
- 队列
- 线程池
- nosql
前端优化
- DNS缓存
- CDN缓存
- 浏览器缓存
- nginx缓存
多级缓存应用
- http 缓存:DNS缓存、CDN缓存、浏览器缓存、nginx缓存。
- 应用级别缓存:代码级别缓存。
- 所谓缓存,就是让数据离用户更近,RT时间更短,吞吐量更高。
- 例如:
- CPU架构(三级缓存):L1(查询)、L2(查询)、L3(查询)
- Maven:先查询本地仓库,再查询远程仓库
- 对项目来说:
- 堆缓存:使用Java堆内存缓存对象,使用技术方案 Ehcache 实现缓存。堆缓存不需要对象序列化。
- 内存缓存:内存缓存,缓存的大小取决于内存大小,技术方案 Ehcache 实现缓存。
- 磁盘缓存:缓存数据存储在磁盘,JVM启动后,还能从磁盘加载,技术方案 Ehcache 实现缓存,设置过期时间。
- 分布式缓存:使用第三方缓存服务器 Redis、memcached
- 大型项目中:构造高性能项目,一定重视缓存应用,非常重要。
连接池详解
- 连接池目的是通过连接池减少频繁创建连接,释放连接,降低消耗,提升性能 (吞吐量)。
- 有哪些连接池:数据库连接,Redis连接池,Http连接池,……
- 技术方案:Apache commons pool2 , jedis, druid, dbcp,……
思考:是否知道连接池怎么配置?设置多少个队列,设置多少个线程?
例如:1w QPS 2W TPS 连接池应用设置多少?
回答:尽量设置大些吧,设置个500吧,此话是否正确?
- Oracle 数据测试数据分析:https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing

- 通过oracle公司公布的测试数据发现:连接池设置变小了,执行数据反而变快了,RT时间变短了,性能更好了,这是什么原因造成的?
- 回答:线程池数据量太大,就会造成创建的线程过多,CPU使用的是时间分片切换线程的使用权,多个线程的频繁切换会消耗大量的时间。
线程池详解
- 线程池的目的类似于连接池,通过减少频繁创建和销毁线程来降低性能损耗。每个线程都需要一个内存栈,用于存储如局部变量、操作栈等信息,可以通过 -Xss 参数来调整每个线程栈大小,通过调整该参数可以创建更多的线程,不过JVM不能无限制地创建线程。
- 通过使用线程池可以限制创建的线程数,从而保护系统。线程池一般配合队列一起工作,使用线程池限制并发处理任务的数量。
- 然后设置队列的大小,当任务超过队列大小时,通过一定的拒绝策略来处理,这样可以保护系统免受大流量而导致崩溃。只是部分拒绝服务,还是有一部分是可以正常服务的。
- 线程池一般有核心线程池大小和线程池最大大小配置,当线程池中的线程空闲一段时间时将会被回收,而核心线程池中的线程不会被回收。

多少个线程合适呢?
建议根据实际业务情况来压测决定,或者根据利特尔法则来算出一个合理的线程池大小,其定义是,在一个稳定的系统中,长时间观察到的平均用户数量L,等于长时间观察到的有效到达速率λ与平均每个用户在系统中花费的时间的乘积,即L= λW。但实际情况是复杂的,如存在处理超时、网络抖动都会导致线程花费时间不一样。因此,还要考虑超时机制、线程隔离机制、快速失败机制等,来保护系统免遭大量请求或异常情况的冲击。
- Java提供了ExecutorService的三种实现:
- ThreadPoolExecutor:标准线程池
- ScheduledThreadPoolExecutor:支持延迟任务的线程池
- ForkJoinPool:类似于ThreadPoolExecutor,但是使用work-stealing模式,其会为线程池中的每个线程创建一个队列,从而用work-stealing(任务窃取)算法使得线程可以从其他线程队列里窃取任务来执行。即如果自己的任务处理完成了,则可以去忙碌的工作线程那里窃取任务执行。
Java线程池
使用Executors来创建线程池。
- 创建但线程的线程池:
ExecutorService executorService = Executors.newSingleThreadExecutor();
- 创建固定数量的线程池:
ExecutorService executorService = Executors.newFixedThreadPool(10);
- 创建可缓存的线程池:初始大小为0,线程池最大大小为 Integer.MAX_VALUE。其使用SynchronousQueue队列,一个没有数据缓冲的阻塞队列。对其执行put操作后必须等待take操作消费该数据,反之亦然。该线程池不限制最大大小,如果线程池有空闲线程则复用,否则会创建一个新线程。如果线程池中的线程空闲60秒,则将被回收。该线程默认最大大小为 Integer.MAX_VALUE,请确认必要后再使用该线程池。
ExecutorService executorService = Executors.newSingleThreadExecutor();
- 支持延迟执行的线程池:其使用DelayedWorkQueue实现任务延迟
ExecutorService executorService = Executors.newScheduledThreadPool(10);
- work-stealing线程池:
ExecutorService executorService = Executors.newWorkStealingPool(5);
- corePoolSize: 核心线程池大小,线程池维护的线程最小大小,即没有任务处理情况下,线程池可以有多个空闲线程,类似于 DBCP 中的 minIdle。
- maximumPoolSize: 线程池最大大小,当任务数非常多时,线程池可创建的最大线程数量。
- keepAliveTime: 线程池中线程的最大空闲时间,存活时间超过该时间的线程会被回收,线程池会一直缩小到corePoolSize大小。
- workQueue: 线程池使用的任务缓冲队列,包括有界阻塞数组队列 ArrayBlockingQueue、有界/无界阻塞链表队列 LinkedBlockingQueue、优先级阻塞队列 PriorityBlockingQueue、无缓冲区阻塞队列 SynchronousQueue。有界阻塞队列须要设置合理的队列大小。
- threadFactory: 创建线程的工厂,我们可以设置线程的名字、是否是后台线程。
- rejectedExecutionHandler: 当缓冲队列满后的拒绝策略,包括 Abort(直接抛出RejectedExecutionException)、Discard(按照LIFO丢弃)、DiscardOldest(按照LRU丢弃)、CallsRun(主线程执行)。
Tomcat线程池
- 以Tomcat 8为例配置如下:
配置方式一
<Connector port="8080" acceptCount="100" maxConnections="200" minSpareThreads="10" maxThreads="200" />
- acceptCount: 请求等待队列大小。当Tomcat没有空闲线程处理连接请求时,新来的连接请求将放入等待队列,默认为100。当队列超过acceptCount后,新连接请求将被拒绝。
- maxConnections: Tomcat能处理的最大并发连接数。当超过后还是会接收连接并放入等待队列(acceptCount控制),连接会等待,不能被处理。BIO默认是maxThreads数量。NIO和NIO2默认是10000,ARP默认是8192。
- minSpareThreads: 线程池最小线程数,默认为10。该配置指定线程池可以维持的空闲线程数量。
- maxThreads: 线程池最大线程数,默认为200。当线程池空闲一段时间后会释放到只保留minSpareThreads个线程。
举例,假设 maxThreads=100,maxConnections=50,acceptCount=50,假设并发请求为 200,则有 50 个线
程并发处理 50 个并发连接,50 个连接进入等待队列,剩余 100 个将被拒绝。也就是说Tomcat最大并发线程数是由maxThreads和maxConnections中最小的一个决定。BIO场景下maxConnections和maxThreads是一样的,当我们需要长连接场景时,应使用NIO模式,并发连接数是大于线程数的。
配置方式二
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-" deamon="true" minSpareThread="25" maxThreads="200" maxIdleTime="60000" maxQueueSize="Integer.MAX_VALUE" prestartminSpareThreads="false" />
<Connector port="8080" executor="tomcatThreadPool" executorTerminationTimeoutMills="5000" />
- 此处我们使用了 org.apache.catalina.Executor 实现,其表示一个可在多个 Connector 间共享的线程池,而且有更丰富的配置。
- namePrefix:创建的Tomcat线程名字的前缀。
- deamon:是否守护线程运行,默认为true。
- minSpareThreads:线程池最小线程数,默认为25。
- maxThreads:线程池最大线程数,默认为200。
- maxIdleTime:空闲线程池的存活时间,默认为60s。当线程空闲超过该时间后,线程将被回收。
- maxQueueSize:任务队列最大大小,默认为Integer.MAX_VALUE,建议改小。可以认为是maxConnections。
- prestartminSpareThreads:是否在 Tomcat 启动时就创建 minSpareThreads 个线程放入线程池,默认为false。
- executorTerminationTimeoutMillis:在停止Executor时,等待请求处理线程终止的超时时间。
- 最后,要根据业务场景和压测来配置合理的线程池大小,配置太大的线程池在并发量较大的情况下会引起请求处理不过来导致响应慢,甚至造成Tomcat僵死。
线程数计算

- 公式一:
Ncpu = CPU 核心数量
Ucpu = CPU 使用率
W/C = 线程等待时间 /(等待时间+计算时间)
线程池数量 = Ncpu * Ucpu * (1 + w/c)
- 公式二:
线程池数量 = Ncpu / (1 – 阻塞系数)
阻塞系数 = waittime / (waittime + cpu time)
* 阻塞系数:
* 计算密集型的任务阻塞系数是0
* IO密集型阻塞系数:无限制靠近1
例如: 阻塞系数= 0.9
线程数=16 /(1-0.9) = 160 线程
经验值设置:
Cpu密集型: threads = N + 1
Io密集型: theads = 2*N
异步并发
- 在应用中一个服务可能会调用多个依赖服务来处理业务,而这些依赖服务是可以同时调用的。如果顺序调用的话需要耗时 100ms,而并发调用只需要 50ms,那么可以使用Java并发机制来并发调用依赖服务,从而降低该服务的响应时间。
- 在开发应用系统过程中,通过异步并发并不能使响应变得更快,更多是为了提升吞吐量、对请求更细粒度控制,或是通过多依赖服务并发调用降低服务响应时间。当一个线程在处理任务时,通过 Fork 多个线程来处理任务并等待这些线程的处理结果,这种应用并不是真正的异步。
- 异步是针对 CPU 和 IO 的,当 IO 没有就绪时要让出 CPU 来处理其他任务,这才是异步。
异步Future
- 线程池配合Future实现,但是阻塞主请求线程,高并发时依然会造成线程数过多、CPU上下文切换。
- 通过Future可以并发发出N 个请求,然后等待最慢的一个返回,总响应时间为最慢的一个请求返回的用时。如下请求如果并发访问,则响应可以在30ms后返回。

- 实现代码:
public class Test {
private static final ExecutorService executor = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
RpcService rpcService = new RpcService();
HttpService httpService = new HttpService();
Future<Map<String, String>> future1 = null;
Future<Integer> future2 = null;
try {
future1 = executor.submit(rpcService::getRpcResult);
future2 = executor.submit(httpService::getHttpResult);
// 耗时 10ms
Map<String, String> result1 = future1.get(300, TimeUnit.MILLISECONDS);
// 耗时 20ms
Integer result2 = future2.get(300, TimeUnit.MILLISECONDS);
// 总耗时 20ms
} catch (Exception e) {
if (future1 != null) future1.cancel(true);
if (future2 != null) future2.cancel(true);
throw new RuntimeException(e);
}
}
static class RpcService {
Map<String, String> getRpcResult() throws Exception {
// 调用远程方法(远程方法耗时约10ms)
TimeUnit.MILLISECONDS.sleep(10);
return null;
}
}
static class HttpService {
Integer getHttpResult() throws Exception {
// 调用远程方法(远程方法耗时约20ms)
TimeUnit.MILLISECONDS.sleep(20);
return 200;
}
}
}
异步Callback
- 通过回调机制实现,即首先发出网络请求,当网络返回时回调相关方法,如HttpAsyncClient使用基于NIO的异步I/O模型实现,它实现了Reactor模式,摒弃阻塞I/O模型one thread per connection,采用线程池分发事件通知,从而有效支撑大量并发连接。这种机制并不能提升性能,而是为了支撑大量并发连接或者提升吞吐量。
- 实现代码:
public class AsyncTest {
private static HttpAsyncClient httpAsyncClient;
public static CompletableFuture<String> getHttpData(String url) {
CompletableFuture asyncFuture = new CompletableFuture();
HttpAsyncRequestProducer producer = HttpAsyncMethods.create(new HttpPost(url));
BasicAsyncResponseConsumer consumer = new BasicAsyncResponseConsumer();
FutureCallback callback = new FutureCallback<HttpResponse>() {
@Override
public void completed(HttpResponse response) {
asyncFuture.complete(response);
}
@Override
public void failed(Exception e) {
asyncFuture.completeExceptionally(e);
}
@Override
public void cancelled() {
asyncFuture.cancel(true);
}
};
httpAsyncClient.execute(producer, consumer, callback);
return asyncFuture;
}
public static void main(String[] args) throws Exception {
CompletableFuture<String> future = AsyncTest.getHttpData("http://www.jd.com");
String result = future.get();
}
}
服务扩容

- 对于这样一个系统,随着产品使用的用户越来越多,网站的流量会增加,最终单台服务器无法处理那么大的流量,此时就需要用分而治之的思想来解决问题。
- 第一步是尝试通过简单扩容来解决。
- 第二步,如果简单扩容搞不定,就需要水平拆分和垂直拆分数据/应用来提升系统的伸缩性,即通过扩容提升系统负载能力。
- 第三步,如果通过水平拆分/垂直拆分还是搞不定,那就需要根据现有系统特性,从架构层面进行重构甚至是重新设计,即推倒重来。
- 对于系统设计,理想的情况下应支持线性扩容和弹性扩容,即在系统瓶颈时,只需要增加机器就可以解决系统瓶颈,如降低延迟提升吞吐量,从而实现扩容需求。
- 如果你想扩容,则支持水平/垂直伸缩是前提。在进行拆分时,一定要清楚知道自己的目的是什么,拆分后带来的问题如何解决,拆分后如果没有得到任何收益就不要为了拆而拆,即不要过度拆分,要适合自己的业务。
队列MQ应用
缓冲队列
- 使用缓冲队列应对突发流量时,并不能使处理速度变快,而是使处理速度变平滑,从而不会因瞬间压力太大而压垮应用。
- 通过缓冲区队列可以实现批量处理、异步处理和平滑流量。
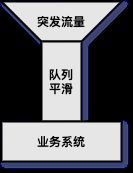
任务队列
- 使用任务队列可以将一些不需要与主线程同步执行的任务扔到任务队列进行异步处理。【例如线程池任务队列(默认为LinkedBlockingQueue)和 Disruptor 任务队列(RingBuffer)。】
- 如用户注册完成后,将发送邮件/送积分/送优惠券任务扔到任务队列进行异步处理;刷数据时,将任务扔到队列异步处理,处理成功后再异步通知用户,处理成功后异步通知用户。以及查询聚合时,将多个可并行处理的任务扔到队列,然后等待最慢的一个任务返回。
消息队列
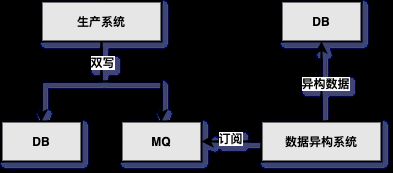
- 使用消息队列存储各业务数据,其他系统根据需要订阅即可。例如:修改商品数据、变更订单状态时,都应该将变更信息发送到消息队列,如果其他系统有需要,则直接订阅该消息队列即可。
- 一般我们会在应用系统中采用双写模式,同时写DB和MQ,然后异构系统可以订阅MQ进行业务处理(见下图)。因为在双写模式下没有事务保证,所以会出现数据不一致的情况,如果对一致性要求没那么严格,则这种模式是没问题的,而且在实际应用中这种模式也非常多。
系统性能优化实践
性能问题的来源
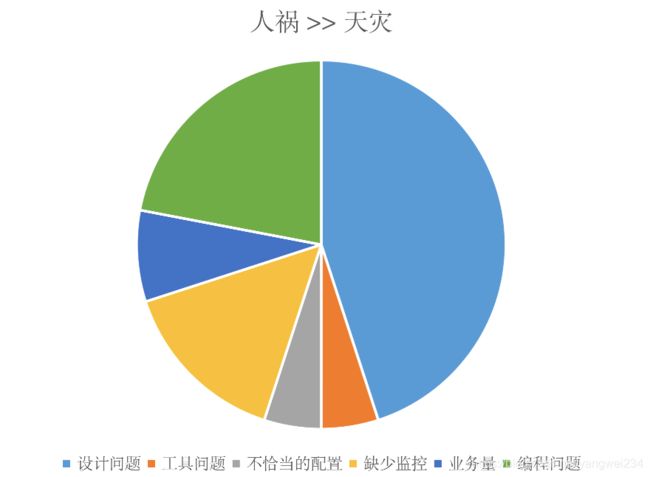
- 解决问题的思维定势:非业务高峰,瞬时峰值已 87% CPU,是否可以优先考虑给系统增加服务器?
常见的性能分析方法
load average
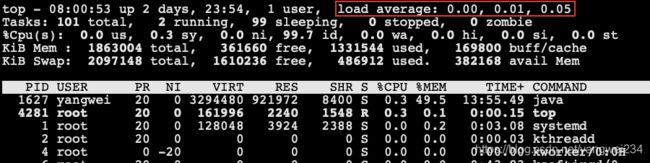
- 代表系统的繁忙程度,三个参数分别是 1 分钟、5 分钟、15 分钟 CPU 的平均负载。
单核CPU
- Load average < 1 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 1 , cpu刚刚占满,没有空闲空间;
- Load average > 1 , cpu已经出现了线程等待,比较繁忙;
- Load average > 3 , cpu阻塞非常严重,出现了严重线程等待。
4核CPU
- Load average < 4 , cpu比较空闲,没有出现线程等待cpu执行现象;
- Load average = 4 , cpu刚刚占满,没有空闲空间;
- Load average > 4 , cpu已经出现了线程等待,比较繁忙;
- Load average > 9 , cpu阻塞非常严重,出现了严重线程等待;
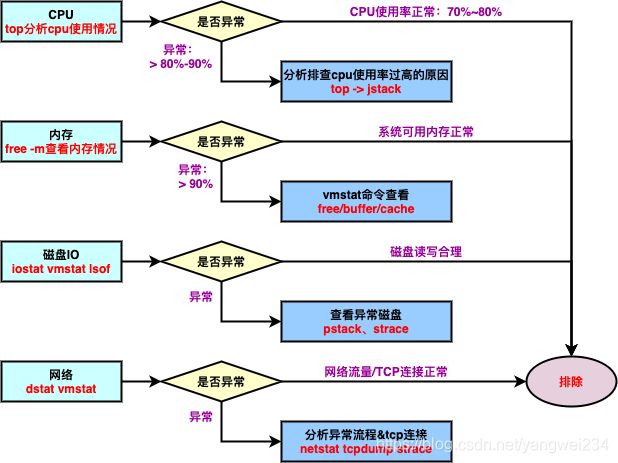
60s快速排错
- 服务上线运行后:系统异常(磁盘满了、CPU持续飙升);业务异常(bug、Full GC、GC)…
系统异常
业务异常
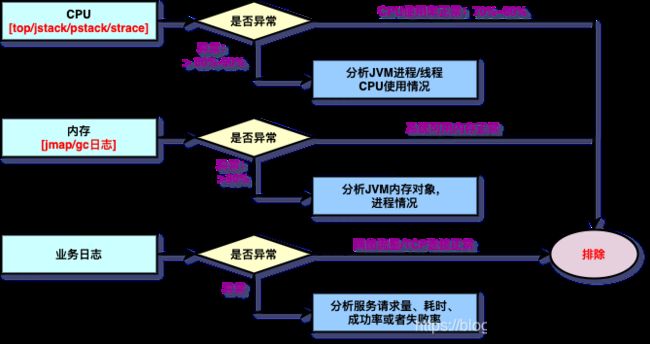
实现高性能系统考虑的问题
实现高并发需要考虑:
- 1、系统的架构设计,如何在架构层面减少不必要的处理(网络请求,数据库操作等)例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间。
- 2、网络拓扑优化减少网络请求时间、如何设计拓扑结构,分布式如何实现?
- 分布式、微服务、servicemesh、serverless。
- 3、系统代码级别的代码优化,使用什么设计模式来进行工作?哪些类需要使用单例,哪些需要尽量减少new操作?
- GC、STW
- 4、提高代码层面的运行效率、如何选取合适的数据结构进行数据存取?如何设计合适的算法?
- 5、任务执行方式级别的同异步操作,在哪里使用同步,哪里使用异步?
- 读缓存,写异步
- 6、JVM调优,如何设置Heap、Stack、Eden的大小,如何选择 GC 策略,控制 Full GC 的频率?
- 响应时间优先,并发优先
- 7、服务端调优(线程池,等待队列)
- 8、数据库优化减少查询修改时间。数据库的选取?数据库引擎的选取?数据库表结构的设计?数据库索引、触发器等设计?是否使用读写分离?还是需要考虑使用数据仓库?
- 连接池优化,MySQL查询语句优化,表结构设计优化;架构优化(分表分库)
- 9、缓存数据库的使用,如何选择缓存数据库?是Redis还是Memcache? 如何设计缓存机制?
- 10、数据通信问题,如何选择通信方式?是使用TCP还是UDP,是使用长连接还是短连接?NIO还是BIO?netty、mina还是原生socket?
- 内网: tcp
- 连接: 长连接,保证连接的复用性,提高性能
- 11、操作系统选取,是使用 Windows 还是 Linux?或者 Unix?
- 12、硬件配置?是 8G 内存还是 32G,网卡 10G 还是 1G?
- 例如:增加 CPU 核数如 32 核,升级更好的网卡如万兆,升级更好的硬盘如 SSD,扩充硬盘容量如 2T,扩充系统内存如 128G。