医学数据挖掘学习项目:他克莫司
目录
1. 报告
2. 代码1:从数据库中提取数据
lambda,匿名函数,快速定义单行函数,可以用在任何需要函数的地方。
numpy.array 和 python.array
python.filter(function, iterable)函数
python zip(a, b)
pandas创建DataFrame()数据
pandas判断是否是空值NaN,isnull(),notnull()
pandas.reset_index()
pandas.astype()
pandas.Excel_Writer()输出到excel
mysql
pandas.concat()函数
pandas merge()方法
pandas.concat() 和 pandas.merge()区别
pandas rename()方法
pandas.DataFrame.columns
pandas.loc[行,列]
pandas.iloc[行号,列号]
pandas.drop()函数
pandas.drop_duplicates()方法
pandas.isnull() 和 .notnull()
pandas.DataFrame.replace(to_place, value)
pandas数据透视表pivot_table(data,values,index,columns,aggfunc='mean')
pandas DataFrame.sort_values()方法
pandas.groupby()方法
pandas statsmodels
pandas DataFrame.describe()
pandas.get_dummies
3. 代码2:初始方案数据清洗
pydotplus
pylab
Ipython.display.image
time.time()
datetime.datetime.strptime(x, %Y-%m-%d %H:%M:%S)
datetime.timedelta(days=2)
TDM
bug
python list(range(9))
4. 代码3:调整方案数据清洗
5. 代码4:初始&调整方案建模
sklearn.model_selection
sklearn.metrics
sklearn.train_test_split
sklearn分类器classifier和回归其regressor的区别
sklearn选择合适的算法/sklearn中各种分类器regressor都适用于什么样的数据
python auto_ml
误差(error),偏差(bias),方差(variance)有什么区别和联系?
scipy.stats
Mann-Whitney U 检验
卡方检验,检验两个变量之间有没有关系
重要性评分柱状图
SHAP图
matplotlib
from matplotlib import pyplot as plt
python seaborn
SPSS倾向性分析
logistic回归
牛顿迭代法(Newton-Raphson)
1. 报告
know what, know how。知道是干什么的,怎么干的
目的:他克莫司用药日剂量
XGBoost, GBDT, Boosting, boosting,误分类样本的权值之和影响误差率,误差率影响分类器在最终分类器中的权重。
基分类器,h1的权重![]() ,误差越大,权重越小
,误差越大,权重越小
分类器:![]()
样本权重更新:![]()
XGBoost输出变量重要性 -->xgb.importance返回由f分数测量的特征重要范围
stepwise regression逐步回归
propensity score倾向性评分 <--由于实验组和对照组两组病人的基线水平存在差异,倾向性评分匹配法消除数据集中的混杂因素。
==>两独立样本t检验:方差齐性检验,p,0.05;t检验/修正t检验
比较特征的差异显著性:连续特征,Mann-Whitney U检验;离散特征,卡方检验。
2. 代码1:从数据库中提取数据
(1) database:surgical_record
.ipynb文件为Jupyter notebook,是一个python交互式笔记本,包含代码、运行结果展示、其他内部设置
data: surgical_record['surgery_NAME'].str.contains('肾’)
- .pandas.str.contains()筛选出包含特殊字符的数列,返回布尔值系列或索引
- .numpy.unique()函数,去除列表或数组中重复的元素,并按元素从小到大返回一个新的无重复元素的新列表或元组。
- .shape输出DataFrame行列数。shape[0] 行;shape[1] 列
lambda,匿名函数,快速定义单行函数,可以用在任何需要函数的地方。
lambda 参数 :操作(参数)
- apply(),对数据框(DataFrame)(类似矩阵)的数据进行按行或按列操作时用apply(),默认axis=0,按行;axis=1,按列
- map(),对series的每一个数据进行操作时用map()
np.nan,创建空值
numpy.array 和 python.array
numpy.array,生成一个数组,他的强大在于可以生成多维数据,而python.array只支持以为数组。
python.filter(function, iterable)函数
- function -- 判断函数
- iterable -- 可迭代对象/序列
python zip(a, b)
将对应的元素打包成一个个元组,然后返回由这些元组组成的列表
pandas创建DataFrame()数据
本质是通过list列表创建
- 方法1: 通过列表创建
li = [
[1, 2, 3, 4],
[2, 3, 4, 5]
]
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d1 = pd.DataFrame(data=li, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print(d1)
- 方法2: 通过numpy对象创建
narr = np.arange(8).reshape(2, 4)
# DataFRame对象里面包含两个索引, 行索引(0轴, axis=0), 列索引(1轴, axis=1)
d2 = pd.DataFrame(data=narr, index=['A', 'B'], columns=['views', 'loves', 'comments', 'tranfers'])
print(d2)
- 方法3: 通过字典的方式创建;
dict = {
'views': [1, 2, ],
'loves': [2, 3, ],
'comments': [3, 4, ]
}
d3 = pd.DataFrame(data=dict, index=['粉条', "粉丝"])
print(d3)
- DataFrame提取某几列数据
list = ['text', 'image', 'voice']
df_p = df[[list]]
pandas判断是否是空值NaN,isnull(),notnull()
pd.DataFrame([('bird',389), ('bird',24), ('mammal',80), ('mammal', np.nan)], index(行)=['falcon','parrot','lion','monkey'], columns=('class', 'max_speed') )
class max_speed falcon bird 389 parrot bird 24 lion manmmal 80.5 monkeyh manmmal NaN
pandas.reset_index()
把就索引列添加为列,并使用心得顺序索引。drop参数=True,避免将旧索引添加为列,默认为False
- pandas.set_index,把数据列设为索引列
pandas.astype()
因为多个表合并到一个表,输出列Excel表发生数据错误,e.g.数值型数据末尾变0,所以python强制类型转换。
df.astype('数据类型')
df['列名'].astype('数据类型') --一列数据类型改变
pandas.Excel_Writer()输出到excel
writer=pd.ExcelWriter(project_path + '/data/data_from_mysql/df_检验序号索引.xlsx')
test_record_tcms.to_excel(writer)
writer.save()(2) 用药医嘱表单
mysql
# 连接mysql数据库
conn = MySQLDB.connect(host='localhost', port=3306, user='root', password='123456', db='mdnov_ciip_ipharma_zdy', charset='UTF8')
cursor = conn.cursor()
cursor.execute("Select version()")
for i in cursor:
print(i)
try:
sql = 'select TEST_RECORD_ID,PROJECT_CODE,PROJECT_NAME,TEST_RESULT,RESULT_UNIT,IS_NORMAL,REFER_SCOPE from test_result;'
test_result = pd.read_sql(sql, conn)
except MySQLDB.err.ProgrammingError as e:
print('test_result Error is ' + str(e))
sys.exit()where子句,有条件的从表中选取数据
pandas DataFrame.head(),返回数据帧或序列的前n行(默认值为5)
pandas.concat()函数
用来连接DataFrame对象,行列相同或行列不同,缺失部分为NaN
pandas merge()方法
left,拼接的左侧DataFrame对象。
right,拼接的右侧DataFrame对象。
on,要加入的列或索引级别名称
how,inner,交集;outer,并集;left只用左侧;right只用右侧keys
pandas.concat() 和 pandas.merge()区别
concat() 是上下拼接;merge()是左右合并
pandas rename()方法
修改DataFrame的个别列名或索引,e.g. df.rename({'表1':'纬度'})
pandas.DataFrame.columns
返回列标签
(3) 检验表单
pandas.loc[行,列]
e.g. temp.loc[0:2,'Drug_Name'],loc表示location,.loc[['Drug_Name', 'Project_Name']]
pandas.iloc[行号,列号]
e.g. [0:3, [4:6]],第3行取不到,第6列能取到
pandas.drop()函数
DataFrame删除一行或一列。默认axis=0,行;axis=1,列
pandas.drop_duplicates()方法
.drop_duplicates(subset='列名',keep='first',inplace='True'),删除DataFrame某列中重复项的函数
- subset='列名1' 或 ['列名1','列名2']
- keep='first' 或 'last',保留第一个或最后一个
pandas.isnull() 和 .notnull()
判断缺失值一般采用isnull()和notnull()。
.isnull().sum(),每列缺失值的数量
(4) 检验结果表单
pandas.DataFrame.replace(to_place, value)
将to_replace数值/字符串替换为value
pandas数据透视表pivot_table(data,values,index,columns,aggfunc='mean')
- values,可以对需要的计算数据进行筛选
- 每个pivot_table必须拥有一个index, index=['对手'],行
- columns,类似index可以设置列层次字段,它不是必要参数,作为一种分割数据的可选方式
- aggfunc,可以设置我们对数据聚合时进行的函数操作
pandas DataFrame.sort_values()方法
.sort_values(by='##', axis=0, ascending=True, inplace=Flase),根据指定列数据排序
- by,指定列名(axis=0,行) 或 索引名(axis=1,列)
- ascending, 默认True,升序
- inplace,默认False,排序后数据不替换原来的数据
(5) 诊断表单
pandas.groupby()方法
.groupby(by=['列名'], axis=0, as_index)
- as_index按某一列分组,相同字段分到同一组。将分组列名作为输出索引
- mean()方法求平均值
pandas statsmodels
传统频率学派统计方法
- statsmodels.api:模型和方法
- statsmodels.tsa.api:统计和测试
- statsmodels.formula.api:模型,从公式和数据框创建模型
pandas DataFrame.describe()
用于查看一些基本的统计信息,e.g. 百分位数,均值,标准差
pandas.get_dummies
pandas从DataFrame数据实现one hot encode的方式。
3. 代码2:初始方案数据清洗
pydotplus
pydotplus -->绘图,比Graphviz支持中文
pylab
pylab是matplotlib的一个子包,适合交互式绘图
pylab.mpl -->rcParams解决matplotlib无法显示中文或负号的情况
# 支持显示中文
mpl.rcParams['font.sans-serif'] = ['SimHei'] ##绘图显示中文
mpl.rcParams['axes.unicode_minus'] = FalseIpython.display.image
显示图像,Ipython是一个python的交互式shell,比python shell好用。利用python进行科学计算和交互可视化的一个最佳平台
- 强大的python交互式shell
- 共Jupyter notebooks使用的一个Jupyter内核(Ipython notebook)
time.time()
获取当前时间
datetime.datetime.strptime(x, %Y-%m-%d %H:%M:%S)
将数据转换为日期的方法
datetime.timedelta(days=2)
对象代表两个时间之间的时间差,两个date或datetime对象相减可以返回一个timedelta对象。
TDM
治疗药物监测,测定药物浓度,therapeutic drug monitoring
bug
- 295,数据清洗-->删除没有tdm检测的病人,需要人工设置patient_id
- 312,
python list(range(9))
可以把range()返回的可迭代对象转化为一个列表
(2) 筛选初始方案中tdm符合终点事件的用药和tdm检测组合
(3) 筛选调整方案中tdm符合终点事件的用药和tdm检测组合
(4) 初始方案所有变量数据清洗
- BMI:身体质量指数
- DataFrame取多列数据用[]把多个列名括起来,[['drug_name', 'project_name']]
(5) 其他用药
start_time <= TDM
end_time >= tcms_3 days前
4. 代码3:调整方案数据清洗
Graphviz -->开源的强大绘图工具,编写dot脚本
%matplotlib inline -->用再Jupyter notebook中具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图时,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。
5. 代码4:初始&调整方案建模
sklearn.model_selection
.model_selection,主要是对数据的分割,以及与数据分割相关的功能
train_test_split方法,将原始数据集划分成train和test两部分
sklearn.metrics
- accuracy_score -->所有分类正确的百分比,
- .log_log,对数损失或交叉熵损失
- confusion_matrix --> 混淆矩阵
| predictual class | ||
| Actual class |
||
- 计算R方。from sklearn.metrics import r2_score
R²的定义如下:![Alt]在这里插入图片描述从公式来看,即使我们不使用任何模型,仅仅用目标集标签的平均值,就能让R2_score为0,如果值为负数,则表示我们预测的结果还不如测试集中的y_label的平均值准确

sklearn.train_test_split
用来随机划分样本数据为训练集和测试集
train_x, test_x, train_y, test_y = train_test_split(train_data,train_target,test_size=0.2,random_state=5)- train_data,待划分样本数据
- train_target,待划分样本数据结果标签
- test_size:测试集占比
- random_state:设置随机数种子。若为0或不填,则每次得到的数据都不同。随机数种子用于生成伪随机数,真随机数是指现实物理现象。
sklearn分类器classifier和回归其regressor的区别
标签数据labeled data
- classification:which category,识别物体属于哪一类。Identifying which category an object belongs to。应用:垃圾邮件检测,图像识别等。score函数计算的是精确度,accuracy_score --> mean accuracy
- regression:quantity,预测与物体相关的连续值属性。Predicting a continuous-valued attribute associated with an object.应用:药物反应、股票价格。score函数计算的是
 ,r2_score -->预测的r2决定系数
,r2_score -->预测的r2决定系数 - clustering: Automatic grouping of similar objects into sets.应用:用户细分,分组实验结果。
- Dimensionality relation:降维,reducing the number of random variables to consider。应用:可视化,提高效率
- Model selection: comparing, validating and choosing parameters and models. 应用:通过参数调整提高精度
- Processing:Feature extraction and normalization.应用:转换输入数据,例如用于机器学习算法的文本
sklearn选择合适的算法/sklearn中各种分类器regressor都适用于什么样的数据
选择合适的ML Algorithms。不存在一个再各方面都最好的模型/算法,需要针对具体问题,找到最好的机器学习算法
- 数据分析(Exploratory Data Analysis)。在选择具体的算法之前,最好对数据中每一个特征的模式和产生原理有一定的了解。e.g. 特征是连续的(real-valued)还是离散的(discrete)?
- 特征工程(Feature Engineering)。特征工程(根据现有的特征,制造出新的有价值的特征)决定了机器学习能力的上限,各种算法不过是在逼近这个上限而已。不同的ML Algorithms一般会有其对应的不同的特征工程。在实践中,特征工程,调整算法参数这两个步骤常常往复进行。
- 具体算法选择。3.1) General Linear Models(high bias高偏差, low variance低方差) 如果对超参数没什么特别要求,可以通过自动的交叉验证来确定超参的值。线性分类器中,最好用的是logistic regression和相应的logistic regression CV。3.2) Ensemble methods。Bagging(random forest),用数据不同部分训练一群high variance算法来降低算法整体的方差;boosting(XGBoost),通过以此建立high bias算法来提升整体的variance。3.3) SVM。sum表现不如XGBoost。3.4) Neural Network。sklearn的神经网络库不如tensorflow、keras、pytorch、theane等
python auto_ml
用于生产和分析的自动化机器学习模块,包括:分析、特征工程、自动缩放、特征选择、模型选择、超参优化、大数据
from auto_ml import Predictor
from auto_ml.utils import get_boston_dataset
from auto_ml.utils_models import load_ml_modelfrom auto_ml import Predictor
1) 首先创建Predictor预测期
Predictor(type_of_estimator=, column_descriptions=)
·type_of_estimator,指定预测器类型(classifier or regressor)
·column_descriptions,字典类型,指定字段描述信息,如果为分类任务,需要制定Y所在的列(output)2) ml_predictor.train(train_data, model_names=['XGBoost'])
2.1) auto_ml集成了DeepLearningClassifier, DeepLearningRegressor, XGBClassifier, XGBRegressor, LGBMClassifier, LGBMRegressor, CatBoostClassifier, CatBoostRegressor,在model_names参数中选择。
2.2) auto_ml中的feature_learning=Ture,用深度学习为我们学习特征,梯度提升将这些特征转化为准确的预测 ==> 这种混合方法比任何一种方法都要精确5%,但要防止过拟合。
3) ml_predictor.score(test_x, test_x['日剂量']) 。
# Score the model on test data
Returns the coefficient of determination R^2 of the prediction. 不是计算准确度R^2,r2计算在from sklearn.metrics import r2_score
4) 保存。file_name = ml_predictor.save()
5) 导入训练好的model。trained_model = load_ml_model(file_name)
6) 预测。predictions = trained_model.predict(test_x)
报错:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you arenotusing fork to start your
child processesandyou have forgotten to use the proper idiom
inthe main module:
解决:设置一个main()函数,控制多线程。参考:Python多进程报错:RuntimeError: An attempt has been made to start a new process before the current process...
误差(error),偏差(bias),方差(variance)有什么区别和联系?
error=bias + variance,反映的是整个模型的准确度。
- bias,偏差。描述的是样本拟合出的model的输出预测结果的期望与样本真实结果的差距。简单讲,就是样本你和的好不好。(training set) 要想在bias上表现好,low bias,就得复杂化模型,增加模型的参数,但这样容易过拟合(overfitting),过拟合容易使正确的数据错分,造成方差过大high variance,点很分散。
- variance,方差。描述的是样本上训练出来的模型在测试集上的表现,要想在variance上表现好,low variance,就要简化模型,减少模型的参数,但这样容易欠拟合(unfitting),欠拟合对应上面的high bias,错误的数据被误认为正确,点偏离中心。
- bias可以理解为偏见,对数据是否一视同仁,高偏见high bias,准确但分散。high bias+low variance --> model太简陋,准确度低;low bias + high variance --> model普适性差
- 在训练集上,可以进行交叉验证(cross-validation)。一种方法叫k-fold cross validation(k-折交叉验证);初始样本分割成k个子样本,一个单独的子样本被保留作为验证模型的数据,其他k-1个样本用来训练。交叉验证重复k次,每个子样本验证一次,平均k次的结果或使用其他结合方式,最终得到一个单一估测 ==> 降低异常数据对模型的影响。k大时,偏差越小,方差越大;k小时,偏差越大,方差越小。
scipy.stats
python统计函数率,该模块包含大量概率分布、汇总和频率统计,相关函数和统计检验、屏蔽统计,核密度估计、Monte Carlo等。e.g. Mann-Whitney U test, Wilcoxon signed rank test, Chi-square test.
Mann-Whitney U 检验
是检验两个独立样本差异性的测试(在数据分布上是否有差异)。当样本正态分布、方差齐次等不能达到t检验的要求时,可以用Mann-Whitney U test。
检验基础:若两个样本有差异,则他们中心位置不同。
e.g. 春夏季犯罪数据是否有差异。原假设:无,显著性差异P值 < 0.05,显著 ==> 有差异。
return: statistic: float = min(U for x, U for y); P值: float
卡方检验,检验两个变量之间有没有关系
from scipy.stats import chi2_contingency
卡方检验要求X、Y都是定类数据
自由度 = (行数-1) * (列数-1) ==>查询得到临界值 ==> 卡方< 临界值,成立
scipy.stats.chi2_contingency(observed), observed, array_like, R*C table, 默认Pearson's 卡方统计
Return ==> chi2: float; p: float; dof: 自由度; expected: 预期频率
· 用log-likelihood ratio --> chi2——contingency(obs, lambda_ = 'log-likelihood')
重要性评分柱状图
重要性评分~参考:Python中XGBoost的特性重要性和特性选择_liuzh的博客-CSDN博客
1) 注意数据类型!!!
.colums()函数返回index object;importance返回np.ndarray;pd.DataFrame主要是根据list列表数据生成。
2) ValueError: shape of passed value is (3,1), indices imply (3,3)
np.array().reshape(3,4)
3) plt.bar不显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] ##绘图显示中文
mpl.rcParams['axes.unicode_minus'] = False
from matplotlib import pyplot as plt
import matplotlib.ticker as ticker
from matplotlib import rc
rc('mathtext', default='regular')SHAP图
参考:SHAP:Python的可解释机器学习库 - 孙佳伟的文章 - 知乎
SHAP图的基础是shap values(归因值)和shape interaction values(交互归因值),基于此二值可以生成:
- force plot。单个样本预测的解释
- summary plot。全部样本预测的解释
- dependency plot。特征值大小与预测影响之间的关系。
matplotlib
-
.pyplot:绘图模块,让用户绘制2D图表。
-
.ticker:用于配置刻度定位和格式的类。其中Locater类根据数据限制和刻度位置的选择处理视图限制的自动缩放
-
.rc:设置当前的rcParams,e.g. linewidth,color
-
axes.Axes.get_figure(),获取fiture实例。
from matplotlib import pyplot as plt
- plt.plot(x,y,[fmt],**kwargs),点或线的x, y坐标,[fmt]包含颜色color,标记marker,linestyle等可迭代参数。label=' ' 是**kwargs中可用的其他参数
- plt.legend(loc, bbox_to_anchor=(1.1,1)),显示图例
- plt.xlabel 和 plt.ylabel,设置坐标轴标签
- plt.savefig() 保存图例,需要想创建好保存路径,savefig只能保存不能创建。dpi分辨率
- plt.figure(figsize=(15, 8)),设置fiture的宽和高
- plt.sticks,设置x坐标轴的刻度及标签。rotation=75 --> 标签旋转;tick,刻度
- plt.text(a, b+2, ha=, va=, fontsize= ) ,将文本添加到x,y的坐标轴上。hahorizontalalignment的缩写,设置水平对齐方式;va是vertical缩写,设置垂直对齐方式。
- plt.show() 画图。调用pyplot.show()后保存图形会导致文件为空
-
matplotlib画图的时候怎么清空之前图片。
clf() # 清图。
cla() # 清坐标轴。
close() # 关窗口python seaborn
实在matplotlib基础上面的封装,方便直接传参调用。
- seaborn.boxplot(x,y, hu, data=df_box, color=()) 绘制箱线图
SPSS倾向性分析
匹配估计的思想:if你要研究企业R&D投入对performance的影响。有两家企业,其R&D投入明显不同,但是其他各方面都高度相同,e.g. 公司规模、杠杆率、所属行业、公司治理结构等,那么在其他各方面都高度相同的情况下,这是就可以吧公司performance的差异鬼影刀R&D投入的差异。
这种找到一个控制组(实验)的个体,使得该个体与处理组(对照)的个体在除自变量外其他各因素都相似(也就是匹配),在通过自变量的差异解释因变量差异的行为,就是匹配的思想。
一般来说,每个样本有多个属性,e.g.一家公司,属性有公司规模、公司年龄、杠杆率、增长率、市场占有率、行业等,这就意味着匹配时要考虑诸多属性,也就是进行高维度匹配,一个比较好的思路是定义高维空间的距离,然后计算两个样本在高维空间的距离。
但高维匹配并不容易,因为维度越高找一个各方面相似的两个个体越难。
引入--> 倾向性评分匹配(Propensity score matching, PSM),定义一个个体进入处理组的概率。
PSM是指,某个体在处理组,找一个其他各方面与该个体尽量相似的控制组个体的概率。
PSM匹配的是自变量之外(R&D)的需要控制的其他所有协变量X。根据PS分值,SPSS筛选出匹配成功的match_id对(可根据实际情况选择合适的ps限定,增加匹配成功数)
PSM:如果自变量是连续变量,需要转换为二元离散变量。
协变量:指与因变量有线性相关,并在探讨自变量与因变量关系时通过统计计数加以控制的变量。(除自变量与因变量外,其他需要控制的变量)
倾向得分匹配(PSM)的原理与步骤 - CanisMajoris的文章 - 知乎
logistic回归
logistic回归为概率型非线性回归模型,是研究二分类观察结果y与一些影响因素(x1,x2,....,xn)之间关系的一种多变量分析方法。通常问题是,研究某些因素条件下某个结果是否发生,比如医学中根据病人的一些症状来判断它是否含有某种病。
在讲解logistic回归理论之前,先从LR分类器说起,logistic refression classifier。在分类情形下,经过学习后的LR分类器是一组权值w0,w1,.....,wn
x=wo+w1x1+.......+wnxn,xi为n个特征
之后按sigmoid函数的形式求出
![]()
因此,最基本的LR分类器适合二分类。
logistic回归最关键的问题是研究如何求得w0, w1, .....wn这组权值 <=用极大似然估计来做。
logistic函数:![]() ,g(x) = w0+w1x1+......+wnxn
,g(x) = w0+w1x1+......+wnxn
射条件概率P(y=1|x) =p为根据观测量相对于某事件y发生的概率。
牛顿迭代法(Newton-Raphson)
作用:用迭代的方法来求解函数方程的根。简单来说,就是不断求取切线的过程。
关键:构建迭代式。
- 根据泰勒展开近似:
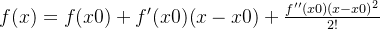 ==>
==> 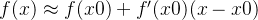
- f(x)=0的近似根
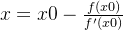
- 迭代式:
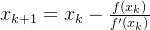 ==>若序列收敛于a,a就是非线性方程根。
==>若序列收敛于a,a就是非线性方程根。