k8s调度原理和策略
k8s调度器Scheduler
Scheduler工作原理
请求及Scheduler调度步骤:
节点预选(Predicate):排除完全不满足条件的节点,如内存大小,端口等条件不满足。
节点优先级排序(Priority):根据优先级选出最佳节点
节点择优(Select):根据优先级选定节点

1.首先用户通过 Kubernetes 客户端 Kubectl 提交创建 Pod 的 Yaml 的文件,向Kubernetes 系统发起资源请求,该资源请求被提交到Kubernetes 系统中,用户通过命令行工具 Kubectl 向 Kubernetes 集群即 APIServer 用 的方式发送“POST”请求,即创建 Pod 的请求。
2.APIServer 接收到请求后把创建 Pod 的信息存储到 Etcd 中,从集群运行那一刻起,资源调度系统 Scheduler 就会定时去监控 APIServer
3.通过 APIServer 得到创建 Pod 的信息,Scheduler 采用 watch 机制,一旦 Etcd 存储 Pod 信息成功便会立即通知APIServer,APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。
而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点
节点预选:基于一系列的预选规则对每个节点进行检查,将那些不符合条件的节点过滤,从而完成节点的预选
节点优选:对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点
节点选定:从优先级排序结果中挑选出优先级最高的节点运行Pod,当这类节点多于1个时,则进行随机选择
k8s的调用工作方式
Kubernetes调度器作为集群的大脑,在如何提高集群的资源利用率、保证集群中服务的稳定运行中也会变得越来越重要Kubernetes的资源分为两种属性。
可压缩资源(例如CPU循环,Disk I/O带宽)都是可以被限制和被回收的,对于一个Pod来说可以降低这些资源的使用量而不去杀掉Pod。
不可压缩资源(例如内存、硬盘空间)一般来说不杀掉Pod就没法回收。未来Kubernetes会加入更多资源,如网络带宽,存储IOPS的支持。
常用预选策略

常用优先函数
节点亲和性调度
节点亲和性规则:硬亲和性 required 、软亲和性 preferred。
Affinity 翻译成中文是“亲和性”,它对应的是 Anti-Affinity,我们翻译成“互斥”。这两个词比较形象,可以把 pod 选择 node 的过程类比成磁铁的吸引和互斥,不同的是除了简单的正负极之外,pod 和 node 的吸引和互斥是可以灵活配置的。
Affinity的优点:
匹配有更多的逻辑组合,不只是字符串的完全相等
调度分成软策略(soft)和硬策略(hard),在软策略下,如果没有满足调度条件的节点,pod会忽略这条规则,继续完成调度。
目前主要的node affinity:
requiredDuringSchedulingIgnoredDuringExecution
表示pod必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。其中IgnoreDuringExecution表示pod部署之后运行的时候,如果节点标签发生了变化,不再满足pod指定的条件,pod也会继续运行。
requiredDuringSchedulingRequiredDuringExecution
表示pod必须部署到满足条件的节点上,如果没有满足条件的节点,就不停重试。其中RequiredDuringExecution表示pod部署之后运行的时候,如果节点标签发生了变化,不再满足pod指定的条件,则重新选择符合要求的节点。
preferredDuringSchedulingIgnoredDuringExecution
表示优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署。
preferredDuringSchedulingRequiredDuringExecution
表示优先部署到满足条件的节点上,如果没有满足条件的节点,就忽略这些条件,按照正常逻辑部署。其中RequiredDuringExecution表示如果后面节点标签发生了变化,满足了条件,则重新调度到满足条件的节点。
软策略和硬策略的区分是有用处的,硬策略适用于 pod 必须运行在某种节点,否则会出现问题的情况,比如集群中节点的架构不同,而运行的服务必须依赖某种架构提供的功能;软策略不同,它适用于满不满足条件都能工作,但是满足条件更好的情况,比如服务最好运行在某个区域,减少网络传输等。这种区分是用户的具体需求决定的,并没有绝对的技术依赖。
下面是一个官方的示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: another-node-label-key
operator: In
values:
- another-node-label-value
containers:
- name: with-node-affinity
image: gcr.io/google_containers/pause:2.0
这个 pod 同时定义了 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution 两种 nodeAffinity。第一个要求 pod 运行在特定 AZ 的节点上,第二个希望节点最好有对应的 another-node-label-key:another-node-label-value 标签。
这里的匹配逻辑是label在某个列表中,可选的操作符有:
In: label的值在某个列表中
NotIn:label的值不在某个列表中
Exists:某个label存在
DoesNotExist:某个label不存在
Gt:label的值大于某个值(字符串比较)
Lt:label的值小于某个值(字符串比较)
如果nodeAffinity中nodeSelector有多个选项,节点满足任何一个条件即可;如果matchExpressions有多个选项,则节点必须同时满足这些选项才能运行pod 。
需要说明的是,node并没有anti-affinity这种东西,因为NotIn和DoesNotExist能提供类似的功能。
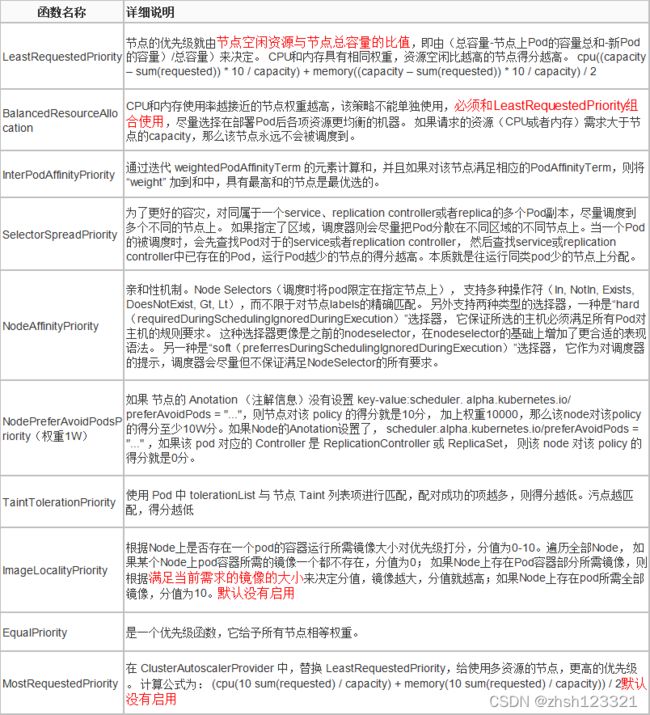
节点软亲和性的权重
preferredDuringSchedulingIgnoredDuringExecution
柔性控制逻辑,当条件不满足时,能接受被编排于其他不符合条件的节点之上
权重 weight 定义优先级,1-100 值越大优先级越高
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-deploy-with-node-affinity
spec:
replicas: 2
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp-pod
labels:
app: myapp
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution: #节点软亲和性
- weight: 60
preference:
matchExpressions:
- {key: zone, operator: In, values: ["foo"]}
- weight: 30
preference:
matchExpressions:
- {key: ssd, operator: Exists, values: []}
containers:
- name: myapp
image: ikubernetes/myapp:v1
Pod资源亲和调度
Pod对象间亲和性,将一些Pod对象组织在相近的位置(同一节点、机架、区域、地区)
Pod对象间反亲和性,将一些Pod在运行位置上隔开
调度器将第一个Pod放置于任何位置,然后与其有亲和或反亲和关系的Pod据此动态完成位置编排
基于MatchInterPodAffinity预选策略完成节点预选,基于InterPodAffinityPriority优选函数进行各节点的优选级评估
位置拓扑,定义"同一位置"
Pod硬亲和调度
requiredDuringSchedulingIgnoredDuringExecution
Pod亲和性描述一个Pod与具有某特征的现存Pod运行位置的依赖关系;即需要事先存在被依赖的Pod对象
# 被依赖Pod
kubectl run tomcat -l app=tomcat --image tomcat:alpine
kubectl explain pod.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.topologyKey
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬亲和调度
- labelSelector:
matchExpressions: #集合选择器
- {key: app, operator: In, values: ["tomcat"]} # 选择被依赖Pod
# 上面意思是,当前pod要跟标签为app值为tomcat的pod在一起
topologyKey: kubernetes.io/hostname # 根据挑选出的Pod所有节点的hostname作为同一位置的判定
containers:
- name: myapp
image: ikubernetes/myapp:v1
Pod软亲和调度
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp-with-preferred-pod-affinity
spec:
replicas: 3
selector:
matchLabels:
app: myapp
template:
metadata:
name: myapp
labels:
app: myapp
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
podAffinityTerm:
labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["cache"]}
topologyKey: zone
- weight: 20
podAffinityTerm:
labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["db"]}
topologyKey: zone
containers:
- name: myapp
image: ikubernetes/myapp:v1
Pod反亲和调度
Pod反亲和调度用于分散同一类应用,调度至不同的区域、机架或节点等
将 spec.affinity.podAffinity替换为 spec.affinity.podAntiAffinity
反亲和调度也分为柔性约束和强制约束
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app: myapp
tier: fronted
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- {key: app, operator: In, values: ["myapp"]}
topologyKey: zone
污点和容忍度
污点 taints 是定义在节点上的键值型属性数据,用于让节点拒绝将Pod调度运行于其上,除非Pod有接纳节点污点的容忍度容忍度 tolerations 是定义在Pod上的键值属性数据,用于配置可容忍的污点,且调度器将Pod调度至其能容忍该节点污点的节点上或没有污点的节点上
使用PodToleratesNodeTaints预选策略和TaintTolerationPriority优选函数完成该机制
节点亲和性使得Pod对象被吸引到一类特定的节点 (nodeSelector和affinity)
污点提供让节点排斥特定Pod对象的能力
定义污点和容忍度
污点定义于nodes.spec.taints容忍度定义于pods.spec.tolerations
语法: key=value:effect
effect定义排斥等级:
NoSchedule,不能容忍,但仅影响调度过程,已调度上去的pod不受影响,仅对新增加的pod生效。
PreferNoSchedule,柔性约束,节点现存Pod不受影响,如果实在是没有符合的节点,也可以调度上来
NoExecute,不能容忍,当污点变动时,Pod对象会被驱逐
在Pod上定义容忍度时:
等值比较 容忍度与污点在key、value、effect三者完全匹配
存在性判断 key、effect完全匹配,value使用空值
一个节点可配置多个污点,一个Pod也可有多个容忍度
管理节点的污点
同一个键值数据,effect不同,也属于不同的污点
给节点添加污点:
kubectl taint node =:
kubectl taint node node2 node-type=production:NoShedule #举例
查看节点污点:
kubectl get nodes -o go-template={{.spec.taints}}
删除节点污点:
kubectl taint node [:]-
kubectl patch nodes -p '{"spec":{"taints":[]}}'
kubectl taint node kube-node1 node-type=production:NoSchedule
kubectl get nodes kube-node1 -o go-template={{.spec.taints}}
#删除key为node-type,effect为NoSchedule的污点
kubectl taint node kube-node1 node-type:NoSchedule-
删除key为node-type的所有污点
kubectl taint node kube-node1 node-type-
删除所有污点
kubectl patch nodes kube-node1 -p '{"spec":{"taints":[]}}'
给Pod对象容忍度
spec.tolerations字段添加
tolerationSeconds用于定义延迟驱逐Pod的时长
等值判断
tolerations:
- key: "key1"
operator: "Equal" #判断条件为Equal
value: "value1"
effect: "NoExecute"
tolerationSeconds: 3600
存在性判断
tolerations:
- key: "key1"
operator: "Exists" #存在性判断,只要污点键存在,就可以匹配
effect: "NoExecute"
tolerationSeconds: 3600
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
domainNames: ""
exposeType: HostNetwork
io.daocloud/dce.ingress.metrics-port: "12955"
lbType: nginx
taintNodes: "false"
tpsLevel: "20000"
watchNamespace: ""
creationTimestamp: "2021-09-15T06:36:59Z"
generation: 1
labels:
ingress.loadbalancer.dce.daocloud.io/ingress-type: nginx
io.daocloud.dce.ingress.controller.name: ""
loadbalancer.dce.daocloud.io/adapter: ingress
loadbalancer.dce.daocloud.io/instance: lb01
resource.ingress.loadbalancer.dce.daocloud.io: lb01
name: lb01-ingress1
namespace: kube-system
resourceVersion: "28248"
selfLink: /apis/apps/v1/namespaces/kube-system/deployments/lb01-ingress1
uid: 760b31d3-66b0-4547-8438-fb7f972344a5
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
name.ingress.loadbalancer.dce.daocloud.io/lb01: enabled
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
annotations:
prometheus.io/port: "12955"
prometheus.io/scrape: "true"
creationTimestamp: null
labels:
ingress.loadbalancer.dce.daocloud.io/ingress-type: nginx
name.ingress.loadbalancer.dce.daocloud.io/lb01: enabled
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: beta.kubernetes.io/os
operator: In
values:
- linux
- key: kubernetes.io/hostname
operator: In
values:
- dce-172-16-17-21
- dce-172-16-17-22
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: name.ingress.loadbalancer.dce.daocloud.io/lb01
operator: In
values:
- enabled
topologyKey: kubernetes.io/hostname
containers:
- args:
- /nginx-ingress-controller
- --healthz-port=12955
- --status-port=12989
- --https-port=12973
- --default-server-port=12956
- --stream-port=12943
- --profiler-port=12963
- --http-port=12987
- --configmap=kube-system/lb01-ingress
- --default-ssl-certificate=kube-system/lb01-ingress
- --tcp-services-configmap=kube-system/lb01-tcp-services
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
image: 172.16.17.250/kube-system/dce-ingress-controller:v0.46.0-1
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 12955
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
name: nginx-ingress-controller
ports:
- containerPort: 12955
hostPort: 12955
name: healthz
protocol: TCP
- containerPort: 12989
hostPort: 12989
name: status
protocol: TCP
- containerPort: 12973
hostPort: 12973
name: https
protocol: TCP
- containerPort: 12956
hostPort: 12956
name: default-server
protocol: TCP
- containerPort: 12943
hostPort: 12943
name: stream
protocol: TCP
- containerPort: 12963
hostPort: 12963
name: profiler
protocol: TCP
- containerPort: 12987
hostPort: 12987
name: http
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /healthz
port: 12955
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 5
resources:
limits:
cpu: "4"
memory: 2Gi
requests:
cpu: "1"
memory: 512Mi
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log
name: log-volume
dnsPolicy: ClusterFirst
hostNetwork: true
initContainers:
- args:
- -c
- ' mkdir -p /var/log/nginx; chown -hR 101:101 /var/log/nginx; mkdir -p /var/log/dce-ingress; chown
-hR 101:101 /var/log/dce-ingress; echo init-done;'
command:
- /bin/sh
image: 172.16.17.250/kube-system/dce-busybox:1.30.1
imagePullPolicy: IfNotPresent
name: init
resources: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /var/log/
name: log-volume
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: lb01
serviceAccountName: lb01
terminationGracePeriodSeconds: 60
tolerations:
- effect: NoSchedule
key: node-role.kubernetes.io/master
- effect: NoSchedule
key: node-role.kubernetes.io/load-balance
- key: CriticalAddonsOnly
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/disk-pressure
operator: Exists
- effect: NoSchedule
key: node.kubernetes.io/memory-pressure
operator: Exists
volumes:
- hostPath:
path: /var/log/
type: Directory
name: log-volume
问题节点标识
自动为节点添加污点信息,使用NoExecute效用标识,会驱逐现有Pod
K8s核心组件通常都容忍此类污点
node.kubernetes.io/not-ready 节点进入NotReady状态时自动添加
node.alpha.kubernetes.io/unreachable 节点进入NotReachable状态时自动添加
node.kubernetes.io/out-of-disk 节点进入OutOfDisk状态时自动添加
node.kubernetes.io/memory-pressure 节点内存资源面临压力
node.kubernetes.io/disk-pressure 节点磁盘面临压力
node.kubernetes.io/network-unavailable 节点网络不可用
node.cloudprovider.kubernetes.io/uninitialized kubelet由外部云环境程序启动时,自动添加,待到去控制器初始化此节点时再将其删除
Pod优选级和抢占式调度
优选级,Pod对象的重要程度
优选级会影响节点上Pod的调度顺序和驱逐次序
一个Pod对象无法被调度时,调度器会尝试抢占(驱逐)较低优先级的Pod对象,以便可以调度当前Pod
Pod优选级和抢占机制默认处于禁用状态
启用:同时为kube-apiserver、kube-scheduler、kubelet程序的 --feature-gates 添加 PodPriority=true
使用:
事先创建优先级类别,并在创建Pod资源时通过 priorityClassName属性指定所属的优选级类别