华盛顿大学提出全新量化和微调方法,在DB-GPT上享受33B参数的LLM

©PaperWeekly 原创 · 作者 | 张洪洋
单位 | 西南财经大学硕士
研究方向 | AIGC

背景
大型语言模型(LLM)的发展日新月异,是近年来自然语言处理(NLP)领域的热门话题,LLM 可以通过大规模的无监督预训练来学习丰富的语言知识,并通过微调来适应不同的下游任务,从而在各种 NLP 任务上取得了令人瞩目的性能。
然而,LLM 也带来了一些挑战,其中一个便是它们的巨大规模和高昂的计算成本。例如,微调 LLaMA 的 65B 模型需要超过 780G 的显存,在 BLOOM-176B 上进行推理,需要 8 个 80GB 的 A100 gpu(每个约 1.5 万美元)。这远远超出了普通用户和研究者的可用资源。虽然最近出现的一些量化方法可以减少 LLM 的内存占用量,但是这些技术仅适用于推理,并不适合在训练过程中使用。因此,如何在保持或提高性能的同时,降低 LLM 的内存占用和训练时间,是一个急需解决的问题。
5 月 24 日华盛顿大学在《QLORA: Efficient Finetuning of Quantized LLMs》这篇文章中提出了一种针对 LLM 的低精度量化和高效微调技术,可以在保证完整的 fp16 的微调任务性能的同时,减少内存使用,从而能够在单个 48GB 显存的 GPU 上微调 65B 参数模型。
作者 Tim Dettmers 在 huggingface 上已经公布了他们利用 QLoRA 方法训练的系列模型 Guanaco,其中 33b 和 65b 的模型可以直接下载使用,7b 和 13b 的模型需要和对应的 LLaMA 模型进行参数融合。同时作者表明 Guanaco 在 Vicuna 基准测试中的表现超过了所有以前公开发布的模型,在 24 小时内微调的 Guanaco 65B 大模型甚至能够达到 GPT4 性能水平的 99.3%。以下是华盛顿大学的作者所公布的数据:

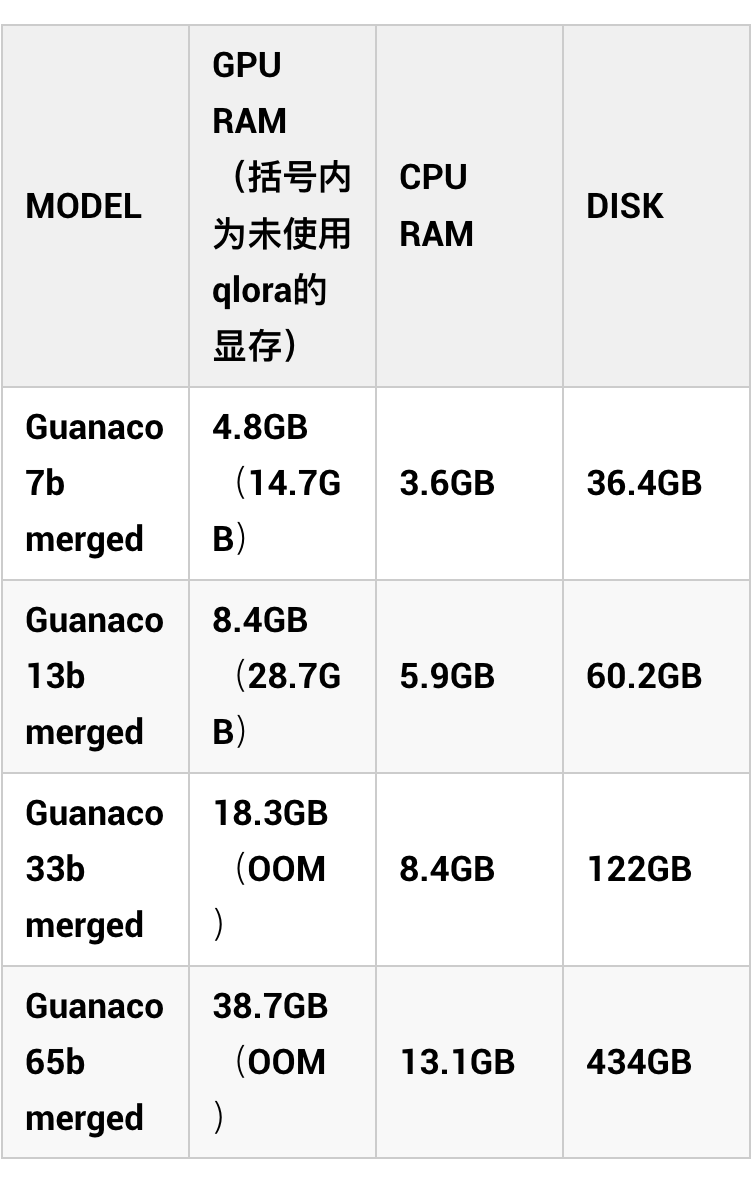
看到这里相信有很多同学已经按捺不住准备去尝试了,但如果我告诉你只要 5 元就可以在 DB-GPT 上部署自己的 Guanaco 33b 模型呢 在安全隐私的环境下拥有如此一个强大的模型将对个人知识库将带来怎样的改变?不妨先耐着性子看完以下介绍

QLoRA
总的来说 QLoRA 使用一种低精度的存储数据类型(NF4)来压缩预训练的语言模型。通过冻结 LM 参数,将相对少量的可训练参数以 Low-Rank Adapters 的形式添加到模型中,LoRA 层是在训练期间更新的唯一参数,使得模型体量大幅压缩同时推理效果几乎没有受到影响。
QLoRA 的核心技术有三个:4-bit NormalFloat(NF4)量化、Double Quantization 和 Paged Optimizers。QLoRA 的 Q 其实已经很明显的说明了量化(Quantize)技术,所以我们首先简单了解一下量化。
2.1 核心技术
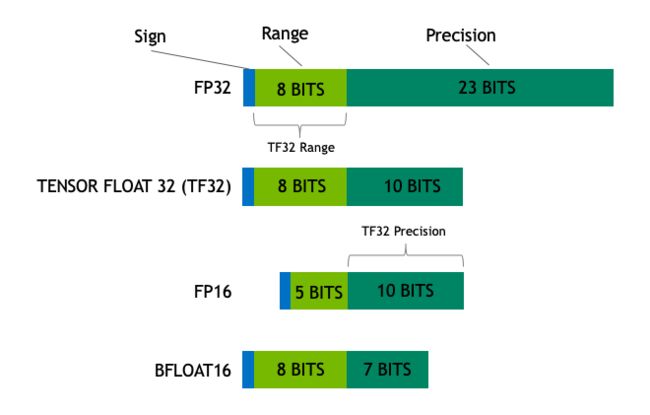
模型的大小通常由其参数的数量及其精度决定,常见的精度有全精度 float32(FP32)、半精度 float16(FP16)和 bfloat16(BF16)、英伟达的 TF32。
FP32:单精度浮点数,用 8bit 表示指数,23bit 表示小数。使用此数据类型,可以表示各种浮点数,并且支持大多硬件。
FP16:半精度浮点数,用 5bit 表示指数,10bit 表示小数。FP16 表示整数范围较小,但是尾数精度较高。
BF16:是对 FP32 单精度浮点数截断数据,用 8bit 表示指数,7bit 表示小数。BF16 可表示的整数范围与 FP32 一样广泛。但只有新的硬件(A100\3090\4090 等)才支持,V100/昇腾910等不支持
TF32:将 BF16 的动态范围和 FP16 的精度相结合,只使用19位。它目前仅在某些操作期间在内部使用。
在 ARM NEON 指令集中,一条指令最多 load 128bit 数据,则对于 FP32 的数据,一次性最多支持 4 个数据的并行计算;对 FP16/BF16 数据,一次性最多支持 8 个数据的并行计算,那么在计算中,FP16/BF16 的性能峰值应该是 FP32 的两倍。
而且,实验表明 FP16/BF16 往往能够在模型大小减半的情况下还能获得和 FP32 模型几乎相同的推理结果,这种惊人的效果吸引着众多研究人员前往更深的领域——FP8、FP4、FP2、FP1。许多量化的技术也逐渐引入了大模型的研究中。
2.1.1 LLM.int8 量化
量化的本质实际是从一种数据类型舍入到另一种数据类型,通常包含量化和反量化两步,假如我们有两组数据类型 A、B,A 可以表示的数值为 [0, 1, 2, 3, 4, 5],B 可以表示的数值为 [0, 2, 4]。我们要做的便是:
将数据范围从 A 标准化为 B。数据类型 A 表示的向量为 [3, 1, 2, 3]。
找到向量 [3, 1, 2, 3] 的最大绝对值 3
向量 [3, 1, 2, 3] 除以最大值 3:[3, 1, 2, 3]->[1, 0.33, 0.66, 1.0]
将向量 [1, 0.33, 0.66, 1.0] 与 B 的数据范围 4 相乘:[1, 0.33, 0.66, 1.0]->[4.0, 1.33, 2.66, 4.0]
将向量 [4.0, 1.33, 2.66, 4.0] 中的每个值用 B 中最接近的数值表示:[4.0, 1.33, 2.66, 4.0] -> [4, 0, 2, 4]。
用 B 中最接近的数值表示 A 。
[4, 0, 2, 4] 除以 4->[1.0, 0.0, 0.5, 1.0]
乘以量化过程中找到的最大的绝对值:[1.0, 0.0, 0.5, 1.0] -> [3.0, 0.0, 1.5, 3.0]
近似表示:[3.0, 0.0, 1.5, 3.0] -> [3, 0, 2, 3]

经过量化、反量化,原来的 [3, 1, 2, 3] 变成了 [3, 0, 2, 3],产生了量化误差。这样的误差在模型中传播、积累,最终会影响模型性能。提高量化精度的最佳方法是使用更多的量化参数。例如,我们有一个二维的张量:[[3, 1, 2, 3], [0, 1, 1, 0]]。如果分别为 [3, 1, 2, 3] 和 [0, 1, 1, 0] 设置独立的量化参数为各自的最大绝对值 3 和 1,那么量化的精度会比为整个 [[3, 1, 2, 3], [0, 2, 2, 0]] 只设置一个量化参数 3 更高。
同样是 Tim Dettmers,他在《LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale》这篇文章中提出将 vector-wise 量化与混合精度分解结合的方法 LLM.int8,这里简单介绍,具体细节见原文:
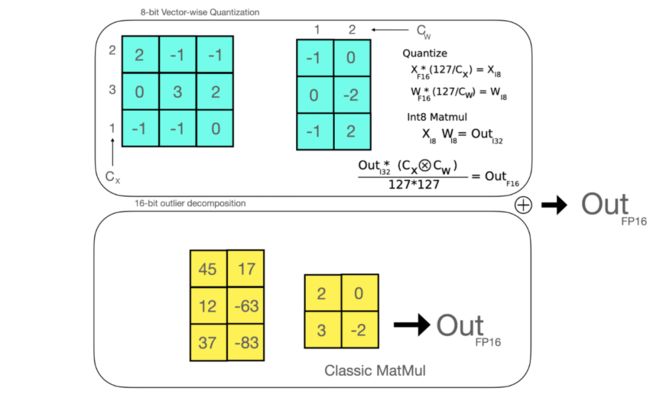
vector-wise 量化:为矩阵内积中独立的行、列向量设置各自的 scaling constant。这种量化方式引入了更多的量化参数,量化的结果也更加精确。
混合精度分解:Transformer 的 hidden state 中存在一些绝对值很大的离群值,这种离群值对于数据分布的影响是重大的。混合精度分解将包含了离群值的几个维度从矩阵中分离出来,对其做高精度的矩阵乘法;其余部分进行量化。
以下是 int8 和 FP16 的 OPT-175B 模型生成质量的对比结果:

以下是在 BLLOM 176B 模型,batch size 为 1、8、32 的情况下,BF16 和 LLM.int8 生成一个 token 所需的毫秒级的时间表现。

2.1.2 NF4
() 是建立在分位数量化技术的基础之上的一种信息理论上最优的数据类型。
由于预训练的神经网络权值通常具有标准差为0的正态分布性质,因此我们可以通过缩放系数将所有的权值转换为固定期望值,从而使该分布完全适合我们的数据类型范围。一旦权重范围和数据类型范围匹配,我们就可以像往常一样进行量化。
分位数量化技术的主要思想便是将数值尽量落到均值为 0,标准差为 [-1,1] 的正态分布的固定期望值上。前面我们知道离群值对于模型量化的影响极其重要,而由于分位数估计算法的近似性质,精度量化对于离群值又有很大的误差。分位数量化技术使得每个量化分区中具有相等的期望值,相等的期望值可以避免昂贵的分位数估计和近似误差,使得精确的分位数估计在计算上可行。
分位数量化技术步骤如下:
估计 N(0,1) 分布的 个分位数,得到正态分布的 k-bit 位量化数据类型。
将其值归一化到 [-1,1] 范围内
通过 absmax 去重新缩放权重张量的标准差,以获得 k-bit 的数据形式。
以下是分位数 的计算过程:

它在量化过程中保留了零点,并使用所有 位来表示 k-bit 数据类型。这种数据类型通过估计两个范围的分位数 来创建一个非对称的数据类型,这两个范围分别是负数部分 的 和正数部分 的 。然后,它统一了这两组分位数 ,并从两组中都出现的两个零中移除一个。这种结果数据类型在每个量化 bin 中都有相等的期望值数量,因此被称为 。
以 NF4,即 k=4 为例,标准正态分布量化函数把 [-1, 0] 分成 7 份,然后生成 [-1, ..., 0] 共 8 个分位数, 把 [0, 1] 分成 8 份,然后生成 [0, ..., 1] 共 9 个分位数,两个合起来去掉一个 0 就生成全部的 16 个分位数了。
创建了 NF4 数据类型的 个值,并用零填充,以便在 8 位量化函数中使用(256 个值,其中包括 256-16 个零)。该函数在 bitsandbytes 库中使用 8 位量化方法来“模拟” NF4。尽管算法可能有些晦涩,但以下是更直观的解释:
我们的目标是找到等面积的量化区间,使得量化区间左右两侧的面积相等。这意味着我们不从正态分布的 0 和 1 量化区间开始,而是从一个偏移量量化区间开始。代码片段中称之为“offset”,其值为 1-1/(215)。如果我们有一个非对称的数据类型,其中一侧的间隔等于每个量化区间周围的 16 个“半个”,而另一侧只有 15 个“半个”。因此,平均偏移量为 (1-1/(215) + 1-1/(2*16))/2 = 0.9677083。
我们使用 norm.ppf 函数获取标准正态分布(N(0, 1))的量化区间。然后,通过将这些量化区间的值除以绝对最大值来重新缩放它们。
2.1.3 Double Quantization
Double Quantization 是将额外的量化常数进行二次量化以减小内存开销的过程。例如每 64 个参数块共享一个 32bit 的量化常数, 这样的话相当于每一个参数的量化额外开销为 。这个总体来说也是比较大的一个开销,所以为了进一步优化这个量化开销,我们对其进行二次量化(Double Quantization),即把第一次 32bit 量化的输出作为第二次量化的输入,我们采用 256 的块大小对量化常数进行 FP8 量化,这样的话,我们可以把每个参数的量化额外开销降低到:

每个参数减少了 0.373bit。
2.1.4 Paged Optimizers
使用 NVIDIA 统一内存功能,该功能在 CPU 和 GPU 之间进行自动 page 对 page 传输,以便在 GPU 偶尔 OOM 的情况仍然下进行模型训练和微调。可以理解成显存偶发 OOM 时,QLoRA 会将优化器状态自动的驱逐到 CPU RAM,当在优化器更新步骤中需要内存时,它们会被分页回 GPU 内存,从而保证训练正常训练下去。
2.2 总结
QLoRA 的量化过程如下:QLoRA有一个用于基本模型权重的存储数据类型(NF4)和一个用于执行计算的计算数据类型(BF16)。QLoRA 将权重从存储数据类型反量化为计算数据类型以执行向前和向后传递, 但在传递过程中仅计算使用 BF16 的 LoRA 参数的权重梯度。权重仅在需要时解压缩,因此在训练和推理期间内存使用量保持较低。

文中还有几个观点值得关注:
NF4 量化优于 FP4 和 int4 量化的性能,并且 NF4+Double Quantization 减少存储的同时,精度并未下降。
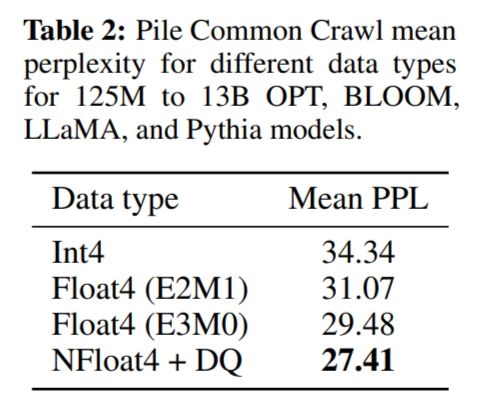
单卡 24G/48G 训练 33B/65B 模型的时候,Paged optimziers 表现很好。

使用默认的 LoRA 参数时,NF4 训练达不到 BF16 的评估指标,QLoRA(4bit) 需要 LoRA 应用到所有的 transformer 层才会有好的效果。

NF4+Double Quantization 的方案 finetune 的模型精度可以媲美 BFloat 16。
同时作者也在文章中留下了 Guanaco 模型的一些不足之处:
在模型评估过程中:人为的主观性影响着模型评估,在自动评估系统中,评估方式存在明显的偏见,系统对首次出现的结果给予更高的分数,并且 GPT-4 对其自身的输出给予的分数高于人类评分。
在数据准备过程中:训练 Guanaco 模型的 OASST1 数据集是多语言的,而 Vicuna13B 模型仅在英语数据上训练,这表明 Vicuna13B 与 Guanaco 模型的测试评估是不太公平的。
在模型训练过程中:Guanaco 仅使用交叉熵损失(监督学习)进行训练,而不依赖于来自人类反馈的强化学习(RLHF)。
总的来说,QLoRA 方法有三个意义:
QLoRA 是第一种能够在单个消费者 GPU 上微调 33B 参数模型和在单个专业 GPU 上微调 65B 参数模型的方法,同时相比于 full finetuning baseline 并不会降低性能。这有助于大模型微调方法的普及,让更多的普通人和小团队参与到 LLM 研究中来。
另一个是 QLoRA 为 LLM 在手机端微调训练带来了可能,作者估计在 iPhone 12 Plus 上,QLoRA 可以在手机充电状态下每晚微调 300 万个 token。
QLoRA 还可以帮助实现 LLM 的隐私保护,用户可以拥有和管理他们自己的数据和模型,同时 LLM 更容易部署。这一点会放在 DB-GBT 中讲述。
2.3 代码
QLoRA 的相关代码已经开源,下面简单介绍一下安装过程:
git clone https://github.com/artidoro/qlora.git
conda create -n qenv python-3.10
conda activate qenv
cd qlora
pip install -r requirements.txt
# 安装 bitsandbytes,transformers, accelerate, peft
pip install -q -U bitsandbytes
pip install -q -U git+https://github.com/huggingface/transformers.git
pip install -q -U git+https://github.com/huggingface/peft.git
pip install -q -U git+https://github.com/huggingface/accelerate.git
#这四个库的版本号应该为:
bitsandbytes 0.39.0
transformers 4.30.0.dev0
accelerate 0.20.0.dev0
peft 0.4.0.dev0
#若官方安装方法不成功可以试试手动安装:
#transformers
git clone https://github.com/huggingface/transformers.git
cd transformers
python -m pip install -e . -i https://mirror.baidu.com/pypi/simple
#bitsandbytes
git clone https://github.com/TimDettmers/bitsandbytes.git
cd bitsandbytes
# CUDA_VERSIONS in {110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 120}
# make argument in {cuda110, cuda11x, cuda12x}
# 看好自己的cuda版本, cuda11.8 对应 118和cuda11x .
CUDA_VERSION=118 make cuda11x
python setup.py install
#peft
git clone https://github.com/huggingface/peft.git
cd peft && pip install -e . -i https://mirror.baidu.com/pypi/simple
#accelerate
git clone https://github.com/huggingface/accelerate.git
cd accelerate && pip install -e . -i https://mirror.baidu.com/pypi/simple在 scripts 文件夹中有模型微调和合成脚本,可以根据自身需要进行修改参数和模型,然后一键运行即可

模型量化部分代码如下:
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path='/name/or/path/to/your/model',
load_in_4bit=True, #设置为True才可以调用BitsAndBytesConfig
device_map={"": 0}, #调用GPU,并使用accelerate加载模型
max_memory=max_memory,
torch_dtype=torch.bfloat16,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16, #计算时采用BF16最快,默认为FP32
bnb_4bit_use_double_quant=True, #二次量化
bnb_4bit_quant_type='nf4' #量化时使用nf4最优,也可以使用fp4
)
)
# 若想使用Paged Optimizer,则在qlora.py中调用 --optim paged_adamw_32bit官方也给出了 llama-7b 模型和 guanaco-7b adapter modules 的合成示例:
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
model_name = "decapoda-research/llama-7b-hf"
adapters_name = 'timdettmers/guanaco-7b'
print(f"Starting to load the model {model_name} into memory")
m = AutoModelForCausalLM.from_pretrained(
model_name,
#load_in_4bit=True,
torch_dtype=torch.bfloat16,
device_map={"": 0}
)
m = PeftModel.from_pretrained(m, adapters_name)
m = m.merge_and_unload()
tok = LlamaTokenizer.from_pretrained(model_name)
tok.bos_token_id = 1
stop_token_ids = [0]
print(f"Successfully loaded the model {model_name} into memory")QLoRA 方法在实际使用中要注意以下几点:
load_in_4bit=True 的情况下模型推理能力较慢。4bit 推理还未能与 4bit 矩阵乘法结合
bnb_4bit_compute_type='fp16' 会导致量化模型训练不稳定。
要设置 tokenizer.bos_token_id = 1

Guanaco+DB-GPT的部署
DB-GPT 是一个在数据库领域与 LLM 大模型结合的项目,核心理念是技术的绝对开放、环境的绝对私有自从 5 月 6 号发布第一个版本以来, 不到一个月就突破了 3.3k star,在半个月内数次占领 GitHub Trending 之后,又登上了 Hacker News 首页,项目仍然在不断开发中,后续我们会不断将最前沿的技术逐渐集成到项目中来,大家可以持续关注~
下面讲讲我在 DB-GPT 上是如何部署 Guanaco 33b 大模型,打造自己的知识库。
3.1 安装DB-GPT
这里有在阿里云上部署的详细教程,大家可以看看。但是阿里云的价格还是有点小贵,今天教大家怎么在 AutoDL 上部署。
首先在算力市场中选择适合我们的 GPU,这里根据我自己的需要选择 3090 显卡:

由于后续会存储各种大模型,所以我会扩容一下硬盘,注意这里系统会根据硬盘扩容大小按日收费。然后选择好要安装的基础镜像。
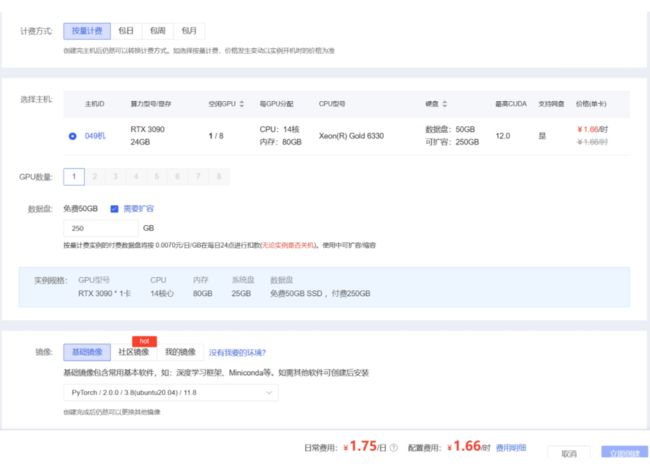
点击立即创建后进入控制台就可以看到我们创建的实例啦,然后开机进入 jupyter lab 即可。这里有个小技巧,如果仅仅是部署环境而不涉及到模型训练,我们可以使用无卡开机模式,每小时只要 0.1 元,可以说相当划算了。
进入 jupyter lab 的终端环境后,我们就可以开始配置环境了,首先我们要安装 git lfs 方便下载大模型,
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs我们所购买的扩容数据盘都是放在 auto-tmp 目录下的,所以我们要 cd 到 auto-tmp 目录下,再进行后续安装。AutoDL 内置了学术资源加速方法,可以提高 github 的访问速度,在帮助文档里有详细说明,这里我们也加载一下。
#设置学术加速
source /etc/network_turbo
cd auto-tmp
# 下载项目代码
git clone https://github.com/csunny/DB-GPT.git
# 更新bashrc中的环境变量
conda init bash && source /root/.bashrc
#构建并激活conda环境
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
#安装环境依赖,这里保险起见我加入了信任的镜像源下载
cd DB-GPT
pip install -r requirements.txt -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
#若后续使用guanaco,还需安装QLoRA的bitsandbytes,transformers,accelerate,peft,安装方法在上面
#这四个库的版本号应该为:
bitsandbytes 0.39.0
transformers 4.30.0.dev0
accelerate 0.20.0.dev0
peft 0.4.0.dev0环境安装完成后,我们要在 DB-GPT 里新建文件夹 models,然后我们把 huggingface 上下载的模型了放在这个目录里面即可
#若想体验完整的DB-GPT项目,建议也下载vicuna-13b和all-MiniLM-L6-v2
git clone https://huggingface.co/Tribbiani/vicuna-13b
git clone https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
#guanaco-33b-merged是量化后可以直接使用的33b模型,如需使用其他量化模型,可自行选择合成或下载
git clone https://huggingface.co/timdettmers/guanaco-33b-merged模型文件很大,下载时间会比较长。在这期间,我们先来配置一下 .env 文件,.env 文件需要从 .env.template 复制创建,我们需要将模型名称修改为要使用的 guanaco-33b-merged,即 LLM_MODEL=guanaco-33b-merged,
由于我们的项目因为要直接连接数据库,这里我们以 MySQL 作为样例,安装 mysql。
# 首先更新apt源
sudo apt update
#下载mysql-server
sudo apt install mysql-server
#查看mysql的状态,开启mysql
sudo service mysql status
sudo service mysql start
#进入mysql终端
sudo mysql
#设置root密码,注意这里的密码应该和DB-GPT中的.env文件保持一致
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'aa12345678';
#登录mysql,这里会提示输入密码,可以查看自己密码创建是否正确
mysql -u root -p模型下载好以后,我们需要切换到 DB-GPT 最新的 dev 分支,Guanaco 33b 这个模型可以跑起来了,但目前还不是流式,后续我们会持续处理一下
#切换分支
git checkout dev
#更新分支
git pull origin dev
# 运行命令启动服务端:
python pilot/server/llmserver.py在这里我们的前后端均放在 AutoDL 上,因此我们再开一个新的终端
cd autodl-tmp/DB-GPT
conda activate dbgpt_env
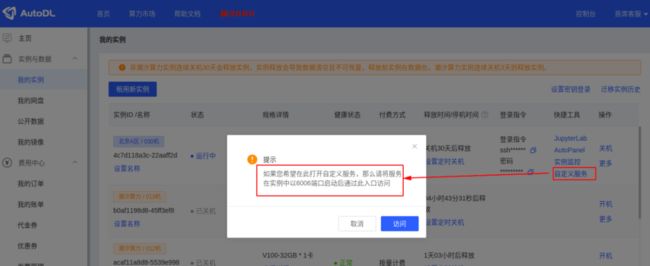
#由于AutoDL的实例无独立公网IP,因此不能任意开启额外的端口。但是AutoDL为每个实例都预留了一个可对外暴露的端口,技术实现为将实例中的6006端口映射到公网可供访问的ip:port上,而ip:port可在「自定义服务」入口获取,这里我们使用6006开启客户端
python pilot/server/webserver.py --port 6006然后我们访问自定义服务便可以开启我们的 DB-GPT 啦
3.2 Guanaco相关
模型的加载代码如下:
class GuanacoAdapter(BaseLLMAdaper):
"""TODO Support guanaco"""
def match(self, model_path: str):
return "guanaco" in model_path
def loader(self, model_path: str, from_pretrained_kwargs: dict):
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path, load_in_4bit=True, device_map={"": 0}, **from_pretrained_kwargs
)
return model, tokenizer模型的生成代码如下:
import torch
import copy
from threading import Thread
from transformers import TextIteratorStreamer, StoppingCriteriaList, StoppingCriteria
def guanaco_generate_output(model, tokenizer, params, device, context_len=2048):
print(params)
stop = params.get("stop", "###")
prompt = params["prompt"]
query = prompt
print("Query Message: ", query)
input_ids = tokenizer(query, return_tensors="pt").input_ids
input_ids = input_ids.to(model.device)
streamer = TextIteratorStreamer(
tokenizer, timeout=10.0, skip_prompt=True, skip_special_tokens=True
)
stop_token_ids = [0]
class StopOnTokens(StoppingCriteria):
def __call__(
self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs
) -> bool:
for stop_id in stop_token_ids:
if input_ids[0][-1] == stop_id:
return True
return False
stop = StopOnTokens()
generate_kwargs = dict(
input_ids=input_ids,
max_new_tokens=512,
temperature=1.0,
do_sample=True,
top_k=1,
streamer=streamer,
repetition_penalty=1.7,
stopping_criteria=StoppingCriteriaList([stop]),
)
t1 = Thread(target=model.generate, kwargs=generate_kwargs)
t1.start()
generator = model.generate(**generate_kwargs)
for output in generator:
# new_tokens = len(output) - len(input_ids[0])
decoded_output = tokenizer.decode(output)
if output[-1] in [tokenizer.eos_token_id]:
break
out = decoded_output.split("### Response:")[-1].strip()
yield out
参考文献
[1] A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using transformers, accelerate and bitsandbytes (huggingface.co)https://huggingface.co/blog/hf-bitsandbytes-integration
[2] LLM.int8()——在大模型上使用int8量化 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/586406082
[3] QLoRA: 训练更大的GPT - 飞书云文档 (feishu.cn)https://readpaper.feishu.cn/docx/CrMGdSVPKow5d1x1XQMcJioRnQe
[4] QLoRA的实测记录 - 知乎 (zhihu.com)https://zhuanlan.zhihu.com/p/632398047
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
