【多线程相关其三】多线程使用
1.为什么要使用多线程?
线程在程序中是独立的、并发的执行流。与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存、文件句柄
和其他进程应有的状态。
因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程之中拥有独立的内存单元,而多个线程共享
内存,从而极大的提升了程序的运行效率。
线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性,多个线程共享一个进程的虚拟空间。线程的共享环境
包括进程代码段、进程的共有数据等,利用这些共享的数据,线程之间很容易实现通信。
操作系统在创建进程时,必须为改进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程
来实现并发比使用多进程的性能高得要多。
总结起来,使用多线程编程具有如下几个优点:
进程之间不能共享内存,但线程之间共享内存非常容易。
操作系统在创建进程时,需要为该进程重新分配系统资源,但创建线程的代价则小得多。因此使用多线程来实现多任务并发执行比使用多进程的效率高
python语言内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了python的多线程编程。
2.如何创建一个多线程?
Python处理线程的模块有两个:thread和threading。Python 3已经停用了thread模块,并改名为_thread模块。Python 3在_thread模块的基础上开发了更高级的threading模块,因此以下的讲解都是基于threading模块。
根据threading底层代码的说明,创建一个线程通常有两种方法:
(1)在实例化一个线程对象时,将要执行的任务函数以参数的形式传入;
(2)继承Thread类的同时重写它的run方法。

总结起来,使用多线程编程具有如下几个优点:
进程之间不能共享内存,但线程之间共享内存非常容易。
操作系统在创建进程时,需要为该进程重新分配系统资源,但创建线程的代价则小得多。因此使用多线程来实现多任务并发执行比使用多进程的效率高
python语言内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了python的多线程编程。
现在我准备创建两个线程,一个线程每隔一秒打印一个“1”,另一个线程每隔2秒打印一个“2”,如何创建并执行呢?两种方法如下:
2.1
import time
import threading
def printNumber(n: int) -> None:
while True:
print(n)
time.sleep(n)
for i in range(1, 3):
t = threading.Thread(target=printNumber, args=(i, ))
t.start()
运行结果如下,控制台会不停地、交错地打印“1”和“2”:

2.2
import time
import threading
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
# 注意:一定要调用父类的初始化函数,否则否发创建线程
super().__init__()
def run(self) -> None:
while True:
print(self.n)
time.sleep(self.n)
for i in range(1, 3):
t = MyThread(i)
t.start()
运行结果如下,控制台会不停地、交错地打印“1”和“2”:

3.主线程和子线程
我们先把上述的代码简单做一下修改,让它在打印的同时打印活跃的线程个数,代码如下
import time
import threading
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
while True:
_count = threading.active_count()
print(self.n, f"当前活跃的线程个数:{_count}")
time.sleep(self.n)
for i in range(1, 3):
t = MyThread(i)
t.start()

好那么问题来了:当我创建了线程1并开始执行的时候,程序却告诉我有2个活跃的线程呢?同样地,我最终只创建了2个线程,为什么程序却告诉我有3个活跃的线程呢?
让我们回到进程和线程的定义,当我们开始执行这个程序的时候,这个程序成为一个“有生命的”进程,进程至少有一个线程,这个线程就是主线程。当程序执行到第一次t.start()的时候,程序创建了一个子线程,此时活跃的线程个数是2。进一步,当执行第二次t.start()的时候,程序又创建了一个子线程,因此最终活跃的线程个数是3。
注意每个进程只有一个主线程。
- 守护线程(Daemon Thread)
守护线程(Daemon Thread)也叫后台进程,它的目的是为其他线程提供服务。如果其他线程被杀死了,那么守护线程也就没有了存在的必要。因此守护线程会随着非守护线程的消亡而消亡。Thread类中,子线程被创建时默认是非守护线程,我们可以通过setDaemon(True)将一个子线程设置为守护线程。
我们把上面这个例子中创建的两个子线程改写为守护线程,看看会发生什么:
import threading
import time
class MyThread(threading.Thread):
"""
守护线程(Daemon Thread)
"""
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
while True:
_count = threading.active_count()
print(self.n, f"当前活跃的线程个数:{_count}")
time.sleep(self.n)
for i in range(1, 3):
t = MyThread(i)
t.daemon = True
t.start()
print("结束!")
运行结果如下:
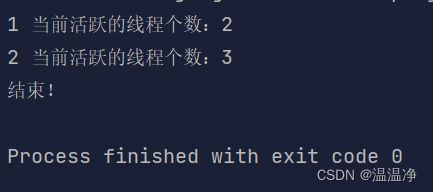
和前面不同,程序打印完“结束!”彻底结束了
和前面完全不同的是:程序打印完“结束!”后就彻底结束了,不再打印任何内容。这是为什么呢?
因为当程序执行完print(“结束!”)以后,主线程就可以结束了,这时候被设定为守护线程的两个子线程会被杀死,然后主线程结束。
现在,如果我把两个子线程的其中一个设置为守护线程,另一个设置为非守护线程,会怎样呢?代码如下:
import time
import threading
class MyThread(threading.Thread):
"""
将其中一个线程设置为守护线程
"""
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
while True:
_count = threading.active_count()
print(self.n, f"当前活跃的线程个数:{_count}")
time.sleep(self.n)
for i in range(1, 3):
t = MyThread(i)
if i == 1:
t.daemon = True # 将其中一个线程设置为守护线程
t.start()
print("结束!")

你可能会想,守护线程会被杀死,非守护线程继续执行。但实际情况并非如此,结果如下:
两个子线程都在继续执行
这是因为非守护线程作为前台程序还在继续执行,守护线程就还有“守护”的意义,就会继续执行。
需要注意的是:将子线程设置为守护线程必须在调用start()方法之前,否则回引发RuntimeError异常
- join()方法
join()会使主线程进入等待状态(阻塞),直到调用join()方法的子线程运行结束。同时你也可以通过设置timeout参数来设定等待的时间,如:
import time
import threading
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
while True:
_count = threading.active_count()
print(f"线程-{self.n}", f"当前活跃的线程个数:{_count}")
time.sleep(self.n)
for i in range(1, 3):
t = MyThread(i)
t.start()
t.join(3)
执行结果如下:

- 数据安全与线程锁
现在假设你创建了100子线程操作同一个全局变量number,number被初始化为100,所有子线程都对这个number进行-1,子线程同时进行。如果一切正常的话,最终这个number会变成0,然而现实并非如此。代码如下
import time
import threading
number = 100
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
global number
tmp = number
time.sleep(1)
number = tmp - 1
# 等子线程运行完,再打印number
t_list = []
for i in range(100):
t = MyThread(i)
t.start()
t_list.append(t)
# 主进程等100个线程结束以后,再打印number,确保子进程都对number进行了操作
for t in t_list:
t.join()
# 确保子线程执行完毕
print("活跃的线程个数:", threading.active_count())
# 输出最终数值
print("number: ", number)
执行结果如下:

结果并不是0
这种情况称为“脏数据”。产生脏数据的原因是,当一个线程在对数据进行修改时,修改到一半时另一个线程读取了未经修改的数据并进行修改。
如何避免脏数据的产生呢?一个办法就是用join方法,即先让一个线程执行完毕再执行另一个线程。但这样的本质是把多线程变成了单线程,失去了多线程的意义。另一个办法就是用线程锁,threading模块中有如下几种线程锁:
6.1 Lock互斥锁
import time
import threading
number = 100
lock = threading.Lock() # 实例化一个锁
class MyThread(threading.Thread):
"""
lock:互斥锁
"""
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
global number
lock.acquire() # 上锁,只允许当前线程访问共享的数据
tmp = number
time.sleep(0.1)
number = tmp - 1
lock.release() # 释放锁,允许其他线程访问共享数据
t_list = []
for i in range(100):
t = MyThread(i)
t.start()
t_list.append(t)
for t in t_list:
t.join()
# 确保子线程执行完毕
print("活跃的线程个数:", threading.active_count())
# 输出最终数值
print("number: ", number)
执行结果如下:

输出正常
6.2 Semaphore
BoundedSemaphore类可以设置同一时间更改数据的线程个数
import time
import threading
semaphore = threading.BoundedSemaphore(3)
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
semaphore.acquire()
for i in range(100):
_count = threading.active_count() - 1
print(f"线程-{self.n}", f"当前活跃的子线程个数:{_count}")
time.sleep(1)
semaphore.release()
for i in range(1, 10):
t = MyThread(i)
t.start()
执行结果如下:
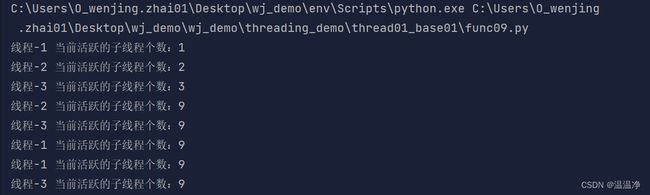
Semaphore设置了同时执行的线程的个数
可以看出:虽然活跃的子线程个数有9个,但其实真正执行的子线程个数只有3个
6.3 Event
Event类会在全局定义一个Flag,当Flag=False时,调用wait()方法会阻塞所有线程;而当Flag=True时,调用wait()方法不再阻塞。形象的比喻就是“红绿灯”:在红灯时阻塞所有线程,而在绿灯时又会一次性放行所有排队中的线程。Event类有四个方法:
set():将Flag设置为True
wait():等待
clear():将Flag设置为False
is_set():返回bool值,判断Flag是否为True
Event的一个好处是:可以实现线程间通信,通过一个线程去控制另一个线程。
import time
import threading
event = threading.Event()
event.set() # 设定Flag = True
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
if self.n in [3, 4]:
event.clear() # 设定Flag = False
event.wait() # 线程3和4进入等待
for i in range(2):
_count = threading.active_count() - 1
print(f"线程-{self.n}", f"当前活跃的子线程个数:{_count}")
time.sleep(2)
if self.n == 2 and i == 1:
# 通过线程2来控制线程3和4
event.set()
for i in range(1, 5):
t = MyThread(i)
t.start()
执行结果如下:

通过一个线程去控制另一个线程
- 一些小技巧
7.1 with上下门管理器
在使用Lock和RLock时,正确的开锁-释放锁非常重要。通过with上下文管理器,可以保证线程锁被正确释放,而且代码也更加简洁。如:
import time
import threading
number = 100
lock = threading.Lock() # 实例化一个锁
class MyThread(threading.Thread):
"""
lock:互斥锁
获取数据之前加上一把锁,保证同一时刻只有一个线程去操作数据
相当于100个人去抢一个公共厕所,第一个抢到厕所的人,把厕所的门锁起来,这样后面的人就无法在同一时刻去用厕所
相当于由并发变成了串行,牺牲了效率,保证的数据的安全
"""
def __init__(self, n):
self.n = n
super().__init__()
def run(self) -> None:
global number
with lock:
tmp = number
# 模拟网络延迟
time.sleep(0.1)
number = tmp - 1
print(number)
t_list = []
for i in range(100):
t = MyThread(i)
t.start()
t_list.append(t)
for t in t_list:
t.join()
# 确保子线程执行完毕
print("活跃的线程个数:", threading.active_count())
# 输出最终数值
print("number: ", number)
7.2 Timer计时器
通过threading.Timer类可以实现n秒后执行某操作。注意一个timer对象相当于一个新的子线程。
import time
import threading
class MyThread(threading.Thread):
def __init__(self, n):
self.n = n
# 注意:一定要调用父类的初始化函数,否则不会创建线程
super().__init__()
def run(self) -> None:
while True:
print(self.n)
time.sleep(self.n)
print('============================')
for i in range(1, 5):
t = MyThread(i)
if i == 4:
timer = threading.Timer(5, t.start) # 5秒后再开始线程4
timer.start()
else:
t.start()