JavaEE--Java Web基础知识
目录
前言
Java Web基础知识
Servlet
***:Servlet发展之路
***:Tomcat各版本与jdk、servlet版本对应关系
request
***:ServletContext和RequestDispatcher是什么?
response
***:转发和重定向的区别
***:重定向时的资源路径如何设定?
***:服务中的页面资源、图片资源等如何定位?
***:如何定位web项目中各级目录下的资源?
Filter
***:升级自定义的Servlet容器,增加Filter功能
***:Filter的链式处理顺序以及拦截方式配置
Listener
***:升级自定义的Servlet容器,增加ServletContext的创建、销毁Listener
Session
Tomcat乱码问题(三种常见的中文乱码分析以及解决措施)
BS架构的文件下载(适配多种浏览器)
前言
带着问题学java系列博文之java基础篇。从问题出发,学习java知识。
Java Web基础知识
上篇博文(《JavaEE--从文件上传、下载入门Java web》),我们入门了Java web,也自己尝试实现了自定义Servlet和Servlet容器。毫无疑问,还是Servlet+容器的实现方案最适合Java web后台服务开发。所以我们也老老实实学习这个最优方案,当然我们也没必要自己去实现容器和Servlet了,可以直接使用前辈们的封装成果,用来开发我们自己的后台服务。本篇将类比上篇博文的自定义Servlet容器,梳理、理解Java web体系知识。
Servlet
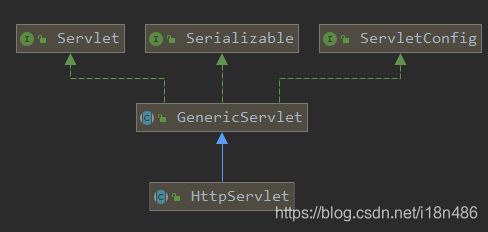
Servlet是一个顶级接口,Tomcat等所有的Servlet容器都是默认支持该接口(这也是为什么把Tomcat等叫做Servlet容器的原因)。类比我们自定义的容器,就是初始化时的反射创建Servlet实例的类型强转,我们自定义的容器是对应我们自定义的MyServlet,所以其实我们自定义的容器应该叫做MyServlet容器。
![]()
Servlet定义了一系列的抽象方法,分别对应着Servlet的生命周期各个阶段:
init(ServletConfig servletConfig):初始化方法,在Servlet实例被创建时调用,仅调用一次;
getServletConfig():获取ServletConfig对象
service(ServletRequest var1, ServletResponse var2):处理请求,每次请求到达,都会执行一次;
getServletInfo():获取Servlet的一些信息;
destory():Servlet实例对象被销毁时执行一次(Servlet容器正常关闭时,会先销毁实例);
我们在上篇的博文中(servlet实现后台服务demo)直接实现该接口,编写自己的业务代码,发现其实真正需要关注的方法只有一个service(),其他的都没有用到。显然java大佬们也意识到了,所以有了后面两个抽象类GenericServlet和HttpServlet,implements Servlet顶级接口,实现接口的部分抽象方法,让我们开发的时候更加简单。其中GenericServlet抽象类对Servlet的抽象方法除了service()之外,都进行了默认实现;而HttpServlet则是继承了GenericServlet父类,覆写了父类的所有方法,包括service()抽象方法,然后还根据请求的方式增加了具体的处理方法,比如doGet(),doPost()。因此,建议开发时直接继承HttpServlet抽象类,可以更加简化后台开发。
***:Servlet发展之路
-
Servlet1.0:1997年,概念,未输出具体sdk;
-
Servlet2.0:jdk1.1中包含;
-
Servlet2.2:引入了 self-contained Web applications 的概念
-
Servlet2.3:增加了filters和filters chains
-
Servlet2.4:没有突出的新功能,增了一些优化
-
Servlet2.5:开始支持部分注解
-
Servlet3.0:随着Java EE 6一起发布,作为Java EE6 体系的一员;支持全注解
-
Servlet4.0:随着Java EE8一起发布,作为Java EE8的核心更新;新增功能:流优先级,请求复用,服务端推送等
***:Tomcat各版本与jdk、servlet版本对应关系
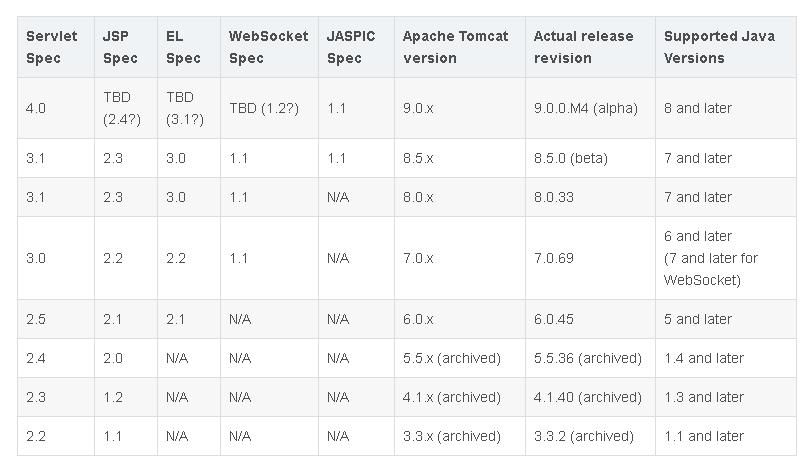
Servlet3.0开始支持全注解;Servlet3.1开始支持NIO;所以现在一般都是使用Tomcat8以上版本。
request
类比我们上篇自定义的Servlet容器,我们知道Request其实就是封装了socket.getInputStream获得的输入流,它的实例化是由容器在处理请求时执行的。我们自定义的容器实例化的是我们自定义的MyServletRequest类,Tomcat容器实例化的是它自定义的类org.apache.catalina.connector.RequestFacde。ServletRequest和HttpServletRequest两个接口,是为了规范request类,定义好Request类需要实现的方法等,Tomcat容器自定义类RequestFacde就是实现了HttpServletRequest接口。
回顾我们自定义的MyServletRequest类,可以发现其实Request最主要功能的就是通过socket的inputstream,读取浏览器发送过来的信息字串,然后解析它,并做好方法封装。比如:获取请求方式 getMethod(),获取请求参数(servletrequest接口定义的规范和我们自定义类MyServletRequest的实现一样的,都是通过一个map保存参数) getParameter(name)和getParameterMap();获取请求路径 getRequestURI();设置编码格式setCharacterEncoding()(这个具体实现其实就是MyServletRequest类中的URL解码,为了解决请求参数中含有中文乱码问题);
另外就是一些特殊的信息集合,比如一次请求可以暂存一些信息,同一次请求间共享;cookie和session,以及代表整个后台服务的服务上下文ServletContext。
按照上面分析,我们对上篇博文的MyServletReuqest进行规范化实现:
public class MyServletRequestFormat implements HttpServletRequest {
// 编码格式
private String encode = "";
// 请求方式
private String method;
// 请求URL
private String uri;
// 请求参数map
private Map paramMap = new HashMap();
// 一次请求范围信息容器
private Map attributeMap = new ConcurrentHashMap();
// socket的输入流
private InputStream inputStream;
// todo ServletContext由容器创建之后传递过来(其实就是一个实体类,包含了一系列信息集)
public MyServletRequestFormat(InputStream inputStream) {
this.inputStream = inputStream;
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
try {
String line = bufferedReader.readLine();
if (null != line && line.length() > 0) {
String[] split = line.split(" ");
//解析请求字串
if (split.length == 3) {
//获取请求方法
this.method = split[0];
String allUrl = split[1];
if (allUrl.contains("?")) {
//获取请求uri
this.uri = allUrl.substring(0, allUrl.indexOf("?"));
String params = allUrl.substring(allUrl.indexOf("?") + 1);
String[] paramArray = params.split("&");
for (String param : paramArray) {
String[] paramValue = param.split("=");
if (paramValue.length == 2) {
//存储请求参数
paramMap.put(paramValue[0], paramValue[1]);
}
}
} else {
this.uri = allUrl;
}
if (allUrl.endsWith("ico")) {
return;
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public String getMethod() {
return method;
}
public String getRequestURI() {
return uri;
}
public Object getAttribute(String s) {
return attributeMap.get(s);
}
public String getCharacterEncoding() {
return encode;
}
public void setCharacterEncoding(String s) throws UnsupportedEncodingException {
if (s.equalsIgnoreCase("utf-8") || s.equalsIgnoreCase("gbk")
|| s.equalsIgnoreCase("iso8859-1") || s.equalsIgnoreCase("gbk2312")) {
encode = s;
} else {
throw new UnsupportedEncodingException();
}
}
public ServletInputStream getInputStream() throws IOException {
return (ServletInputStream) inputStream;
}
public String getParameter(String s) {
return paramMap.get(s);
}
public void setAttribute(String s, Object o) {
attributeMap.put(s,o);
}
public void removeAttribute(String s) {
attributeMap.remove(s);
}
//省略其它方法
} 如上代码,我们对一些方法进行了简单实现,其实无非都是对inputstream读取到的字串信息进行解析、封装,然后通过方法对外暴露。需要注意的我们没有实现两个特殊对象:ServletContext和RequestDispatcher,这两个对象也是由容器实现的。
***:ServletContext和RequestDispatcher是什么?
ServletContext代表整个web应用,可以和整个容器通讯,它保存的对象可以被所有请求共享,它和整个web应用同生命周期。虽然我们没有实现这个对象,但是我们可以肯定的预见,Tomcat一定是在程序入口类中进行创建的(类比我们的MyTomcat类,在MyTomcat中init()创建ServletContext对象实例,然后使用map来作为对象容器等)。
RequestDispatcher对象是用来做请求转发的,也是由Tomcat创建对象实例,从request.getRequestDispatcher(uri)可以看到,它要传入一个uri参数;而我们自定义实现MyTomcat中有个核心逻辑:init()方法读取web.xml,完成反射创建MyServlet实例以及与uri映射对应。所以我们可以肯定的预见,这个requestDispather对象其实就是从MyTomcat的servletMapping中通过uri获取具体的servlet,然后执行servlet的服务方法。它的转发方法forword(req,res)的伪代码应该是:
void forword(ServletRequest req,ServletResponse res){
servlet.service(req,res);
}可以看到,转发其实就是后台服务根据转发uri,找到对应的servlet实例,然后执行servlet的服务方法,并且整个过程都是使用同一个request和response对象(也就是还是使用同一个socket来进行数据读写)。整个转发过程对于浏览器前端来说,都是不可感知的,浏览器还是认为仅发起了一个请求,然后服务端给出响应。
response
和request一样,类比我们上篇自定义的Servlet容器,我们知道response其实就是封装了socket.getOutputStream获得的输出流,它的实例化是由容器在处理请求时执行的。我们自定义的容器实例化的是我们自定义的MyServletResponse类,Tomcat容器实例化的是它自定义的类org.apache.catalina.connector.ResponseFacde。ServletResponse和HttpServletResponset两个接口,是为了规范response类,定义好response类需要实现的方法等,Tomcat容器自定义类ResponseFacde就是实现了HttpServletReponse接口。
回顾我们自定义的MyServletResponse类,首先使用了BufferWriter缓存流包装了outputStream字节流,便于写回响应信息;然后固定写回了一个特殊的头信息,为了适配浏览器的规范;其他方法就没有过多实现(其实无非就是使用writer写回特殊的信息)。为了规范response类,所以制定了HttpServletResponse接口,要求实现类必须实现其中的方法。我们也模仿Tomcat等容器进行标准实现response类,范例如下:
public class MyServletResponseFormat implements HttpServletResponse {
private OutputStream outputStream;
private PrintWriter writer;
// 添加Response响应头
public static final String RESPONSE_HEADER=
"HTTP/1.1 200 \r\n"
+ "Content-Type: text/html;charset=utf-8\r\n"
+ "\r\n";
public MyServletResponseFormat(OutputStream outputStream) {
this.outputStream = outputStream;
this.writer = new PrintWriter(new OutputStreamWriter(outputStream));
//为了符合浏览器规范,写入特殊头信息
writer.write(RESPONSE_HEADER);
}
public ServletOutputStream getOutputStream() throws IOException {
return (ServletOutputStream) outputStream;
}
public PrintWriter getWriter() throws IOException {
return writer;
}
public void setContentType(String s) {
writer.write("Content-Type: "+s);
}
public void setHeader(String s, String s1) {
//todo 覆盖头信息中的参数
}
public void addHeader(String s, String s1) {
writer.write(s+":"+s1);
}
//省略其它方法
}如上代码,对上篇博文的MyServletResponse类进行了规范化实现,主要逻辑有:封装outputStream,用PrintWriter(接口规定的,上篇博文我们使用的是BufferWriter;用打印流好处是,不用每次手动添加换行字符)包装字节输出流,便于写操作;写入固定的头信息,适配浏览器规范;其它方法主要是使用writer写入特殊的信息,简化我们的编程。
response中有个特别的方法提出来讲一下:sendRedirect(),用例如下:
response.sendRedirect(request.getContextPath()+"/hello.html");这行代码的作用是,让浏览器重新发起一个请求,请求uri是:request.getContextPath()+"/hello.html",专业术语叫重定向。那response.sendRedirect做了啥,为什么浏览器就会重新发起一个请求呢?
追踪Tomcat的源码:
public void sendRedirect(String location)
throws IOException {
if (isCommitted())
throw new IllegalStateException
(sm.getString("coyoteResponse.sendRedirect.ise"));
// Ignore any call from an included servlet
if (included)
return;
// Clear any data content that has been buffered
resetBuffer();
// Generate a temporary redirect to the specified location
try {
String absolute = toAbsolute(location);
setStatus(SC_FOUND);
setHeader("Location", absolute);
} catch (IllegalArgumentException e) {
setStatus(SC_NOT_FOUND);
}
// Cause the response to be finished (from the application perspective)
setSuspended(true);
}
可以看到,其实也不复杂,就是使用writer,向浏览器写回了一些特殊的信息,比如写回一个状态码SC_FOUND(302),写回一个特殊的头信息:Location:资源绝对路径。然后浏览器接收了服务端响应,就会解析,发现原来需要重定向,所以就再发起一次请求(请求uri就是服务端响应信息里面的资源绝对路径)。
重定向完整流程是:浏览器发起请求,服务端处理之后,响应一个特殊的信息(状态码:status=302;header:Locatioin=资源路径),浏览器收到响应信息后,拿到请求uri,重新发起一次请求。整个过程需要服务端和浏览器配合实现,服务端需要按照浏览器规范写回特定的响应信息;浏览器需要按照规范解析响应信息,重新发起请求。
***:转发和重定向的区别
经过上面request和response的详细分析,理解了转发和重定向的本质,它们之间的区别就很好列举了:
-
转发始终是一次请求,浏览器的地址栏始终没有变化;
-
重定向是两次请求,浏览器重新发起一次请求,第二次请求的uri来自服务端的响应数据;
-
转发只能访问当前后台服务的资源,不能访问外部资源(其他后台服务);
-
重定向可以访问外部资源;
-
转发可以通过request对象共享数据,重定向不可以。
分析:转发的本质就是后台服务根据uri找到具体的servlet实例对象,然后执行它的service方法,所以只能访问当前服务的内部资源;整个过程始终使用同一个request对象,所以可以通过request对象实现数据共享。
重定向的本质是后台响应一个特殊的信息,浏览器拿到响应体后,得到uri重新发起一个请求,所以浏览器地址栏有变化(变成uri了),也可以访问外部资源(uri是其他服务的资源路径);由于不是同一次请求,两次请求的request对象都不是同一个,所以也无法通过request对象实现数据共享。
***:重定向时的资源路径如何设定?
response.sendRedirect(request.getContextPath()+"/responseDemo2");从上面的实际用例可以看到,有一个request.getContextPath()作为整个重定向uri的前缀。那这个ContextPath是什么呢?为什么要加上这个ContextPath呢?
如果我们是直接使用Idea配置了Tomcat,然后直接run运行的,看一下我们实际设定的Tomcat Config:
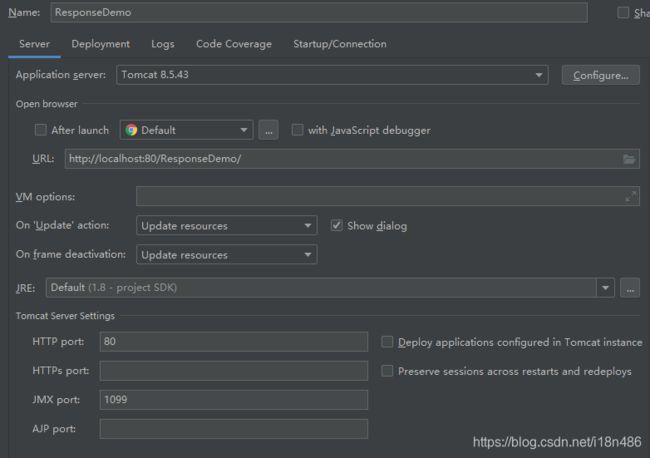
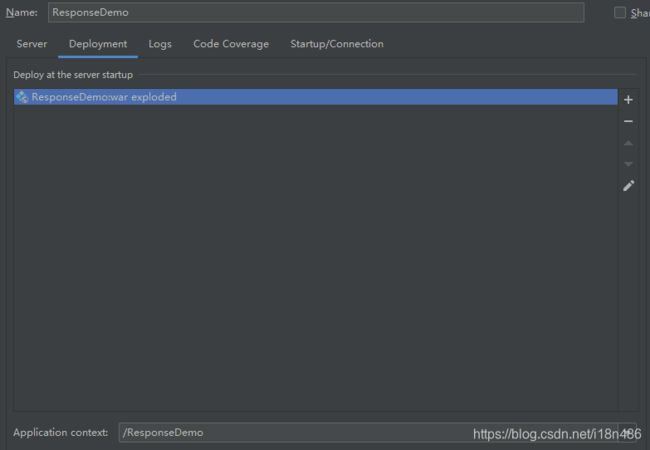
注意图片1有一个URL:http://localhost:80/ResponseDemo/ ; 图片2有个Application context: /ResponseDemo,这个“/ResponseDemo”就是ContextPath。它相当于给当前后台服务起了一个别名,所有的资源uri都是以这个为前缀,之后再对应web.xml中配置的url-pattern或者注解中的urlPatterns。所以代码范例中相当于访问当前服务的responseDemo2对应的Servlet。
***:注意,图片1和图片2的ContextPath要一致,否则将无法访问后台服务。当我们修改这个的时候,要记得两处一起修改,不要遗漏!
如果不是使用idea,而是直接将war包部署到tomcat中运行,那这个ContextPath就是war包的包名。这是因为直接使用war部署到Tomcat的话,其实Tomcat会先解压war包,生成一个同名文件夹,里面就是服务资源。所以定位服务资源就需要添加上这个文件夹父路径。
***:服务中的页面资源、图片资源等如何定位?
前面我们一直都是访问servlet,它的路径也都是通过配置设定好了,访问时根据配置的路径发起请求就好了(最多加上一个ContextPath)。那如果是访问html页面,或者图片资源呢?难道要为每一个静态资源都实现一个servlet,然后在servlet中去读取资源返回给浏览器吗(实现文件下载)?
不妨测试一下:
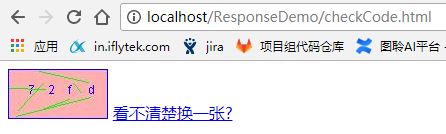
web项目运行之后(依赖Tomcat容器),直接访问html页面,浏览器是可以直接打开的。而直接访问pickage.jpg就不行,直接访问img下的图片.jpg又可以。

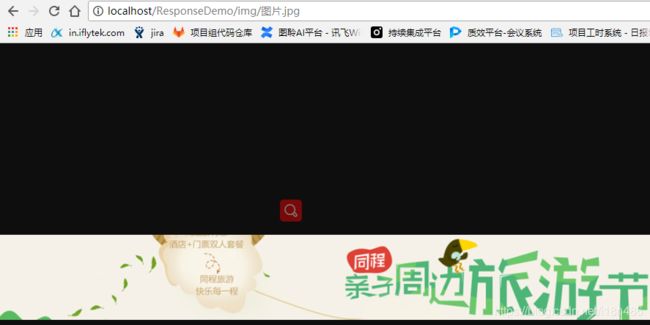
出现上述现象的原因是因为Tomcat容器为我们做了封装实现,Tomcat容器默认对所有的页面资源比如html、jsp都进行了servlet转化,相当于一个html页面就是一个servlet。上例中checkCode.Html就相当于一个urlPattern是“checkCode.html”的Servlet,这个servlet的service方法实现了读取checkCode.html文件写回给浏览器(文件下载逻辑)。同样的Tomcat对img文件夹下的图片资源也做了类似的servlet转化,当访问img下的图片资源时,相当于下载图片。
如果我们是直接使用骨架创建的web项目,那idea会默认为我们创建webapp文件夹(我们上例是自己手动创建的web文件夹,也是可以的)。为规范war包结构,对src\main\webapp目录做如下约定:
| 目录 |
存放内容 |
| css |
存放.css格式文件(可再分目录) |
| skins |
存放皮肤文件(按主题划分的framework的位图) |
| images(可以是img) |
存放图片,按产品、功能模块划分子目录 |
| js |
JavaScript文件(对象、函数库) |
| include |
存放被包含的JS文件片段【注:JSP文件互相不要包含,通过模板/组件/标签库/BEAN实现重用】 |
| resources |
存放JSF组件、相关资源等 |
| templates |
模板文件存放地,按类别划分子目录 |
| pages |
网页目录(静态和动态网页,除index.jsp),按产品、功能模块划分子目录 |
| webapp下其他目录 |
解释为模块名,认为其中全部为网页,可再分子目录 |
| META-INF |
存放清单文件、services等配置信息 |
| WEB-INF |
网站配置文件目录,存放WEB.XML等配置信息 |
| WEB-INF/classes |
未打包的项目编译代码,禁止手工修改。 |
| WEB-INF/conf |
存放struts,spring,hibernate,JSF等的配置文件 |
| WEB-INF/lib |
存放第三方JAR包,使用MAVEN构建时此目录禁止手动放入文件! |
| WEB-INF/pages |
高安全性的网页目录,如登录信息维护等 |
| WEB-INF/tld |
JSP标签库定义文件存放目录 |
***:如何定位web项目中各级目录下的资源?
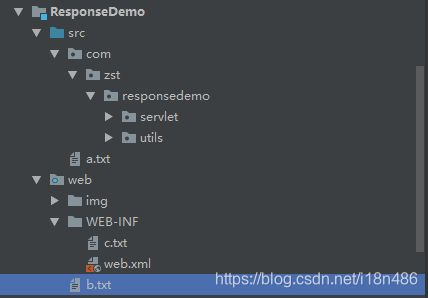
如上图,我们要读取a.txt、b.txt和c.txt三个文件,三个文件的路径应该是怎样的呢?
首先,要明白,要想读取这三个文件,必须得使用相对路径。原因很简单,因为web项目是打包成一个war,然后部署到Tomcat中再执行,绝对路径是无法确定的。所以我们主要是要弄清楚三个文件相对于当前web项目的相对路径,这样在web项目运行过程中才可以读取文件,而不会因为部署路径不同,导致文件读取失败。为了弄清楚,我们写个demo试一下:
@WebServlet("/servletContextDemo")
public class ServletContextDemo extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获取ServletContext方式:两种方式
ServletContext context = request.getServletContext();
ServletContext context1 = this.getServletContext();
System.out.println(context == context1);
//mime类型
String fileName = "a.jpg";
String mimeType = context.getMimeType(fileName);
System.out.println(mimeType);
//域对象,共享数据(最大范围:所有用户的所有请求,最长的生命周期:服务器整个过程)
context.setAttribute("name","demo1");
//获取文件真实路径
String realPath = context.getRealPath("/b.txt");//web目录下文件访问
System.out.println(realPath);
File file = new File(realPath);
FileReader reader = new FileReader(file);
System.out.println(reader.read());
String realPath2 = context.getRealPath("/WEB-INF/c.txt");//WEB-INF目录下文件访问
System.out.println(realPath2);
String realpath3 = context.getRealPath("/WEB-INF/classes/a.txt");//src目录下文件访问
System.out.println(realpath3);
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request,response);
}
}上例通过ServletContext将相对路径转换成了绝对路径(getRealPath),这个绝对路径是当前war包解压后所处的绝对路径。
总结:
web目录下:"/"
WEB-INF下:“/WEB-INF”
src下:“/WEB-INF/classes” (src下经过编译java文件生成class字节码文件,src下的文件经过编译打包之后,都是放在/WEB-INF/classes/下)
Filter
前面梳理得知,servlet2.3就引入了filter和filter chains。Filter的概念:拦截器,定义了被tomcat等容器识别的规范,web容器会按照规范去创建它的实例,执行doFliter()等方法。
上篇博文我们已经实现了Servlet容器,也编写了两个Servlet,并成功调用。那如果现有如下场景:浏览器发起请求访问hello.html时,我们想先判断下这个请求是否是规定的用户发出的,不允许规定之外的用户访问hello.html。我们首先想到的肯定是在HtmlServlet中增加判断逻辑,判断用户是否合法,合法则执行原来的逻辑,不合法则响应非法提示。如下:
public class HtmlServlet extends MyServlet {
public void doGet(MyServletRequest request, MyServletResponse response) {
doPost(request,response);
}
public void doPost(MyServletRequest request, MyServletResponse response) {
try {
//新增逻辑,拿到user参数,判断用户是否合法
String user = request.getParameter("user");
if (user.equals("zhangsan")){
//用户合法,放行
//{原有逻辑起始
String uri = request.getUrl();
System.out.println("uri:"+uri);
String path = request.getParameter("path");
//创建文件输入流,读取文件
FileReader fr = new FileReader(path);
//读取浏览器想获取的对应路径文件,并写入socket输入流,响应浏览器
char[] data = new char[258];
int len = 0;
while ((len = fr.read(data)) != -1){
response.getWriter().write(data,0,len);
}
fr.close();
response.getWriter().close();
//}原有逻辑结束
} else {
//非法用户,禁止访问html
response.getWriter().write("非法用户,禁止访问");
response.getWriter().close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}现在需求又变化了,我们要求对HelloServlet的访问也要做用户合法认证。这时我们又需要去修改HelloServlet类,像上面一样增加判断逻辑。很显然,我们的设计不满足开闭原则,每次需求的变化都需要修改原有的servlet代码;而且还需要修改多个Servlet类。
为了解决这个问题,java前辈们设计了Filter(拦截器、过滤器),它的原理也很简单,首先设定拦截的url,对所有匹配的url请求进行拦截,先执行自己的doFilter()方法,然后再考虑是否放行(继续执行servlet的service方法)。这样的设计既满足了拦截请求的需求实现,又支持开闭原则,且不需要修改多个servlet类了。
***:升级自定义的Servlet容器,增加Filter功能
(自定义容器的完整代码详见:git仓库)
那具体是如何实现的呢?首先可以肯定也是类似Servlet一样,在web.xml中配置拦截器,所以在MyTomcat类init()读取配置文件,创建Filter实例对象,并完成与Url的映射(和servlet一样,使用一个map保存)。然后在请求到来,在SocketTask处理请求时,先判断是否有匹配的拦截器,有拦截器则先执行拦截器的拦截方法,然后再由拦截器决定是否放行(调用servlet.service())。MyTomcat容器增加Filter功能扩展如下:
//改写MyTomcat类:增加filterMapping容器;
//Filter实例URL映射map
public static final ConcurrentHashMap filterMapping = new ConcurrentHashMap();
//改写init(),增加读取filter配置,实例化filter对象
} else if ("filter-name".equals(ename1) && "filter".equals(element.getName())){
String servletName = element2.getStringValue();
Element ele2 = element.element("filter-class");
String classname = ele2.getStringValue();
List elements2 = rootElement.elements("filter-mapping");
for (int k = 0, lk=elements2.size(); k < lk; k++) {
Element element4 = elements2.get(k);
List es3 = element4.elements();
for (int op = 0, opp=es3.size(); op < opp; op++) {
if ("filter-name".equals(es3.get(op).getName())
&& servletName.equals(es3.get(op).getStringValue())) {
Element element7 = element4.element("url-pattern");
String urlPattern = element7.getStringValue();
filterMapping.put(urlPattern, (MyFilter) Class.forName(classname).newInstance());
System.out.println("==> 加载 "+ classname + ":" +urlPattern);
}
}
}
}
//增加接口类MyFilter,规范filter的实现
public interface MyFilter {
void init();
void doFilter(MyServletRequest request,MyServletResponse response,String url);
void destory();
}
//实现具体的Filter类:UserFilter,用于用户验证
public class UserFilter implements MyFilter {
public void init() { }
public void doFilter(MyServletRequest request, MyServletResponse response,String url) {
//拦截,判断用户是否合法
String user = request.getParameter("user");
if (user.equals("zhangsan")){
//合法,放行
MyTomcat.servletMapping.get(url).service(request,response);
} else {
//非法用户,拦截
try {
response.getWriter().write("用户非法,禁止访问");
response.getWriter().close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void destory() { }
}
//web.xml中配置filter
user
com.zst.filter.UserFilter
user
/*
//改写请求处理类SocketTask,增加filter逻辑
public void run() {
try {
// 封装自定义request对象
MyServletRequest request = new MyServletRequest(socket.getInputStream());
// 封装自定义response对象
MyServletResponse response = new MyServletResponse(socket.getOutputStream());
String url = request.getUrl();
//先执行filter(这里逻辑简单,仅实现了一个路径全匹配逻辑)
if (MyTomcat.filterMapping.containsKey("/*")){
// “/*”表示全路径匹配,所以不管请求url是什么,都是先执行filter
MyTomcat.filterMapping.get("/*").doFilter(request,response,url);
}
添加Filter功能之后,执行结果如下图:
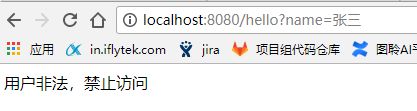
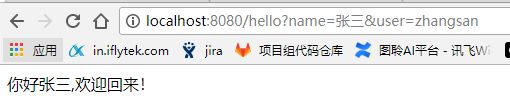


毫无疑问,Tomcat等Servlet容器都是支持Filter的,实现的主要逻辑也和我们上例类似。不过考虑的更加周全,比如路径匹配(支持多种路径匹配的过滤器)、过滤器链式处理等等。Java为了规范化Filter的具体实现,所以设计了Filter接口,我们需要用到过滤器时只需要编写一个具体的Filter类(实现Filter接口),在doFilter()方法中实现具体的业务逻辑。
***:Filter的链式处理顺序以及拦截方式配置
@WebFilter("/*")//(/*匹配所有路径)访问所有资源之前都会先执行过滤器
public class FilterDemo implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
System.out.println("filterdemo1 被执行了");
//拦截之后,考虑是否放行
//放行
filterChain.doFilter(servletRequest,servletResponse);
System.out.println("filterdemo1 又回来了");
}
@Override
public void destroy() {
}
}
//拦截路径配置
//1.资源的具体路径:/index.jsp
//2.目录拦截: /user/* user下的所有资源
//3.后缀名拦截: *.jsp 所有jsp资源
//4.拦截所有: /* 所有资源
//拦截方式配置,可以组合
//设置dispatcherTypes属性:
// REQUEST:默认值,浏览器直接请求资源
// FORWARD:转发方式访问资源
// INCLUDE:包含访问资源
// ERROR:错误跳转资源
// ASYNC:异步访问资源
//执行顺序:
//注解方式配置的filter的大小比较:根据类名比较,类名小的先执行(FilterDemo上面两个代码范例,不妨运行一下,看看运行后台打印的日志如何。可以看到先执行了FilterDemo,然后再执行FilterDemo2.
整个链路执行:先进入FilterDemo的doFilter,打印“filterdemo1 被执行了”,然后放行;再被FilterDemo2拦截,进入doFilter,打印“filterdemo2 执行了”,继续放行,请求到达具体的servlet,servlet处理完成之后,返回响应;依次返回到过滤器,先回到FilterDemo2,相当于chain.doFilter()这行执行完毕,然后继续执行后续代码,打印“filterdemo2 又回来了”;至此FilterDemo2的dofilter()方法执行完毕,回到过滤器FilterDemo,相当于FilterDemo的filterChain.doFilter()这行执行完毕,继续执行后续代码,打印“filterdemo1 又回来了”;最后浏览器接收到响应。
总结一下Filter的链式执行顺序是:
1.使用web.xml配置时,谁配置在前面,谁先执行;
2.使用注解方式配置时,谁的类名小,谁先执行(类名大小比较,就是比较类名的字串);
3.拦截器的链式执行就像方法调用,依次调用,也是依次返回(回路执行顺序与请求传递执行顺序相反)。
此外,拦截器还支持对请求的方式进行配置,区分如下
拦截方式配置,可以组合,设置dispatcherTypes属性(如FilterDemo2):
REQUEST:默认值,浏览器直接请求资源
FORWARD:转发方式访问资源
INCLUDE:包含访问资源
ERROR:错误跳转资源
ASYNC:异步访问资源
Listener
Listener监听器:主要是用来监听java web服务中常见对象(ServletContext、HttpServletRequest、HttpSession)的创建、销毁以及属性变化等。
我们自定义的Servlet容器是没有实现ServletContext的,上面也分析了ServletContext代表整个web应用,支持全局的数据共享,如果要实现它,最好的位置应该是在MyTomcat类中,那如果要实现ServletContext的创建、销毁监听Listener,只需要在MyTomcat中实现方法回调即可。
***:升级自定义的Servlet容器,增加ServletContext的创建、销毁Listener
(自定义容器的完整代码,详见git仓库)
//1.在MyTomcat中增加具体对象
//ServletContext对象
private static ServletContext servletContext;
//ServletContextListener监听器
private static ServletContextListener contextListener;
//2.在init()方法中增加读取配置,实例化监听器逻辑
} else if ("listener".equals(element.getName())){
Element ele2 = element.element("listener-class");
String className = ele2.getStringValue();
//初始化ServletContext,也实例化监听器
servletContext = new MyServletContext();
contextListener = (ServletContextListener) Class.forName(className).newInstance();
//调用servletContext创建监听回调方法
contextListener.contextInitialized(null);
}
//3.实现监听器
public class MyServletContextListener implements ServletContextListener {
public void contextInitialized(ServletContextEvent servletContextEvent) {
System.out.println("servletContext 被创建了");
}
public void contextDestroyed(ServletContextEvent servletContextEvent) {
System.out.println("servletContext 被销毁了");
}
}
//4.web.xml配置监听器
com.zst.listener.MyServletContextListener
如上范例,可以看到其实Listener监听器就是一个回调接口类,用户只需要实现具体的监听类(实现规范的ServerSocketListener接口),之后的所有逻辑(反射创建实例、回调方法调用等)都是交给容器来做。
Cookie
cookie(曲奇),它是存储在客户端浏览器的一种数据结构,servlet-api中Cookie是一个具体的java类。它的实现原理是:发起请求时,在请求头中携带cookie特殊头信息,传递给服务端;服务端增加cookie时,是在响应头中增加set-cookie特殊头信息,浏览器拿到响应体后,解析信息保存在浏览器本地。
***:Cookie的特点和作用
1.存储在客户端浏览器(安全性不高)
2.浏览器对于单个cookie的大小有限制(<4kb),以及对同一个域名下的cookie的数量有限制(<20)。
3.cookie多用于存储少量的不敏感数据
4.在不登录的情况下完成服务器对客户端的身份识别(免登录)
***:小贴士
注意,设定cookie一定要在response.write(“”)之前。也就是设定cookie一定要在response写回其他响应信息之前。原因也很简单,因为cookie是特殊的头信息,如果已经写过普通的响应信息,再继续写入cookie,此时cookie不会归属于响应头,所以无法被浏览器识别,也就设置不生效。
Session
HttpSession是一个接口,设计它是为了规范Session类的具体实现。不用怀疑,session肯定也是servlet容器进行具体实现,并创建实例对象。
原理:Session依赖于Cookie。
细节:
1.当客户端关闭,服务器不关闭,两次获取的session是否为同一个?
*默认不是同一个
*可以设置:通过添加特定cookie,来实现暂存session ID的目的
//这样做的目的是暂存session一个小时,保证浏览器关闭之后的一小时内再次访问的session仍然是同一个
Cookie cookie = new Cookie("JSESSIONID",session.getId());
cookie.setMaxAge(3600);
response.addCookie(cookie);
2.客户端不关闭,服务器关闭,两次获取的session一样吗?
*不是同一个(session是在服务器端,服务器关闭,session没有了)
*为了保证session对象丢失,保存在session中的值不丢失,可以对session钝化,持久化到硬盘上;服务器重启之后,再对session活化,读取到内存。(整个过程Tomcat自动帮我们做了)
3.session什么时候会被销毁?
*服务器关闭
*session对象调用invalidate()
*session失效(默认时长 30分钟)
特点:
1.session用于存储一次会话的多次请求的数据,存在于服务器端
2.session存储数据没有大小限制
Tomcat乱码问题(三种常见的中文乱码分析以及解决措施)
Java web项目区别传统java项目,需要依赖Tomcat等Servlet容器运行,比如我们上面的demo都是依赖本地安装的Tomcat运行的。那随之而来的就是中文乱码问题!中文为什么会乱码呢?又该如何解决乱码问题?
首先,我们的web项目是在idea中编写,然后打包成war的,idea默认设定的utf-8编码。所以在代码中通过System.out.println("打印中文,显示在控制台"),打印的就是utf-8编码的中文。注意,此时web项目是运行在Tomcat,sout输出也是向Tomcat运行后的控制台输出。而windows系统下Tomcat启动的java虚拟机默认的是GBK编码,所以这里打印出来的中文会显示为乱码。这也就是常见的中文乱码之一:虚拟机后台日志、控制台打印中文乱码。
根据上面的分析,这个问题的根本原因是因为Tomcat容器启动的虚拟机的编码和web项目的编码不是统一的,所以只需要保证编码统一即可。主要解决措施有以下两个:
1.修改Tomcat的配置文件conf/logging.properties,将其中所有的类似*.*.encoding = GBK/ISO-8859-1之类,全改为 UTF-8;
2.增加虚拟机配置:

另外一种常见的中文乱码是:浏览器发起的请求中含有中文,后台服务拿到后显示为乱码。这个问题的原因主要是Tomcat容器接收到请求时封装request用的编码不是UTF-8,后台服务读取是默认使用UTF-8(与后台编码相同)。要解决也很简单设置一下request的编码就可以了。
get方式Tomcat8.0以上版本已经做了兼容,可以直接显示
post方式仍然会显示乱码,所以需要设置流的字符编码(与页面的编码保持一致就可以)
request.setCharacterEncoding("utf-8");
还有一种常见的中文乱码是:后台服务响应信息有中文,浏览器显示中文乱码。这个问题的原因是Tomcat容器封装的response对象默认采用ISO-8859-1编码(contentType:text/html;charset=utf-8),而后台服务使用的是UTF-8编码。解决措施就是使用response设定一下ContentType。
response.setCharacterEncoding("utf-8"); 或者 response.setContentType("text/html;charset=utf-8");
BS架构的文件下载(适配多种浏览器)
上篇博文(《JavaEE--从文件上传、下载入门Java web》)我们实现了cs架构的普通文件下载,BS架构只有HTML。那如果是普通文件呢,浏览器会自动接收文件流,然后写入到本地文件吗?
当然,浏览器是具备接收文件流,并写入本地文件的功能。只不过,我们得按照它的规范,在写回文件流的时候,需要添加一些头信息,以便浏览器识别当前是文件下载,以附件形式打开。
/**
* 文件下载案例:注意文件名的规范(带_,或者中文都会有异常)
* 解决办法:采用utils中的工具类,进行编码转换
*/
@WebServlet("/fileDownloadDemo")
public class FileDownloadDemo extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获取请求参数文件名
String filename = request.getParameter("filename");
//读取文件进内存,写入到输出流
String filePath = getServletContext().getRealPath("/img/"+filename);
FileInputStream fis = new FileInputStream(filePath);
ServletOutputStream sos = response.getOutputStream();
//首先设置响应头
//1.响应头类型
response.setContentType(getServletContext().getMimeType(filename));
//2.打开方式(附件的方式,携带文件名:filename)
//首先使用工具类解决文件名问题
String agent = request.getHeader("user-agent"); //获取浏览器
String fileName = DownLoadUtils.getFileName(agent,filename); //根据浏览器不同对文件名采用对应的编码转换
response.setHeader("content-disposition","attachment;filename="+fileName);
//注意读取文件写入之前,需要设置响应头
byte[] buffer = new byte[1024*8];
int len = 0;
while ((len = fis.read(buffer)) != -1){
sos.write(buffer,0,len);
}
fis.close();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
this.doPost(request,response);
}
}
/**
* 对文件名进行重新编码
* 根据不同的浏览器采用不同的编码方式
*/
public class DownLoadUtils {
public static String getFileName(String agent,String fileName) throws UnsupportedEncodingException {
if (agent.contains("MSIE")){
//IE浏览器
fileName = URLEncoder.encode(fileName,"utf-8");
fileName = fileName.replace("+"," ");
} else if (agent.contains("Firefox")){
//火狐浏览器
fileName = "=?utf-8?B?"+new BASE64Encoder().encode(fileName.getBytes("utf-8"))+"?=";
} else {
//其他浏览器
fileName = URLEncoder.encode(fileName,"utf-8");
}
return fileName;
}
}以上系个人理解,如果存在错误,欢迎大家指正。原创不易,转载请注明出处!