经过负载均衡图片加载不出来_吐血输出:2万字长文带你细细盘点五种负载均衡策略。...
Dubbo的五种负载均衡策略
2020 年 5 月 15 日,Dubbo 发布 2.7.7 release 版本。其中有这么一个 Features

新增一个负载均衡策略。
熟悉我的老读者肯定是知道的,Dubbo 的负载均衡我都写过专门的文章,对每个负载均衡算法进行了源码的解读,还分享了自己调试过程中的一些骚操作。
新的负载均衡出来了,那必须的得解读一波。
先看一下提交记录:
https:// github.com/chickenlj/in cubator-dubbo/commit/6d2ba7ec7b5a1cb7971143d4262d0a1bfc826d45

负载均衡是基于 SPI 实现的,我们看到对应的文件中多了一个名为 shortestresponse 的 key。
这个,就是新增的负载均衡策略了。看名字,你也知道了这个策略的名称就叫:最短响应。
所以截止 2.7.7 版本,官方提供了五种负载均衡算法了,他们分别是:
- ConsistentHashLoadBalance 一致性哈希负载均衡
- LeastActiveLoadBalance 最小活跃数负载均衡
- RandomLoadBalance 加权随机负载均衡
- RoundRobinLoadBalance 加权轮询负载均衡
- ShortestResponseLoadBalance 最短响应时间负载均衡
前面四种我已经在之前的文章中进行了详细的分析。有的读者反馈说想看合辑,所以我会在这篇文章中把之前文章也整合进来。
所以,需要特别强调一下的是,这篇文章集合了之前写的三篇负载均衡的文章。看完最短响应时间负载均衡这一部分后,如果你看过我之前的那三篇文章,你可以温故而知新,也可以直接拉到文末看看我推荐的一个活动,然后点个赞再走。如果你没有看过那三篇,这篇文章如果你细看,肯定有很多收获,以后谈起负载均衡的时候若数家珍,但是肯定需要看非常非常长的时间,做好心理准备。
我已经预感到了,这篇文章妥妥的会超过 2 万字。属于硬核劝退文章,想想就害怕。

最短响应时间负载均衡
首先,我们看一下这个类上的注解,先有个整体的认知。
org.apache.dubbo.rpc.cluster.loadbalance.ShortestResponseLoadBalance

我来翻译一下是什么意思:
- 从多个服务提供者中选择出调用成功的且响应时间最短的服务提供者,由于满足这样条件的服务提供者有可能有多个。所以当选择出多个服务提供者后要根据他们的权重做分析。
- 但是如果只选择出来了一个,直接用选出来这个。
- 如果真的有多个,看它们的权重是否一样,如果不一样,则走加权随机算法的逻辑。
- 如果它们的权重是一样的,则随机调用一个。
再配个图,就好理解了,可以先不管图片中的标号:
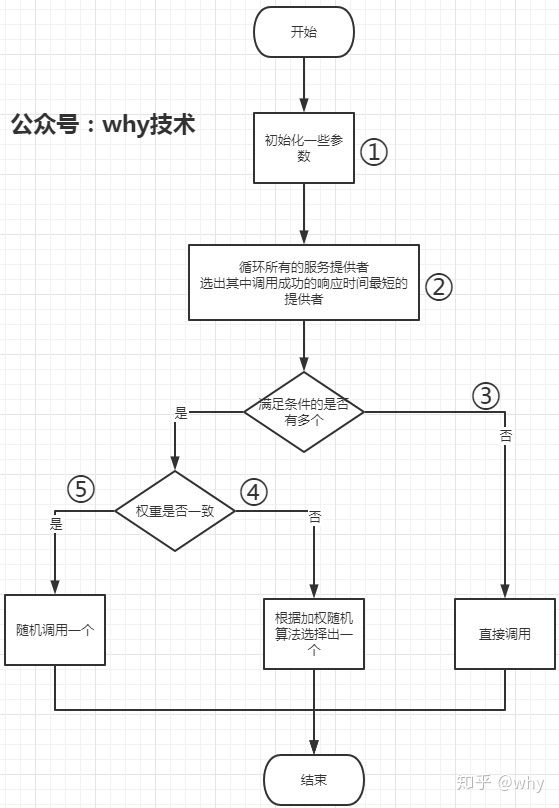
有了上面的整体概念的铺垫了,接下来分析源码的时候就简单了。
源码一共就 66 行,我把它分为 5 个片段去一一分析。

这里一到五的标号,对应上面流程图中的标号。我们一个个的说。
标号为①的部分

这一部分是定义并初始化一些参数,为接下来的代码服务的,翻译一下每个参数对应的注释:
- length 参数:服务提供者的数量。
- shortestResponse 参数:所有服务提供者的估计最短响应时间。(这个地方我觉得注释描述的不太准确,看后面的代码可以知道这只是一个零时变量,在循环中存储当前最短响应时间是多少。)
- shortCount 参数:具有相同最短响应时间的服务提供者个数,初始化为 0。
- shortestIndexes 参数:数组里面放的是具有相同最短响应时间的服务提供者的下标。
- weights 参数:每一个服务提供者的权重。
- totalWeight 参数:多个具有相同最短响应时间的服务提供者对应的预热(预热这个点还是挺重要的,在下面讲最小活跃数负载均衡的时候有详细说明)权重之和。
- firstWeight 参数:第一个具有最短响应时间的服务提供者的权重。
- sameWeight 参数:多个满足条件的提供者的权重是否一致。
标号为②的部分

这一部分代码的关键,就在上面框起来的部分。而框起来的部分,最关键的地方,就在于第一行。

获取调用成功的平均时间。
成功调用的平均时间怎么算的?
调用成功的请求数总数对应的总耗时 / 调用成功的请求数总数 = 成功调用的平均时间。
所以,在下面这个方法中,首先获取到了调用成功的请求数总数:
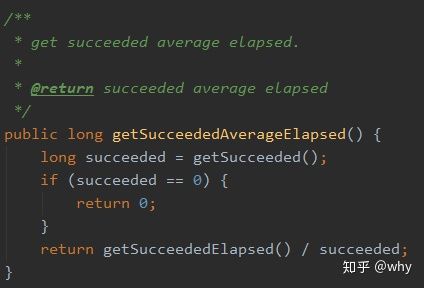
这个 succeeded 参数是怎么来的呢?

答案就是:总的请求数减去请求失败的数量,就是请求成功的总数!

那么为什么不能直接获取请求成功的总数呢?
别问,问就是没有这个选项啊。你看,在 RpcStatus 里面没有这个参数呀。

请求成功的总数我们有了,接下来成功总耗时怎么拿到的呢?

答案就是:总的请求时间减去请求失败的总时间,就是请求成功的总耗时!

那么为什么不能直接获取请求成功的总耗时呢?
别问,问就是......
我们看一下 RpcStatus 中的这几个参数是在哪里维护的:
org.apache.dubbo.rpc.RpcStatus#endCount(org.apache.dubbo.rpc.RpcStatus, long, boolean)

其中的第二个入参是本次请求调用时长,第三个入参是本次调用是否成功。
具体的方法不必细说了吧,已经显而易见了。
再回去看框起来的那三行代码:

- 第一行获取到了该服务提供者成功请求的平均耗时。
- 第二行获取的是该服务提供者的活跃数,也就是堆积的请求数。
- 第三行获取的就是如果当前这个请求发给这个服务提供者预计需要等待的时间。乘以 active 的原因是因为它需要排在堆积的请求的后面嘛。
这里,我们就获取到了如果选择当前循环中的服务提供者的预计等待时间是多长。
后面的代码怎么写?
当然是出来一个更短的就把这个踢出去呀,或者出来一个一样长时间的就记录一下,接着去 pk 权重了。
所以,接下来 shortestIndexes 参数和 weights 参数就排上用场了:

另外,多说一句的,它里面有这样的一行注释:
和 LeastActiveLoadBalance 负载均衡策略一致,我给你截图对比一下:
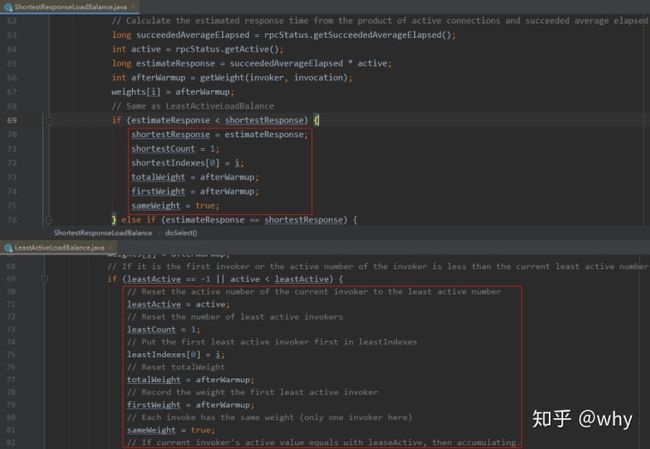
可以看到,确实是非常的相似,只是一个是判断谁的响应时间短,一个是判断谁的活跃数低。
标号为③的地方
标号为③的地方是这样的:

里面参数的含义我们都知道了,所以,标号为③的地方的含义就很好解释了:经过选择后只有一个服务提供者满足条件。所以,直接使用这个服务提供者。
标号为④的地方
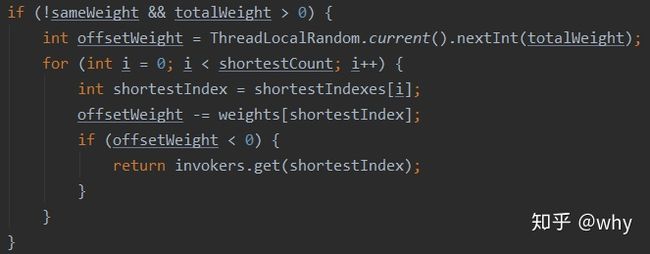
这个地方我就不展开讲了(后面的加权随机负载均衡那一小节有详细说明),熟悉的朋友一眼就看出来这是加权随机负载均衡的写法了。
不信?我给你对比一下:
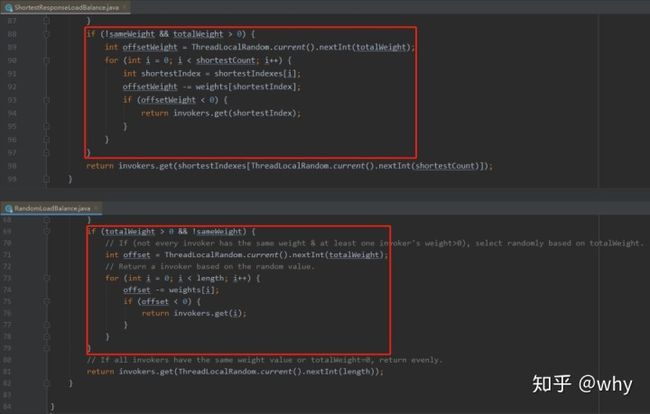
你看,是不是一模一样的。

标号为⑤的地方
一行代码,没啥说的。就是从多个满足条件的且权重一样的服务提供者中随机选择一个。
如果一定要多说一句的话,我截个图吧:

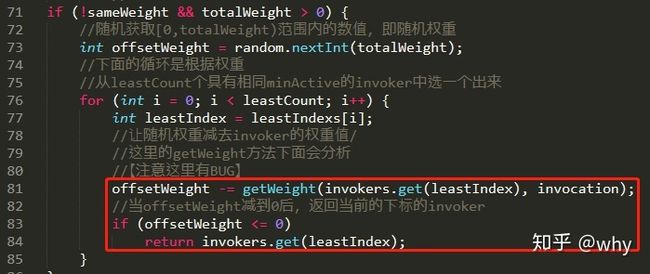
可以看到,这行代码在最短响应时间、加权随机、最小活跃数负载均衡策略中都出现了,且都在最后一行。
好了,到这里最短响应时间负载均衡策略就讲完了,你再回过头去看那张流程图,会发现其实流程非常的清晰,完全可以根据代码结构画出流程图。一个是说明这个算法是真的不复杂,另一个是说明好的代码会说话。
优雅
你知道 Dubbo 加入这个新的负载均衡算法提交了几个文件吗?
四个文件,其中还包含两个测试文件:

这里就是策略模式和 SPI 的好处。对原有的负载均衡策略没有任何侵略性。只需要按照规则扩展配置文件,实现对应接口即可。
这是什么?
这就是值得学习优雅!

那我们优雅的进入下一议题。
最小活跃数负载均衡
这一小节所示源码,没有特别标注的地方均为 2.6.0 版本。
为什么没有用截止目前(我当时写这段文章的时候是2019年12月01日)的最新的版本号 2.7.4.1 呢?因为 2.6.0 这个版本里面有两个 bug 。从 bug 讲起来,印象更加深刻。
最后会对 2.6.0/2.6.5/2.7.4.1 版本进行对比,通过对比学习,加深印象。
我这里补充一句啊,仅仅半年的时间,版本号就从 2.7.4.1 到了 2.7.7。其中还包含一个 2.7.5 这样的大版本。
所以还有人说 Dubbo 不够活跃?(几年前的文章现在还有人在发。)

对吧,我们不吵架,我们摆事实,聊数据嘛。
Demo 准备
我看源码的习惯是先搞个 Demo 把调试环境搭起来。然后带着疑问去抽丝剥茧的 Debug,不放过在这个过程中在脑海里面一闪而过的任何疑问。
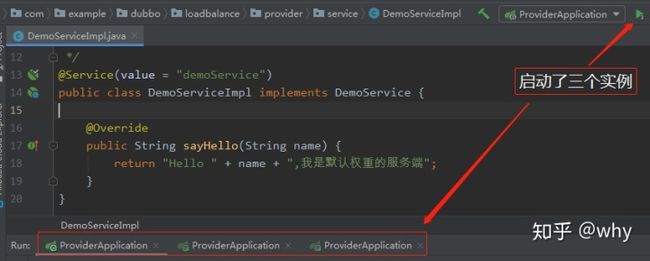
这一小节分享的是Dubbo负载均衡策略之一最小活跃数(LeastActiveLoadBalance)。所以我先搭建一个 Dubbo 的项目,并启动三个 provider 供 consumer 调用。
三个 provider 的 loadbalance 均配置的是 leastactive。权重分别是默认权重、200、300。

默认权重是多少?后面看源码的时候,源码会告诉你。
三个不同的服务提供者会给调用方返回自己是什么权重的服务。

启动三个实例。(注:上面的 provider.xml 和 DemoServiceImpl 其实只有一个,每次启动的时候手动修改端口、权重即可。)
到 zookeeper 上检查一下,服务提供者是否正常:
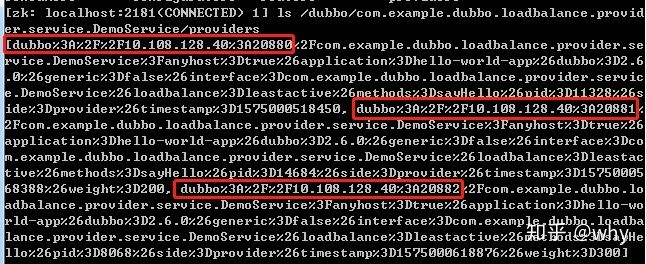
可以看到三个服务提供者分别在 20880、20881、20882 端口。(每个红框的最后5个数字就是端口号)。
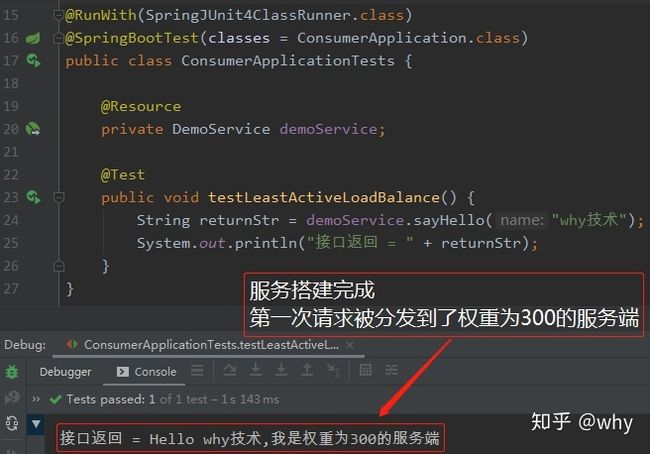
最后,我们再看服务消费者。消费者很简单,配置consumer.xml

直接调用接口并打印返回值即可。
断点打在哪?
相信很多朋友也很想看源码,但是不知道从何处下手。处于一种在源码里面"乱逛"的状态,一圈逛下来,收获并不大。
这一部分我想分享一下我是怎么去看源码。首先我会带着问题去源码里面寻找答案,即有针对性的看源码。
如果是这种框架类的,正如上面写的,我会先翻一翻官网(Dubbo 的官方文档其实写的挺好了),然后搭建一个简单的 Demo 项目,然后 Debug 跟进去看。Debug 的时候当然需要是设置断点的,那么这个断点如何设置呢?
第一个断点,当然毋庸置疑,是打在调用方法的地方,比如本文中,第一个断点是在这个地方:

接下里怎么办?
你当然可以从第一个断点处,一步一步的跟进去。但是在这个过程中,你发现了吗?大多数情况你都是被源码牵着鼻子走的。本来你就只带着一个问题去看源码的,有可能你Debug了十分钟,还没找到关键的代码。也有可能你Debug了十分钟,问题从一个变成了无数个。
所以不要慌,我们点支烟,慢慢分析。

首先怎么避免被源码牵着四处乱逛呢?
我们得找到一个突破口,还记得我在《很开心,在使用mybatis的过程中我踩到一个坑》这篇文章中提到的逆向排查的方法吗?这次的文章,我再次展示一下该方法。
看源码之前,我们的目标要十分明确,就是想要找到 Dubbo 最小活跃数算法的具体实现类以及实现类的具体逻辑是什么。
根据我们的 provider.xml 里面的:

很明显,我们知道 loadbalance 是关键字。所以我们拿着 loadbalance 全局搜索,可以看到 Dubbo 包下面的 LoadBalance。
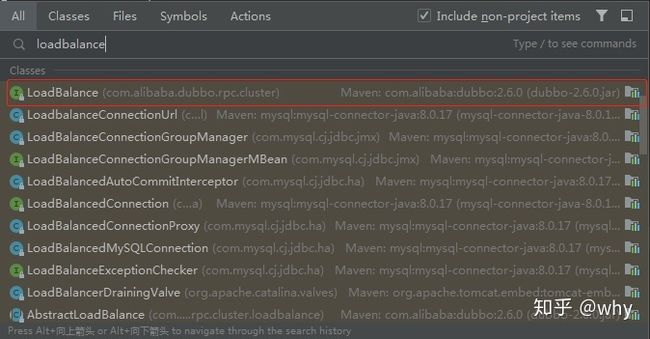
这是一个 SPI 接口 com.alibaba.dubbo.rpc.cluster.LoadBalance:

其实现类为:
com.alibaba.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance
AbstractLoadBalance 是一个抽象类,该类里面有一个抽象方法doSelect。这个抽象方法其中的一个实现类就是我们要分析的最少活跃次数负载均衡的源码。

同时,到这里我们知道了 LoadBalance 是一个 SPI 接口,说明我们可以扩展自己的负载均衡策略。抽象方法 doSelect 有四个实现类。这个四个实现类,就是 Dubbo 官方提供的负载均衡策略(截止 2.7.7 版本之前),他们分别是:
ConsistentHashLoadBalance 一致性哈希算法
LeastActiveLoadBalance 最小活跃数算法
RandomLoadBalance 加权随机算法
RoundRobinLoadBalance 加权轮询算法
我们已经找到了 LeastActiveLoadBalance 这个类了,那么我们的第二个断点打在哪里已经很明确了。

目前看来,两个断点就可以支撑我们的分析了。

有的朋友可能想问,那我想知道 Dubbo 是怎么识别出我们想要的是最少活跃次数算法,而不是其他的算法呢?其他的算法是怎么实现的呢?从第一个断点到第二个断点直接有着怎样的调用链呢?
在没有彻底搞清楚最少活跃数算法之前,这些统统先记录在案但不予理睬。一定要明确目标,带着一个问题进来,就先把带来的问题解决了。之后再去解决在这个过程中碰到的其他问题。在这样环环相扣解决问题的过程中,你就慢慢的把握了源码的精髓。这是我个人的一点看源码的心得。供诸君参考。
模拟环境
既然叫做最小活跃数策略。那我们得让现有的三个消费者都有一些调用次数。所以我们得改造一下服务提供者和消费者。
服务提供者端的改造如下:
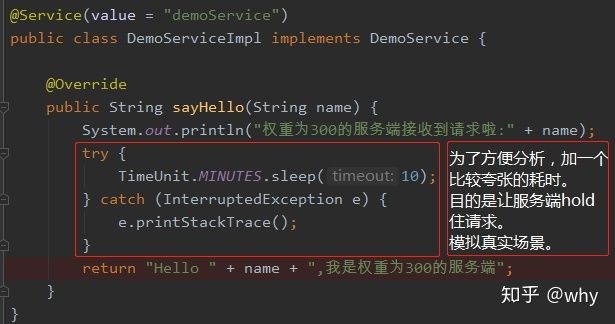

PS:这里以权重为 300 的服务端为例。另外的两个服务端改造点相同。
客户端的改造点如下:

一共发送 21 个请求:其中前 20 个先发到服务端让其 hold 住(因为服务端有 sleep),最后一个请求就是我们需要 Debug 跟踪的请求。
运行一下,让程序停在断点的地方,然后看看控制台的输出:

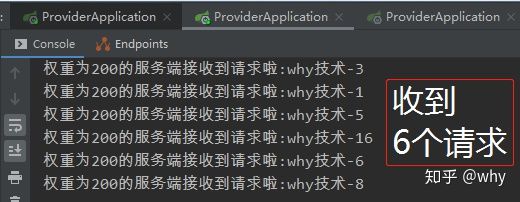

▲上下滑动查看更多
- 权重为300的服务端共计收到9个请求
- 权重为200的服务端共计收到6个请求
- 默认权重的服务端共计收到5个请求
我们还有一个请求在 Debug。直接进入到我们的第二个断点的位置,并 Debug 到下图所示的一行代码(可以点看查看大图):

正如上面这图所说的:weight=100 回答了一个问题,active=0 提出的一个问题。
weight=100 回答了什么问题呢?
默认权重是多少?是 100。
我们服务端的活跃数分别应该是下面这样的
- 权重为300的服务端,active=9
- 权重为200的服务端,active=6
- 默认权重(100)的服务端,active=5
但是这里为什么截图中的active会等于 0 呢?这是一个问题。
继续往下 Debug 你会发现,每一个服务端的 active 都是 0。所以相比之下没有一个 invoker 有最小 active 。于是程序走到了根据权重选择 invoker 的逻辑中。

active为什么是0?
active 为 0 说明在 Dubbo 调用的过程中 active 并没有发生变化。那 active 为什么是 0,其实就是在问 active 什么时候发生变化?
要回答这个问题我们得知道 active 是在哪里定义的,因为在其定义的地方,必有其修改的方法。
下面这图说明了active是定义在RpcStatus类里面的一个类型为AtomicInteger 的成员变量。

在 RpcStatus 类中,有三处()调用 active 值的方法,一个增加、一个减少、一个获取:

很明显,我们需要看的是第一个,在哪里增加。
所以我们找到了 beginCount(URL,String) 方法,该方法只有两个 Filter 调用。ActiveLimitFilter,见名知意,这就是我们要找的东西。

com.alibaba.dubbo.rpc.filter.ActiveLimitFilter具体如下:

看到这里,我们就知道怎么去回答这个问题了:为什么active是0呢?因为在客户端没有配置ActiveLimitFilter。所以,ActiveLimitFilter没有生效,导致active没有发生变化。
怎么让其生效呢?已经呼之欲出了。

好了,再来试验一次:



▲上下滑动查看更多
加上Filter之后,我们通过Debug可以看到,对应权重的活跃数就和我们预期的是一致的了。
1.权重为300的活跃数为6
2.权重为200的活跃数为11
3.默认权重(100)的活跃数为3

根据活跃数我们可以分析出来,最后我们Debug住的这个请求,一定会选择默认权重的invoker去执行,因为他是当前活跃数最小的invoker。如下所示:
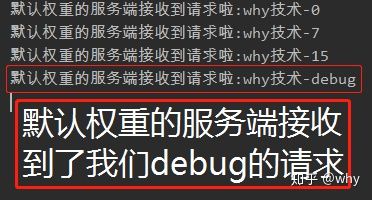
虽然到这里我们还没开始进行源码的分析,只是把流程梳理清楚了。但是把Demo完整的搭建了起来,而且知道了最少活跃数负载均衡算法必须配合ActiveLimitFilter使用,位于RpcStatus类的active字段才会起作用,否则,它就是一个基于权重的算法。
比起其他地方直接告诉你,要配置ActiveLimitFilter才行哦,我们自己实验得出的结论,能让我们的印象更加深刻。
我们再仔细看一下加上ActiveLimitFilter之后的各个服务的活跃数情况:
1.权重为300的活跃数为6
2.权重为200的活跃数为11
3.默认权重(100)的活跃数为3
你不觉得奇怪吗,为什么权重为200的活跃数是最高的?

其在业务上的含义是:我们有三台性能各异的服务器,A服务器性能最好,所以权重为300,B服务器性能中等,所以权重为200,C服务器性能最差,所以权重为100。
当我们选择最小活跃次数的负载均衡算法时,我们期望的是性能最好的A服务器承担更多的请求,而真实的情况是性能中等的B服务器承担的请求更多。这与我们的设定相悖。
如果你说20个请求数据量太少,可能是巧合,不足以说明问题。说明你还没被我带偏,我们不能基于巧合编程。

所以为了验证这个地方确实有问题,我把请求扩大到一万个。

同时,记得扩大 provider 端的 Dubbo 线程池:

由于每个服务端运行的代码都是一样的,所以我们期望的结果应该是权重最高的承担更多的请求。但是最终的结果如图所示:

各个服务器均摊了请求。这就是我文章最开始的时候说的Dubbo 2.6.0 版本中最小活跃数负载均衡算法的Bug之一。
接下来,我们带着这个问题,去分析源码。
剖析源码
com.alibaba.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance的源码如下,我逐行进行了解读。可以点开查看大图,细细品读,非常爽:

下图中红框框起来的部分就是一个基于权重选择invoker的逻辑:
我给大家画图分析一下:

请仔细分析图中给出的举例说明。同时,上面这图也是按照比例画的,可以直观的看到,对于某一个请求,区间(权重)越大的服务器,就越可能会承担这个请求。所以,当请求足够多的时候,各个服务器承担的请求数,应该就是区间,即权重的比值。
其中第 81 行有调用 getWeight 方法,位于抽象类 AbstractLoadBalance 中,也需要进行重点解读的代码。
com.alibaba.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance 的源码如下,我也进行了大量的备注:
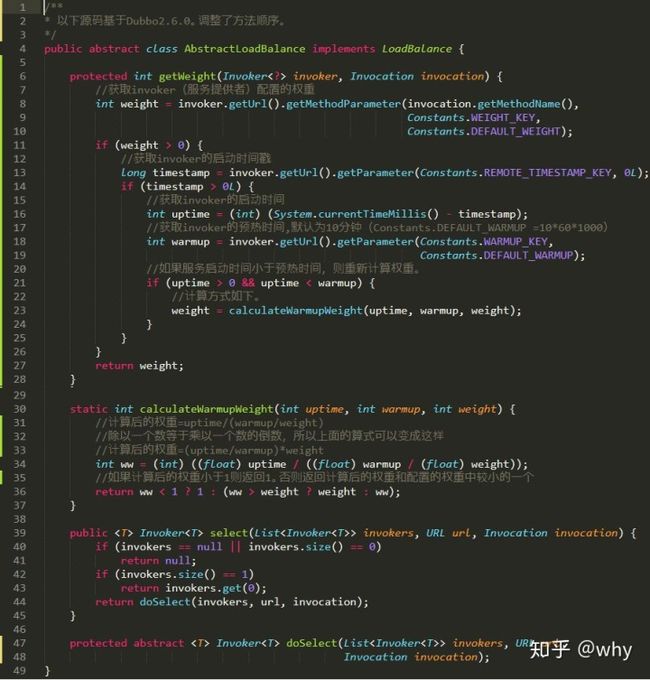
在 AbstractLoadBalance 类中提到了一个预热的概念。官网中是这样的介绍该功能的:
权重的计算过程主要用于保证当服务运行时长小于服务预热时间时,对服务进行降权,避免让服务在启动之初就处于高负载状态。服务预热是一个优化手段,与此类似的还有 JVM 预热。主要目的是让服务启动后“低功率”运行一段时间,使其效率慢慢提升至最佳状态。
从上图代码里面的公式(演变后):计算后的权重=(uptime/warmup)*weight 可以看出:随着服务启动时间的增加(uptime),计算后的权重会越来越接近weight。从实际场景的角度来看,随着服务启动时间的增加,服务承担的流量会慢慢上升,没有一个陡升的过程。所以这是一个优化手段。同时 Dubbo 接口还支持延迟暴露。
在仔细的看完上面的源码解析图后,配合官网的总结加上我的灵魂画作,相信你可以对最小活跃数负载均衡算法有一个比较深入的理解:
- 遍历 invokers 列表,寻找活跃数最小的 Invoker
- 如果有多个 Invoker 具有相同的最小活跃数,此时记录下这些 Invoker 在 invokers 集合中的下标,并累加它们的权重,比较它们的权重值是否相等
- 如果只有一个 Invoker 具有最小的活跃数,此时直接返回该 Invoker 即可
- 如果有多个 Invoker 具有最小活跃数,且它们的权重不相等,此时处理方式和 RandomLoadBalance 一致
- 如果有多个 Invoker 具有最小活跃数,但它们的权重相等,此时随机返回一个即可

所以我觉得最小活跃数负载均衡的全称应该叫做:有最小活跃数用最小活跃数,没有最小活跃数根据权重选择,权重一样则随机返回的负载均衡算法。
Bug在哪里?
Dubbo2.6.0最小活跃数算法Bug一

问题出在标号为 ① 和 ② 这两行代码中:
标号为 ① 的代码在url中取出的是没有经过 getWeight 方法降权处理的权重值,这个值会被累加到权重总和(totalWeight)中。
标号为 ② 的代码取的是经过 getWeight 方法处理后的权重值。
取值的差异会导致一个问题,标号为 ② 的代码的左边,offsetWeight 是一个在 [0,totalWeight) 范围内的随机数,右边是经过 getWeight 方法降权后的权重。所以在经过 leastCount 次的循环减法后,offsetWeight 在服务启动时间还没到热启动设置(默认10分钟)的这段时间内,极大可能仍然大于 0。导致不会进入到标号为 ③ 的代码中。直接到标号为 ④ 的代码处,变成了随机调用策略。这与设计不符,所以是个 bug。
前面章节说的情况就是这个Bug导致的。
这个Bug对应的issues地址和pull request分为:
https:// github.com/apache/dubbo /issues/904 https:// github.com/apache/dubbo /pull/2172
那怎么修复的呢?我们直接对比 Dubbo 2.7.4.1 (目前最新版本)的代码:

可以看到获取weight的方法变了:从url中直接获取变成了通过getWeight方法获取。获取到的变量名称也变了:从weight变成了afterWarmup,更加的见名知意。
还有一处变化是获取随机值的方法的变化,从Randmo变成了ThreadLoaclRandom,性能得到了提升。这处变化就不展开讲了,有兴趣的朋友可以去了解一下。
ThreadLocalRandom
Dubbo2.6.0最小活跃数算法Bug二
这个Bug我没有遇到,但是我在官方文档上看了其描述(官方文档中的版本是2.6.4),引用如下:

官网上说这个问题在2.6.5版本进行修复。我对比了2.6.0/2.6.5/2.7.4.1三个版本,发现每个版本都略有不同。如下所示:

图中标记为①的三处代码:
2.6.0版本的是有Bug的代码,原因在上面说过了。
2.6.5版本的修复方式是获取随机数的时候加一,所以取值范围就从[0,totalWeight)变成了[0,totalWeight],这样就可以避免这个问题。
2.7.4.1版本的取值范围还是[0,totalWeight),但是它的修复方法体现在了标记为②的代码处。2.6.0/2.6.5版本标记为②的地方都是if(offsetWeight<=0),而2.7.4.1版本变成了if(offsetWeight<0)。
你品一品,是不是效果是一样的,但是更加优雅了。

朋友们,魔鬼,都在细节里啊!
好了,进入下一议题。
一致性哈希负载均衡
这一部分是对于Dubbo负载均衡策略之一的一致性哈希负载均衡的详细分析。对源码逐行解读、根据实际运行结果,配以丰富的图片,可能是东半球讲一致性哈希算法在Dubbo中的实现最详细的文章了。

文中所示源码,没有特别标注的地方,均为2.7.4.1版本。
在撰写本文的过程中,发现了Dubbo2.7.0版本之后的一个bug。会导致性能问题,如果你们的负载均衡配置的是一致性哈希或者考虑使用一致性哈希的话,可以了解一下。
哈希算法
在介绍一致性哈希算法之前,我们看看哈希算法,以及它解决了什么问题,带来了什么问题。
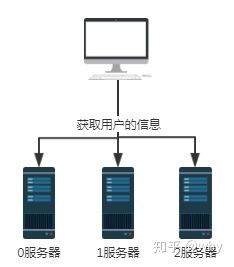
如上图所示,假设0,1,2号服务器都存储的有用户信息,那么当我们需要获取某用户信息时,因为我们不知道该用户信息存放在哪一台服务器中,所以需要分别查询0,1,2号服务器。这样获取数据的效率是极低的。
对于这样的场景,我们可以引入哈希算法。

还是上面的场景,但前提是每一台服务器存放用户信息时是根据某一种哈希算法存放的。所以取用户信息的时候,也按照同样的哈希算法取即可。
假设我们要查询用户号为100的用户信息,经过某个哈希算法,比如这里的userId mod n,即100 mod 3结果为1。所以用户号100的这个请求最终会被1号服务器接收并处理。
这样就解决了无效查询的问题。
但是这样的方案会带来什么问题呢?
扩容或者缩容时,会导致大量的数据迁移。最少也会影响百分之50的数据。

为了说明问题,我们加入一台服务器3。服务器的数量n就从3变成了4。还是查询用户号为100的用户信息时,100 mod 4结果为0。这时,请求就被0号服务器接收了。
当服务器数量为3时,用户号为100的请求会被1号服务器处理。
当服务器数量为4时,用户号为100的请求会被0号服务器处理。
所以,当服务器数量增加或者减少时,一定会涉及到大量数据迁移的问题。可谓是牵一发而动全身。
对于上诉哈希算法其优点是简单易用,大多数分库分表规则就采取的这种方式。一般是提前根据数据量,预先估算好分区数。
其缺点是由于扩容或收缩节点导致节点数量变化时,节点的映射关系需要重新计算,会导致数据进行迁移。所以扩容时通常采用翻倍扩容,避免数据映射全部被打乱,导致全量迁移的情况,这样只会发生50%的数据迁移。
假设这是一个缓存服务,数据的迁移会导致在迁移的时间段内,有缓存是失效的。
缓存失效,可怕啊。还记得我之前的文章吗,《当周杰伦把QQ音乐干翻的时候,作为程序猿我看到了什么?》就是讲缓存击穿、缓存穿透、缓存雪崩的场景和对应的解决方案。
一致性哈希算法
为了解决哈希算法带来的数据迁移问题,一致性哈希算法应运而生。
对于一致性哈希算法,官方说法如下:
一致性哈希算法在1997年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系。一致性哈希解决了简单哈希算法在分布式哈希表( Distributed Hash Table,DHT) 中存在的动态伸缩等问题。
什么意思呢?我用大白话加画图的方式给你简单的介绍一下。
一致性哈希,你可以想象成一个哈希环,它由0到2^32-1个点组成。A,B,C分别是三台服务器,每一台的IP加端口经过哈希计算后的值,在哈希环上对应如下:

当请求到来时,对请求中的某些参数进行哈希计算后,也会得出一个哈希值,此值在哈希环上也会有对应的位置,这个请求会沿着顺时针的方向,寻找最近的服务器来处理它,如下图所示:

一致性哈希就是这么个东西。那它是怎么解决服务器的扩容或收缩导致大量的数据迁移的呢?
看一下当我们使用一致性哈希算法时,加入服务器会发什么事情。

当我们加入一个D服务器后,假设其IP加端口,经过哈希计算后落在了哈希环上图中所示的位置。
这时影响的范围只有图中标注了五角星的区间。这个区间的请求从原来的由C服务器处理变成了由D服务器请求。而D到C,C到A,A到B这个区间的请求没有影响,加入D节点后,A、B服务器是无感知的。
所以,在一致性哈希算法中,如果增加一台服务器,则受影响的区间仅仅是新服务器(D)在哈希环空间中,逆时针方向遇到的第一台服务器(B)之间的区间,其它区间(D到C,C到A,A到B)不会受到影响。
在加入了D服务器的情况下,我们再假设一段时间后,C服务器宕机了:

当C服务器宕机后,影响的范围也是图中标注了五角星的区间。C节点宕机后,B、D服务器是无感知的。
所以,在一致性哈希算法中,如果宕机一台服务器,则受影响的区间仅仅是宕机服务器(C)在哈希环空间中,逆时针方向遇到的第一台服务器(D)之间的区间,其它区间(C到A,A到B,B到D)不会受到影响。
综上所述,在一致性哈希算法中,不管是增加节点,还是宕机节点,受影响的区间仅仅是增加或者宕机服务器在哈希环空间中,逆时针方向遇到的第一台服务器之间的区间,其它区间不会受到影响。
是不是很完美?
不是的,理想和现实的差距是巨大的。
一致性哈希算法带来了什么问题?

当节点很少的时候可能会出现这样的分布情况,A服务会承担大部分请求。这种情况就叫做数据倾斜。
怎么解决数据倾斜呢?加入虚拟节点。
怎么去理解这个虚拟节点呢?
首先一个服务器根据需要可以有多个虚拟节点。假设一台服务器有n个虚拟节点。那么哈希计算时,可以使用IP+端口+编号的形式进行哈希值计算。其中的编号就是0到n的数字。由于IP+端口是一样的,所以这n个节点都是指向的同一台机器。
如下图所示:
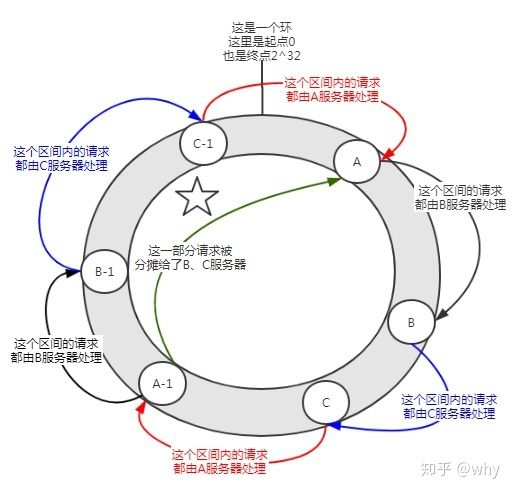
在没有加入虚拟节点之前,A服务器承担了绝大多数的请求。但是假设每个服务器有一个虚拟节点(A-1,B-1,C-1),经过哈希计算后落在了如上图所示的位置。那么A服务器的承担的请求就在一定程度上(图中标注了五角星的部分)分摊给了B-1、C-1虚拟节点,实际上就是分摊给了B、C服务器。
一致性哈希算法中,加入虚拟节点,可以解决数据倾斜问题。
当你在面试的过程中,如果听到了类似于数据倾斜的字眼。那大概率是在问你一致性哈希算法和虚拟节点。
在介绍了相关背景后,我们可以去看看一致性哈希算法在Dubbo中的应用了。
一致性哈希算法在Dubbo中的应用
前面我们说了Dubbo中负载均衡的实现是通过org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance中的 doSelect 抽象方法实现的,一致性哈希负载均衡的实现类如下所示:
org.apache.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance

由于一致性哈希实现类看起来稍微有点抽象,不太好演示,所以我想到了一个"骚"操作。前面的文章说过 LoadBalance 是一个 SPI 接口:
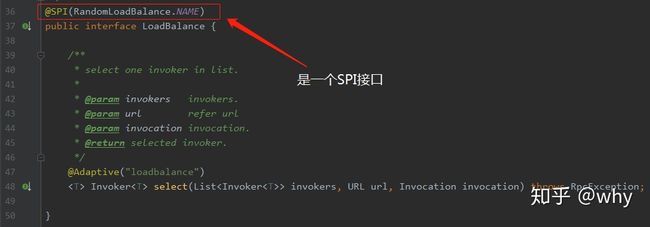
既然是一个 SPI 接口,那我们可以自己扩展一个一模一样的算法,只是在算法里面加入一点输出语句方便我们观察情况。怎么扩展 SPI 接口就不描述了,只要记住代码里面的输出语句都是额外加的,此外没有任何改动即可,如下:

整个类如下图片所示,请先看完整个类,有一个整体的概念后,我会进行方法级别的分析。
图片很长,其中我加了很多注释和输出语句,可以点开大图查看,一定会帮你更加好的理解一致性哈希在Dubbo中的应用:

改造之后,我们先把程序跑起来,有了输出就好分析了。
服务端代码如下:
其中的端口是需要手动修改的,我分别启动服务在20881和20882端口。
项目中provider.xml配置如下:

consumer.xml配置如下:

然后,启动在20881和20882端口分别启动两个服务端。客户端消费如下:

运行结果输出如下,可以先看个大概的输出,下面会对每一部分输出进行逐一的解读。
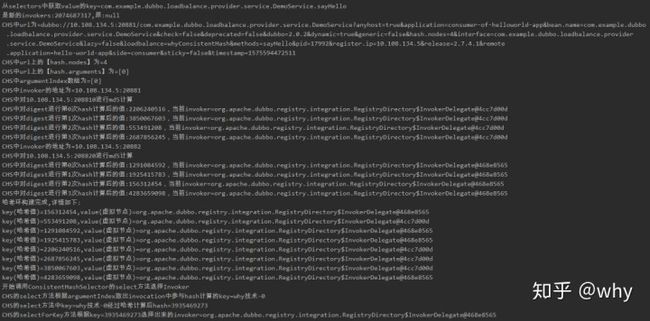
好了,用例也跑起来了,日志也有了。接下来开始结合代码和日志进行方法级别的分析。
首先是doSelect方法的入口:

从上图我们知道了,第一次调用需要对selectors进行put操作,selectors的 key 是接口中定义的方法,value 是 ConsistentHashSelector 内部类。
ConsistentHashSelector通过调用其构造函数进行初始化的。invokers(服务端)作为参数传递到了构造函数中,构造函数里面的逻辑,就是把服务端映射到哈希环上的过程,请看下图,结合代码,仔细分析输出数据:

从上图可以看出,当 ConsistentHashSelector 的构造方法调用完成后,8个虚拟节点在哈希环上已经映射完成。两台服务器,每一台4个虚拟节点组成了这8个虚拟节点。
doSelect方法继续执行,并打印出每个虚拟节点的哈希值和对应的服务端,请仔细品读下图:
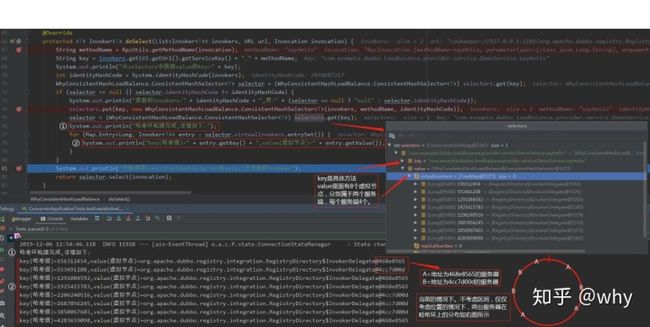
说明一下:上面图中的哈希环是没有考虑比例的,仅仅是展现了两个服务器在哈希环上的相对位置。而且为了演示说明方便,仅仅只有8个节点。假设我们有4台服务器,每台服务器的虚拟节点是默认值(160),这个情况下哈希环上一共有160*4=640个节点。
哈希环映射完成后,接下来的逻辑是把这次请求经过哈希计算后,映射到哈希环上,并顺时针方向寻找遇到的第一个节点,让该节点处理该请求:

还记得地址为 468e8565 的 A 服务器是什么端口吗?前面的图片中有哦,该服务对应的端口是 20882 。

最后我们看看输出结果:
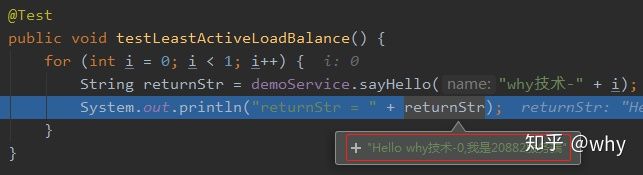
和我们预期的一致。整个调用就算是完成了。
再对两个方法进行一个补充说明。
第一个方法是 selectForKey,这个方法里面逻辑如下图所示:
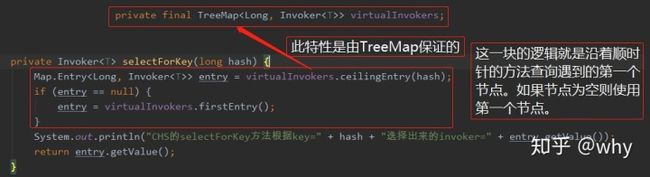
虚拟节点都存储在 TreeMap 中。顺时针查询的逻辑由 TreeMap 保证。看一下下面的 Demo 你就明白了。

第二个方法是 hash 方法,其中的 & 0xFFFFFFFFL 的目的如下:

&是位运算符,而 0xFFFFFFFFL 转换为四字节表现后,其低32位全是1,所以保证了哈希环的范围是 [0,Integer.MAX_VALUE]:
所以这里我们可以改造这个哈希环的范围,假设我们改为 100000。十进制的 100000 对于的 16 进制为 186A0 。所以我们改造后的哈希算法为:
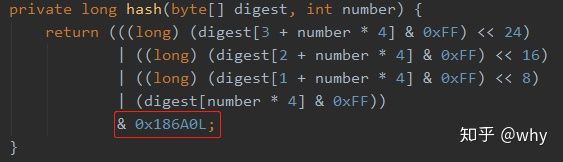
再次调用后可以看到,计算后的哈希值都在10万以内。但是分布极不均匀,说明修改数据后这个哈希算法不是一个优秀的哈希算法:

以上,就是对一致性哈希算法在Dubbo中的实现的解读。需要特殊说明一下的是,一致性哈希负载均衡策略和权重没有任何关系。
我又发现了一个BUG
前面我介绍了Dubbo 2.6.5版本之前,最小活跃数算法的两个 bug。
很不幸,这次我又发现了Dubbo 2.7.4.1版本,一致性哈希负载均衡策略的一个bug,我提交了issue 地址如下:
https:// github.com/apache/dubbo /issues/5429

我在这里详细说一下这个Bug现象、原因和我的解决方案。
现象如下,我们调用三次服务端:

输出日志如下(有部分删减):

可以看到,在三次调用的过程中并没有发生服务的上下线操作,但是每一次调用都重新进行了哈希环的映射。而我们预期的结果是应该只有在第一次调用的时候进行哈希环的映射,如果没有服务上下线的操作,后续请求根据已经映射好的哈希环进行处理。
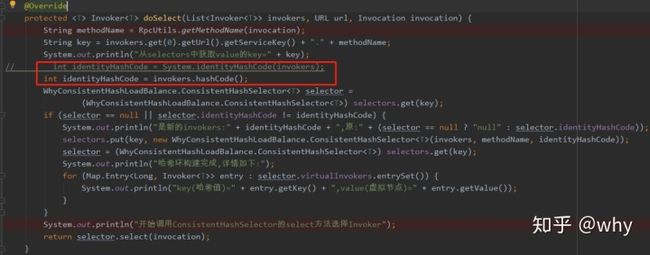
上面输出的原因是由于每次调用的invokers的identityHashCode发生了变化:

我们看一下三次调用invokers的情况:

经过debug我们可以看出因为每次调用的invokers地址值不是同一个,所以System.identityHashCode(invokers)方法返回的值都不一样。
接下来的问题就是为什么每次调用的invokers地址值都不一样呢?
经过Debug之后,可以找到这个地方:
org.apache.dubbo.rpc.cluster.RouterChain#route

问题就出在这个TagRouter中:
org.apache.dubbo.rpc.cluster.router.tag.TagRouter#filterInvoker

所以,在TagRouter中的stream操作,改变了invokers,导致每次调用时其
System.identityHashCode(invokers)返回的值不一样。所以每次调用都会进行哈希环的映射操作,在服务节点多,虚拟节点多的情况下会有一定的性能问题。
到这一步,问题又发生了变化。这个TagRouter怎么来的呢?
如果了解Dubbo 2.7.x版本新特性的朋友可能知道,标签路由是Dubbo2.7引入的新功能。

通过加载下面的配置加载了RouterFactrory:
META-INFdubbointernalorg.apache.dubbo.rpc.cluster.RouterFactory(Dubbo 2.7.0版本之前)
META-INFdubbointernalcom.alibaba.dubbo.rpc.cluster.RouterFactory(Dubbo 2.7.0之前)
下面是Dubbo 2.6.7(2.6.x的最后一个版本)和Dubbo 2.7.0版本该文件的对比:

可以看到确实是在 Dubbo 2.7.0 之后引入了 TagRouter。
至此,Dubbo 2.7.0 版本之后,一致性哈希负载均衡算法的 Bug 的来龙去脉也介绍清楚了。
解决方案是什么呢?特别简单,把获取 identityHashCode 的方法从 System.identityHashCode(invokers) 修改为 invokers.hashCode() 即可。
此方案是我提的 issue 里面的评论,这里 System.identityHashCode 和 hashCode 之间的联系和区别就不进行展开讲述了,不清楚的大家可以自行了解一下。
(可以看看我的这篇文章:够强!一行代码就修复了我提的Dubbo的Bug。)
改完之后,我们再看看运行效果:

可以看到第二次调用的时候并没有进行哈希环的映射操作,而是直接取到了值,进行调用。
加入节点,画图分析
最后,我再分析一种情况。在A、B、C三个服务器(20881、20882、20883端口)都在正常运行,哈希映射已经完成的情况下,我们再启动一个D节点(20884端口),这时的日志输出和对应的哈希环变化情况如下:

根据日志作图如下:

根据输出日志和上图再加上源码,你再细细回味一下。我个人觉得还是讲的非常详细了。
一致性哈希的应用场景
当大家谈到一致性哈希算法的时候,首先的第一印象应该是在缓存场景下的使用,因为在一个优秀的哈希算法加持下,其上下线节点对整体数据的影响(迁移)都是比较友好的。
但是想一下为什么 Dubbo 在负载均衡策略里面提供了基于一致性哈希的负载均衡策略?它的实际使用场景是什么?
我最开始也想不明白。我想的是在 Dubbo 的场景下,假设需求是想要一个用户的请求一直让一台服务器处理,那我们可以采用一致性哈希负载均衡策略,把用户号进行哈希计算,可以实现这样的需求。但是这样的需求未免有点太牵强了,适用场景略小。
直到有天晚上,我睡觉之前,电光火石之间突然想到了一个稍微适用的场景了。当时的情况大概是这样的。

如果需求是需要保证某一类请求必须顺序处理呢?
如果你用其他负载均衡策略,请求分发到了不同的机器上去,就很难保证请求的顺序处理了。比如A,B请求要求顺序处理,现在A请求先发送,被负载到了A服务器上,B请求后发送,被负载到了B服务器上。而B服务器由于性能好或者当前没有其他请求或者其他原因极有可能在A服务器还在处理A请求之前就把B请求处理完成了。这样不符合我们的要求。
这时,一致性哈希负载均衡策略就上场了,它帮我们保证了某一类请求都发送到固定的机器上去执行。比如把同一个用户的请求发送到同一台机器上去执行,就意味着把某一类请求发送到同一台机器上去执行。所以我们只需要在该机器上运行的程序中保证顺序执行就行了,比如你加一个队列。
一致性哈希算法+队列,可以实现顺序处理的需求。
好了,一致性哈希负载均衡算法就写到这里。
继续进入下一个议题。
加权轮询负载均衡
这一小节是对于Dubbo负载均衡策略之一的加权随机算法的详细分析。
从 2.6.4 版本聊起,该版本在某些情况下存在着比较严重的性能问题。由问题入手,层层深入,了解该算法在 Dubbo 中的演变过程,读懂它的前世今生。
什么是轮询?
在描述加权轮询之前,先解释一下什么是轮询算法,如下图所示:
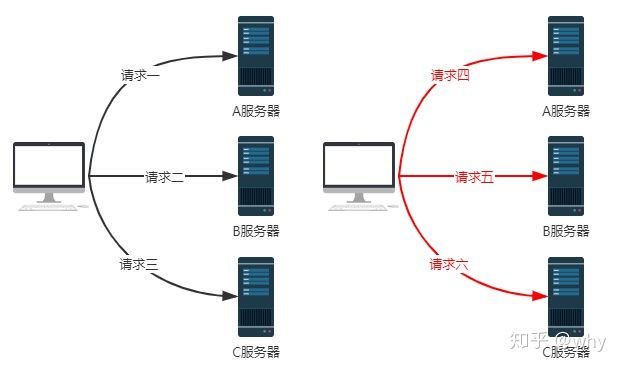
假设我们有A、B、C三台服务器,共计处理6个请求,服务处理请求的情况如下:
- 第一个请求发送给了A服务器
- 第二个请求发送给了B服务器
- 第三个请求发送给了C服务器
- 第四个请求发送给了A服务器
- 第五个请求发送给了B服务器
- 第六个请求发送给了C服务器
- ......
上面这个例子演示的过程就叫做轮询。可以看出,所谓轮询就是将请求轮流分配给每台服务器。
轮询的优点是无需记录当前所有服务器的链接状态,所以它一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。
轮询的缺点也是显而易见的,它的应用场景要求所有服务器的性能都相同,非常的局限。
大多数实际情况下,服务器性能是各有差异,针对性能好的服务器,我们需要让它承担更多的请求,即需要给它配上更高的权重。
所以加权轮询,应运而生。
什么是加权轮询?
为了解决轮询算法应用场景的局限性。当遇到每台服务器的性能不一致的情况,我们需要对轮询过程进行加权,以调控每台服务器的负载。
经过加权后,每台服务器能够得到的请求数比例,接近或等于他们的权重比。比如服务器 A、B、C 权重比为 5:3:2。那么在10次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的3次请求,服务器 C 则收到其中的2次请求。

这里要和加权随机算法做区分哦。直接把前面介绍的加权随机算法画的图拿过来:
上面这图是按照比例画的,可以直观的看到,对于某一个请求,区间(权重)越大的服务器,就越可能会承担这个请求。所以,当请求足够多的时候,各个服务器承担的请求数,应该就是区间,即权重的比值。
假设有A、B、C三台服务器,权重之比为5:3:2,一共处理10个请求。
那么负载均衡采用加权随机算法时,很有可能A、B服务就处理完了这10个请求,因为它是随机调用。
采用负载均衡采用轮询加权算法时,A、B、C服务一定是分别承担5、3、2个请求。
Dubbo2.6.4版本的实现
对于Dubbo2.6.4版本的实现分析,可以看下图,我加了很多注释,其中的输出语句都是我加的:

示例代码还是沿用之前文章中的Demo,这里分别在 20881、20882、20883 端口启动三个服务,各自的权重分别为 1,2,3。
客户端调用 8 次:

输出结果如下:

可以看到第七次调用后mod=0,回到了第一次调用的状态。形成了一个闭环。
再看看判断的条件是什么:

其中mod在代码中扮演了极其重要的角色,mod根据一个方法的调用次数不同而不同,取值范围是[0,weightSum)。
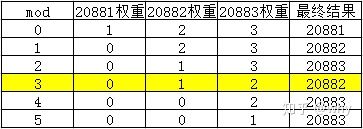
因为weightSum=6,所以列举mod不同值时,最终的选择结果和权重变化:

可以看到20881,20882,20883承担的请求数量比值为1:2:3。同时我们可以看出,当 mod >= 1 后,20881端口的服务就不会被选中了,因为它的权重被减为0了。当 mod >= 4 后,20882端口的服务就不会被选中了,因为它的权重被减为0了。
结合判断条件和输出结果,我们详细分析一下(下面内容稍微有点绕,如果看不懂,多结合上面的图片看几次):
第一次调用
mod=0,第一次循环就满足代码块①的条件,直接返回当前循环的invoker,即20881端口的服务。此时各端口的权重情况如下:

第二次调用
mod=1,需要进入代码块②,对mod进行一次递减。
- 第一次循环对20881端口的服务权重减一,mod-1=0。
- 第二次循环,mod=0,循环对象是20882端口的服务,权重为2,满足代码块①,返回当前循环的20882端口的服务。
此时各端口的权重情况如下:

第三次调用
mod=2,需要进入代码块②,对mod进行两次递减。
- 第一次循环对20881端口的服务权重减一,mod-1=1;
- 第二次循环对20882端口的服务权重减一,mod-1=0;
- 第三次循环时,mod已经为0,当前循环的是20883端口的服务,权重为3,满足代码块①,返回当前循环的20883端口的服务。
此时各端口的权重情况如下:

第四次调用
mod=3,需要进入代码块②,对mod进行三次递减。
- 第一次循环对20881端口的服务权重减一,从1变为0,mod-1=2;
- 第二次循环对20882端口的服务权重减一,从2变为1,mod-1=1;
- 第三次循环对20883端口的服务权重减一,从3变为2,mod-1=0;
- 第四次循环的是20881端口的服务,此时mod已经为0,但是20881端口的服务的权重已经变为0了,不满足代码块①和代码块②,进入第五次循环。
- 第五次循环的是20882端口的服务,当前权重为1,mod=0,满足代码块①,返回20882端口的服务。
此时各端口的权重情况如下:
第五次调用
mod=4,需要进入代码块②,对mod进行四次递减。
- 第一次循环对20881端口的服务权重减一,从1变为0,mod-1=3;
- 第二次循环对20882端口的服务权重减一,从2变为1,mod-1=2;
- 第三次循环对20883端口的服务权重减一,从3变为2,mod-1=1;
- 第四次循环的是20881端口的服务,此时mod为1,但是20881端口的服务的权重已经变为0了,不满足代码块②,mod不变,进入第五次循环。
- 第五次循环时,mod为1,循环对象是20882端口的服务,权重为1,满足代码块②,权重从1变为0,mod从1变为0,进入第六次循环。
- 第六次循环时,mod为0,循环对象是20883端口的服务,权重为2,满足条件①,返回当前20883端口的服务。
此时各端口的权重情况如下:

第六次调用
第六次调用,mod=5,会循环九次,最终选择20883端口的服务,读者可以自行分析一波,分析出来了,就了解的透透的了。

第七次调用
第七次调用,又回到mod=0的状态:
2.6.4版本的加权轮询就分析完了,但是事情并没有这么简单。这个版本的加权轮询是有性能问题的。
该问题对应的issue地址如下:
https:// github.com/apache/dubbo /issues/2578
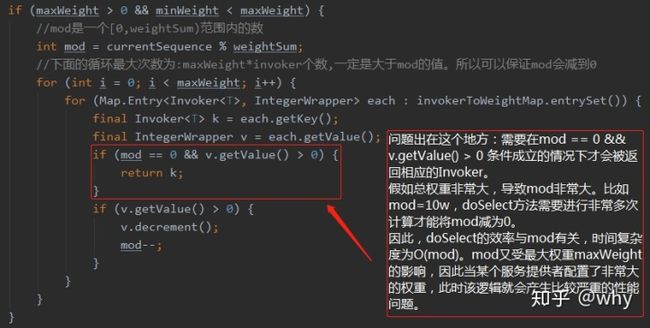
问题出现在invoker返回的时机上:
截取issue里面的一个回答:

10分钟才选出一个invoker,还怎么玩?
有时间可以读一读这个issue,里面各路大神针对该问题进行了激烈的讨论,第一种改造方案被接受后,很快就被推翻,被第二种方案代替,可以说优化思路十分值得学习,很精彩,接下来的行文路线就是按照该issue展开的。
推翻,重建。
上面的代码时间复杂度是O(mod),而第一次修复之后时间复杂度降低到了常量级别。可以说是一次非常优秀的优化,值得我们学习,看一下优化之后的代码:

其关键优化的点是这段代码,我加入输出语句,便于分析。

输出日志如下:

把上面的输出转化到表格中去,7次请求的选择过程如下:

该算法的原理是:
把服务端都放到集合中(invokerToWeightList),然后获取服务端个数(length),并计算出服务端权重最大的值(maxWeight)。
index表示本次请求到来时,处理该请求的服务端下标,初始值为0,取值范围是[0,length)。
currentWeight表示当前调度的权重,初始值为0,取值范围是[0,maxWeight)。
当请求到来时,从index(就是0)开始轮询服务端集合(invokerToWeightList),如果是一轮循环的开始(index=0)时,则对currentWeight进行加一操作(不会超过maxWeight),在循环中找出第一个权重大于currentWeight的服务并返回。
这里说的一轮循环是指index再次变为0所经历过的循环,这里可以把index=0看做是一轮循环的开始。每一轮循环的次数与Invoker的数量有关,Invoker数量通常不会太多,所以我们可以认为上面代码的时间复杂度为常数级。
从issue上看出,这个算法最终被merged了。

但是很快又被推翻了:
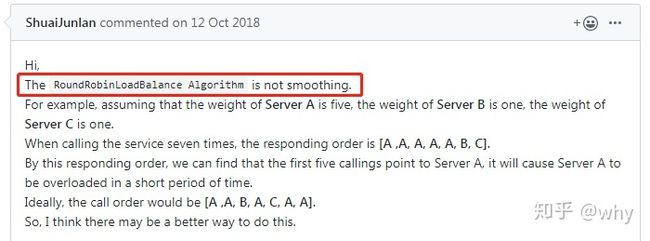
这个算法不够平滑。什么意思呢?
翻译一下上面的内容就是:服务器[A, B, C]对应权重[5, 1, 1]。进行7次负载均衡后,选择出来的序列为[A, A, A, A, A, B, C]。前5个请求全部都落在了服务器A上,这将会使服务器A短时间内接收大量的请求,压力陡增。而B和C此时无请求,处于空闲状态。而我们期望的结果是这样的[A, A, B, A, C, A, A],不同服务器可以穿插获取请求。
我们设置20881端口的权重为5,20882、20883端口的权重均为1。
进行实验,发现确实如此:可以看到一共进行7次请求,第1次到5次请求都分发给了权重为5的20881端口的服务,前五次请求,20881和20882都处于空闲状态:

转化为表格如下:

从表格的最终结果一栏也可以直观的看出,七次请求对应的服务器端口为:
分布确实不够均匀。
再推翻,再重建,平滑加权。
从issue中可以看到,再次重构的加权算法的灵感来源是Nginx的平滑加权轮询负载均衡:

看代码之前,先介绍其计算过程。
假设每个服务器有两个权重,一个是配置的weight,不会变化,一个是currentWeight会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的currentWeight加上自身权重。遍历完成后,找到最大的currentWeight,并将其减去权重总和,然后返回相应的服务器即可。
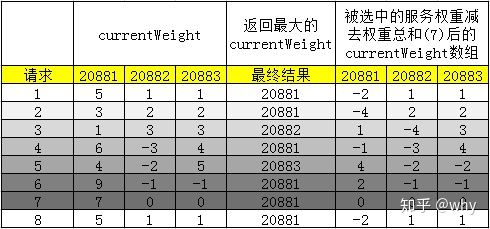
如果你还是不知道上面的表格是如何算出来的,我再给你详细的分析一下第1、2个请求的计算过程:
第一个请求计算过程如下:

第二个请求计算过程如下:

后面的请求你就可以自己分析了。
从表格的最终结果一栏也可以直观的看出,七次请求对应的服务器端口为:
可以看到,权重之比同样是5:1:1,但是最终的请求分发的就比较的"平滑"。对比一下:

对于平滑加权算法,我想多说一句。我觉得这个算法非常的神奇,我是彻底的明白了它每一步的计算过程,知道它最终会形成一个闭环,但是我想了很久,我还是不知道背后的数学原理是什么,不明白为什么会形成一个闭环,非常的神奇。
很正常,我不纠结的,程序猿的工作不就是这样吗?我也不知道为什么,它能工作。别问,问就是玄学,如果一定要说出点什么的话,我想,我愿称之为:绝活吧。

但是我们只要能够理解我前面所表达的平滑加权轮询算法的计算过程,知道其最终会形成闭环,就能理解下面的代码。配合代码中的注释食用,效果更佳。
以下代码以及注释来源官网:
http:// dubbo.apache.org/zh-cn/ docs/source_code_guide/loadbalance.html

总结
好了,到这里关于Dubbo的五种负载均衡策略就讲完了。简单总结一下:(加权随机算法在讲最小活跃数算法的时候提到过,因为原理十分简单,这里就不专门拿出章节来描述了。)
最短响应时间负载均衡:在所有服务提供者中选出平均响应时间最短的一个,如果能选出来,则使用选出来的一个。如果不能选出来多个,再根据权重选,如果权重也一样,则随机选择。
一致性哈希负载均衡:在一致性哈希算法中,不管是增加节点,还是宕机节点,受影响的区间仅仅是增加或者宕机服务器在哈希环空间中,逆时针方向遇到的第一台服务器之间的区间,其它区间不会受到影响。为了解决数据倾斜的问题,引入了虚拟节点的概念。一致性哈希算法是 Dubbo 中唯一一个与权重没有任何关系的负载均衡算法,可以保证相同参数的请求打到同一台机器上。
最小活跃数负载均衡:需要配合 activeFilter 使用,活跃数在方法调用前后进行维护,响应越快的服务器堆积的请求越少,对应的活跃数也少。Dubbo 在选择的时候遵循下面的规则,有最小活跃数用最小活跃数,没有最小活跃数根据权重选择,权重一样则随机返回的负载均衡算法。
加权随机算法:随机,顾名思义,就是从多个服务提供者中随机选择一个出来。加权,就是指需要按照权重设置随机概率。常见场景就是对于性能好的机器可以把对应的权重设置的大一点,而性能相对较差的,权重设置的小一点。哎,像极了这个社会上的某些现象,对外宣传是随机摇号,背后指不定有一群权重高的人呢。
加权轮询负载均衡:轮询就是雨露均沾的意思,所有的服务提供者都需要调用。而当轮询遇到加权则可以让请求(不论多少)严格按照我们的权重之比进行分配。比如有A、B、C三台服务器,权重之比为5:3:2,一共处理10个请求。那么采用负载均衡采用轮询加权算法时,A、B、C服务一定是分别承担5、3、2个请求。同时需要注意的是加权轮询算法的两次升级过程,以及最终的“平滑”的解决方案。
再说两件事
第一件事情是终于来到第 50 篇原创文章了。算是一个小小的里程牌。我曾经在《订阅号做了77天,我挣了487.52元》这篇文章中说过:

但行好事,莫问前程。好好写文章,剩下的交给时间吧。只是写完这篇文章后在往回看自己的前 49 篇,前 279 天,有点感慨。收获很多,失去很多。
说好连续周更50篇的,期间好几次差点就断更了。嗯,坚持不住的时候再坚持一下,确实是一种难能可贵的品质。
第二件事情是本文主要聊的是负载均衡嘛,让我想起了 2019 年阿里巴巴第五届中间件挑战赛的初赛赛题也是实现一个负载均衡策略。
具体的赛题可以看这里:
https:// tianchi.aliyun.com/comp etition/entrance/231714/information

这种比赛还是很有意思的,你报名之后仅仅是读懂赛题,然后自己多想想怎么实现,哪怕是不提交代码,在比赛完成后看前几名的赛题分析,再去把他们的代码拉下来看看,你就会发现,其实最终的思路都大同小异,差别会体现在参数调优和代码优化程度上。
当然最大的差别还是会体现在语言的层面。如果不限制参数语言的话,Java 系的选手一定是被 C 系选手吊打的。
但是,被吊打不重要,重要的是真的能学到很多的东西,而这些东西,在绝大部分工作中是很难学到的。
最近,阿里巴巴第六届中间件挑战赛也开始了,可以看一下这个链接:
https://tianchi.aliyun.com/competition/entrance/231790/introduction?spm=5176.12281968.1008.3.65818188YmzFqa
这次是分为三个赛道,选择性更多了。

作为这个比赛的长期关注者(持续关注三年了吧),这次作为一个自来水免费宣传一波。
朋友,我真心建议你去看一下,报个名,玩一玩,收获真的很大的。
当然,如果能在报名的时候邀请人那一栏填【why技术】,我真心感谢你。
最后说一句(求关注)

点个“znazan赞”吧,周更很累的,不要白嫖我,需要一点正反馈。

才疏学浅,难免会有纰漏,如果你发现了错误的地方,由于本号没有留言功能,还请你在后台留言指出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。
我是 why,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。