基于sentencepiece工具和unicode编码两种编码分词的word2vec(CBOW,Skip-gram)词向量训练,并结合TextCNN模型,替换初始词向量进行文本分类任务
基于sentencepiece工具和unicode编码两种编码分词的word2vec(CBOW,Skip-gram)词向量训练,并结合TextCNN模型,替换初始词向量进行文本分类任务
博主这次做的实验很难,但是想法很好,我觉得基础不好的可能都看不懂我的题目,在这篇博客里,博主会附上我得代码,大家可以好好学习一下。
这个实验分如下几个部分
一、sentencepiece分词模型训练
二、使用sentencepiece分词模型对文本进行分词,和使用unicode编码方式对文本进行分词
三、使用CBOW和Skip-gram训练我们的词向量
四、使用训练好的词向量替换TextCNN模型初始词向量,并应用于文本分类任务
注:本次实验较难,若想运行博主代码,需要基础很好,希望误轻易尝试,若实在很想运行我的代码,可以联系我。
一、sentencepiece分词模型训练和分词
注:word2vecdata.txt为文本其中吗,每一行为一个句子。
训练部分代码如下,同时
import os
import sentencepiece as spm
# train sentencepiece model from `botchan.txt` and makes `m.model` and `m.vocab`
# `m.vocab` is just a reference. not used in the segmentation.
spm.SentencePieceTrainer.train('--input="D:\\data\\1018\\word2vecdata.txt --model_prefix=m --vocab_size=8000 --model_type=bpe')
os.system('pause')
二、使用sentencepiece分词模型对文本进行分词,和使用unicode编码方式对文本进行分词
这部分比较简单
调用训练的sentencepiece分词模型并进行切词代码如下:
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
sp.Load("C:\\Users\\gaoxing\\source\\repos\\wordvec_to_TextCNN\\wordvec_to_TextCNN\\m.model") #加载训练好的模型
a=sp.EncodeAsPieces(test_text) #切词
unicode编码分词很简单:
word=[i for i in strz]
三、使用CBOW和Skip-gram训练我们的词向量
这部分内容比较难了
(1)首先是CBOW训练词向量的代码:
cbow.py
#coding=gbk
import os
import jieba
import torch
from torch import nn, optim
from torch.autograd import Variable
import torch.nn.functional as F
import sentencepiece as spm
import matplotlib.pyplot as plt
loss_list=[]
sp = spm.SentencePieceProcessor()
sp.Load("C:\\Users\\gaoxing\\source\\repos\\wordvec_to_TextCNN\\wordvec_to_TextCNN\\m.model") #加载训练好的模型
path=r"D:\data\1018\word2vecdata.txt"
learning_rate = 0.001
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
epochs=100
embedding_dim=100
windows_size=30
use_sentencepiece=0
def read_file(path):
fp=open(path,encoding='utf8')
text=fp.readlines()
fp.close()
return text
def cut_words(text):
dict_index={}
index=0
words_list=[]
for line in text:
line=line.replace('"','')
line=line.replace('“','')
line=line.replace('”','')
line=line.replace('。','')
line=line.replace('\n','')
line=line.replace(' ','')
words_cut=line.split(',')
for strz in words_cut:
if use_sentencepiece:
words_l= sp.EncodeAsPieces(strz)
else:
words_l=[i for i in strz]
for word in words_l:
if word not in dict_index.keys():
dict_index[word]=index
index=index+1
if len(words_l)>0:
words_list.append(words_l)
return words_list,dict_index
def get_data_corpus(words_list,window_size):
data_corpus=[]
for words in words_list:
if len(words)<2:
continue
else:
for index in range(len(words)):
l=[]
target=words[index]
l.append(target)
try:
l.append(words[index+1])
l.append(words[index+2])
except:
pass
try:
l.append(words[index-1])
l.append(words[index-2])
except:
pass
data_corpus.append(l)
return data_corpus
text=read_file(path)
words_list,dict_index=cut_words(text)
#print(words_list,dict_index)
data_corpus=get_data_corpus(words_list,windows_size)
#print(data_corpus)
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# self.proj = nn.Linear(embedding_dim, vocab_size)
self.output = nn.Linear(embedding_dim, vocab_size)
def forward(self, inputs):
embeds = sum(self.embeddings(inputs)).view(1, -1)
# out = F.relu(self.proj(embeds))
out = self.output(embeds)
nll_prob = F.log_softmax(out, dim=-1)
return nll_prob
length=len(dict_index.keys())
print("length",length)
data_final=[]
for words in data_corpus[0:1000]:
target_vector=torch.zeros(length)
context_id=[]
if len(words)==5:
target_vector[dict_index[words[0]]]=1
for i in words[1:]:
context_id.append(dict_index[i])
data_final.append([target_vector,context_id])
#print(data_final)
model=CBOW(length,embedding_dim).to(device)
loss_function=nn.NLLLoss()
optimizer=optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9)
losses=[]
for epoch in range(epochs):
total_loss = 0
for data in data_final:
target=data[0]
context=data[1]
# context_vector = make_context_vector(context, word_to_idx).to(device) # 把训练集的上下文和标签都放到cpu中
target = torch.tensor(target).type(dtype=torch.long)
context=torch.tensor(context)
target = target.cuda()
context=context.to(device)
model.zero_grad() # 梯度清零
train_predict = model(context).cuda() # 开始前向传播
#print("train_predict",train_predict[0])
#print("target",target)
loss = loss_function(train_predict[0], target)
loss.backward() # 反向传播
optimizer.step() # 更新参数
total_loss += loss.item()
print("loss ",total_loss)
loss_list.append(total_loss)
losses.append(total_loss)
#保存
torch.save(model,r'D:\data\1018\cbow_emb_uni.pt')
#读取
path=r'D:\data\1018\cbow_emb_uni.pt'
model = torch.load(path)
print(type(model.state_dict())) # 查看state_dict所返回的类型,是一个“顺序字典OrderedDict”
for param_tensor in model.state_dict(): # 字典的遍历默认是遍历 key,所以param_tensor实际上是键值
print(param_tensor,'\t',model.state_dict()[param_tensor].size())
embedings=model.state_dict()['output.weight']
fp=open(r'D:\data\1018\cbow_emb_uni.txt','w',encoding='utf8')
for word in dict_index.keys():
print(word,dict_index[word])
# print(word,embedings[dict_index[word]])
ls=list(embedings[dict_index[word]])
# print("ls",ls)
ls=[float(i) for i in ls]
ls=[str(i) for i in ls]
# print(ls)
ls=' '.join(ls)
fp.write(word+' '+ls+'\n')
fp.close()
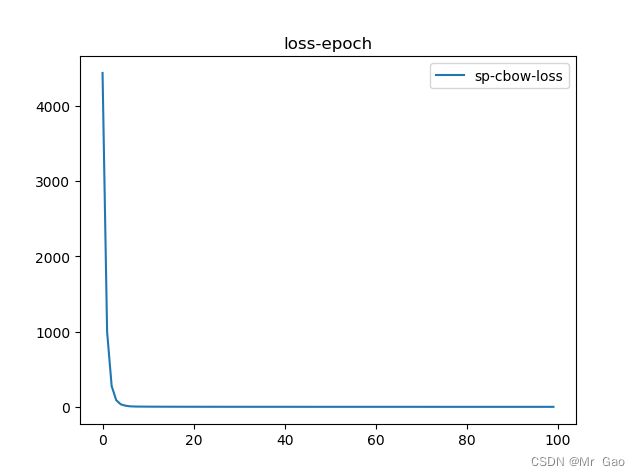
plt.plot(loss_list,label='uni-cbow-loss')
plt.legend()
plt.title('loss-epoch')
plt.show()
os.system("pause")
这里附上我们的训练loss曲线图:

(2)然后是skip-gram模型词向量训练
在这之前,需要先进行文本分词,CBOW是两步连在一起的,这个是文本分词是分开的,代码如下:
data_precess_skip.py
#encoding=gbk
import re
import jieba
import sentencepiece as spm
sp = spm.SentencePieceProcessor()
sp.Load("C:\\Users\\gaoxing\\source\\repos\\wordvec_to_TextCNN\\wordvec_to_TextCNN\\m.model") #加载训练好的模型
stopwords=[]
use_sentencepiece=1
def get_stop_words():
file_object = open(r'D:\work\10-5\use_data\stopwords.txt',encoding='utf-8')
stop_words = []
for line in file_object.readlines():
line = line[:-1]
line = line.strip()
stopwords.append(line)
return stop_words
f1 = open(r'D:\data\1018\word2vecdata.txt', 'r', encoding='utf-8', errors='ignore')
f2 = open(r'D:\data\1018\word2vecdata_sp.txt', 'w', encoding='utf-8')
line = f1.readline()
count=540
while line and count:
line = line.strip() # 去前后的空格
if line.isspace(): # 跳过空行
line = f1.readline()
# line = re.findall('[\u4e00-\u9fa5]+', line) # 去除标点符号
line = "".join(line)
count=count-1
#seg_list = [i for i in line]
if use_sentencepiece:
seg_list= sp.EncodeAsPieces(line)
else:
seg_list=[i for i in line]
outStr = ""
for word in seg_list:
if word not in stopwords: # 去除停用词
outStr += word
outStr += " "
if outStr: # 不为空添加换行符
outStr = outStr.strip() + '\n'
f2.writelines(outStr)
line = f1.readline()
f1.close()
f2.close()
然后是模型构建代码:
skip_gram.py
#encoding=gbk
import torch
import torch.nn as nn
import torch.nn.functional as F
class SkipGramModel(nn.Module):
def __init__(self, emb_size, emb_dimension):
super(SkipGramModel, self).__init__()
self.emb_size = emb_size
self.emb_dimension = emb_dimension
self.u_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True) # 初始化中心词向量矩阵
self.v_embeddings = nn.Embedding(emb_size, emb_dimension, sparse=True) # 初始化周围词向量矩阵
self.init_emb()
def init_emb(self):
initrange = 0.5 / self.emb_dimension
self.u_embeddings.weight.data.uniform_(-initrange, initrange) # 初始化中心词词向量矩阵权重
self.v_embeddings.weight.data.uniform_(-0, 0)
def forward(self, pos_u, pos_v, neg_v):
emb_u = self.u_embeddings(pos_u) # [batch_size * emb_dimension]
emb_v = self.v_embeddings(pos_v) # [batch_size * emb_dimension]
score = torch.mul(emb_u, emb_v).squeeze() # [batch_size * emb_dimension]
score = torch.sum(score, dim=1) # [batch_size * 1]
score = F.logsigmoid(score) # [batch_size * 1]
neg_emb_v = self.v_embeddings(neg_v) # [batch_size, k, emb_dimension]
neg_score = torch.bmm(neg_emb_v, emb_u.unsqueeze(2)).squeeze() # [batch_size, k]
neg_score = F.logsigmoid(-1 * neg_score) # [batch_size, k]
# L = log sigmoid (Xu.T * θv) + ∑neg(v) [log sigmoid (-Xu.T * θneg(v))]
return -1 * (torch.sum(score) + torch.sum(neg_score))
def save_embedding(self, id2word, file_name, use_cuda): # 保存中心词与周围词向量矩阵
embedding = self.u_embeddings.weight.cpu().data.numpy()
# embedding_u = self.u_embeddings.weight.cpu().data.numpy()
# embedding_v = self.v_embeddings.weight.cpu().data.numpy()
# embedding = (embedding_u + embedding_v) / 2
fout = open(file_name, 'w', encoding="utf-8")
fout.write('%d %d\n' % (len(id2word), self.emb_dimension))
for wid, w in id2word.items():
e = embedding[wid]
e = ' '.join(map(lambda x: str(x), e))
fout.write('%s %s\n' % (w, e))
负采样代码:
input_data.py
#encoding=gbk
import math
import numpy
from collections import deque
from numpy import random
numpy.random.seed(6)
class InputData:
def __init__(self, file_name, min_count):
self.input_file_name = file_name
self.get_words(min_count)
self.word_pair_catch = deque() # deque为队列,用来读取数据
self.init_sample_table() # 采样表
print('Word Count: %d' % len(self.word2id))
print("Sentence_Count:", self.sentence_count)
print("Sentence_Length:", self.sentence_length)
def get_words(self, min_count): # 剔除低频词,生成id到word、word到id的映射
self.input_file = open(self.input_file_name, encoding="utf-8")
self.sentence_length = 0
self.sentence_count = 0
word_frequency = dict()
for line in self.input_file:
self.sentence_count += 1
line = line.strip().split(' ') # strip()去除首尾空格,split(' ')按空格划分词
self.sentence_length += len(line)
for w in line:
try:
word_frequency[w] += 1
except:
word_frequency[w] = 1
self.word2id = dict()
self.id2word = dict()
wid = 0
self.word_frequency = dict()
for w, c in word_frequency.items(): # items()以列表返回字典(键, 值)
if c < min_count:
self.sentence_length -= c
continue
self.word2id[w] = wid
self.id2word[wid] = w
self.word_frequency[wid] = c
wid += 1
self.word_count = len(self.word2id)
def subsampling(self, corpus, word2id_freq): # 使用二次采样算法(subsampling)处理语料,强化训练效果
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-5 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
def init_sample_table(self): # 获得负样本采样表
self.sample_table = []
sample_table_size = 1e8 # 10*8
pow_frequency = numpy.array(list(self.word_frequency.values())) ** 0.75 # 采样公式
words_pow = sum(pow_frequency) # 求和获得归一化参数Z
ratio = pow_frequency / words_pow
count = numpy.round(ratio * sample_table_size) # round四舍五入,得到每个词的出现次数
for wid, c in enumerate(count): # 按采样频率估计的次数将词放入词表
self.sample_table += [wid] * int(c)
self.sample_table = numpy.array(self.sample_table)
numpy.random.shuffle(self.sample_table) # 打乱采样表
# self.sample_table = self.subsampling(self.sample_table,self.word_frequency) # 重采样
def get_batch_pairs(self, batch_size, window_size): # 获取正样本
while len(self.word_pair_catch) < batch_size: # 当队列中数据个数小于batch_size, 向队列添加数据
sentence = self.input_file.readline()
if sentence is None or sentence == '':
self.input_file = open(self.input_file_name, encoding="utf-8")
sentence = self.input_file.readline()
word_ids = []
for word in sentence.strip().split(' '):
try:
word_ids.append(self.word2id[word]) # 获取中心词
except:
continue
for i, u in enumerate(word_ids): # 按窗口依次取不同的id对
for j, v in enumerate(
word_ids[max(i - window_size, 0):i + window_size]): # 获取周围词
assert u < self.word_count
assert v < self.word_count
if i == j: # 上下文词=中心词 跳过
continue
self.word_pair_catch.append((u, v)) # 将正样本对(u, v)加入队列
batch_pairs = []
for _ in range(batch_size): # 返回batch大小的正采样对
batch_pairs.append(self.word_pair_catch.popleft()) # popleft()左出
return batch_pairs
def get_neg_v_neg_sampling(self, pos_word_pair, count): # 获取负样本
neg_v = numpy.random.choice( # 有选择的随机
self.sample_table, size=(len(pos_word_pair), count)).tolist()
return neg_v
def evaluate_pair_count(self, window_size): # 估计数据中正采样对数,用于设定batch
return self.sentence_length * (2 * window_size - 1) - (
self.sentence_count - 1) * (1 + window_size) * window_size
skip-gram词向量训练代码:
#encoding=gbk
from input_data import InputData
from skip_gram import SkipGramModel
from torch.autograd import Variable
import torch
import torch.optim as optim
from tqdm import tqdm
from gensim import utils
import matplotlib.pyplot as plt
loss_list=[]
class Word2Vec(utils.SaveLoad):
def __init__(self,
input_file_name,
output_file_name,
emb_dimension=100, # 词嵌入维度
batch_size=50, # 批处理批次大小
window_size=50, # 上下文窗口
iteration=1,
initial_lr=0.025,
k=5, # 负采样数
min_count=15): # 设定低频词出现次数
self.data = InputData(input_file_name, min_count)
self.output_file_name = output_file_name
self.emb_size = len(self.data.word2id) # 词的数量
self.emb_dimension = emb_dimension
self.batch_size = batch_size
self.window_size = window_size
self.iteration = iteration
self.initial_lr = initial_lr
self.k = k
self.skip_gram_model = SkipGramModel(self.emb_size, self.emb_dimension)
self.use_cuda = torch.cuda.is_available()
if self.use_cuda:
self.skip_gram_model.cuda()
self.optimizer = optim.SGD(self.skip_gram_model.parameters(), lr=self.initial_lr)
def train(self):
pair_count = self.data.evaluate_pair_count(self.window_size) # 样本对数量
batch_count = self.iteration * pair_count / self.batch_size # 批次数量
process_bar = tqdm(range(int(batch_count))) # 进度条
for i in process_bar:
pos_pairs = self.data.get_batch_pairs(self.batch_size, self.window_size) # 获取正样本
neg_v = self.data.get_neg_v_neg_sampling(pos_pairs, self.k) # 获取负样本
pos_u = [pair[0] for pair in pos_pairs]
pos_v = [pair[1] for pair in pos_pairs]
# 传入参数以进行反向传播
pos_u = Variable(torch.LongTensor(pos_u))
pos_v = Variable(torch.LongTensor(pos_v))
neg_v = Variable(torch.LongTensor(neg_v))
if self.use_cuda:
pos_u = pos_u.cuda()
pos_v = pos_v.cuda()
neg_v = neg_v.cuda()
self.optimizer.zero_grad() # 初始化0梯度
loss = self.skip_gram_model.forward(pos_u, pos_v, neg_v) # 正向传播
loss.backward() # 反向传播
self.optimizer.step() # 优化目标函数
process_bar.set_description("Loss: %0.8f, lr: %0.6f" % (loss.data.item(),
self.optimizer.param_groups[0]['lr']))
loss_list.append(loss.data.item())
if i * self.batch_size % 100000 == 0: # 动态更新学习率
lr = self.initial_lr * (1.0 - 1.0 * i / batch_count)
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
plt.plot(loss_list,label='sp-skg-loss')
plt.legend()
plt.title('loss-epoch')
plt.show()
self.skip_gram_model.save_embedding( # 保存词向量
self.data.id2word, self.output_file_name, self.use_cuda)
def save(self, *args, **kwargs): # 保存模型
super(Word2Vec, self).save(*args, **kwargs)
if __name__ == '__main__':
w2v = Word2Vec(r"D:\data\1018\word2vecdata_p.txt", r"D:\data\1018\skipgram_e.txt")
w2v.train()
这里附上我们的训练loss曲线图:


四、使用训练好的词向量替换TextCNN模型初始词向量,并应用于文本分类任务
在进行词向量替换之前,我们需要先加载词向量,代码如下:
#encoding=gbk
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
def get_dict():
f1 = open(r'D:\data\1018\cbow_emb_sp.txt', 'r', encoding='utf-8', errors='ignore')
lines=f1.readlines()
f1.close()
word_to_em_dict={}
for line in lines:
#print(line)
li=line.split()
print(li)
data=[ float(i) for i in li[1:]]
word_to_em_dict[li[0]]=torch.FloatTensor(data)
print(word_to_em_dict)
return word_to_em_dict
最后就是我们的TextCNN模型训练代码:
#coding=gbk
from cgi import test
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3, 4,5"
from get_embeding import get_dict
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from get_data import get_data
dtype = torch.FloatTensor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 3 words sentences (=sequence_length is 3)
import matplotlib.pyplot as plt
sentences,labels,setences_test,label_test=get_data()
print(sentences,labels)
#sentences = ["i love you", "he loves me", "she likes baseball", "i hate you", "sorry for that", "this is awful"]
#labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
num_classes = len(set(labels))
classnum=3
embedding_size = 100
batch_size = 10
sequence_length = 50
epochs=50
word_list = " ".join(sentences).split()
word_list2 = " ".join(setences_test).split()
vocab = list(set(word_list+word_list2))
word2idx = {w:i for i,w in enumerate(vocab)}
idx2word = {i:w for i,w in enumerate(vocab)}
vocab_size = len(vocab)
def make_data(sentences, labels):
inputs = []
for sen in sentences:
l=[word2idx[n] for n in sen.split()]
if len(l)<sequence_length:
length=len(l)
for i in range(sequence_length-length):
l.append(0)
inputs.append(l)
else:
inputs.append(l[0:sequence_length])
targets = []
for out in labels:
targets.append(out)
return inputs, targets
input_batch, target_batch = make_data(sentences, labels)
print(input_batch, target_batch)
input_batch= torch.LongTensor(input_batch)
target_batch= torch.LongTensor(target_batch)
print("*"*100)
print(input_batch.size(),target_batch.size())
dataset = Data.TensorDataset(input_batch,target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
word_to_em_dict=get_dict()
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
self.W = nn.Embedding(vocab_size, embedding_size)
output_channel = 3
self.conv = nn.Sequential(nn.Conv2d(1, output_channel, kernel_size=(10,embedding_size)), # inpu_channel, output_channel, 卷积核高和宽 n-gram 和 embedding_size
nn.ReLU(),
nn.MaxPool2d((10,1)))
self.fc = nn.Linear(12,num_classes)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
embedding_X = self.W(X) # [batch_size, sequence_length, embedding_size]
# print(X.size(),embedding_X.size())
p1=0
temp_emb=torch.zeros(batch_size, sequence_length, embedding_size)
for secequence in X:
p2=0
for id in secequence:
word=idx2word[int(id)]
# print(word)
try:
emd=word_to_em_dict[word]
except:
# print(word)
emd=torch.zeros(embedding_size)
# print(emd)
# print(emd.size())
temp_emb[p1][p2]=emd
p2=p2+1
p1=p1+1
embedding_X = temp_emb.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
conved = self.conv(embedding_X) # [batch_size, output_channel,1,1]
flatten = conved.view(batch_size, -1)# [batch_size, output_channel*1*1]
output = self.fc(flatten)
return output
model = TextCNN().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
loss_list=[]
# Training
for epoch in range(epochs):
loss_add=0
count=0
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
# print("pred,batch_y",pred,batch_y)
loss = criterion(pred, batch_y)
loss_add=loss_add+loss
count=count+1
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (epoch + 1) % 5 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
loss_list.append(loss_add/count)
#test
input_batch, target_batch = make_data(setences_test, label_test)
input_batch= torch.LongTensor(input_batch)
target_batch= torch.LongTensor(target_batch)
print("*"*100)
dataset = Data.TensorDataset(input_batch,target_batch)
loader = Data.DataLoader(dataset, batch_size, True)
test_loss = 0
correct = 0
total = 0
target_num = torch.zeros((1,classnum))
predict_num = torch.zeros((1,classnum))
acc_num = torch.zeros((1,classnum))
for batch_x, batch_y in loader:
batch_x, batch_y = batch_x.to(device), batch_y.to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
test_loss += loss
_, predicted = torch.max(pred.data, 1)
total += batch_y.size(0)
correct += predicted.eq(batch_y.data).cpu().sum()
pre_mask = torch.zeros(pred.size()).scatter_(1, predicted.cpu().view(-1, 1), 1.)
predict_num += pre_mask.sum(0)
tar_mask = torch.zeros(pred.size()).scatter_(1, batch_y.data.cpu().view(-1, 1), 1.)
target_num += tar_mask.sum(0)
acc_mask = pre_mask*tar_mask
acc_num += acc_mask.sum(0)
recall = acc_num/target_num
precision = acc_num/predict_num
F1 = 2*recall*precision/(recall+precision)
accuracy = acc_num.sum(1)/target_num.sum(1)
recall = (recall.numpy()[0]*100).round(3)
precision = (precision.numpy()[0]*100).round(3)
F1 = (F1.numpy()[0]*100).round(3)
accuracy = (accuracy.numpy()[0]*100).round(3)
# 打印格式方便复制
p=sum(precision)/3
r=sum(recall)/3
F=sum(F1)/3
print('recall:',r)
print('precision:',p)
print('F1:',F)
print('accuracy',accuracy)
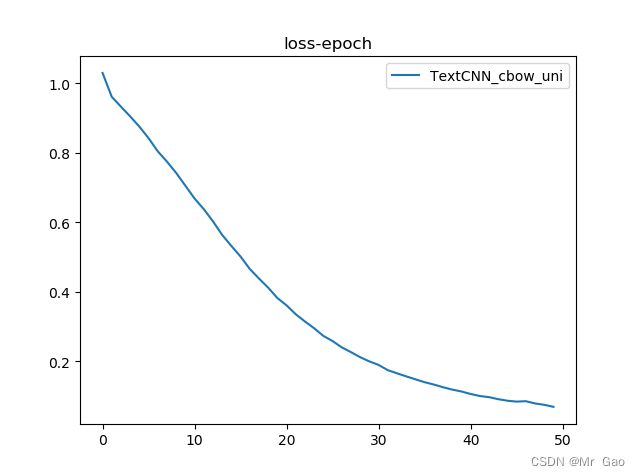
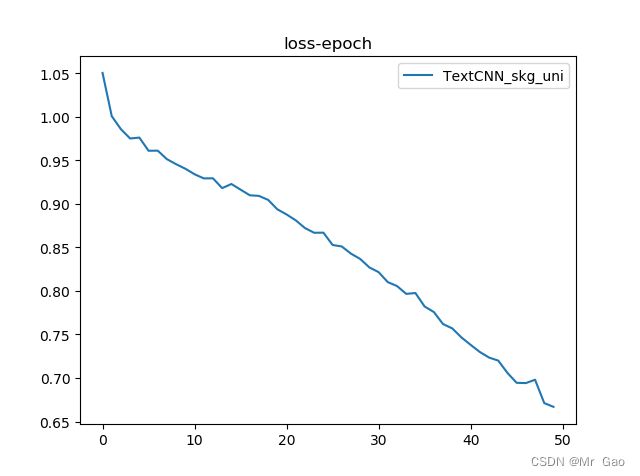
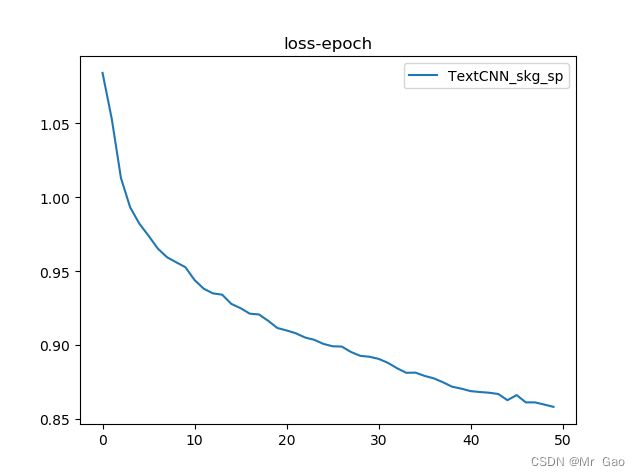
plt.plot(loss_list,label='TextCNN_sp')##########
plt.legend()
plt.title('loss-epoch')
plt.show()
这里附上我们的loss曲线图: