牛客网面试必刷算法题TOP101刷题记录(一)
牛客网在线编程_算法篇_面试必刷TOP101
链表
JZ6 从尾到头打印链表(简单)
题目描述:

思路1(非递归,通过)
从头到尾遍历,边遍历边存进栈,最后从栈弹出来打印。时间复杂度O(n),空间复杂度O(n)
public ArrayList printListFromTailToHead(ListNode listNode) {
ArrayList list = new ArrayList();
Stack stack = new Stack();
ListNode p = listNode;
while(p!=null){
stack.push(p.val);
p = p.next;
}
while(!stack.empty()){
list.add((Integer) stack.peek());
stack.pop();
}
return list;
} 思路一,通过。

思路2(递归,栈内存溢出)
递归打印,不是空则传入next递归,当从下一层返回时说明当前节点后面的节点内容全部打印完,所以把当前节点值加入结果列表。时间复杂度O(n),空间复杂度O(n)
import java.util.ArrayList;
public class Solution {
ArrayList list = new ArrayList();
public ArrayList printListFromTailToHead(ListNode listNode) {
if(listNode!=null){
printListFromTailToHead(listNode.next);
list.add(listNode.val);
}
return list;
}
} 思路2的代码跑起来栈内存溢出 Exception in thread "main" java.lang.StackOverflowError
JZ24 反转链表
题目描述

思路1(通过)

public ListNode ReverseList(ListNode head) {
if(head==null) return null;
ListNode p = head.next;
ListNode newHead = head;
head.next = null;
while(p!=null){
ListNode q = p.next;
p.next = newHead;
newHead = p;
p = q;
}
return newHead;
}
JZ25 合并两个排序的链表
题目描述

思路1
用一个新节点做新链表表头,两个指针分别遍历两条链表,取两个指针中小的一个链接到新链表表尾,重置新链表表尾指针、被链接到新链表的那个指针后移,直至其中一个指针到达链表尾,将还未到链表尾的那条链表直接链接到新链表上。
public class Solution {
public ListNode Merge(ListNode list1,ListNode list2) {
ListNode p=list1,q=list2;
//用一个新节点做新链表表头
ListNode newHead = new ListNode(0);
//r用来表示新链表表尾
ListNode r = newHead;
while(p!=null && q!=null){
//取其中较小值链接到新链表,被选中的那个指针需要后移
if(p.val<=q.val){
r.next = new ListNode(p.val);
p = p.next;
}else{
r.next = new ListNode(q.val);
q = q.next;
}
//更新新链表尾指针
r = r.next;
}
if(q!=null) p=q;
//把未遍历到尾的长链表剩下节点全部接到新链表尾
while(p!=null){
r.next = new ListNode(p.val);
p = p.next;
r = r.next;
}
return newHead.next;
}
}BM2 链表内指定区间反转 (中等)
描述
将一个节点数为 size 链表 m 位置到 n 位置之间的区间反转,要求时间复杂度 O(n),空间复杂度 O(1)。
例如:
给出的链表为 1→2→3→4→5→null m=2,n=4
返回 1→4→3→2→5→NULL.
要求:时间复杂度 O(n) ,空间复杂度 O(n)
思路
找出第m个位置节点start、第n个位置节点end,记录下start前一个节点preStart、end的后一个节点afterEnd。和反转链表一样思路,将start卸下来,把这段反转,最后将反转后链表的头接在preStart后,反转后链表的尾接上afterEnd。
以上思路需要至少四个节点,需要处理的边界情况包括(1)要反转的指定区间是原链表尾(afterEnd==null)(2)要反转的指定区间是原链表头(preStart==null)(3)反转区间是整个链表三种特殊情况(afterEnd==null && preStart==null)。这三种特殊情况如果不处理会出现越界的情况。
代码
public ListNode reverseBetween (ListNode head, int m, int n) {
// write code here
if(m==n){
return head;
}
ListNode start = findNNode(m,head);
ListNode preStart = findNNode(m-1,head);
ListNode end = findNNode(n,head);
ListNode afterEnd = findNNode(n+1,head);
ListNode newHead = start;
ListNode p = start.next;
start.next = null;
while(p!=afterEnd && p!=null){
ListNode q = p.next;
p.next = newHead;
newHead = p;
p = q;
}
if(afterEnd==null && preStart==null){
return newHead;
}else if(preStart==null){
start.next = afterEnd;
return newHead;
}else if(afterEnd==null){
preStart.next = end;
return head;
}else{
preStart.next = newHead;
start.next = afterEnd;
return head;
}
}
public ListNode findNNode(int n,ListNode head){
if(head==null || n==0) return null;
int count = 1;
ListNode p=head;
while(count < n){
p = p.next;
count++;
}
return p;
}时间复杂度 O(n) 空间复杂度O(1)

BM3 链表中的节点每k个一组翻转
描述
将给出的链表中的节点每 k 个一组翻转,返回翻转后的链表
如果链表中的节点数不是 k 的倍数,将最后剩下的节点保持原样
你不能更改节点中的值,只能更改节点本身。
数据范围: 0≤n≤2000 , 1≤k≤2000 ,链表中每个元素都满足 0≤val≤1000
要求空间复杂度O(1),时间复杂度 O(n)
例如:
给定的链表是 1→2→3→4→5
对于 k=2 , 你应该返回 2→1→4→3→5
对于 k=3 , 你应该返回 3→2→1→4→5
思路
写一个反转(ListNode start,ListNode end)的函数,不断更新start和end,将start到end区间链表取下来,使用该函数进行反转。
使用newHead标识新链表头,值取第一次反转后的队头,即第一次的end(默认值为head,用于整个不能整除的情况)。
使用tail标识新链表尾,用于不断衔接新区间。
start初始值为head,当start不为空时循环:通过累加到k寻找end,在移动end之前需要将最初的end.next备份。1)如果中途end为null,说明剩余的节点数不是k的倍数且是最后一组,直接将start接到tail后面,返回newHead。2)否则将链表取下、反转、将反转后的链表接在tail后,并将tail更新为start(反转后链表的尾巴,即原来的头),更新start为原end.next。第一组的话,还需要给newHead赋初始值-第一次的end。
如果end为null,说明已经到最后一组了,直接将start接在队尾,返回new Head。
否则直接返回new Head。
代码
import java.util.*;
/*
* public class ListNode {
* int val;
* ListNode next = null;
* public ListNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param head ListNode类
* @param k int整型
* @return ListNode类
*/
public ListNode reverseKGroup (ListNode head, int k) {
if(head==null) return null;
ListNode start = head;
ListNode end = start;
//标记队尾,用来将各组连起来
ListNode tail = new ListNode(-1);
//标记队头,用于最后返回结果
ListNode newHead = head;
int time = 0;
while (start != null) {
//将要反转的链表左侧断开
tail.next = null;
//寻找反转链表右侧终点
end = start;
int count = 1;
while (count < k) {
end = end.next;
count++;
//如果节点数不能被整除,直接将这段接到链表尾
if (end == null) {
//不能整除说明到了最后一段,将start接到队尾
tail.next = start;
return newHead;
}
}
//否则,继续连接反转链表
//队头元素应该是第一组反转后的队头
if(time==0){
newHead = end;
time++;
}
ListNode p = end.next;
//将要反转的链表右侧断开
end.next = null;
//新反转的链表接到上一组后面
tail.next = reverseLink(start, end);
//队尾变为此次队尾,因为是反转后的,所以就是start
tail = start;
//上一组尾后元素作为下一组起点
start = p;
}
return newHead;
}
public ListNode reverseLink(ListNode start, ListNode end) {
ListNode p = start;
ListNode newHead = new ListNode(-1);
while (p != null) {
ListNode q = p.next;
p.next = newHead;
newHead = p;
p = q;
}
start.next = null;
return end;
}
}BM5 合并k个已排序的链表
描述
合并 k 个升序的链表并将结果作为一个升序的链表返回其头节点。
数据范围:节点总数 0≤n≤5000,每个节点的val满足 ∣val∣<=1000
要求:时间复杂度O(nlogn)
输入:
[{1,2,3},{4,5,6,7}]
返回值:
{1,2,3,4,5,6,7}
输入:
[{1,2},{1,4,5},{6}]
返回值:
{1,1,2,4,5,6}
思路
用长度为k的列表保存指向每条链表的指针。
遍历列表,比较各个指针对应值,得到值最小的节点、最小节点值、最小节点的后一个节点(将该节点摘下来会损失后继信息,所以需要提前备份)。将最小节点摘出来、接到新链表尾、更新新链表表尾指针、替换列表中该指针位置(替换为提前备份的该指针向后移动一位)。结束循环的条件是列表中全部为null,即所有链表均已到达队尾。
代码
public static ListNode mergeKLists (ArrayList lists) {
ArrayList pointList = new ArrayList<>();
ListNode newHead = null;
ListNode tail = new ListNode(-1);
//初始指针放在各链表头
for (int i = 0; i < lists.size(); i++) {
pointList.add(lists.get(i));
}
while (!isAllNull(pointList)) {
ListNode minPoint = new ListNode(Integer.MAX_VALUE);
ListNode minNext = null;
int minValue = Integer.MAX_VALUE;
int minIndex = 0;
//寻找最小值节点
for (int i = 0; i < pointList.size(); i++) {
if (pointList.get(i) != null && pointList.get(i).val < minValue) {
minPoint = pointList.get(i);
minValue = pointList.get(i).val;
minNext = minPoint.next;
minIndex = i;
}
}
if (newHead == null) {
newHead = minPoint;
}
minPoint.next = null;
tail.next = minPoint;
tail = minPoint;
pointList.set(minIndex, minNext);
}
return newHead;
}
public static Boolean isAllNull(ArrayList lists) {
for (int i = 0; i < lists.size(); i++) {
if (lists.get(i) != null) {
return false;
}
}
return true;
} BM6 判断链表中是否有环
描述
判断给定的链表中是否有环。如果有环则返回true,否则返回false。
数据范围:链表长度 0≤n≤10000,链表中任意节点的值满足∣val∣<=100000
要求:空间复杂度 O(1),时间复杂度 O(n)
思路
快慢指针同时从链表头开始移动,慢指针每次移动一步,快指针每次移动两步,快指针为空或者快指针.next为空时说明遍历完链表,循环结束。
代码
public boolean hasCycle(ListNode head) {
ListNode slow = head;
ListNode qucik = head;
while(qucik!=null && qucik.next!=null){
slow = slow.next;
qucik = qucik.next.next;
if(slow==qucik){
return true;
}
}
return false;
}BM7 链表中环的入口结点
描述
给一个长度为n链表,若其中包含环,请找出该链表的环的入口结点,否则,返回null。
思路

根据上一道题,我们已经掌握了判断链表是否有环的方法,在此方法中我们通过找到第一个快慢指针重叠的点来判断链表是否有环,将我们上一题找到的相遇点设为C。设链表头到环入口距离为x,环入口到相遇点距离为y,相遇点顺时针到环入口的距离为z(即环长-y)。
假设上一题快慢指针在相遇点C相遇时,快指针在环中已经走了m圈,慢指针在环中已经走了n圈。那么此时快指针走过的路径长为:x+m(y+z)+y
慢指针走过的路径长为:x+n(y+z)+y
因为快指针每次走两步,慢指针每次走一步,所以快指针走的路径长应该是慢指针的两倍。
即 x+m(y+z)+y = 2(x+n(y+z)+y)
等号右侧减去等号左侧可以得到:x+y = (m-2n)(y+z)
即x+y是整数倍的环长。
那么可以设想一下:当快慢指针在相遇点C相遇后,就把快指针移动回链表头,再让快指针、慢指针都每次走一步,那么当快指针移动了x+y到达相遇点C时,慢指针应该也到达相遇点C,这时候两个指针会再次在相遇点C相遇。
而因为重新走的这次快慢指针都是每次走一步,所以如果确定他们在C点相遇的话,那么从环起点到相遇点C这段路径,两个指针也应该是重叠着走过的。也就是说两个指针将最早在环入口相遇。
所以只要按照这样的方式去实现,找到最早相遇点就找到环入口了。
代码
public ListNode EntryNodeOfLoop(ListNode pHead) {
ListNode slow = pHead;
ListNode qucik = pHead;
while (qucik != null && qucik.next != null) {
slow = slow.next;
qucik = qucik.next.next;
if (slow == qucik) {
break;
}
}
if (qucik == null || qucik.next == null) {
return null;
} else {
qucik = pHead;
while (qucik != slow) {
qucik = qucik.next;
slow = slow.next;
}
return qucik;
}
}BM8 链表中倒数最后k个结点
描述
输入一个长度为 n 的链表,设链表中的元素的值为 ai ,返回该链表中倒数第k个节点。
如果该链表长度小于k,请返回一个长度为 0 的链表。
思路
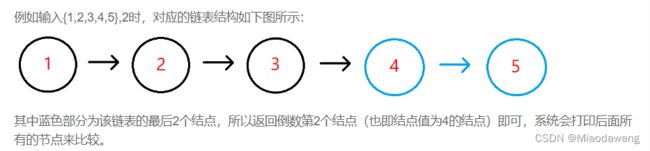
p指针走k步时将q指针放链表头,p指针和q指针同时移动,当p指针为null时q指针所指的即是倒数第k个。
每次对累计值count++判断是否小于k,小于k时候p移动,等于k时候给q赋值,并count++(不加的话后面每次都count==k,一直进这个分支出不去),大于k时p、q一起移动。需要注意的是链表长度小于k的情况,对这种情况的处理是:1)在小于k分支中再判断p是否为null,是的话说明链表长度小于k,直接返回null。2)特殊情况k和链表长相等时找到p已经是null了,导致退出了循环,所以加一个count==k时返回q
代码
public ListNode FindKthToTail (ListNode pHead, int k) {
int count = 0;
ListNode p = pHead;
ListNode q = null;
while(p!=null){
if(countk){
p = p.next;
q = q.next;
}
if(p!=null)
System.out.println("p.val:"+p.val);
if(q!=null)
System.out.println("q.val:"+q.val);
System.out.println("count:"+count);
}
if(count==k){
return pHead;
}
return q;
} JZ76 删除链表中重复的结点
描述
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表 1->2->3->3->4->4->5 处理后为 1->2->5
数据范围:链表长度满足 0≤n≤1000 ,链表中的值满足 1≤val≤1000
进阶:空间复杂度 O(n) ,时间复杂度 O(n)
思路
很简单,两次遍历,一次遍历将是否重复的结果写入hashMap(类型为
代码
public ListNode deleteDuplication(ListNode pHead) {
HashMap hashMap = new HashMap<>();
ListNode p = pHead;
while(p!=null){
if(!hashMap.containsKey(p.val)){
hashMap.put(p.val,true);
}else{
hashMap.put(p.val,false);
}
p = p.next;
}
for(Integer i:hashMap.keySet()){
System.out.println("key:"+i+"val:"+hashMap.get(i));
}
p = pHead;
ListNode newHead = new ListNode(-1);
newHead.next = pHead;
ListNode tail = newHead;
tail.next = null;
while(p!=null){
if(hashMap.get(p.val)){
tail.next = p;
tail = p;
System.out.println(tail.val);
}
p = p.next;
}
tail.next = null;
return newHead.next;
} JZ18 删除链表的节点
描述
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
1.此题对比原题有改动
2.题目保证链表中节点的值互不相同
3.该题只会输出返回的链表和结果做对比,所以若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
思路
和上道题差不多,直接对比每个值是不是目标值,不是则加到链表,是则跳过。
代码
public ListNode deleteNode (ListNode head, int val) {
ListNode newHead = new ListNode(-1);
ListNode tail = newHead;
newHead.next = tail;
tail.next = null;
ListNode p = head;
while(p!=null){
if(p.val!=val){
tail.next = p;
tail = p;
}
p = p.next;
}
return newHead.next;
}JZ52 两个链表的第一个公共结点
描述
输入两个无环的单向链表,找出它们的第一个公共结点,如果没有公共节点则返回空。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)
思路
先遍历两个链表得到两个链表长度,将链表对齐,即长链表先走链表差值的步数后再开始遍历短链表。
代码
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
ListNode shortList = pHead1;
ListNode longList = pHead2;
int len1 = 0;
int len2 = 0;
int start = 0;
while(shortList!=null){
len1++;
shortList = shortList.next;
}
while(longList!=null){
len2++;
longList = longList.next;
}
if(len1>len2){
shortList = pHead2;
longList = pHead1;
start = len1-len2;
System.out.println(start);
}else{
shortList = pHead1;
longList = pHead2;
start = len2-len1;
System.out.println(start);
}
int i =0;
while(shortList!=null && longList!=null){
while(iBM11 链表相加(二)
描述
假设链表中每一个节点的值都在 0 - 9 之间,那么链表整体就可以代表一个整数。
给定两个这种链表,请生成代表两个整数相加值的结果链表。
数据范围:0≤n,m≤1000000,链表任意值 0≤val≤9
要求:空间复杂度O(n),时间复杂度 O(n)
例如:链表 1 为 9->3->7,链表 2 为 6->3,最后生成新的结果链表为 1->0->0->0。
代码
public ListNode addInList (ListNode head1, ListNode head2) {
ListNode newHead = null;
int high = 0;
int cur = 0;
//先反转两个链表.反转链表1
ListNode tail1 = null;
ListNode p1 = head1;
while (p1 != null) {
ListNode q = p1.next;
p1.next = tail1;
tail1 = p1;
p1 = q;
}
//先反转两个链表,反转链表2
ListNode tail2 = null;
ListNode p2 = head2;
while (p2 != null) {
ListNode q = p2.next;
p2.next = tail2;
tail2 = p2;
p2 = q;
}
// //打印反转结果检查
// ListNode out1 = tail1;
// ListNode out2 = tail2;
// while(out1!=null){
// System.out.print("->"+out1.val);
// out1 = out1.next;
// }
// System.out.println("");
// while(out2!=null){
// System.out.print("->"+out2.val);
// out2 = out2.next;
// }
ListNode p = tail1;
ListNode q = tail2;
while (p != null && q != null) {
System.out.print("p.val->" + p.val);
System.out.print("q.val->" + q.val);
System.out.println("");
cur = (p.val + q.val + high) % 10;
if (p.val + q.val + high >= 10) {
high = 1;
} else {
high = 0;
}
System.out.print("cur->" + cur);
ListNode node = new ListNode(cur);
node.next = newHead;
newHead = node;
p = p.next;
q = q.next;
System.out.println("high:"+high);
}
if (p != null) {
q = p;
}
while (q != null) {
cur = (q.val + high) % 10;
if (q.val + high >= 10) {
high = 1;
} else {
high = 0;
}
System.out.println("high:"+high);
ListNode node = new ListNode(cur);
node.next = newHead;
newHead = node;
q = q.next;
}
if (high != 0) {
ListNode node = new ListNode(1);
node.next = newHead;
newHead = node;
}
return newHead;
}BM12 单链表的排序
描述
给定一个节点数为n的无序单链表,对其按升序排序。
数据范围:0 要求:空间复杂度 O(n),时间复杂度O(nlogn) 遍历一遍链表存进数组,用Collections.sort对数组进行排序,然后遍历数组新建链表 给定一个链表,请判断该链表是否为回文结构。 回文是指该字符串正序逆序完全一致。 数据范围: 链表节点数 0≤n≤105,链表中每个节点的值满足∣val∣≤107 先正向遍历一遍存进数组,指针重新指向链表头。 数组倒序输出,如果不同则返回false 循环条件为指针不是null或者数组下标>=0,循环结束则返回true 给定一个单链表,请设定一个函数,将链表的奇数位节点和偶数位节点分别放在一起,重排后输出。 注意是节点的编号而非节点的数值。 数据范围:节点数量满足 0≤n≤105,节点中的值都满足 0≤val≤1000 要求:空间复杂度 O(n),时间复杂度 O(n) 用指针p遍历链表,指针newHead、tail重建链表。 p是从第一个节点(奇数个)开始遍历的,遍历到一个节点时就将p的下一个节点(偶数个)拆下来并插到新链表上,然后p指针直接跳过被拆下的那个节点指向它本来的下下个节点,将整体过程完成后。(注意循环结束条件是p!=null&&p.next!=null) 最后把p复位到head,移动到最末端节点,将两个链表合起来。 删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次 数据范围:链表长度满足 0≤n≤100,链表中任意节点的值满足 ∣val∣≤100 进阶:空间复杂度 O(1),时间复杂度 O(n) 空间复杂度 O(n),时间复杂度 O(n) 遍历一遍链表,用hashmap记录每个值出现的次数 再遍历一遍链表,次数大于1的加入到新链表并将次数改为0,次数等于1的加入新链表。 时间复杂度O(n),空间复杂度O(1) 双指针,一个指针放在前一位,一个指针一直向后遍历找到第一个与前面的指针不同的值,越过中间相同的这些值。需要处理的特殊情况是{1,2,4,4}这种情况,处理方法是遍历的那个后指针在找不同值过程中为null则说明是重复序列在链表尾的这种特殊情况,这种情况之前令前指针next为null,返回即可。 给出一个升序排序的链表,删除链表中的所有重复出现的元素,只保留原链表中只出现一次的元素。 数据范围:链表长度 0≤n≤10000,链表中的值满足 ∣val∣≤1000 要求:空间复杂度O(n),时间复杂度O(n) 进阶:空间复杂度 O(1),时间复杂度O(n) 遍历一遍链表将值与是否重复存入到hashmap,再次遍历链表,使用不重复的节点值重建链表 给定一个链表,删除链表的倒数第 n 个节点并返回链表的头指针 给出的链表为: 1→2→3→4→51→2→3→4→5, n=2. 数据范围: 链表长度 0≤n≤1000,链表中任意节点的值满足0≤val≤100 要求:空间复杂度 O(1),时间复杂度O(n) 题目保证 n 一定是有效的 已知当遍历指针p走到第n个节点时将新指针q指向指针头,那么当指针p走到最后一个节点(p.next==null)l时指针q应该刚好指向倒数第n个节点。 实现方法为使用count记录步数,当count 其中一种特殊状况是,当p走到最后一个指针时count刚好等于n,此时因为p.next==null不会进入循环,pre和q都来得及初始化。因此增加一个对此种特殊情况的判定,对这种情况直接返回head.next。 对普通情况,直接将pre.next置为q.next,就可以将q节点删除掉,返回原链表head。 给定一个二叉树其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的next指针。下图为一棵有9个节点的二叉树。树中从父节点指向子节点的指针用实线表示,从子节点指向父节点的用虚线表示 输入:{8,6,10,5,7,9,11},8 返回:9 解析:这个组装传入的子树根节点,其实就是整颗树,中序遍历{5,6,7,8,9,10,11},根节点8的下一个节点就是9,应该返回{9,10,11},后台只打印子树的下一个节点,所以只会打印9,如下图,其实都有指向左右孩子的指针,还有指向父节点的指针,下图没有画出来 1.如果右子树不为空,输出其右子树的最左端 2.如果右子树为空,当前为父亲的左子树,输出其父亲 3.如果右子树为空,当前为父亲的右子树,重复循环,直到父亲的父亲...父亲为空:跳到父亲的父亲,判断父亲是否为其左子树,如果是输出其父亲的父亲,否则继续向上找。 输入一棵二叉树,求该树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度,根节点的深度视为 1 。 数据范围:节点的数量满足0≤n≤100 ,节点上的值满足 0≤val≤100 进阶:空间复杂度 O(1) ,时间复杂度 O(n) 假如输入的用例为{1,2,3,4,5,#,6,#,#,7},那么如下图: 输入: 复制 返回值: 递归 给定一个二叉树,返回该二叉树的之字形层序遍历,(第一层从左向右,下一层从右向左,一直这样交替) 数据范围:0≤n≤1500,树上每个节点的val满足 ∣val∣<=1500 例如: 该二叉树之字形层序遍历的结果是 [ [1], [3,2], [4,5] ] 使用列表实现二维数组,每一行是一层的节点,根据上一层节点得到下一层节点。 首先判断根节点是否为空,不为空的话将根节点加入到结果列表第一行。接着从第一行开始从该行(第i行)的尾部开始使用数字j对第i行进行遍历,如果i+1行是从左往右的就将该节点的左右子树依次加入到i+1行列表中,否则将该节点的右左子树依次加入到i+1行列表。使用Boolean类型值left标注i+1行是从左往右还是从右往左,每当遍历完一行(退出j循环,新一次i循环时)改变left值。 需要注意的是,ArrayList每次取arr[i][j]之前都需要先初始化一个列表放在第i行,否则会指针越界错误,而且要注意该列表的作用域。 使用result保存结果 使用一个[treenode,depth]的列表先将各层节点和其深度存起来,得到如下方的列表 [(3,0),(9,1),(20,1),(15,2),(7,2)] 接着遍历该列表 如果result.size和该节点的depth相同,说明该节点是该层第一个节点,新建列表,将该节点值加入列表,再将列表加入到result。如果不同,则说明该节点不是第一个节点,直接获取result.get(node.depth) 如果是偶数行是从左向右,直接add,如果是奇数行,add(0,val) 给定一棵结点数为n 二叉搜索树,请找出其中的第 k 小的TreeNode结点值。 1.返回第k小的节点值即可 2.不能查找的情况,如二叉树为空,则返回-1,或者k大于n等等,也返回-1 3.保证n个节点的值不一样 数据范围: 0≤n≤1000,0≤k≤1000,树上每个结点的值满足0≤val≤1000 递归中序遍历树,得到第k-1个元素,注意对题中所说的非法情况的处理。 输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则返回 true ,否则返回 false 。假设输入的数组的任意两个数字都互不相同。 最后一个为root,小于root值那一段为左子树,这段里不能出现大于root值的数字,大于root值的那一段为右子树,这段不能出现小于root值的数字,递归判断左子树及右子树,序列长度为0或1则返回true,因为规定空序列为false,无法区分这种情况,所以分成两个函数。 给定一个二叉树,返回该二叉树层序遍历的结果,(从左到右,一层一层地遍历) 给定的二叉树是{3,9,20,#,#,15,7}, 该二叉树层序遍历的结果是 ] 使用一个[treenode,depth]的列表先将各层节点和其深度存起来,得到如下方的列表 [(3,0),(9,1),(20,1),(15,2),(7,2)] 类似层次遍历输出一维数组,一边新增尾节点一边删除头节点,直到该列表为空 首先取首个元素,查看result尺寸是否小于等于depth,如果小于说明该元素是这层首个节点,需要创建一个list,将当前节点值加入list,并将list加入到二维列表;否则直接取list.get(depth)这个子列表,将当前节点值加入该列表。 定一个二叉树根节点,请你判断这棵树是不是二叉搜索树。 二叉搜索树满足每个节点的左子树上的所有节点均小于当前节点且右子树上的所有节点均大于当前节点。 中序遍历二叉树得到中序遍历序列,如果该序列单调递增说明是二叉搜索树,否则不是。 给定一个二叉树,确定他是否是一个完全二叉树。 完全二叉树的定义:若二叉树的深度为 h,除第 h 层外,其它各层的结点数都达到最大个数,第 h 层所有的叶子结点都连续集中在最左边,这就是完全二叉树。(第 h 层可能包含 [1~2h] 个节点) 先使用一个列表得到广度遍历结果及每个节点对应的深度 遍历该列表。 1.如果节点不是倒数第二层,只需要累计该层节点总数,看是否等于2的n次方(假设二叉树深度从0开始的情况下)。累计的方式为使用一个curLength标识当前层,如果当前节点层数与curLength相同,说明还在这一层,只需要累加;如果不相等,则说明进入了下一层,对上一层的数目进行判定,并将累加数置0、更新当前层。 2.如果节点是倒数第二层,这一层的所有节点都不允许在左子树为空的情况下有右子树、如果同层前面的节点没有右孩子,那么当前节点只能为叶子结点(不能有左孩子也不能有右孩子)。 使用一个hasChild标识当前节点是否允许有孩子。 输入一棵节点数为 n 二叉树,判断该二叉树是否是平衡二叉树。 在这里,我们只需要考虑其平衡性,不需要考虑其是不是排序二叉树 平衡二叉树(Balanced Binary Tree),具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。 写一个函数计算二叉树深度,判断二叉树左右子树深度差是否符合条件,如果符合再递归判断二叉树的左子树、右子树是否符合条件。 给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。 1.对于该题的最近的公共祖先定义:对于有根树T的两个节点p、q,最近公共祖先LCA(T,p,q)表示一个节点x,满足x是p和q的祖先且x的深度尽可能大。在这里,一个节点也可以是它自己的祖先. 2.二叉搜索树是若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值; 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值 3.所有节点的值都是唯一的。 4.p、q 为不同节点且均存在于给定的二叉搜索树中。 数据范围: 3<=节点总数<=10000 0<=节点值<=10000 输入:{7,1,12,0,4,11,14,#,#,3,5},1,12 输出:7 先通过一个函数得到在二叉搜索树中找寻某值的路径,得到两个值的路径后,路径中最后相等的那个节点就是他们的最近公共祖先。 给定一棵二叉树(保证非空)以及这棵树上的两个节点对应的val值 o1 和 o2,请找到 o1 和 o2 的最近公共祖先节点。 数据范围:树上节点数满足 1≤n≤105 , 节点值val满足区间 [0,n) 要求:时间复杂度 O(n) 注:本题保证二叉树中每个节点的val值均不相同。 如当输入{3,5,1,6,2,0,8,#,#,7,4},5,1时,二叉树{3,5,1,6,2,0,8,#,#,7,4}如下图所示: 所以节点值为5和节点值为1的节点的最近公共祖先节点的节点值为3,所以对应的输出为3。 节点本身可以视为自己的祖先。 如何判断6和4的最近公共祖先?节点6的路径为[3,5,6],节点4的路径为[3,5,2.4],得到两个节点的路径,遍历节点6的路径,第一个同时也在节点4路径中的节点就是两个节点的最近公共祖先。 如何得到节点4和节点6的路径?层次遍历一遍二叉树,用一个hashmap存放<节点,节点的父节点>,那么通过节点找节点的父节点,再通过节点的父节点找父父节点,每个找到的节点都插入到列表头,就可以得到一个节点的路径列表了。 请实现两个函数,分别用来序列化和反序列化二叉树,不对序列化之后的字符串进行约束,但要求能够根据序列化之后的字符串重新构造出一棵与原二叉树相同的树。 二叉树的序列化(Serialize)是指:把一棵二叉树按照某种遍历方式的结果以某种格式保存为字符串,从而使得内存中建立起来的二叉树可以持久保存。序列化可以基于先序、中序、后序、层序的二叉树等遍历方式来进行修改,序列化的结果是一个字符串,序列化时通过 某种符号表示空节点(#)二叉树的反序列化(Deserialize)是指:根据某种遍历顺序得到的序列化字符串结果str,重构二叉树。 例如,可以根据层序遍历的方案序列化,如下图 层序序列化(即用函数Serialize转化)如上的二叉树转为"{1,2,3,#,#,6,7}",再能够调用反序列化(Deserialize)将"{1,2,3,#,#,6,7}"构造成如上的二叉树。 当然你也可以根据满二叉树结点位置的标号规律来序列化,还可以根据先序遍历和中序遍历的结果来序列化。不对序列化之后的字符串进行约束,所以欢迎各种奇思妙想。 数据范围:节点数 n≤100,树上每个节点的值满足 0≤val≤150 要求:序列化和反序列化都是空间复杂度 O(n),时间复杂度 O(n) 编码:用层次遍历的方式编码,先将根节点放入列表,然后从列表取第一个节点,如果该节点左子树为空,放进列表里一个特殊空节点(此处用值为-1的节点标识空节点),不为空则使用左节点创建节点放入列表,右子树同理。如果取出的节点是空节点,那么只将一个#放入到结果里,不再将其左右子树加入到列表。最后需要用特殊字符把他们隔开,便于解码函数处理。 解码:先按照特殊字符分割,再使用和编码方式一样的解码方式解码,使用一个队列存放非空节点,先把根节点放进去,遍历传入的字符串数组,从第二个元素(下标1)开始遍历,每次取两个元素出来并每次递增2,这样可以保证队列队首元素是每次取的两个元素的根。 请根据二叉树的前序遍历,中序遍历恢复二叉树,并打印出二叉树的右视图 数据范围: 0≤n≤10000 如输入[1,2,4,5,3],[4,2,5,1,3]时,通过前序遍历的结果[1,2,4,5,3]和中序遍历的结果[4,2,5,1,3]可重建出以下二叉树: 所以对应的输出为[1,3,5]。 根据前序、中序重建二叉树就不说了。打印右视图方法为DFS遍历二叉树,得到DFS遍历序列以及相对应的每个节点的深度,例如上面的树DFS结构就是45213,对应的深度是22101,使用一个长度为3的数组,遍历DFS结构,用节点值覆盖索引为深度值的元素,即右侧的元素会将左侧的元素覆盖掉,最后就得到了135。 得到DFS序列的方法为使用非递归,用一个栈暂存节点,首先将根节点放进去,然后每次都取栈顶元素(取值不弹出),如果该元素左子树不为空且左节点未遍历过(用一个列表记录已经遍历过的节点)那么将左节点压入栈,否则压入其右节点,如果左右子树均为空 或者 (左子树不为空但左子树已经被遍历过或左子树为空 且 右子树不为空但右子树已经被遍历过或右子树为空)就将栈顶元素弹出,直至栈为空即完成了DFS。 请实现无重复数字的升序数组的二分查找 给定一个 元素升序的、无重复数字的整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标(下标从 0 开始),否则返回 -1 数据范围:0≤len(nums)≤2×105 , 数组中任意值满足 ∣val∣≤109 进阶:时间复杂度 O(logn) ,空间复杂度 O(1) 递归查找,每次传入原数组和low、high,如果low>high则说明没找到返回-1,取mid=(low+high)/2,如果nums[mid]<目标值,说明需要去mid右面部分找,反之则需要去左边找,如果等于则返回mid。 在一个二维数组array中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。 [ [1,2,8,9], ] 给定 target = 7,返回 true。 给定 target = 3,返回 false。 从左下角元素arr[arr.length-1][0]开始寻找,如果值 给定一个长度为n的数组nums,请你找到峰值并返回其索引。数组可能包含多个峰值,在这种情况下,返回任何一个所在位置即可。 1.峰值元素是指其值严格大于左右相邻值的元素。严格大于即不能有等于 2.假设 nums[-1] = nums[n] = −∞−∞ 3.对于所有有效的 i 都有 nums[i] != nums[i + 1] 4.你可以使用O(logN)的时间复杂度实现此问题吗? 时间复杂度O(n) 时间复杂度O(logN)的方法看起来像是分治+贪心,每次取中间元素mid为标杆,如果标杆大于其右侧的值,将区间改为以标杆为终点的区间,如果标杆小于其右侧的值,将区间改为以标杆为起始的区间,如果左侧边界low与右侧边界high重叠则返回该下标,如果low>high此时峰值为最左侧值或者最右侧值,返回其中的一个。(题目似乎没说一定含有峰值,什么道理也不知道,但是确实对,和沿着梯度下降方向优化一定能找到局部最优解一个道理?) 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P mod 1000000007 数组中所有数字的值满足 0≤val≤10^9 要求:空间复杂度 O(n),时间复杂度 O(nlogn) 通过归并排序过程得到逆序对数量 归并排序过程如下: 以[4,5,8,1,7,2,6,3]这个序列为例 先划分为两部分[4,5,8.1]和[7,2,6,3] 再将这两部分向下划分为[4,5] [8,1] [7,2],[6,3] 再向下划分为[4],[5],[8],[1],[7],[2],[6],[3](当每个子序列里都只有一个元素时停止划分) 再逐层将子序列两两合并,合并的方法为先建立一个长度为两个子序列长度和的临时数组,每次都取两个序列中小的那个放进临时数组,最后可以得到一个有序长序列。 [4,5],[1,8],[2,7],[3,6] 再继续向上合并[1,4,5,8],[2,3,6,7] 继续向上合并得到结果[1,2,3,4,5,6,7,8] 如何在归并排序的过程中统计出逆序列对数呢? 我们拿[4,5],[1,8]合并成[1,4,5,8]这个过程举例 因此我们只要在每一次合并的过程中加一步,一旦序列B的数字比序列A的小,那么count += (序列A长度 - x +1) 牛客项目发布项目版本时会有版本号,比如1.02.11,2.14.4等等 现在给你2个版本号version1和version2,请你比较他们的大小 版本号是由修订号组成,修订号与修订号之间由一个"."连接。1个修订号可能有多位数字组成,修订号可能包含前导0,且是合法的。例如,1.02.11,0.1,0.2都是合法的版本号 每个版本号至少包含1个修订号。 修订号从左到右编号,下标从0开始,最左边的修订号下标为0,下一个修订号下标为1,以此类推。 比较规则: 一. 比较版本号时,请按从左到右的顺序依次比较它们的修订号。比较修订号时,只需比较忽略任何前导零后的整数值。比如"0.1"和"0.01"的版本号是相等的 二. 如果版本号没有指定某个下标处的修订号,则该修订号视为0。例如,"1.1"的版本号小于"1.1.1"。因为"1.1"的版本号相当于"1.1.0",第3位修订号的下标为0,小于1 三. version1 > version2 返回1,如果 version1 < version2 返回-1,不然返回0. 数据范围: 1<=ℎ<=10001<=version1.length,version2.length<=1000 version1 和 version2 的修订号不会超过int的表达范围,即不超过 32 位整数 的范围 现将字符串按.分割,将短的补位成和长的一样长,每一位转成int,逐位比较。 用两个栈来实现一个队列,使用n个元素来完成 n 次在队列尾部插入整数(push)和n次在队列头部删除整数(pop)的功能。 队列中的元素为int类型。保证操作合法,即保证pop操作时队列内已有元素。 放就放栈1里,出时候从栈2出,如果栈2是空的,先把1全部元素倒进来再出。 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的 min 函数,输入操作时保证 pop、top 和 min 函数操作时,栈中一定有元素。 此栈包含的方法有: push(value):将value压入栈中 pop():弹出栈顶元素 top():获取栈顶元素 min():获取栈中最小元素 数据范围:操作数量满足0≤n≤300 ,输入的元素满足 ∣val∣≤10000 示例: 输入: ["PSH-1","PSH2","MIN","TOP","POP","PSH1","TOP","MIN"] 输出: -1,2,1,-1 解析: "PSH-1"表示将-1压入栈中,栈中元素为-1 "PSH2"表示将2压入栈中,栈中元素为2,-1 “MIN”表示获取此时栈中最小元素==>返回-1 "TOP"表示获取栈顶元素==>返回2 "POP"表示弹出栈顶元素,弹出2,栈中元素为-1 "PSH1"表示将1压入栈中,栈中元素为1,-1 "TOP"表示获取栈顶元素==>返回1 “MIN”表示获取此时栈中最小元素==>返回-1 用两个栈,s1用来正常进栈出栈,s2与s1一一对应、记录着每一步的最小值。当入栈时,比较入栈元素和栈顶谁小,如果栈顶小那么说明加入新元素以后最小值不变,所以再放进S2一个S2栈顶元素。如果入栈元素小,那么加入新元素以后最小值就是新元素,所以在S2栈顶放入新元素。 给出一个仅包含字符'(',')','{','}','['和']',的字符串,判断给出的字符串是否是合法的括号序列 数据范围:字符串长度 0≤n≤10000 要求:空间复杂度 O(n),时间复杂度 O(n) 学c语言时候就做过的题,老朋友了。如果是左括号就进栈,右括号就出栈,如果栈是空的或者出栈不匹配就返回flase,如果字符串遍历完了栈还有元素也返回false。 给定一个长度为 n 的数组 num 和滑动窗口的大小 size ,找出所有滑动窗口里数值的最大值。 例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针对数组{2,3,4,2,6,2,5,1}的滑动窗口有以下6个: {[2,3,4],2,6,2,5,1}, {2,[3,4,2],6,2,5,1}, {2,3,[4,2,6],2,5,1}, {2,3,4,[2,6,2],5,1}, {2,3,4,2,[6,2,5],1}, {2,3,4,2,6,[2,5,1]}。 窗口大于数组长度或窗口长度为0的时候,返回空。 数据范围: 1≤n≤10000,0≤size≤10000,数组中每个元素的值满足 ∣val∣≤10000 要求:空间复杂度 O(n),时间复杂度O(n) 优化思路:如果i 如果用一个序列表示可能成为某个窗口最大值,那么在新值加入时有三种情况: 1.序列为空,直接加入 2.新值大于序列尾,则序列尾不停出队,直到序列里所有小于该值的都出队或者队列为空。这时候将新值加入进去 3.新值小于序列尾,直接加入 这样能保证序列是一个非递增序列,队首永远是队列中的最大值。 需要注意的是窗口每移动一次序列中就会有一个元素过期,为了方便确定队首元素是否过期,我们在队伍中存放元素下标而不是元素的值,每次加入新值之前先判断一下当前遍历的下标减去队首元素下标是否大于等于窗口大小,如果大于队首元素就因为过期被淘汰了。 从遍历到首个窗口最后一个元素起,第一个窗口的最大值就诞生了,把它加入到结果集中,以后每新加入一个元素都代表了一次窗口的移动,也同样要诞生当前窗口的最大值,所以从那个位置起,每次都取队首加入到结果集。 采用双端队列实现上述序列。 给定一个长度为 n 的可能有重复值的数组,找出其中不去重的最小的 k 个数。例如数组元素是4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4(任意顺序皆可)。 数据范围:0≤k,n≤10000,数组中每个数的大小0≤val≤1000 要求:空间复杂度 O(n) ,时间复杂度 O(nlogk) 求topK问题用大小根堆。小根堆求前K个大元素,大顶堆求前K个小元素。所以此题用大顶堆,priorityQueue是实现好的小顶堆,通过传入Compartor可以改为大顶堆。 有一个整数数组,请你根据快速排序的思路,找出数组中第 k 大的数。 给定一个整数数组 a ,同时给定它的大小n和要找的 k ,请返回第 k 大的数(包括重复的元素,不用去重),保证答案存在。 要求:时间复杂度 O(nlogn),空间复杂度O(1) 数据范围:0≤n≤1000,≤K≤n,数组中每个元素满足 0≤val≤10000000 快排,时间复杂度为O(nlogn),然后取第a[n-k]个元素 快排思路:首先选取数组的首个元素作为基准,使用两个指针low、high帮忙寻找,从最右侧往左找第一个比基准小的数(大于基准时移动指针),从左侧往右找第一个比基准大的数(小于等于基准时移动指针),将两数字交换,直到两指针重叠,两指针重叠位置为分界线,将分界处值与基准值互相交换并返回分界线下标pivot。接着以该分界点将原数组划分为左半边(startIndex,pivot-1),右半边(pivot+1,endIndex),递归对左半边右半边就行比较排序,startIndex>=endIndex为递归出口。 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。我们使用Insert()方法读取数据流,使用GetMedian()方法获取当前读取数据的中位数。 数据范围:数据流中数个数满足 1≤n≤1000 ,大小满足 1≤val≤1000 insert采用插入排序法,时间复杂度应该是O(n^2)不知道为什么没超时 然后按照下标取值,时间复杂度O(1) 请写一个整数计算器,支持加减乘三种运算和括号。 数据范围:0≤∣s∣≤100,保证计算结果始终在整型范围内 要求:空间复杂度: O(n),时间复杂度 O(n) 用op记录上一步的运算符,num记录当前数字,c表示当前位字符。 首先判断当前字符c是否为数字,因为可能是多位数字,因此如果是数字的话,当前数字变为num*10+c-'0'。 其次判断当前字符是否是左括号。如果是左括号,处理方式为将括号内的当做一个整体进行递归,递归起点为此位+1,终点为与之匹配的括号位-1。用下标j寻找与之匹配的括号位方法为采用一个技术count=1,如果新字符是左括号则count+1,为右括号则count-1,count=0说明j在匹配的括号位了,那么递归(i+1,j)(左闭右开,j不在递归范围内),然后i=j。 最后判断字符是否为非数字或者当前是字符串最后一位,如果是的话: op为加,num进栈。 op为减,-num进栈。 op为乘法,num*stack.pop()进栈。 最后将栈中所有累加得到结果。 给出一个整型数组 numbers 和一个目标值 target,请在数组中找出两个加起来等于目标值的数的下标,返回的下标按升序排列。 (注:返回的数组下标从1开始算起,保证target一定可以由数组里面2个数字相加得到) 数据范围:2≤len(numbers)≤105,−−10≤numbersi≤109,0≤target≤109 要求:空间复杂度 O(n),时间复杂度 O(nlogn) 遍历一遍将数组元素和下标存入hashmap,再遍历一遍取出来。 给一个长度为 n 的数组,数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。 例如输入一个长度为9的数组[1,2,3,2,2,2,5,4,2]。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。 数据范围:n≤50000,数组中元素的值 0≤val≤10000 要求:空间复杂度:O(1),时间复杂度 O(n) 保证数组输入非空,且保证有解 用count表示当前数的个数,并记录结果,如果每次遇到的数与当前数一样则数量加一,如果不一样则数量减一,同时如果count=0则更换结果。因为所求的那个数出现次数大于其他所有数,所以最后留下的一定是所求的那个数。 如果不是要求空间复杂度O(1)的话可以用hashmap 一个整型数组里除了两个数字只出现一次,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。 数据范围:数组长度 2≤n≤1000,数组中每个数的大小0 提示:输出时按非降序排列。 遍历数组把数字和出现个数存入hashmap,遍历hashmap把出现一次的数字放入结果 时间复杂度O(n)空间复杂度 O(n) 两个数字取异或 可以得出不同的那一位 因此如果是一堆数中只有一个数字出现一次、其他数字出现两次,那么通过所有数字异或就可以得出这个数字。但是题目中是两个数字,那么这种情况下将所有数字异或就可以得出最终求的那两个数不同的所有位。 比如如果结果是3(0011),6(0110),那么所有异或得出的结果就是5(0101)。根据异或结果我们可以得到他们不同的一位0001,可以通过这一位将所有的数字分成两组,和0001取交集为1的一组,取交集为0的一组,这样就能将结果的两个数分开。 给定一个无重复元素的整数数组nums,请你找出其中没有出现的最小的正整数 进阶: 空间复杂度 O(1),时间复杂度 O(n) 数据范围: −2^31≤nums[i]≤2^31−1 0≤len(nums)≤5∗105 遍历一遍存hashmap里,然后判断有没有 给出一个有n个元素的数组S,S中是否有元素a,b,c满足a+b+c=0?找出数组S中所有满足条件的三元组。 数据范围:0≤n≤1000,数组中各个元素值满足 ∣val∣≤100 空间复杂度:O(n2),时间复杂度 O(n2) 注意: 暴力法的话时间复杂度是O(n^3) 优化:首先将数组排序(快排,时间复杂度O(logn))只从头到尾遍历一个元素num[i],目标变为找相加和为-num[i]的两个数,采用双指针,初始左指针在最左(i+1),初始右指针在最右(num.length-1),如果两个指针的数相加小于目标值则左指针向右,如果两个指针的数相加大于目标值则右指针向左,如果相等则将三个数加入到结果集中,并且左指针向右一次、右指针向左一次(因为还要继续查找)。为了避免解集中出现重复三元组,如果遍历中出现num[i]和num[i-1]相等则continue跳过一次,另外是双指针查找时如果找到了同时num[left+1]和num[left]相等要跳过、num[right-1]和num[right]相等也要跳过。 给出一组数字,返回该组数字的所有排列 例如: [1,2,3]的所有排列如下 数据范围:数字个数 0 要求:空间复杂度 O(n!) ,时间复杂度 O(n!) 回溯法 得到题中结果集的过程如上所示,在有新数字没加入到当前集合的情况下一直向下深度遍历,直到所有数字都在时向上退一级,退到原有的节点所有子节点都遍历过时再向上退一级。 使用一个递归函数完成这个递归回退的过程,递归函数需要传递的参数是整个数组、当前已经遍历到的所有节点,因此参数为原数组和一个list。 递归出口为list的长度与原数组长度相同说明已经到达解空间树的叶子结点,此时返回。 递归函数中需要做的事包括:对整个数组进行遍历,如果当前数字已经在list了跳出一次循环对下一个数进行判断,如果当前数字不在List里则将该数字加进去,使用新的list继续向下递归。递归结束说明向下的所有节点遍历完了,将list删掉末尾一个节点 回退到上一层。 给出一组可能包含重复项的数字,返回该组数字的所有排列。结果以字典序升序排列。 数据范围:0 要求:空间复杂度 O(n!),时间复杂度 O(n!) 解空间树的结构和上一题一样,不同的是当第一个[1]的所有分支已经都遍历过以后,下一次再到1不继续向下递归了,也就是增加了剪枝条件。为了能使相同数字相邻,先将整个原数组排序。用一个boolean数组mark标识所有的数字是否被遍历过,每次将当前节点加入list时都将mark[i]置为true,每次递归结束返回上一级删除当前节点时再将mark[i-1]置为false。 这样每次此节点遍历过或者是遍历到的数字如果其值与上一个数字一样且上一个数组没被遍历过(mark[i-1]==false说明上一个相同数字的所有分支都被遍历过了),应该对当前进行剪枝,即跳过此数字。 给一个01矩阵,1代表是陆地,0代表海洋, 如果两个1相邻,那么这两个1属于同一个岛。我们只考虑上下左右为相邻。 岛屿: 相邻陆地可以组成一个岛屿(相邻:上下左右) 判断岛屿个数。 例如: 输入 [ [1,1,0,0,0], [0,1,0,1,1], [0,0,0,1,1], [0,0,0,0,0], [0,0,1,1,1] ] 对应的输出为3 (注:存储的01数据其实是字符'0','1') 遍历整个矩阵,如果元素为1则累加数加一、进入递归函数。在递归函数中,将当前位置置为0,然后如果上面一个不越界且为1则递归遍历上面一个,下、右、左同理。 输入一个长度为 n 字符串,打印出该字符串中字符的所有排列,你可以以任意顺序返回这个字符串数组。 例如输入字符串ABC,则输出由字符A,B,C所能排列出来的所有字符串ABC,ACB,BAC,BCA,CBA和CAB。 和上面那道重复数的全部排列一样的,只是改成字符串版了 N 皇后问题是指在 n * n 的棋盘上要摆 n 个皇后, 数据范围: 1≤n≤9 要求:空间复杂度 O(1) ,时间复杂度 O(n!) 例如当输入4时,对应的返回值为2, 对应的两种四皇后摆位如下图所示: 思路为遍历棋盘,如果点符合放置皇后的条件,将因该点不能放置皇后的点记录下来,然后递归在这个皇后的下一行遍历每一列寻找合适位置放置余下的皇后。每次传递已经放置的皇后数(同时此数字加1也是下次遍历的起点,因为N个皇后放在N行N列肯定每一行都有一个皇后、每一列都有一个皇后,上一个皇后放在i行的话,下一个皇后一定出现在第i+1行)、棋盘大小。递归出口为当已放置的皇后数与要求一致时count++,return。 怎么记录不能放置皇后的点?当一个位置(i,j)放置了皇后以后,其所在行(x=i的所有点)、列(y=j的所有点)、对角线(x-y与j-i相等的所有点)、反对角线(x+y与i+j)上的点都不能再放置皇后了。因为每次传递了下一次遍历的起点行,为上一次遍历的下一行,行不会重复,因此不需要记录不能放置的行。列、对角线、反对角线分别用三个HashSet记录(查找比较快)。每次递归时候如果当前坐标不满足条件则跳过,满足条件则进行下一次递归。 给出n对括号,请编写一个函数来生成所有的由n对括号组成的合法组合。 例如,给出n=3,解集为: "((()))", "(()())", "(())()", "()()()", "()(())" 数据范围:0≤n≤10 要求:空间复杂度 O(n),时间复杂度 O(2n) 把每个括号当作不重复的字符串,得到所有排列组合,用函数判断是否合法,合法的放到HashSet去重。 用hashmap存放现在可用的左括号数、右括号数。还有左括号的时候,用一个左括号,然后使用(+str作为中间结果继续递归,并将左括号可用数减一,递归完成后再将该数目加一还原。已经用的左括号数大于已经用的右括号数(即hashmap中左括号数小于右括号数)时候才可以用一个右括号,然后使用)+str作为中间结果继续递归。当左右括号都用光时递归结束,将中间结果放入结果集。 给定一个 n 行 m 列矩阵 matrix ,矩阵内所有数均为非负整数。 你需要在矩阵中找到一条最长路径,使这条路径上的元素是递增的。并输出这条最长路径的长度。 这个路径必须满足以下条件: 1. 对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外。 2. 你不能走重复的单元格。即每个格子最多只能走一次。 数据范围:1≤n,m≤1000,0≤matrix[i][j]≤1000 进阶:空间复杂度 O(nm) ,时间复杂度 O(nm) 例如:当输入为[[1,2,3],[4,5,6],[7,8,9]]时,对应的输出为5, 其中的一条最长递增路径如下图所示: 用一个布尔型的mark数组记录该点是否可以走,用一个list记录当前路径走过的点,用一个maxLength量记录当前最常路径长度。如果数组越界或者当前节点的权重小于路径上一个节点,说明不能继续走,此时比较路径长度是否可以替换最大长度、返回。如果当前list为空且当前节点可以走、或者list不为空、当前节点可以走、list的最后一个元素权重小于当前节点值则可以继续走,将当前节点加入List并继续递归其上、下、左、右路径。递归结束后将当前节点移除。 在主函数中遍历矩阵每一个元素,调用递归函数。 大家都知道斐波那契数列,现在要求输入一个正整数 n ,请你输出斐波那契数列的第 n 项。 斐波那契数列是一个满足fib(x)=1,x=1,21 fib(x)=fib(x−1)+fib(x−2),x>2 的数列 数据范围:1≤n≤40 要求:空间复杂度 O(1),时间复杂度 O(n) ,本题也有时间复杂度 O(logn) 的解法 递归 一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个 n 级的台阶总共有多少种跳法(先后次序不同算不同的结果)。 数据范围:1≤n≤40 要求:时间复杂度:O(n) ,空间复杂度: O(1) 台阶数为1时青蛙只有一种跳法,台阶数为2时青蛙有两种跳法。台阶数为n时青蛙跳的最后一步可以是只跳一个台阶,那么跳法数f(n-1),跳的最后一步也可以是跳两个台阶,那么跳法数为f(n-2),因为最后一步只有这两种跳法,所以f(n)=f(n-1)+f(n-2) 给定一个整数数组 cost ,其中cost[i] 是从楼梯第i 个台阶向上爬需要支付的费用,下标从0开始。一旦你支付此费用,即可选择向上爬一个或者两个台阶。 请你计算并返回达到楼梯顶部的最低花费。 数据范围:数组长度满足 1≤n≤105 ,数组中的值满足 1≤costi≤104 给定两个字符串str1和str2,输出两个字符串的最长公共子序列。如果最长公共子序列为空,则返回"-1"。目前给出的数据,仅仅会存在一个最长的公共子序列 数据范围:0≤∣str1∣,∣str2∣≤2000 要求:空间复杂度 O(n2) ,时间复杂度 O(n2) 创建一个二维数组num[str1.length() + 1][str2.length() +1]用来保存str1长度为i,str2长度为j时他们的最长公共子序列的长度 首先将第0行0列都赋0,接着按照上面的规则填写,可以得到如下矩阵: 题目中要求输出的时两个字符串的最长公共子序列而不是该子序列的长度,不过问题不大,我们重新复盘一下上述对求最长公共子序列长度的分析,不难发现,对于i >0,j>0时,num[i][j]的数据来源有两种情况: 1.如果str1.charAt(i - 1) == str2.charAt(j - 1),那么num[i][j]一定来源于num[i - 1][j - 1]+1; 2.如果str1.charAt(i - 1) != str2.charAt(j - 1),那么num[i][j]来源于num[i - 1][j]和num[i][j - 1]二者里面的较大值。 定义一个direction数组,为了方便起见,他的大小应该与num数组大小相同,direction[i][j]用来保存num[i][j]数据的来源方位 从direction数组的右下角开始,遇到1就加入结果字符串的左边,并向左上,遇到2则向左、遇到3则向上,就可以得到结果了。 给定两个字符串str1和str2,输出两个字符串的最长公共子串 题目保证str1和str2的最长公共子串存在且唯一。 数据范围: 1≤∣str1∣,∣str2∣≤5000 类似找最长公共子序列,建立一个二维数组,如果字符相等则dp[i][j]=dp[i-1][j-1]+1,否则dp[i][j]=0。用一个量记录最长子序列长度和最后的下标,后面用这两个值截取字符串。 一个机器人在m×n大小的地图的左上角(起点)。 机器人每次可以向下或向右移动。机器人要到达地图的右下角(终点)。 可以有多少种不同的路径从起点走到终点? 因为到达每一个点要不是从上方移动过来的,要不是从左边移动过来的,所以递推公式为dp[i][j]=dp[i-1][j]+dp[i][j-1],当只有一行或者只有一列时候只有一条路线,用1初始化。最后返回右下角元素。 给定一个 n * m 的矩阵 a,从左上角开始每次只能向右或者向下走,最后到达右下角的位置,路径上所有的数字累加起来就是路径和,输出所有的路径中最小的路径和。 数据范围: 1≤n,m≤500,矩阵中任意值都满足 0≤ai,j≤100 要求:时间复杂度 O(nm) 例如:当输入[[1,3,5,9],[8,1,3,4],[5,0,6,1],[8,8,4,0]]时,对应的返回值为12, 所选择的最小累加和路径如下图所示: 递推方程为 dp[i][j] = weight[i][j] + min(dp[i-1][j],dp[i][j-1]) 有一种将字母编码成数字的方式:'a'->1, 'b->2', ... , 'z->26'。 现在给一串数字,返回有多少种可能的译码结果 数据范围:字符串长度满足0 进阶:空间复杂度 O(n),时间复杂度 O(n) 先排除一些特殊情况,比如空字符串应该返回0、在字符串中如果某一位出现了0但是其前一位不是1或者2也无法编码,应该也返回0、字符串如果是10或者20直接返回1。 接着第一位赋值为1,第二位要看第一位加上第二位在不在11~26之间(排除20 因为20只有一种编码方式),如果满足条件第二位也有两种方式,否则为一种方式。 接下来每一位dp[i]=dp[i-1]+dp[i-2](因此要至少从第三位开始,前两位需要赋初始值) 给定数组arr,arr中所有的值都为正整数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个aim,代表要找的钱数,求组成aim的最少货币数。 如果无解,请返回-1. 数据范围:数组大小满足 0≤n≤10000 , 数组中每个数字都满足0 要求:时间复杂度 O(n×aim) ,空间复杂度 O(aim)。 用dp[i]表示目标为i时需要的最少钱数,因此新建一个长度为aim+1的数组用于动态规划。将dp[0]设置为0。 对动态数组里的每一位,遍历货币数组。比如i=6时有三种选择 1)可以取一张面额为5的货币,那么问题就变成了d[6-5]+1 2)可以取一张面额为2的货币,那么问题就变成了d[6-2]+1 3)还可以取一张面额为3的货币,问题就变成了d([6-3]+1) 因为20一张面额就大于6了,所以取不了 此时如果想得到i=6时最小货币数,就要得到上述三种情况中最小的那个。所以如果用j遍历货币数组的话,状态转移方程为d[i]=min(d[i],d[i-coin[j]]+1),注意遍历时只需要取货币面值小于目标值的。 这样一直递推到第aim个,就可以得到结果了。 因为货币最小单位是一元,在目标值为aim的情况下,最差也就是换到aim张一元的,所以用aim+1来初始化数组,如果最后返回的值大于aim,说明无解,返回-1 给定两个字符串 str1 和 str2 ,请你算出将 str1 转为 str2 的最少操作数。 你可以对字符串进行3种操作: 1.插入一个字符 2.删除一个字符 3.修改一个字符。 字符串长度满足 1≤n≤1000 ,保证字符串中只出现小写英文字母。 输入:"nowcoder","new" 输出:6 说明: 把第一个字符串变成第二个字符串,我们需要逐个将第一个字符串的子串最少操作下变成第二个字符串,这就涉及了第一个字符串增加长度,状态转移,那可以考虑动态规划。用 具体做法: 请实现一个函数用来匹配包括'.'和'*'的正则表达式。 1.模式中的字符'.'表示任意一个字符 2.模式中的字符'*'表示它前面的字符可以出现任意次(包含0次)。 在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串"aaa"与模式"a.a"和"ab*ac*a"匹配,但是与"aa.a"和"ab*a"均不匹配 数据范围: 1.str 只包含从 a-z 的小写字母。 2.pattern 只包含从 a-z 的小写字母以及字符 . 和 *,无连续的 '*'。 3. 0≤str.length≤26 用dp[i][j]表示模板串截止第i个字符(下标为i-1),匹配串截止第j个字符(下标为j-1)能否匹配上。行对应模板串,列对应匹配串。 第0行表示模板串为空,第0列表示匹配串为空,那么dp[0][0]应该初始化为true。 1.在字符不为*的情况下,如果pattern[i-1]和str[j-1]相同或者pattern[i-1]为.的情况下,说明当前字符匹配,进而结果取决于前面的匹配情况,即dp[i][j] = dp[i-1][j-1] 2.在字符为*的情况下,将*前面的字符(假设为x)与*看作一个整体。 (1)第一种情况:将x跳过,比较取消x*和当前匹配串的匹配程度,即dp[i][j]=dp[i-2][j]。 (2)第二种情况:如果x与当前字符匹配或者是x是.,那么取决于当前模板串与当前字符之前字符串的匹配程度,即dp[i][j]=dp[i][j-1] 给出一个长度为 n 的,仅包含字符 '(' 和 ')' 的字符串,计算最长的格式正确的括号子串的长度。 例1: 对于字符串 "(()" 来说,最长的格式正确的子串是 "()" ,长度为 2 . 例2:对于字符串 ")()())" , 来说, 最长的格式正确的子串是 "()()" ,长度为 4 . 字符串长度:0≤n≤5∗105 要求时间复杂度 O(n) ,空间复杂度 O(n) 用dp[i]表示截止到下标为i的字符当前最长合法括号子串长度。 合法括号子串必然以)为结尾,所以所有以(为结尾的子串合法长度均为0,初始第一个如果就为)合法长度也为0。 对以)结尾的子串有两种情况: 1."()":这种情况表示在先前合法子串上新增一对合法括号,因此dp[i]=dp[i-1]+2 2."))":这种情况要看右面这个)有没有匹配的(,如果有的话,他匹配的左括号下标应该为i-dp[i-1]-1 (解释:dp[i-1]为截止左面那个)为止合法的串长度,i-dp[i-1]就是与左面那个)匹配的(位置,所以i-dp[i-1]-1就是与左面那个)匹配的(位置的上一位,也就是与右面这个)匹配的(位置) 所以判断i-dp[i-1]-1位置是否有匹配的左括号,如果有则长度为dp[i-dp[i-1]-2]+dp[i-1]+2 (解释:如果该位置有匹配的左括号,那么最长括号子串长度应为在))这个序列之前最长的括号子串长度 加上 这次匹配))的新串长度,即0dp[i-dp[i-1]-2] + dp[i-1]+2) 你是一个经验丰富的小偷,准备偷沿街的一排房间,每个房间都存有一定的现金,为了防止被发现,你不能偷相邻的两家,即,如果偷了第一家,就不能再偷第二家;如果偷了第二家,那么就不能偷第一家和第三家。 给定一个整数数组nums,数组中的元素表示每个房间存有的现金数额,请你计算在不被发现的前提下最多的偷窃金额。 数据范围:数组长度满足 1≤n≤2×105 ,数组中每个值满足 1≤num[i]≤5000 每一户都可以选择偷或者不偷,如果不偷的话dp[i]=dp[i-1] 如果偷的话 dp[i]=dp[i-2]+num[i] 二者里取最大的。初始值为dp[0],赋值为num[0]。 你是一个经验丰富的小偷,准备偷沿湖的一排房间,每个房间都存有一定的现金,为了防止被发现,你不能偷相邻的两家,即,如果偷了第一家,就不能再偷第二家,如果偷了第二家,那么就不能偷第一家和第三家。沿湖的房间组成一个闭合的圆形,即第一个房间和最后一个房间视为相邻。 给定一个长度为n的整数数组nums,数组中的元素表示每个房间存有的现金数额,请你计算在不被发现的前提下最多的偷窃金额。 数据范围:数组长度满足 1≤n≤2×105 ,数组中每个值满足 1≤nums[i]≤5000 相比于上一题,考虑偷第一家不偷最后一家、偷最后一家不偷第一家两种情况,分别进行一次动态规划,取两种情况中结果最大的一个作为结果。 假设你有一个数组prices,长度为n,其中prices[i]是股票在第i天的价格,请根据这个价格数组,返回买卖股票能获得的最大收益 1.你可以买入一次股票和卖出一次股票,并非每天都可以买入或卖出一次,总共只能买入和卖出一次,且买入必须在卖出的前面的某一天 2.如果不能获取到任何利润,请返回0 3.假设买入卖出均无手续费 数据范围: 0≤n≤105,0≤val≤104 要求:空间复杂度 O(1),时间复杂度O(n) 贪心,看到比手头小的就买入,遇到比手头大的就卖出,记录最大值。 假设你有一个数组prices,长度为n,其中prices[i]是某只股票在第i天的价格,请根据这个价格数组,返回买卖股票能获得的最大收益 1. 你可以多次买卖该只股票,但是再次购买前必须卖出之前的股票 2. 如果不能获取收益,请返回0 3. 假设买入卖出均无手续费 数据范围: 1≤n≤1×105 , 1≤prices[i]≤104 要求:空间复杂度 O(n),时间复杂度 O(n) 进阶:空间复杂度 O(1),时间复杂度O(n) 贪心:只要后一天比前一天大,就说明有利可图,就卖出去,将结果累加。 动态规划: 每一天都可以分成持有股票和不持有股票两种情况。采用一个二维数组分别表示这两种情况,dp[0]表示持有股票,dp[1]表示不持有股票。 1.持有股票:与前一天持有股票的收益相同,前一天不持有股票的话今天需要购买股票,因此收益为前一天持有股票的收益减去今天股票价格。 2.不持有股票:与前一天不持有股票收益相同,前一天持有股票的话今天需要卖出股票,因此收益为前一天持有股票的收益加上今天股票价格。 动态规划代码 贪心代码 假设你有一个数组prices,长度为n,其中prices[i]是某只股票在第i天的价格,请根据这个价格数组,返回买卖股票能获得的最大收益 数据范围:1≤n≤105,股票的价格满足 1≤val≤104 要求: 空间复杂度 (n),时间复杂度 O(n) 进阶:空间复杂度O(1),时间复杂度O(n) 有五种状态:1.没买过股票 2.买过一次股票还没有交易 3.买过一次也卖出过一次 4.买过两次卖出去过一次 5.买过两次卖出去过两次 状态一:由同样是状态一的转换过来,即dp[0][j]=dp[0][j-1]=0 状态二:上次没买这次买了dp[1][j] = dp[0][j-1]-num[j] 之前买过 dp[1][j-1] 里面取较大的 状态三:在状态二的基础上这次卖了或者之前就已经是状态三了 dp[2][j]=dp[1][j-1]+num[j]和dp[2][j-1]里取最大的 状态四:在状态三基础上又买了一次或者之前已经是状态四 dp[3][j]=dp[2][j-1]-num[j]和 dp[3][j-1]里取最大的 状态五:dp[4][j]=dp[3][j-1]+num[j]和 dp[4][j-1]里取最大的 最后从状态1、3、5中取最大值 给出两个字符串 s 和 t,要求在 s 中找出最短的包含 t 中所有字符的连续子串。 数据范围:0≤∣S∣,∣T∣≤10000,保证s和t字符串中仅包含大小写英文字母 要求:进阶:空间复杂度 O(n) , 时间复杂度 O(n) 例如: S="XDOYEZODEYXNZ" 注意: 用一个hashMap存模板里各个字符要求的数量,再用另一个hashMap存目前已经匹配上的字符数量。用两个指针left,right构成一个滑动窗口。match表示数量能匹配上的字符种类个数。 判断right所指的字符是否在模板要求内,如果在的话更新该字符数量,对比字符数量与模板要求是否一样,如果一样则匹配数加一。如果匹配数小于模板字符种类个数,还需要继续匹配,right++。如果相等,说明当前窗口内字符串满足条件,记录下来。left右移,left右移前要判断left当前位是否是模板内要求的字符串,如果是需要更新map和match,对应个数要减一。left右移到下一个模板内要求的字符即可,不是模板内要求字符的位置可以跳过。 以下代码只通过了60%用例。 给定一个数组height,长度为n,每个数代表坐标轴中的一个点的高度,height[i]是在第i点的高度,请问,从中选2个高度与x轴组成的容器最多能容纳多少水 1.你不能倾斜容器 2.当n小于2时,视为不能形成容器,请返回0 3.数据保证能容纳最多的水不会超过整形范围,即不会超过231-1 数据范围: 0<=height.length<=105 0<=height[i]<=104 如输入的height为[1,7,3,2,4,5,8,2,7],那么如下图: 容器容积其实就是面积,等于两条边中较短的一条边乘以两条边的间距。使用双指针,一个指数组头一个指数组尾,每次都较短的那边向中间靠,并保留乘积最大值。 给定一个整形数组arr,已知其中所有的值都是非负的,将这个数组看作一个柱子高度图,计算按此排列的柱子,下雨之后能接多少雨水。(数组以外的区域高度视为0) 数据范围:数组长度 0≤n≤2×105,数组中每个值满足 0 要求:时间复杂度 O(n) 我们都知道水桶的短板问题,控制水桶水量的是最短的一条板子。这道题也是类似,我们可以将整个图看成一个水桶,两边就是水桶的板,中间比较低的部分就是水桶的底,由较短的边控制水桶的最高水量。但是水桶中可能出现更高的边,比如上图第四列,它比水桶边还要高,那这种情况下它是不是将一个水桶分割成了两个水桶,而中间的那条边就是两个水桶的边。 有了这个思想,解决这道题就容易了,因为我们这里的水桶有两个边,因此可以考虑使用对撞双指针往中间靠。 一群孩子做游戏,现在请你根据游戏得分来发糖果,要求如下: 1. 每个孩子不管得分多少,起码分到一个糖果。 2. 任意两个相邻的孩子之间,得分较多的孩子必须拿多一些糖果。(若相同则无此限制) 给定一个数组 arr 代表得分数组,请返回最少需要多少糖果。 要求: 时间复杂度为 O(n) 空间复杂度为 O(n) 数据范围: 1≤n≤100000 ,1≤ai≤1000 要想分出最少的糖果,利用贪心的思想就是在相邻位置没有增加的情况下,大家都分到1,相邻的分数有增加的情况下,在前者基础上增加。 先将数组元素全部初始化为1,然后先从左往右遍历数组,如果右面的比左面的大,给右面的加一。再从右向左遍历数组,如果左面的比右面的大且左面的糖没有右面的多,则给左边的多发一颗糖。 有 n 个活动即将举办,每个活动都有开始时间与活动的结束时间,第 i 个活动的开始时间是 starti ,第 i 个活动的结束时间是 endi ,举办某个活动就需要为该活动准备一个活动主持人。 复杂度要求:时间复杂度 O(nlogn) ,空间复杂度 O(n) 我们利用贪心思想,什么时候需要的主持人最少?那肯定是所有的区间没有重叠,每个区间首和上一个的区间尾都没有相交的情况,我们就可以让同一位主持人不辞辛劳,一直主持了。但是题目肯定不是这种理想的情况,那我们需要对交叉部分,判断需要增加多少位主持人。 具体做法: 一个数组A中存有 n 个整数,在不允许使用另外数组的前提下,将每个整数循环向右移 M( M >=0)个位置,即将A中的数据由(A0 A1 ……AN-1 )变换为(AN-M …… AN-1 A0 A1 ……AN-M-1 )(最后 M 个数循环移至最前面的 M 个位置)。如果需要考虑程序移动数据的次数尽量少,要如何设计移动的方法? 数据范围:0 进阶:空间复杂度 O(1),时间复杂度 O(n) 数组[1,2,3,4,5,6] 输入N=6,M=2 旋转完的结果应该是[5,6,1,2,3,4] 首先整体翻转:[6,5,4,3,2,1] 再单独翻转前M个:[5,6,4,3,2,1] 最后翻转剩下的N-M个:[5,6,1,2,3,4] 翻转的方法为使用双指针逼近,每次交换两个指针下标处元素 有一个NxN整数矩阵,请编写一个算法,将矩阵顺时针旋转90度。 给定一个NxN的矩阵,和矩阵的阶数N,请返回旋转后的NxN矩阵。 数据范围:,矩阵中的值满足 要求:空间复杂度 ,时间复杂度 进阶:空间复杂度 ,时间复杂度 示例1 输入 [[1,2,3],[4,5,6],[7,8,9]],3 输出 [[7,4,1],[8,5,2],[9,6,3]] 可以看出旋转后的矩阵就是原矩阵的第一行变为最后一列,第二行变为倒数第二列......那么可以先将原矩阵的行变为列(矩阵倒置),再将第一列变为最后一列,第二列变为最后第二列(矩阵按列倒置) 一个缓存结构需要实现如下功能。 但是缓存结构中最多放K条记录,如果新的第K+1条记录要加入,就需要根据策略删掉一条记录,然后才能把新记录加入。这个策略为:在缓存结构的K条记录中,哪一个key从进入缓存结构的时刻开始,被调用set或者get的次数最少,就删掉这个key的记录; 如果调用次数最少的key有多个,上次调用发生最早的key被删除 这就是LFU缓存替换算法。实现这个结构,K作为参数给出 将相同访问频率的key放在一条链表上,新加入这个频率的放在队首,这样方便淘汰时找到要淘汰的节点,要淘汰的就是频率最小里面队尾的元素。用一个值记录现场的最小频率。用一个hashmap存键到值的映射,另一个存访问频率到对应频率链表的映射。 数据结构采用双向链表LinkedList,每个链表节点内包括key,value,freq(访问次数)。 1.set操作:(1)如果链表中已经存在,更新访问次数:将此节点从该频率下的链表取出,放到频次数加一的链表首部并更新hashmap中的头结。 如果移动后原频率下已经没有节点了,从哈希表中删除这个频率,并且如果该频率是此前记录的最小频率,更新最小频率。 (2)链表中不存在: 2.1 如果没有剩余空间,由最小频率找到对应节点,将尾部删除,如果这个频率链表空了,也要将记录频率链表映射的map中该频率的删除。将新节点插入到访问频率为1的链表头部(如果没有该链表需要新建) 2.2 有剩余空间直接将他插入到访问频率为1的链表头部 2.get操作:链表中是否存在,如果存在则取出并更新访问频率。(更新步骤类似set(1))思路
代码
public ListNode sortInList (ListNode head) {
ArrayListBM13 判断一个链表是否为回文结构
描述
思路
代码
public boolean isPail (ListNode head) {
ListNode p = head;
if(head == null) return false;
ArrayListBM14 链表的奇偶重排
描述
思路
代码
public ListNode oddEvenList (ListNode head) {
if (head == null) return null;
ListNode p = head;
ListNode newHead = new ListNode(-1);
ListNode tail = newHead;
while (p != null && p.next != null) {
ListNode q = p.next.next;
p.next.next = null;
tail.next = p.next;
tail = p.next;
p.next = q;
p = p.next;
}
p = head;
while(p.next!=null){
p = p.next;
}
ListNode q = newHead;
while(q!=null){
q = q.next;
}
p.next = newHead.next;
return head;
}BM15 删除有序链表中重复的元素-I
描述
例如:
给出的链表为1→1→21→1→2,返回1→21→2.
给出的链表为1→1→2→3→31→1→2→3→3,返回1→2→31→2→3.思路一
代码一
public ListNode deleteDuplicates (ListNode head) {
if (head == null) return null;
ListNode p = head;
HashMap思路二
代码二
public ListNode deleteDuplicates (ListNode head) {
if(head==null) return null;
ListNode pre = head;
ListNode p = pre.next;
while(p!=null){
while(pre.val==p.val){
p = p.next;
if(p==null){
pre.next = null;
return head;
}
}
pre.next = p;
pre = p;
p = p.next;
}
return head;
}BM16 删除有序链表中重复的元素-II
描述
例如:
给出的链表为1→2→3→3→4→4→51→2→3→3→4→4→5, 返回1→2→51→2→5.
给出的链表为1→1→1→2→31→1→1→2→3, 返回2→32→3.思路
代码
public ListNode deleteDuplicates (ListNode head) {
ListNode newHead = new ListNode(-1);
ListNode tail = newHead;
ListNode p = head;
HashMapBM9 删除链表的倒数第n个节点
描述
例如,
删除了链表的倒数第 n 个节点之后,链表变为1→2→3→51→2→3→5.
备注:思路
代码
public ListNode removeNthFromEnd (ListNode head, int n) {
if(head == null) return null;
ListNode pre = new ListNode(-1);
ListNode p = head;
ListNode q = new ListNode(-1);
int count = 1;
while(p.next!=null){
if(count树
JZ8 二叉树的下一个结点
描述

思路
代码
public TreeLinkNode GetNext(TreeLinkNode pNode) {
//如果为空,返回空
if(pNode==null) return null;
//如果右子树不为空,返回右子树的最左节点
if(pNode.right!=null){
TreeLinkNode left = pNode.right;
while(left.left!=null){
left = left.left;
}
return left;
}
//如果右子树为空,如果当前节点为根节点,返回null
if(pNode.right==null && pNode.next==null){
return null;
}
//如果右子树为空,如果当前为父亲的左子树,返回父亲
if(pNode.right==null && pNode==pNode.next.left){
return pNode.next;
}
TreeLinkNode parent;
//如果右子树为空,且当前为父亲的右子树,返回未被遍历过的祖先节点
if(pNode.right==null && pNode==pNode.next.right){
parent = pNode.next;
TreeLinkNode cur = pNode;
while(parent!=null && parent.left!=cur){
parent = parent.next;
cur = cur.next;
}
return parent;
}
return null;
}JZ55 二叉树的深度
描述
{1,2,3,4,5,#,6,#,#,7}
4
思路
代码
public class Solution {
public int TreeDepth(TreeNode root) {
if(root == null) return 0;
return (TreeDepth(root.left)+1)>(TreeDepth(root.right)+1)?(TreeDepth(root.left)+1):(TreeDepth(root.right)+1);
}
}
JZ77 按之字形顺序打印二叉树
描述
要求:空间复杂度:O(n),时间复杂度:O(n)
给定的二叉树是{1,2,3,#,#,4,5}
思路1
代码1
public ArrayList思路2
代码2
public class TempNode {
public TreeNode node;
public int depth = 0;
public TempNode(TreeNode node, int depth) {
this.node = node;
this.depth = depth;
}
}
public ArrayListJZ54 二叉搜索树的第k个节点
描述
进阶:空间复杂度 O(n),时间复杂度O(n)思路
代码
public int KthNode (TreeNode proot, int k) {
ArrayListJZ33 二叉搜索树的后序遍历序列
描述
思路
代码
public boolean VerifySquenceOfBST(int [] sequence) {
if(sequence.length==0) {
return false;
}else{
return VerifySquence(sequence);
}
}
public boolean VerifySquence(int [] sequence) {
for(int s:sequence){
System.out.print(" " + s);
}
System.out.println();
if (sequence.length == 0) return true;
if (sequence.length == 1) return true;
int root = sequence[sequence.length - 1];
int index = 0;
Boolean left = true;
Boolean right = true;
int i=0;
for (i = 0; i < sequence.length; i++) {
if (sequence[i] > root) {
index = i;
break;
}
}
if(i>=sequence.length){
index = sequence.length-1;
}
for (i = 0; i < sequence.length - 1; i++) {
if (i < index && sequence[i] > root) return false;
if (i >= index && sequence[i] < root) return false;
}
left = VerifySquence(Arrays.copyOfRange(sequence, 0, index));
right = VerifySquence(Arrays.copyOfRange(sequence, index, sequence.length - 1));
return left && right;
}BM26 求二叉树的层序遍历
描述
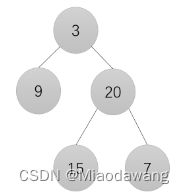
[
[3],
[9,20],
[15,7]思路
代码
public class TempNode {
public TreeNode node;
public int depth=0;
public TempNode(TreeNode node,int depth){
this.node = node;
this.depth = depth;
}
}
public ArrayListBM34 判断是不是二叉搜索树
描述
思路
代码
public ArrayListBM35 判断是不是完全二叉树
描述
思路
代码
public class TempNode {
public TreeNode node;
public int length;
public TempNode(TreeNode node, int length) {
this.node = node;
this.length = length;
}
}
public boolean isCompleteTree (TreeNode root) {
ArrayListBM36 判断是不是平衡二叉树
描述
思路
代码
public boolean IsBalanced_Solution (TreeNode pRoot) {
if(pRoot==null) return true;
if(Math.abs(Depth(pRoot.left)-Depth(pRoot.right))>1){
return false;
}else{
return IsBalanced_Solution(pRoot.left) && IsBalanced_Solution(pRoot.right);
}
}
public int Depth(TreeNode pRoot) {
if (pRoot == null) return 0;
return Math.max(Depth(pRoot.left), Depth(pRoot.right))+ 1;
}
BM37 二叉搜索树的最近公共祖先
描述

思路
代码
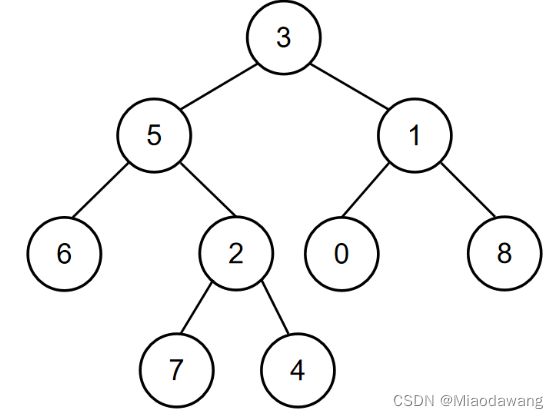
ArrayListBM38 在二叉树中找到两个节点的最近公共祖先
描述
思路
代码
public int lowestCommonAncestor (TreeNode root, int o1, int o2) {
HashMapBM39 序列化二叉树
描述

思路
代码
String Serialize(TreeNode root) {
System.out.println("-----int the Serialize Fuction-----");
String res = "";
if (root == null) return res;
ArrayListBM41 输出二叉树的右视图
描述
要求: 空间复杂度 O(n),时间复杂度 O(n)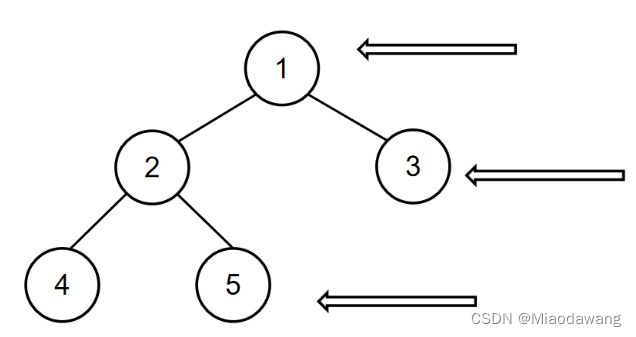
思路
代码
public class TempNode {
int depth = 0;
TreeNode treeNode;
public TempNode(int depth, TreeNode treeNode) {
this.depth = depth;
this.treeNode = treeNode;
}
}
ArrayList二分
BM17 二分查找-I
描述
思路
代码
public int search (int[] nums, int target) {
return searchTarget(nums,target,0,nums.length-1);
}
public int searchTarget(int[] nums,int target,int low,int high){
if(low>high){
return -1;
}else{
int mid = (low + high)/2;
if(nums[mid]==target){
return mid;
}else if(nums[mid]>target){
return searchTarget(nums,target,low,mid-1);
}else{
return searchTarget(nums,target,mid+1,high);
}
}
}BM18 二维数组中的查找
描述
[2,4,9,12],
[4,7,10,13],
[6,8,11,15]思路
代码
public boolean Find (int target, int[][] array) {
int i = array.length-1;
int j = 0;
while(i>=0 && jBM19 寻找峰值
描述
思路一
代码一
public int findPeakElement (int[] nums) {
if (nums.length == 1) return 0;
for (int i = 0; i < nums.length; i++) {
if (i == 0 && nums[i] > nums[i + 1]) return i;
if (i == nums.length - 1 && nums[i] > nums[i - 1]) return i;
if (i!=0 && i!=nums.length - 1 && nums[i] > nums[i - 1] && nums[i] > nums[i + 1]) {
return i;
}
}
return -1;
}思路二
代码二
public int findPeakElement (int[] nums) {
int low = 0;
int high = nums.length-1;
while(lowBM20 数组中的逆序对
描述
数据范围: 对于 50%50% 的数据, size≤10^4
所有数据满足 size≤10^5思路

代码
int count = 0;
public int InversePairs (int[] nums) {
//数组长度小于2时不会出现逆序对
if(nums.length<2) return 0;
mergeSort(nums,0,nums.length-1);
return count;
}
public void mergeSort(int[] nums,int left,int right){
if(leftBM22 比较版本号
描述
思路
代码
public int compare (String version1, String version2) {
//分割
List栈和队列
BM42 用两个栈实现队列
描述
思路
代码
StackBM43 包含min函数的栈
描述
进阶:栈的各个操作的时间复杂度是 O(1) ,空间复杂度是 O(n) 思路
代码
StackBM44 有效括号序列
描述
括号必须以正确的顺序关闭,"()"和"()[]{}"都是合法的括号序列,但"(]"和"([)]"不合法。思路
代码
StackBM45 滑动窗口的最大值
描述
思路
代码
public static ArrayListBM46 最小的K个数
描述
思路
代码
public ArrayListBM47 寻找第K大
描述
思路
代码
public int findKth (int[] a, int n, int K) {
quickSort(a, 0, n-1);
return a[n - K];
}
public void quickSort(int[] a, int low, int high) {
if(low>=high) return;
int partion = doubleSwap(a, low, high);
quickSort(a, low, partion - 1);
quickSort(a, partion + 1, high);
}
public int doubleSwap(int[] a, int low, int high) {
int par = a[low];
int startIndex = low;
System.out.println("low:"+low+"high:"+high);
while (low < high) {
while (low < high && a[high] > par) {
high--;
}
while (low < high && a[low] <= par) {
low++;
}
if (low < high) {
int temp = a[low];
a[low] = a[high];
a[high] = temp;
}
}
int temp = a[high];
a[high] = par;
a[startIndex] = temp;
return high;
}BM48 数据流中的中位数
描述
进阶: 空间复杂度 O(n) , 时间复杂度O(nlogn) 思路
代码
ArrayList栈和队列
BM49 表达式求值
描述
思路
代码
public int solve (String s) {
System.out.println(s);
Stack 哈希
BM50 两数之和
描述
思路
代码
public int[] twoSum (int[] numbers, int target) {
HashMapBM51 数组中出现次数超过一半的数字
描述
思路
代码
public int MoreThanHalfNum_Solution (int[] numbers) {
int res = numbers[0];
int count = 1;
for(int i=1;iBM52 数组中只出现一次的两个数字
描述
思路1
代码1
public int[] FindNumsAppearOnce (int[] nums) {
int[] res = new int[2];
int i=0;
HashMap思路2
代码2
public int[] FindNumsAppearOnce (int[] nums) {
int[] res = new int[2];
int tmp=0;
//得到这两个数不同的那一位
for(int num:nums){
tmp ^= num;
}
System.out.println(tmp);
int mask = 1;
while((mask&tmp)==0){
mask <<= 1;
}
int a = 0;
int b = 0;
for(int num:nums){
if((num&tmp)==0){
a ^= num;
}else{
b ^= num;
}
}
if(a>b){
res[0] = b;
res[1] = a;
}else{
res[0] = a;
res[1] = b;
}
return res;
}BM53 缺失的第一个正整数
描述
思路
代码
public int minNumberDisappeared (int[] nums) {
HashMapBM54 三数之和
描述
例如,给定的数组 S = {-10 0 10 20 -10 -40},解集为(-10, -10, 20),(-10, 0, 10)
思路
代码
public ArrayList回溯
BM55 没有重复项数字的全排列
描述
[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2], [3,2,1].
(以数字在数组中的位置靠前为优先级,按字典序排列输出。)思路

代码
ArrayListBM56 有重复项数字的全排列
描述
思路

代码
boolean[] mark;
ArrayListBM57 岛屿数量
描述
思路
代码
public int solve (char[][] grid) {
int count = 0;
int row = grid.length;
int column = grid[0].length;
if(grid.length==0) return 0;
for(int i=0;iBM58 字符串的排列
描述

思路
代码
boolean[] track;
ArrayListBM59 N皇后问题
描述
要求:任何两个皇后不同行,不同列也不在同一条斜线上,
求给一个整数 n ,返回 n 皇后的摆法数。
思路
代码
int count = 0;
//列
HashSetBM60 括号生成
描述
思路1(超时)
代码1
HashSet思路2
代码2
public ArrayListBM61 矩阵最长递增路径
描述

思路
代码
int maxLength = 0;
public int solve (int[][] matrix) {
LinkedList动态规划
BM62 斐波那契数列
描述
思路
代码
public int Fibonacci (int n) {
if(n==1 || n==2) return 1;
return Fibonacci(n-1)+Fibonacci(n-2);
}BM63 跳台阶
描述
思路
代码
public int jumpFloor (int number) {
if(number==1) return 1;
if(number==2) return 2;
return jumpFloor(number-2)+jumpFloor(number-1);
}BM64 最小花费爬楼梯
描述
你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。思路
代码
public int minCostClimbingStairs (int[] cost) {
int[] dp = new int[cost.length+1];
for(int i=2;i<=cost.length;i++){
dp[i] = Math.min(dp[i-1]+cost[i-1],dp[i-2]+cost[i-2]);
}
return dp[cost.length];
}BM65 最长公共子序列(二)
描述
思路

把上述三种数据来源的方位分别用1,2,3来标记(1来自左上方,2来自左边,3来自上面)

代码
public String LCS (String s1, String s2) {
int[][] dp = new int[s1.length() + 1][s2.length() + 1];
int[][] direction = new int[s1.length() + 1][s2.length() + 1];
String res = "";
for (int i = 0; i < dp.length; i++) {
for (int j = 0; j < dp[i].length; j++) {
if (i == 0 || j == 0) {
dp[i][j] = 0;
direction[i][j] = 0;
} else {
if (s1.charAt(i - 1) == s2.charAt(j - 1)) {
dp[i][j] = dp[i - 1][j - 1] + 1;
direction[i][j] = 1;
} else {
if (dp[i - 1][j] > dp[i][j - 1]) {
dp[i][j] = dp[i - 1][j];
direction[i][j] = 3;
} else {
dp[i][j] = dp[i][j - 1];
direction[i][j] = 2;
}
}
}
}
}
int i = dp.length - 1;
int j = direction[0].length - 1;
while(i>0 && j>0) {
if (direction[i][j] == 1) {
res = s1.charAt(i - 1) + res;
i--;
j--;
} else if (direction[i][j] == 2) {
j--;
} else if (direction[i][j] == 3) {
i--;
} else {
i--;
j--;
}
if (i <= 0) break;
}
if (res.equals("")) {
return "-1";
}
return res;
}BM66 最长公共子串
描述
要求: 空间复杂度 O(n2),时间复杂度 O(n2)思路
代码
public String LCS (String str1, String str2) {
int m = str1.length();
int n = str2.length();
int[][] dp = new int[m+1][n+1];
int maxLength = 0;
int maxLastIndex = 0;
for(int i=0;iBM67 不同路径的数目(一)
描述

思路
代码
public int uniquePaths (int m, int n) {
int[][] dp = new int[m][n];
for(int i=0;iBM68 矩阵的最小路径和
描述

思路
代码
public int minPathSum (int[][] matrix) {
int m = matrix.length;
int n = matrix[0].length;
int[][] dp = new int[m][n];
for(int i=0;iBM69 把数字翻译成字符串
描述
思路
代码
public int solve (String nums) {
int n = nums.length();
if(nums.equals("0")) return 0;
if(nums.length()==1) return 1;
if(nums.equals("10")||nums.equals("20")) return 1;
for(int i=1;iBM70 兑换零钱(一)
描述
思路
假设货币数组为[5,2,3,20],目标值为20
代码
public int minMoney (int[] arr, int aim) {
if(arr.length==0) return -1;
if(aim==0) return 0;
int[] dp = new int[aim+1];
Arrays.fill(dp,aim+1);
dp[0] = 0;
for(int i=0;iBM75 编辑距离(一)
描述
"nowcoder"=>"newcoder"(将'o'替换为'e'),修改操作1次
"nowcoder"=>"new"(删除"coder"),删除操作5次
思路
dp[i][j]表示从两个字符串首部各自到str1[i]和str2[j]为止的子串需要的编辑距离,那很明显dp[str1.length][str2.length]就是我们要求的编辑距离。(下标从1开始)
str1[i]和 str2[j]的位置,这两个字符相同,这多出来的字符就不用操作,操作次数与两个子串的前一个相同,因此有dp[i][j]=dp[i−1][j−1];如果这两个字符不相同,那么这两个字符需要编辑,但是此时的最短的距离不一定是修改这最后一位,也有可能是删除某个字符或者增加某个字符,因此我们选取这三种情况的最小值增加一个编辑距离,dp[i][j]=min(dp[i−1][j−1],min(dp[i−1][j],dp[i][j−1]))+1。代码
public int editDistance (String str1, String str2) {
int len1 = str1.length();
int len2 = str2.length();
int[][] dp = new int[len1+1][len2+1];
for(int j=1;j<=len2;j++){
dp[0][j] = dp[0][j-1] + 1;
}
for(int i=1;i<=len1;i++){
dp[i][0] = dp[i-1][0] + 1;
}
for(int i=1;i<=len1;i++){
for(int j=1;j<=len2;j++){
if(str1.charAt(i-1)==str2.charAt(j-1)){
dp[i][j] = dp[i-1][j-1];
}else{
dp[i][j] = Math.min(dp[i-1][j-1],Math.min(dp[i-1][j],dp[i][j-1]))+1;
}
}
}
return dp[len1][len2];
}BM76 正则表达式匹配
描述
4. 0≤pattern.length≤26 思路
代码
public boolean match (String str, String pattern) {
int n1 = pattern.length();
int n2 = str.length();
boolean[][] dp = new boolean[n1 + 1][n2 + 1];
for (int i = 0; i <= n1; i++)
for (int j = 0; j <= n2; j++) {
if (i == 0) {
dp[i][j] = (j == 0 ? true : false);
} else {
if (i>=1 && j>=1 && pattern.charAt(i - 1) != '*') {
if(pattern.charAt(i-1)==str.charAt(j-1) || pattern.charAt(i-1)=='.'){
dp[i][j] = dp[i-1][j-1];
}
}else{
if(i>=2) dp[i][j] |= dp[i-2][j];
if(i>=2 && j>=1 &&(pattern.charAt(i-2)==str.charAt(j-1) || pattern.charAt(i-2)=='.')){
dp[i][j] |= dp[i][j-1];
}
}
}
}
return dp[n1][n2];
}BM77 最长的括号子串
描述
思路
代码
public int longestValidParentheses (String s) {
int[] dp = new int[s.length()];
int maxLength = 0;
for(int i=0;iBM78 打家劫舍(一)
描述
思路
代码
public int rob (int[] nums) {
int n = nums.length;
if(n==1) return nums[0];
if(n==2) return Math.max(nums[0],nums[1]);
int[] dp = new int[n];
dp[0] = nums[0];
dp[1] = Math.max(nums[0],nums[1]);
int maxMoney = Math.max(dp[0],dp[1]);
for(int i=2;iBM79 打家劫舍(二)
描述
思路
代码
public int rob (int[] nums) {
int n = nums.length;
int[] dp = new int[n];
int res = 0;
dp[0] = nums[0];
//偷第一家不偷最后一家
for (int i = 1; i < n - 1; i++) {
dp[1] = dp[0];
if (i >= 2) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
}
dp[n-1] = dp[n-2];
}
res = dp[n - 1];
dp[0] = 0;
//偷最后一家不偷第一家
for (int i = 1; i < n; i++) {
dp[1] = nums[1];
if (i >= 2) {
dp[i] = Math.max(dp[i - 2] + nums[i], dp[i - 1]);
}
}
return Math.max(res,dp[n-1]);
}BM80 买卖股票的最好时机(一)
描述
思路
代码
public int maxProfit (int[] prices) {
int min = Integer.MAX_VALUE;
int max = 0;
int profit = 0;
int maxProfit = 0;
for(int i=0;iBM81 买卖股票的最好时机(二)
描述
思路
代码
public int maxProfit (int[] prices) {
int n = prices.length;
int[][] dp = new int[2][n];
//第一行表示一直持有股票
dp[0][0] = -prices[0];
//第二行表示一直不持有股票
dp[1][0] = 0;
for(int i=1;ipublic int maxProfit (int[] prices) {
int n = prices.length;
int allProfit = 0;
for(int i=0;iBM82 买卖股票的最好时机(三)
描述
1. 你最多可以对该股票有两笔交易操作,一笔交易代表着一次买入与一次卖出,但是再次购买前必须卖出之前的股票
2. 如果不能获取收益,请返回0
3. 假设买入卖出均无手续费思路
代码
import java.util.*;
public class Solution {
public int maxProfit (int[] prices) {
int n = prices.length;
int[][] dp = new int[n][5];
//初始化dp为最小
Arrays.fill(dp[0], -10000);
//第0天不持有状态
dp[0][0] = 0;
//第0天持有股票
dp[0][1] = -prices[0];
//状态转移
for(int i = 1; i < n; i++){
dp[i][0] = dp[i - 1][0];
dp[i][1] = Math.max(dp[i - 1][1], dp[i - 1][0] - prices[i]);
dp[i][2] = Math.max(dp[i - 1][2], dp[i - 1][1] + prices[i]);
dp[i][3] = Math.max(dp[i - 1][3], dp[i - 1][2] - prices[i]);
dp[i][4] = Math.max(dp[i - 1][4], dp[i - 1][3] + prices[i]);
}
//选取最大值,可以只操作一次
return Math.max(dp[n - 1][2],Math.max(0, dp[n - 1][4]));
}
}双指针
BM90 最小覆盖子串
描述
T="XYZ"
找出的最短子串为"YXNZ".
如果 s 中没有包含 t 中所有字符的子串,返回空字符串 “”;
满足条件的子串可能有很多,但是题目保证满足条件的最短的子串唯一。思路
代码
public String minWindow (String S, String T) {
//已经匹配上的字符数
int match = 0;
int left = 0;
int right = 0;
HashMap贪心
BM93 盛水最多的容器
描述
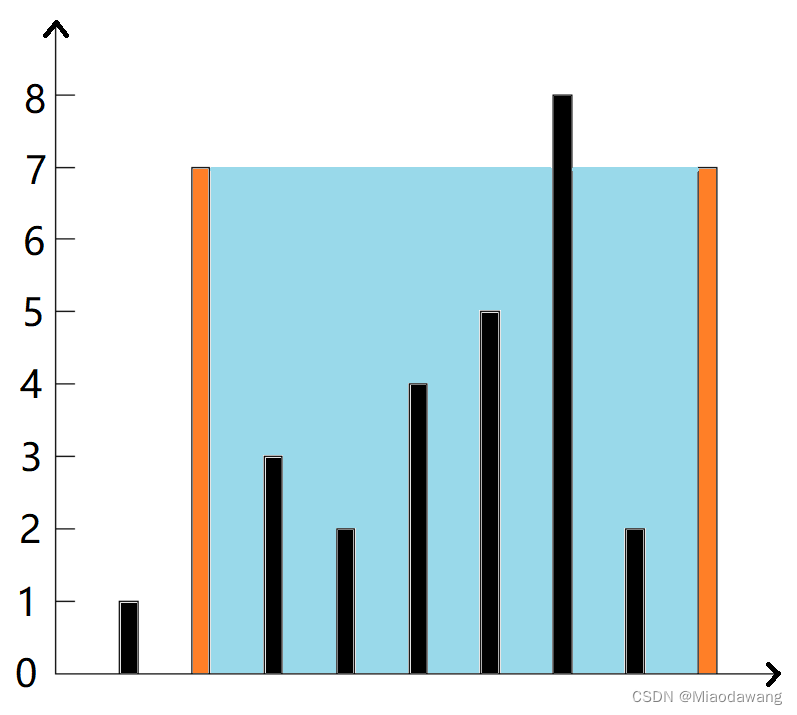
思路
代码
public int maxArea (int[] height) {
//排除不能形成容器的情况
if (height.length < 2)
return 0;
int res = 0;
//双指针左右界
int left = 0;
int right = height.length - 1;
//共同遍历完所有的数组
while (left < right) {
//计算区域水容量
int capacity = Math.min(height[left], height[right]) * (right - left);
//维护最大值
res = Math.max(res, capacity);
//优先舍弃较短的边
if (height[left] < height[right])
left++;
else
right--;
}
return res;
}BM94 接雨水问题
描述
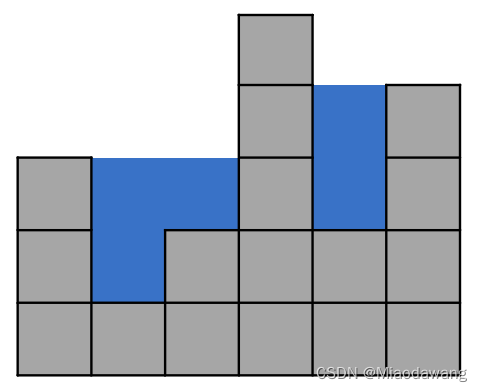
思路


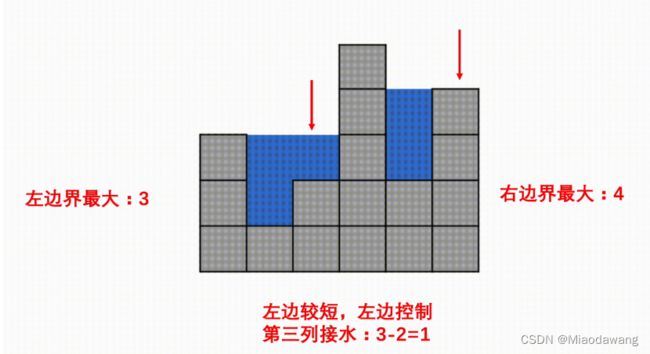


代码
public long maxWater (int[] arr) {
int left = 0;
int right = arr.length-1;
int maxLeft = 0;
int maxRight = 0;
int water = 0;
while(leftBM95 分糖果问题
描述
思路
代码
public int candy (int[] arr) {
if(arr.length<1) return 0;
int[] res = new int[arr.length];
Arrays.fill(res,1);
for(int i=0;iBM96 主持人调度(二)
描述
一位活动主持人在同一时间只能参与一个活动。并且活动主持人需要全程参与活动,换句话说,一个主持人参与了第 i 个活动,那么该主持人在 (starti,endi) 这个时间段不能参与其他任何活动。求为了成功举办这 n 个活动,最少需要多少名主持人。思路
代码
public int minmumNumberOfHost (int n, int[][] startEnd) {
int[] start = new int[n];
int[] end = new int[n];
for (int i = 0; i < n; i++) {
start[i] = startEnd[i][0];
end[i] = startEnd[i][1];
}
Arrays.sort(start);
Arrays.sort(end);
int res = 0;
//j用来记录上一位主持人最后主持的场次下标
int j = 0;
for (int i = 0; i < n; i++) {
if (start[i] >= end[j]) {
j++;
} else {
res++;
}
}
return res;
}BM97 旋转数组
描述
思路
代码
public int[] solve (int n, int m, int[] a) {
//取余,因为每次长度为n的旋转数组相当于没有变化
m = m % n;
//第一次逆转全部数组元素
reverse(a, 0, n - 1);
//第二次只逆转开头m个
reverse(a, 0, m - 1);
//第三次只逆转结尾m个
reverse(a, m, n - 1);
return a;
}
//反转函数
public void reverse(int[] nums, int start, int end) {
while (start < end) {
swap(nums, start++, end--);
}
}
//交换函数
public void swap(int[] nums, int a, int b) {
int temp = nums[a];
nums[a] = nums[b];
nums[b] = temp;
}BM99 顺时针旋转矩阵
描述
思路

代码
public int[][] rotateMatrix (int[][] mat, int n) {
int length = mat.length;
for(int i=0;iBM101 设计LFU缓存结构
描述
思路
代码
import java.util.*;
public class Solution {
//设置节点结构
static class Node {
int freq;
int key;
int val;
//初始化
public Node(int freq, int key, int val) {
this.freq = freq;
this.key = key;
this.val = val;
}
}
//频率到双向链表的哈希表
private Map