【网络通信】详解NIO、select
前言
- 本文地址:https://blog.csdn.net/hancoder/article/details/108899013
- 推荐视频:
- NIO多路复用+系统调用整合讲解:https://www.bilibili.com/video/BV1Ka4y177gs
- 多路复用源码级讲解视频:https://www.bilibili.com/video/BV1pp4y1e7xN
- 推荐视频:https://www.bilibili.com/video/BV1VJ411D7Pm
- 中断、零拷贝等知识:https://blog.csdn.net/hancoder/article/details/112149121
0、 网络编程基础原理
1 网络编程(Socket)概念
首先注意,Socket不是Java中独有的概念,而是一个语言无关标准。任何可以实现网络编程的编程语言都有Socket。
1.1 什么是 Socket
网络上的两个程序通过一个双向的通信连接实现数据的交换,这个连接的一端称为一个socket。
建立网络通信连接至少要一个端口号。socket 本质是编程接口*(API)*,对 TCP/IP 的封装,
TCP/IP 也要提供可供程序员做网络开发所用的接口,这就是 Socket 编程接口;HTTP 是轿车,提供了封装或者显示数据的具体形式;Socket 是发动机,提供了网络通信的能力。
Socket 的英文原义是“孔”或*“插座”。作为 BSD UNIX 的进程通信机制,取后一种意思。通常也称作"套接字"*,用于描述 IP 地址和端口,是一个通信链的句柄,可以用来实现不同虚拟机或不同计算机之间的通信。在 Internet 上的主机一般运行了多个服务软件,同时提供几种服务。每种服务都打开一个 Socket,并绑定到一个端口上,不同的端口对应于不同的服务。
Socket正如其英文原义那样,像一个多孔插座。一台主机犹如布满各种插座的房间,每个插座有一个编号,有的插座提供220伏交流电, 有的提供 110伏交流电,有的则提供有线电视节目。 客户软件将插头插到不同编号的插座,就可以得到不同的服务。
1.2 Socket 连接步骤
根据连接启动的方式以及本地套接字要连接的目标,套接字之间的连接过程可以分为三个步骤:服务器监听,客户端请求,连接确认。【如果包含数据交互*+*断开连接,那么一共是五个步骤】
(1)服务器监听:是服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态。
(2)客户端请求:是指由客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端套接字提出连接请求。
(3)连接确认:是指当服务器端套接字监听到或者说接收到客户端套接字的连接请求,它就响应客户端套接字的请求,建立一个新的线程,把服务器端套接字的描述发给客户端,一旦客户端确认了此描述,连接就建立好了。而服务器端套接字继续处于监听状态,继续接收其他客户端套接字的连接请求。
1.3 Java 中的 Socket
在 java.net 包是网络编程的基础类库。其中 ServerSocket 和 Socket 是网络编程的基础类型。ServerSocket 是服务端应用类型。Socket 是建立连接的类型。当连接建立成功后,服务器和客户端都会有一个 Socket 对象示例,可以通过这个 Socket 对象示例,完成会话的所有操作。
对于一个完整的网络连接来说,Socket 是平等的,没有服务器客户端分级情况。
ServerSocket执行构造方法成功后,其他方法调用都必须放到try-finally块中,以保证ServerSocket都能正常关闭。
同理,accept()返回的Socket,若accept失败,那么必须保证socket不再存在或者含有任何资源,以便不必清除他们。但若执行成功,则后续的语句必须进入一个try-finally块,以保证发生异常的时候,socket都能得到正确清楚。
一次完整的通信有3个socket,服务端的serverSocket在accept成功后会产生一个socket与客户端通信
一、BIO (Blocking I/O)
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
https://zhuanlan.zhihu.com/p/23488863
1.1 传统 BIO
BIO通信(一请求一应答)模型图如下:
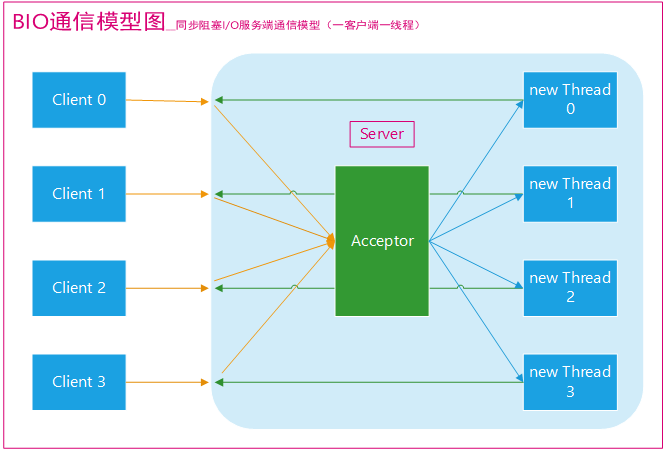
采用 BIO 通信模型 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在while(true) 循环中服务端会调用 accept() 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
- accept() // 阻塞,建立三次握手
- read() //读数据

如果要让 BIO 通信模型 能够同时处理多个客户端请求,就必须使用多线程(主要原因是socket.accept()、socket.read()、socket.write() 涉及的三个主要函数都是【同步 阻塞】的),也就是说服务端它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 一请求一应答通信模型 。
我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 线程池机制 改善,线程池还可以让线程的创建和回收成本相对较低。使用FixedThreadPool 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。
我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
Java BIO 工作机制:
-
- 服务器端启动一个 ServerSocket
-
- 客户端启动 Socket 对服务器进行通信,默认情况下服务器端需要对每个客户 建立一个线程与之通讯
-
- 客户端发出请求后, 先咨询服务器是否有线程响应,如果没有则会等待,或者被拒绝
-
- 如果有响应,客户端线程会等待请求结束后,在继续执行
public class BIOServer {
public static void main(String[] args) throws IOException {
byte[] bytes = new byte[1024];
ServerSocket serverSocket = null;
Socket socket=null;//客户端
InputStream in=null;//输入流
OutputStream out = null;//输出流
//下面的内容要try catch,这里简写
serverSocket = new ServerSocket();
// 端口号+ip,ip默认本机
serverSocket.bind(new InetSocketAddress(9876));//指定监听接口
//serverSocket = new ServerSocket(port);//指定端口 监听
// 阻塞--程序释放cpu资源,程序不会向下执行
// accept,专门负责通信
while(true){
System.out.println("--等待连接--");
socket =serverSocket.accept();//阻塞,三次握手
System.out.println("--连接成功--");
// 解阻塞,向下执行,read也会阻塞
in = socket.getInputStream();
byte[] buffer = new byte[1024];
int length=0;
System.out.println("--开始读数据--");
while((length=in.read(buffer))>0){//阻塞
System.out.println("input is:"+new String(buffer,0,length));
out = socket.getOutputStream();
out.write("success".getBytes);//
}
System.out.println("--数据读取完成:" + read + "--");
}
// finally close
}
}
public class Client {
public static void main(String[] args) throws IOException {
Socket socket = new Socket();
socket.connect(new InetSocketAddress("127.0.0.1", 9876));
System.out.println("--请输入内容--");
Scanner scanner = new Scanner(System.in);
while (true) {
String next = scanner.next();
socket.getOutputStream().write(next.getBytes());
}
}
}
阻塞和非阻塞是针对于进程在访问数据的时候,根据 IO 操作的就绪状态来采取的不同方式,说白了是一种读取或者写入操作方法的实现方式,阻塞方式下读取或者写入函数将一直等待,而非阻塞方式下,读取或者写入方法会立即返回一个状态值。
以银行取款为例:
阻塞 : ATM 排队取款,你只能等待(使用阻塞 IO 时,Java 调用会一直阻塞到读写完成才返回);
非阻塞 : 柜台取款,取个号,然后坐在椅子上做其它事,等号广播会通知你办理,没到号你就不能去,你可以不断问大堂经理排到了没有,大堂经理如果说还没到你就不能去(使用非阻塞IO 时,如果不能读写 java 调用会马上返回,当 IO 事件分发器通知可读写时再继续进行读写,不断循环直到读写完成)
1.2 伪异步 IO(多线程BIO)
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化—后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N。通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。

采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层仍然是同步阻塞的BIO模型,因此无法从根本上解决问题。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏洞,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
每个线程管理一个连接
// 多线程BIO 服务端
public class IOServer {
public static void main(String[] args) throws IOException {
// 服务端处理客户端连接请求
ServerSocket serverSocket = new ServerSocket(3333);
/*
ServerSocket serverSocket = new ServerSocket();
serverSocket.bind(new InetSocketAddress(9876));
*/
// 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
new Thread(() -> {
while (true) {//循环
try {
// 阻塞方法获取新的连接,阻塞
Socket socket = serverSocket.accept();
// 每一个新的连接都创建一个线程,负责读取数据
new Thread(() -> {
try {
int len;
byte[] data = new byte[1024];
InputStream inputStream = socket.getInputStream();
// 按字节流方式读取数据
while ((len = inputStream.read(data)) != -1) {
System.out.println(new String(data, 0, len));
}
} catch (IOException e) {
}
}).start();
/* 也可以把线程都提交到线程池里
newCachedThreadPool.execute(new Runnable() {
@Override
public void run() {
//业务处理
myHandler(socket);// 把业务代码写到里面
}
});
*/
} catch (IOException e) {
}
}
}).start();
}
}
或者在服务端采用线程池的方案
1) 使用 BIO 模型编写一个服务器端,监听 6666 端口,当有客户端连接时,就启动一个线程与之通讯。
2) 要求使用线程池机制改善,可以连接多个客户端.
3) 服务器端可以接收客户端发送的数据(telnet 方式即可)。
// 尝试使用线程池解决BIO的问题
public class BIOServer {
public static void main(String[] args) throws Exception {
//线程池机制
//思路
//1. 创建一个线程池
//2. 如果有客户端连接,就创建一个线程,与之通讯(单独写一个方法)
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
//创建 ServerSocket
ServerSocket serverSocket = new ServerSocket(6666);
System.out.println("服务器启动了");
while (true) {
System.out.println(" 线 程 信 息 id =" + Thread.currentThread().getId() + " 名 字 =" +
Thread.currentThread().getName());
//监听,等待客户端连接
System.out.println("等待连接....");
final Socket socket = serverSocket.accept();
System.out.println("连接到一个客户端");
//就创建一个线程,与之通讯(单独写一个方法)
newCachedThreadPool.execute(new Runnable() {
public void run() {
//处理连接 //可以和客户端通讯
handler(socket);
}
});
}
}
//编写一个 handler 方法,和客户端通讯
public static void handler(Socket socket) {
try {
System.out.println(" 线 程 信 息 id =" + Thread.currentThread().getId() +
" 名 字 =" +Thread.currentThread().getName());
byte[] bytes = new byte[1024];
//通过 socket 获取输入流
InputStream inputStream = socket.getInputStream();
//循环的读取客户端发送的数据
while (true) {
System.out.println(" 线 程 信 息 id =" + Thread.currentThread().getId() +
" 名 字 =" + Thread.currentThread().getName());
System.out.println("read....");
int read = inputStream.read(bytes);
if(read != -1) {
System.out.println(new String(bytes, 0, read)); //输出客户端发送的数据
} else {
break;
}
}
}catch (Exception e) {
e.printStackTrace();
}finally {
System.out.println("关闭和 client 的连接");
try {
socket.close();
}catch (Exception e) {
e.printStackTrace();
}
}
}
}
// 客户端
public class IOClient {
public static void main(String[] args) {
// TODO 创建多个线程,模拟多个客户端连接服务端
new Thread(() -> {
try {
Socket socket = new Socket("127.0.0.1", 3333);
while (true) {
try {
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
Thread.sleep(2000);
} catch (Exception e) {
}
}
} catch (IOException e) {
}
}).start();
}
}
BIO的问题
Java BIO 问题分析
-
每个请求都需要创建独立的线程,与对应的客户端进行数据 Read,业务处理,数据 Write 。
-
当并发数较大时,需要创建大量线程来处理连接,系统资源占用较大。
-
连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费
BIO的通信过程
- 加入你正在家打游戏,且刚点了外卖。吃东西的状态为休眠状态stop,打游戏为running
- 外卖来了,即中断请求IRQ,中断处理程序存档游戏(用户态到内核态)取外卖,吃东西的状态改为就绪状态
- 取完后,不只可以执行打游戏了,还可以执行吃东西。两个都处于就绪态
中断与系统调用
零拷贝、DMA、中断等内容请参考:
https://blog.csdn.net/hancoder/article/details/112149121
可编程中断控制器:
如下有用户空间和内核空间。
INTR是中断引脚,中断控制器有8个IR,两个级联就有64个可能。中断请求寄存器里保存中断信号,比如键盘字符。优先级解析器是为了区分中断的优先级。正在服务寄存器是为了执行完后清空,然后寄存器就能再往里添加值了,再给CPU处理
可编程中断控制器:
socket缓冲区:每个socket有两个缓冲区:输入缓冲区和输出缓冲区
- 写操作都会映射到内核的write和send。先把数据从用户空间的缓冲区拷贝到内核空间的缓冲区,然后TCP/IP会把数据包装成报文发送。
- 读操作都会映射到内核的read和recv。读的话是先是把数据映射到内核空间缓冲区,再从内核空间的缓冲区拷贝到用户空间的缓冲区。
上层socket发送完后close后并不影响内核空间的发送,数据不会丢,TCP/IP会保证。但是如果没读完的输入缓冲区就会直接丢弃
socket缓冲区:

BIO与NIO的区别:
- bio写:BIO输出的时候会检查输出缓冲区可用空间,如果可用大小不够就会阻塞到可用空间够,比如要写2mb,但是内核空间只有1mb,就会阻塞到TCP把内核空间的数据发送腾出空间后2mb放入。TCP如果正在写的话会给内核缓冲区加锁。比如要发10mb,但是内核空间最大只有5mb,就会先发5mb然后挂起进程,tcp发送完上个5mb后再唤醒进程再发送剩下的5mb
- bio读:也会映射到内核的read和recv系统调用,检查内核缓冲区是否有数据,有数据的话读取,没的话阻塞当前调用进程,直到网络有数据输入到输入缓冲区后,程序才会中断唤醒该进程。如果读的缓存没有输入缓冲区大,就多次读。buffer大小小的话多次读取。
- NIO:
- nio写:也会进行用户空间到内核空间的拷贝,但是此时会检查内核输出缓冲区大小够不够,不够的话尽可能拷贝,比如要写2mb,可用1mb,就先写1mb,然后返回到用户态告诉写了多少。如果内核可用空间为0,也会立马返回-1(BIO会等待),就可以选择等待一会还是立即重试。
- nio读:也会映射到内核的read和recv系统调用,检查内核缓冲区是否有数据,有的话就返回,没的话也返回不会阻塞。
- 多路复用:
- 问题描述:解决上面客户端和服务端进程需要1对1的问题,我们想让服务端一个进程监听客户端多个进程。比如客户端不断发到服务端的输入缓冲区,服务器负载很高了cpu没有空闲,所以服务器进程一直抢不到cpu资源。流量控制拥塞控制总是满的话,再发的时间会延长。如果客户端是BIO的话客户端也会阻塞,客户端如果是NIO的话返回-1
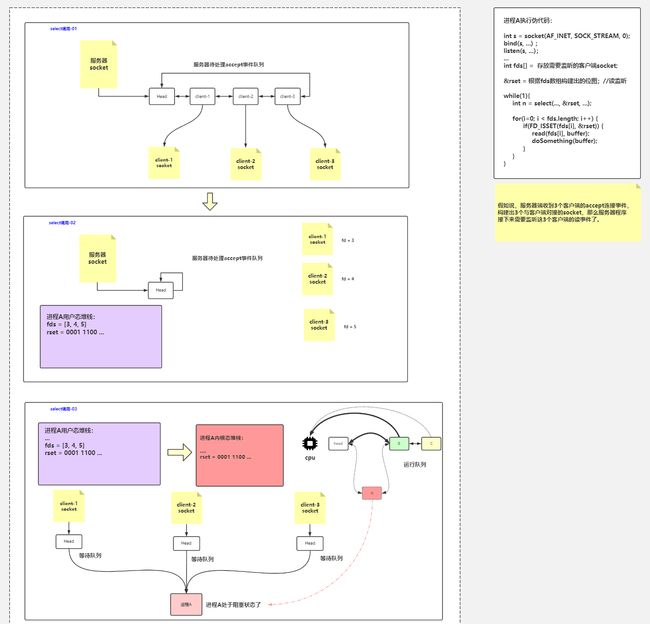
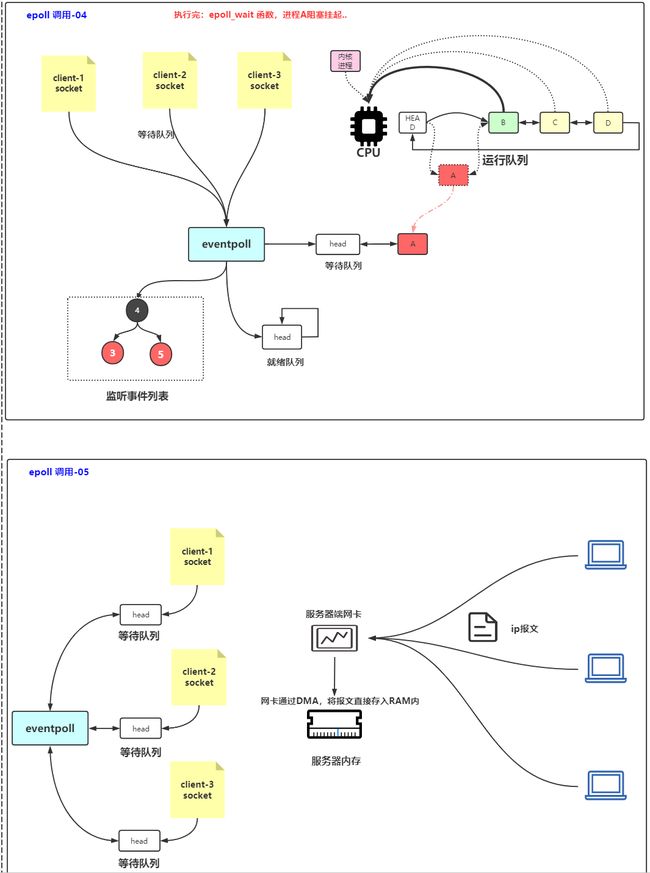
- 解决方案:一个进程监听多个socket,select/epoll就是为了解决这个问题。选择器将选择信息告诉内核,即告诉监听哪些套接字。关心的状态。返回的时候会告诉就绪的套接字的数量,有哪些描述符就绪,就可以点用读写函数,病人不会被调用,
1 BIO读数据
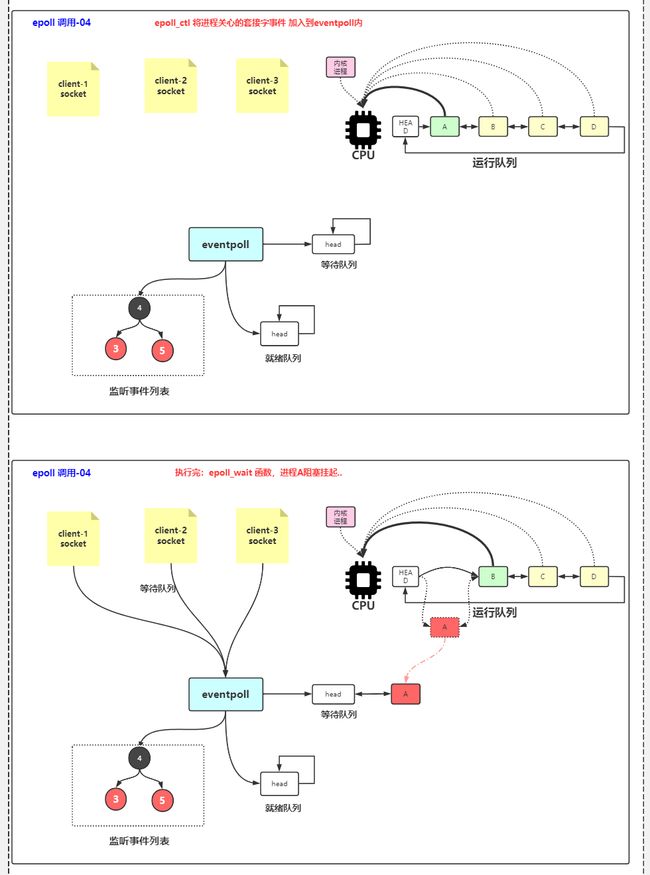
CPU上有运行队列(就绪队列),选一个运行。比如A运行时执行到了socket.read()读数据。没有可读数据会被阻塞
2 没有数据后阻塞
进程A被阻塞后从运行队列中拿出,移动到等待队列(阻塞/等待队列),进程B/C/D去执行
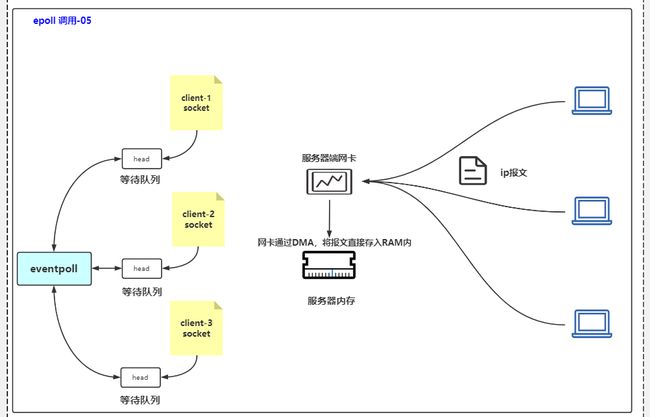
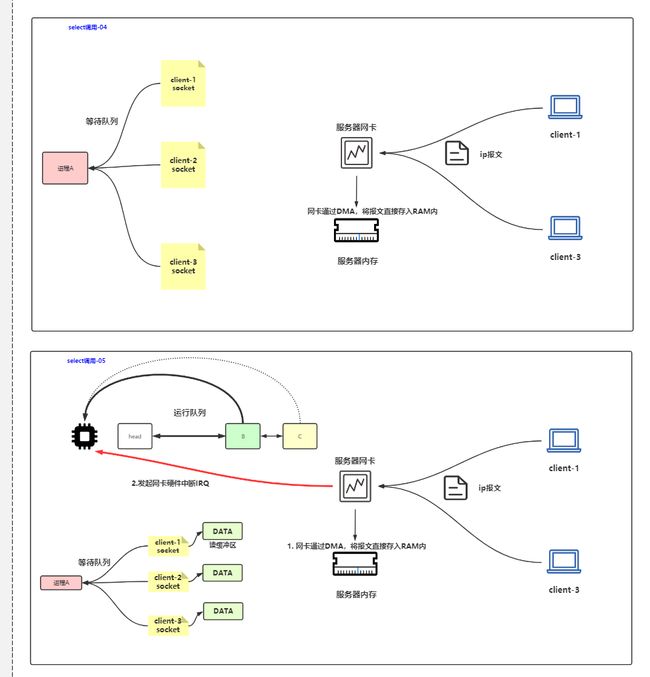
3 数据来了
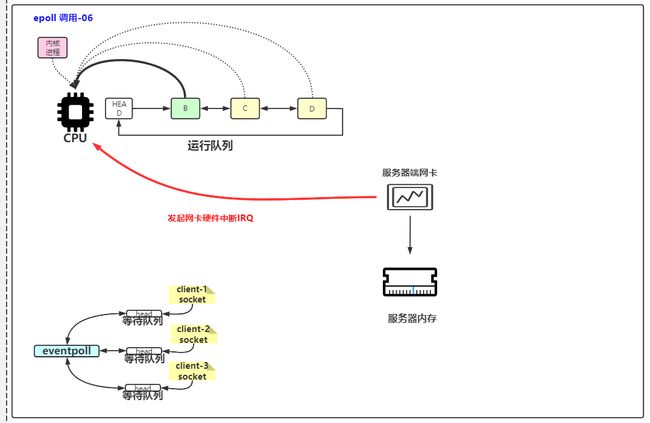
客户端发来了数据,报文到达服务器网卡后,网卡通过DMA,将报文直接存入内核态缓冲区,网卡发起硬件中断
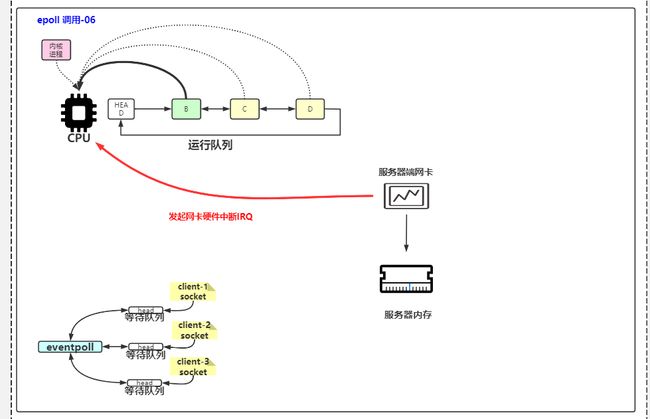
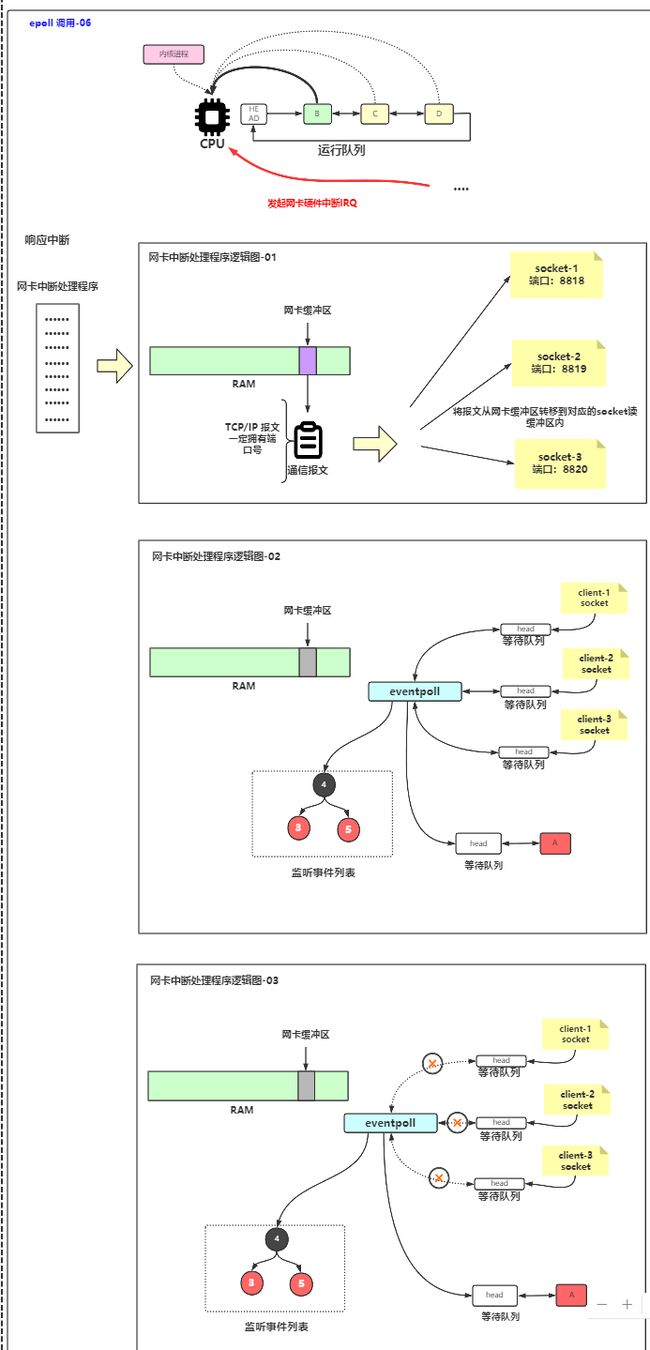
4 网卡发起硬件中断
网卡发起硬件中断,让cpu进入内核态
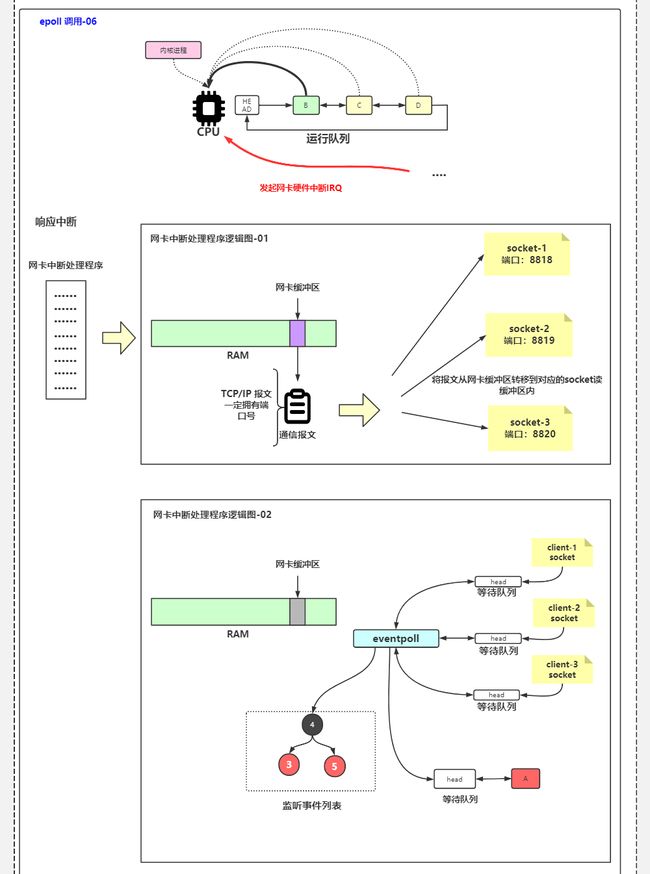
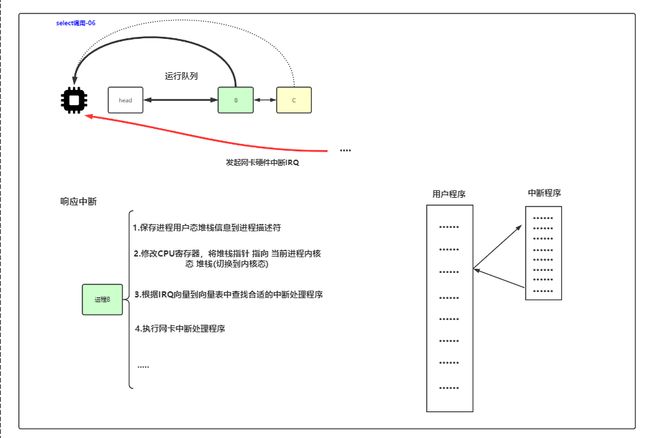
5 响应中断、保存信息、切换状态
cpu要进入内核态,所以把正在执行的进程B挂起,在这个过程中,需要
- 保存用户态堆栈信息到进程描述符、
- 修改CPU寄存器,将堆栈指针指向当前进程内核态堆栈
- 切换到内核态
- 根据IRQ( Interrupt Request)向量到向量表中查找合适的中断处理程序
- 指向网卡中断程序
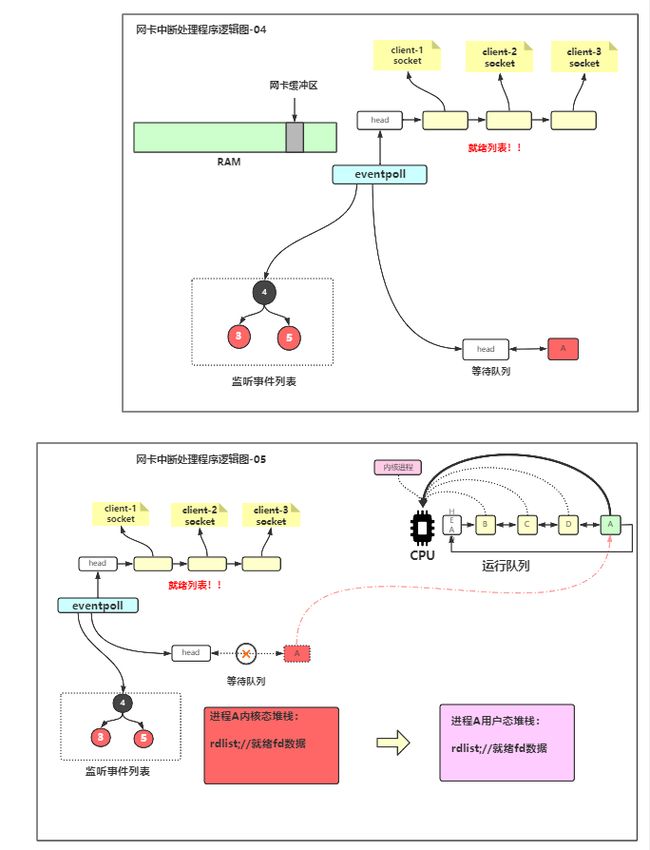
6 中断处理程序
一条条处理报文,报文中有端口信息,就能查找到对应的socket,把数据放到对应socket的读缓冲区。
进程A从等待(阻塞)队列中出队,转移到运行(就绪)队列
7 拿到数据运行
进程A进入到运行队列
缺点:服务端进程和客户端进程1对1
RandomAccessFile
支持随机读写seek。seek后再写,会覆盖原来地方,相当于覆盖到中间了
既支持读,也支持写,指定mode
他的write是写到文件里
网络IO流程
客户端的socket从网卡进来
应用程序通过内核,内核去网卡拿数据。拿到数据后先到内核,然后再传给应用程序。
一个线程依次进行accept和read操作,第二个客户端client来了之后只在网卡,并没连接到
read的取字节流,
又来一个client后,应用程序线程阻塞
图来源:迄今为止 https://www.bilibili.com/video/BV1VJ411D7Pm
非阻塞IO(NIO)服务端一个线程维护多个client
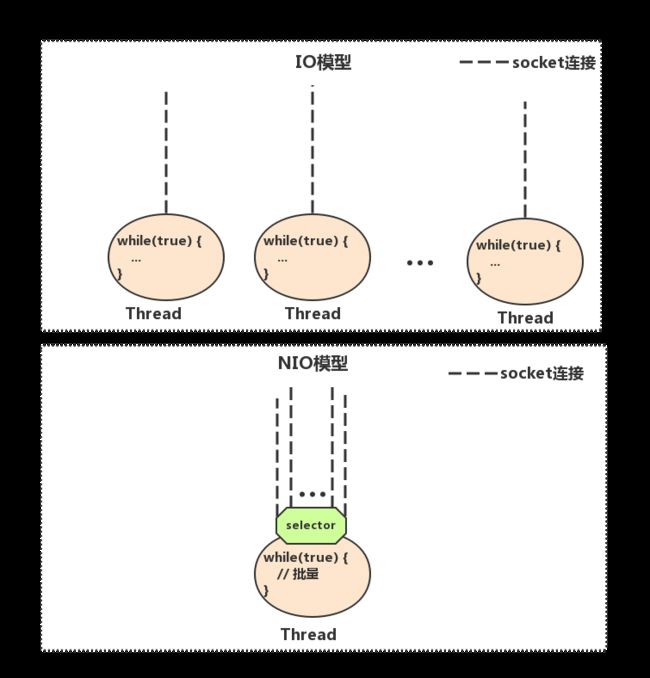

linux select函数详解
在Linux中,我们可以使用select函数实现I/O端囗的复用,传递给select函数的参数会告诉内核:(设置select)
1,我们所关心的文件描述符
2.对每个描述符,我们所关心的状态。
3.我们要等待多长时间。
从select函数返回后,内核告诉我们一下信息:
1.对我们的要求已经做好准备的描述符的个数
2.对于三种条件哪些描述符已经准备(读,写,异常)
有了这些返回信息,我们可以调用合适的I/O函数(通常是read或write),且这些函数不会再阻塞.
课程大纲:http://note.youdao.com/s/GkwuyYC7
可编程中断控制器:https://www.processon.com/view/link/5f5b1d071e08531762cf00ff
系统调用的过程:https://www.processon.com/view/link/5f5edf94637689556170d993
socket缓冲区:https://www.processon.com/view/link/5f5c4342e0b34d6f59ef7057
bio通信底层原理:https://www.processon.com/view/link/5f61bd766376894e32727d66
linux select函数API:https://www.processon.com/view/link/5f601ed86376894e326d9730
linux select原理图:https://www.processon.com/view/link/5f62b9a6e401fd2ad7e5d6d1
linux epoll函数:https://www.processon.com/view/link/5f6034210791295dccbc1426
linux epoll原理图:https://www.processon.com/view/link/5f62f98f5653bb28eb434add
多个线程上,再继续运行。例如客户端需要发送数据给服务器端,只当客户端所有的数据都准备完毕后,选择器才会将这个注册的通道分配到服务器端的一个或多个线程上。而在客户端准备数据的这段时间,服务器端的线程可以执行别的任务。
三 AIO
(Asynchronous I/O) AIO 异步IO也就是 NIO 2。在 Java 7 中引入,它是异步非阻塞的IO模型。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
AIO解决的问题:虽然NIO解决了阻塞的问题,但是还是同步的,意思是说你得自己去问selector有没有数据,有没有准备好。而AIO是异步的,相当于回调函数,有数据了它会通知你。
除了 AIO 其他的 IO 类型都是同步的,这一点可以从底层IO线程模型解释,推荐一篇文章:什么是Linux的五种IO模型?
目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
四、NIO
多线程需要上下文切换(从运行态到阻塞态,保存堆栈信息),耗时
我们相用单线程。
网络连接
sockfd = socket(AF_INET,SOCK_STREAM,0);
memset(&addrm0,sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port=htons(2000);
NIO和IO适用场景:
NIO是为弥补传统IO的不足而诞生的,但是尺有所短寸有所长,**NIO也有缺点,因为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那么就会有一个问题,在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕,如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。**所以每次数据处理之前都要检测缓冲区数据。
那么NIO和IO各适用的场景是什么呢?
- 如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。
- 而如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
但是实际上使用时无需考虑场景问题,直接使用Netty等搭建的NIO即可
Java IO是阻塞的,如果在一次读写数据调用时数据还没有准备好,或者目前不可写,那么读写操作就会被阻塞直到数据准备好或目标可写为止。Java NIO则是非阻塞的,每一次数据读写调用都会立即返回,并将目前可读(或可写)的内容写入缓冲区或者从缓冲区中输出,即使当前没有可用数据,调用仍然会立即返回并且不对缓冲区做任何操作。这就好像去超市买东西,如果超市中没有需要的商品或者数量还不够,那么BIO会一直等直到超市中需要的商品数量足够了就将所有需要的商品带回来,NIO则不同,不论超市中有多少需要的商品,它都会立即买下可以买到的所有需要的商品并返回,甚至是没有需要的商品也会立即返回。
阻塞IO会使得线程将大量的时间浪费在等待IO上,这是非常不划算的,但是这种阻塞可以在数据可用时立即获取并处理数据,而非阻塞IO则必须通过重复的调用来获取全部数据。
Java NIO 使用Selector实现单线程管理多个Channel,通过 select 调用,可以获取已经准备好的Channel并进行相应的处理。
多个客户端都连到了服务端的网卡,epoll会把这些链接都拿过来监视,数据准备非阻塞,数据拷贝阻塞一个一个的,但最终都会把client处理。epoll改善了数据拷贝工作,零拷贝,从网卡放到硬盘,从内核空间到用户空间拷贝的是内存地址
发展历史
了解这个基本的概念以后,其他的就很好解释了。
select, poll, epoll 都是I/O多路复用的具体的实现,之所以有这三个鬼存在,其实是他们出现是有先后顺序的。
I/O多路复用这个概念被提出来以后, select是第一个实现 (1983 左右在BSD里面实现的)。
select 被实现以后,很快就暴露出了很多问题。
- select 会修改传入的参数数组,这个对于一个需要调用很多次的函数,是非常不友好的。
- select 如果任何一个sock(I/O stream)出现了数据,select 仅仅会返回,但是返回后并不会告诉你是哪个sock上有数据,于是你只能自己一个一个的找,10几个sock可能还好,要是几万的sock每次都找一遍,这个无谓的开销就颇有海天盛筵的豪气了。
- select 只能监视1024个链接,linux 定义在头文件中的,参见
FD_SETSIZE。 - select 不是线程安全的,如果你把一个sock加入到select, 然后突然另外一个线程发现这个sock不用,要收回。对不起,这个select 不支持的,如果你丧心病狂的竟然关掉这个sock, select的标准行为是。。呃。。不可预测的, 这个可是写在文档中的哦 “If a file descriptor being monitored by select() is closed in another thread, the result is unspecified”
于是14年以后(1997年)一帮人又实现了poll, poll 修复了select的很多问题,比如
- poll 去掉了1024个链接的限制
- poll 从设计上来说,不再修改传入数组,不过这个要看你的平台了,所以行走江湖,还是小心为妙。
- poll仍然不是线程安全的, 这就意味着,不管服务器有多强悍,你也只能在一个线程里面处理一组I/O流。你当然可以那多进程来配合了,不过然后你就有了多进程的各种问题。
其实拖14年那么久也不是效率问题, 而是那个时代的硬件实在太弱,一台服务器处理1千多个链接简直就是神一样的存在了,select很长段时间已经满足需求。
于是5年以后, 在2002, 大神 Davide Libenzi 实现了epoll
epoll 可以说是I/O 多路复用最新的一个实现,epoll 修复了poll 和select绝大部分问题, 比如:
- epoll 现在是线程安全的。
- epoll 现在不仅告诉你sock组里面数据,还会告诉你具体哪个sock有数据,你不用自己去找了。
- 只有linux支持
epoll 当年的patch,现在还在,下面链接/dev/epoll Home Page
贴一张霸气的图,看看当年神一样的性能(测试代码都是死链了, 如果有人可以刨坟找出来,可以研究下细节怎么测的)
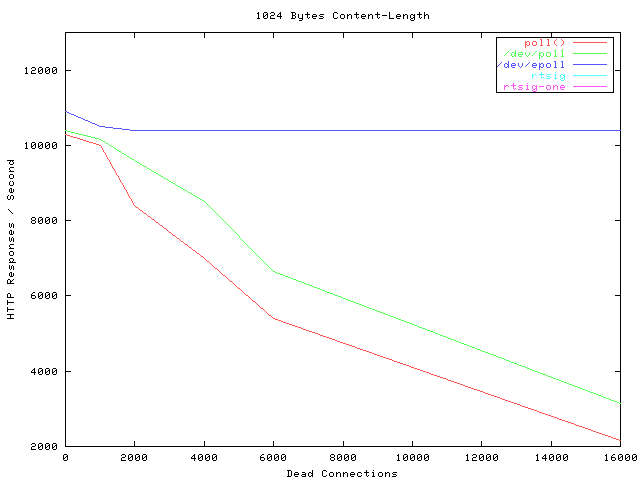
横轴Dead connections 就是链接数的意思,叫这个名字只是它的测试工具叫deadcon. 纵轴是每秒处理请求的数量,你可以看到,epoll每秒处理请求的数量基本不会随着链接变多而下降的。poll 和/dev/poll 就很惨了。
可是epoll 有个致命的缺点:只有linux支持。比如BSD上面对应的实现是kqueue。
其实有些国内知名厂商把epoll从安卓里面裁掉这种脑残的事情我会主动告诉你嘛。什么,你说没人用安卓做服务器,尼玛你是看不起p2p软件了啦。
而ngnix 的设计原则里面, 它会使用目标平台上面最高效的I/O多路复用模型咯,所以才会有这个设置。一般情况下,如果可能的话,尽量都用epoll/kqueue吧。
select、poll、epoll
文件描述符(File Descriptor,FD):是一个抽象的概念,形式上是一个整数,实际上是一个索引值,指向内核中为每个进程维护进程所打开的文件的记录表。当程序打开一个文件或者创建一个文件时,内核就会向进程返回一个FD。Unix,Linux
文件描述符在网络通信中也就是链接的链接socket
- select机制:会维护一个GC的集合fd_set,将fd_set从用户空间复制到内核空间,激活socket。fd_set是一个数组结构
- poll机制:和select机制是差不多的,把fdset结构进行了优化,FD集合的大小就突破了操作系统的限制。pollfd结构代替fdset,通过链表实现的
- epoll(Event Poll):不再扫描所有的FD,只将用户关心的FD的事件存放到内核的一个事件表当中。这样,可以减少用户空间和内核空间之间需要拷贝到数据
面试要点:文件描述符、个数限制、数组每回都需要初始化,数组复制耗性能、事件驱动
| 操作方式 | 底层实现 | 最大连接数 | IO效率 | |
|---|---|---|---|---|
| select | 遍历 | 数组 | 受限于内核 | 一般 |
| poll | 遍历 | 链表 | 无上限 | 一般 |
| epoll | 事件回调 | 红黑树 | 无上限 | 高 |
while(1)遍历文件描述符集合fdA-E。
nginx和redis采用了epoll
应用程序线程内有多路复用器,多路复用器有select函数,调用内核的epoll()(要分清代码里的select函数和内核的epoll函数,它会根据系统自动转换)
内核有epoll【根据版本的不同也可以可能是select()/poll()】
假如现在有多个客户端client链接到网卡。epoll会把3个client都做数据准备,放到内核空间,然后把3个数据的索引值返回给应用程序的多路复用器。多路复用器的select再去调用recFrom方法,挨个告诉内核要拷贝哪个数据,然后把数据从内核空间拷贝到用户空间。
数据准备是非阻塞的,数据拷贝是阻塞的。线程最终都会把client的数据处理,对于应用程序而言处理也是非阻塞的,因为多路复用器可以把这堆数据都拿过来。根据业务操作做一些读写操作而已handler()。多路复用器管理了多个client。
从内核空间拷贝到用户空间消耗很大,所以epoll有了零拷贝。即公共的内存空间,即直接缓冲区
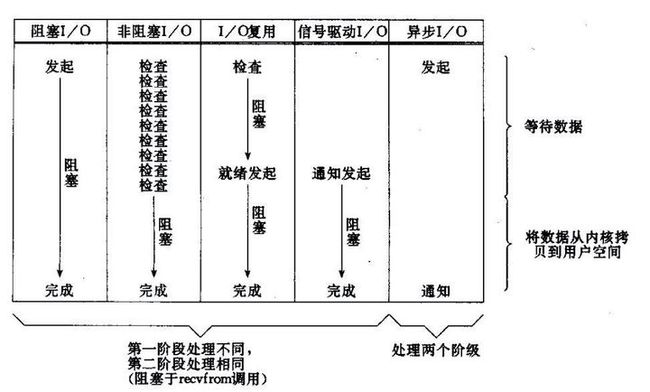
阻塞IO
应用程序accept()阻塞,取的是socket
应用程序read()阻塞,取的是字节流
内核recvFrom(block,…)
五、NIO Reactor(NIO的改进)
这里的改进主要还是让各个功能各司其职,为每个功能建立线程。如建立多个selector线程去accept,接收到之后把任务提交到线程池,让线程池找个线程去处理read操作
为何要用Reactor:常见的网络服务中,如果每一个客户端都维持一个与登陆服务器的连接。那么服务器将维护多个和客户端的连接以出来和客户端的connect 、read、write ,特别是对于长链接的服务,有多少个客户端,就需要在服务端维护同等的IO连接。这对服务器来说是一个很大的开销。
长链接:一个socket处理多个请求连接
BIO:
我们采用线程池的方式来处理读写服务。但是这么做依然有很明显的弊端:
- 同步阻塞IO,读写阻塞,线程等待时间过长
- 在制定线程策略的时候,只能根据CPU的数目来限定可用线程资源,不能根据连接并发数目来制定,也就是连接有限制。否则很难保证对客户端请求的高效和公平。
- 多线程之间的上下文切换,造成线程使用效率并不高,并且不易扩展
- 状态数据以及其他需要保持一致的数据,需要采用并发同步控制
NIO:
事实上NIO已经解决了上述BIO暴露的1&2问题了,服务器的并发客户端有了量的提升,不再受限于一个客户端一个线程来处理,而是一个线程可以维护多个客户端(selector 支持对多个socketChannel 监听)。
但这依然不是一个完善的Reactor Pattern ,首先Reactor 是一种设计模式,好的模式应该是支持更好的扩展性,显然以上的并不支持,另外好的Reactor Pattern 必须有以下特点:
- 更少的资源利用,通常不需要一个客户端一个线程
- 更少的开销,更少的上下文切换以及locking
- 能够跟踪服务器状态
- 能够管理handler 对event的绑定
NIO Reactor单线程
有事件发生后,交给一个handler处理
public class TCPReactor{
private final ServerSocketChannel ssc;
private final Selector selector;
TCPReactor(int port){
selector = Selector.open();// 创建选择器对象
ssc = ServerSocketChannel.open();//打开服务端socket
InetSocketAddress addr = new InetSocketAddress(port);
ssc.socket().bind(addr);//在ServerSocketChannel绑定端口
ssc.configureBlocking(false);//设置ServerSocketChannel非阻塞
Selection sk = ssc.register(selector,SelectionKey.OP_ACCEPT);//ServerSocketChannel注册进selector中,监听的是ACCEPT事件 // 客户端有连接来了通知服务端
// 这个Acceptor和上面的服务端ssc是关联的
sk.attach(new Acceptor(selector,ssc));// 给定key一个附加的Acceptor对象,如果事件没有被 // 这句可以写到上句中
}
NIO Reactor多线程
有事件发生后,交给多个handler处理
如果读写耗时的话,我们可以另开一个线程处理读写
NIO Reactor主从模型
多个selector
提升:多拿几个selector
多buffer的分散(Scatter)与聚集(Gather)
- 分散读取(Scattering Reads):将通道中的数据分散到多个缓冲区中
- 聚集写入(Gathering Writes):将多个缓冲区中的数据聚集到通道中
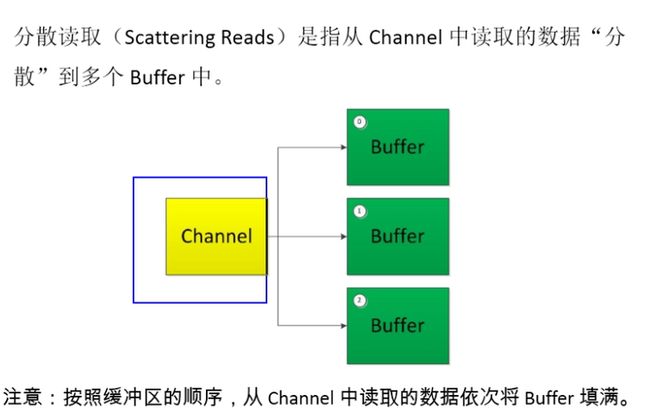

读写案例代码
@Test
public void test1() throws IOException {
// rw代表 读写模式
RandomAccessFile file = new RandomAccessFile("D:\\学习使用NIO.md","rw");
FileChannel channel = file.getChannel();
// 分配制定多个缓冲区
ByteBuffer byteBuffer1 = ByteBuffer.allocate(1024*2);
ByteBuffer byteBuffer2 = ByteBuffer.allocate(1024*6);
ByteBuffer byteBuffer3 = ByteBuffer.allocate(1024*5);
// 分散读取,从通道读取到多个缓存区
ByteBuffer[] buffers= {byteBuffer1,byteBuffer2,byteBuffer3};
channel.read(buffers);
//将多个缓冲区翻转
for (ByteBuffer buffer : buffers) {
buffer.flip();
}
// 聚集写入
RandomAccessFile file2 = new RandomAccessFile("D:\\nio2.txt","rw");
// 获取 通道
FileChannel channel2 = file2.getChannel();
channel2.write(buffers);
channel.close();
channel2.close();
}
字符集Charset
设置字符集,解决乱码问题
编码:字符串->字节数组
解码:字节数组->字符串
思路
用Charset.forName(String)构造一个编码器或解码器,利用编码器和解码器来对CharBuffer编码,对ByteBuffer解码。
需要注意的是,在对CharBuffer编码之前、对ByteBuffer解码之前,请记得对CharBuffer、ByteBuffer进行flip()切换到读模式。
如果编码和解码的格式不同,则会出现乱码
@Test
public void CharacterEncodingTest() throws CharacterCodingException {
//加载字符集
Charset charset = Charset.forName("utf-8");
Charset charset1 = Charset.forName("gbk");
// 获取编码器 utf-8
CharsetEncoder encoder = charset.newEncoder();
// 获得解码器 gbk
CharsetDecoder decoder = charset1.newDecoder();
CharBuffer buffer = CharBuffer.allocate(1024);//char
buffer.put("哈哈哈哈!");//5个汉字,10B
// 编码
buffer.flip();//切换
ByteBuffer byteBuffer = encoder.encode(buffer);//对buffer编码
for (int i = 0; i < 10; i++) {
System.out.println(byteBuffer.get());//显示数字
}
// 解码
byteBuffer.flip();//切换
CharBuffer charBuffer = decoder.decode(byteBuffer);//对buffer解码
System.out.println(charBuffer.toString());//有tostring方法
}
在for循环中使用过到了ByteBuffer的get()方法。一开始习惯性的在get()方法里加上了变量i随即出现了问题,无法取得数据。注释代码byteBuffer.flip();之后可以执行。当直接使用get()方法时,不加byteBuffer.flip();则会报错。所以就来区别一下ByteBuffer里的get();与get(int index);的区别。
查看get();方法源码:
/*** Relative get method. Reads the byte at this buffer's
* current position, and then increments the position.
* @return The byte at the buffer's current position
*
* @throws BufferUnderflowException
* If the buffer's current position is not smaller than its limit
*/
public abstract byte get();
可以看出返回的值是“ The byte at the buffer’s current position”,就是返回缓冲区当前位置的字节。"then increments the position"也说明了返回字节之后,position会自动加1,也就是指向下一字节。
上述情况如果是get(index),则是下面的方法:
/**
* Absolute get method. Reads the byte at the given index.
* @param index
* The index from which the byte will be read
* @return The byte at the given index
* @throws IndexOutOfBoundsException
* If index is negative or not smaller than the buffer's limit
*/
public abstract byte get(int index);
由“The byte at the given index”可以知道返回的是给定索引处的字节。position并未移动。如果之后再执行flip();操作则读取不到任何数据。原因接着往下看。
六、多路复用
链接:https://www.zhihu.com/question/32163005/answer/55772739
第一种方法就是最传统的多进程并发模型 (每进来一个新的I/O流会分配一个新的进程管理。)
第二种方法就是I/O多路复用 (单个线程,通过记录跟踪每个I/O流(sock)的状态,来同时管理多个I/O流 。)
*其实“I/O多路复用”这个坑爹翻译可能是这个概念在中文里面如此难理解的原因。所谓的I/O多路复用在英文中其实叫 I/O multiplexing. 如果你搜索multiplexing啥意思,基本上都会出这个图:


于是大部分人都直接联想到"一根网线,多个sock复用" 这个概念,包括上面的几个回答, 其实不管你用多进程还是I/O多路复用, 网线都只有一根好伐。多个Sock复用一根网线这个功能是在内核+驱动层实现的。
重要的事情再说一遍: I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sockect的状态(对应空管塔里面的Fight progress strip槽)来同时管理多个I/O流. 发明它的原因,是尽量多的提高服务器的吞吐能力。
是不是听起来好拗口,看个图就懂了
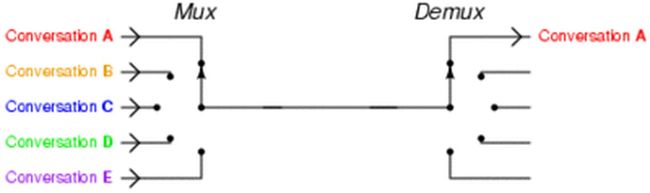
在同一个线程里面, 通过拨开关的方式,来同时传输多个I/O流, (学过EE的人现在可以站出来义正严辞说这个叫“时分复用”了)。
什么,你还没有搞懂“一个请求到来了,nginx使用epoll接收请求的过程是怎样的”, 多看看这个图就了解了。提醒下,ngnix会有很多链接进来, epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。
管道(Pipe)
Java NIO 管道是两个线程之间的单向数据连接。Pipe有一个source通道和一个sink通道。数据会被写到sink通道,从source通道读取。
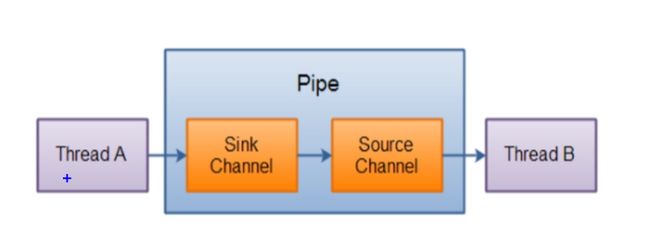
代码示例
@Test
public void test() throws IOException {
// 获取管道
Pipe pipe = Pipe.open();
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 将缓冲区中数据写入管道
Pipe.SinkChannel sinkChannel = pipe.sink();
buffer.put("要死了要死了要死了,,,救救孩子吧".getBytes());
buffer.flip();
sinkChannel.write(buffer);
// 为了省事,就不写两个线程了
// 读取缓冲区中数据
Pipe.SourceChannel sourceChannel = pipe.source();
buffer.flip();
System.out.println(new String(buffer.array(),0,sourceChannel.read(buffer)));
sinkChannel.close();
sourceChannel.close();
}
epoll流程
1 建立连接、创建文件描述符
3个客户端发起的链接请求,服务端serverSocket接收到链接请求,accept接收到
建立链接后就形成了socket链接,在操作系统中表现为3个文件描述符。

3 注册事件
把socket关注的事件注册到selector上,此时selector不仅知道了哪个socket,还知道对应socket要进行的事件,如读、写、accept。(还知道哪个网口对应的哪个socket)
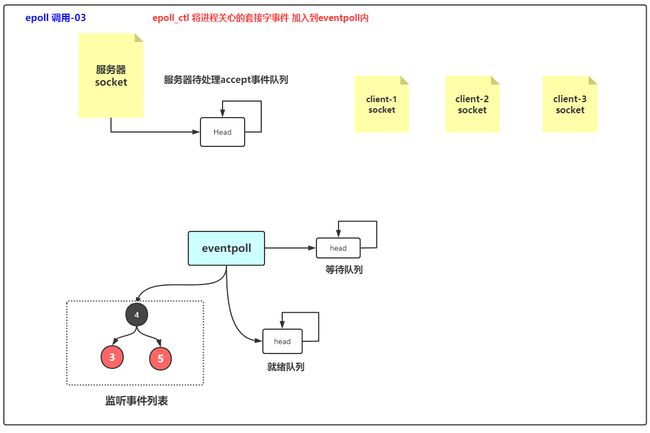
4 阻塞
socket要读数据却没有数据,就阻塞,等selector得到对应的事件变化后处理该事件。
这里还可以说说的是唤醒的不是线程,因为多路复用并非一个线程对应一个链接,而是拿到事件之后去线程池拿个线程去处理
5 DMA读到缓冲区
DMA会读到socket缓冲区或内核缓冲区,内核缓冲区和用户态缓冲区交互,而socket缓冲区和内核缓冲区及网卡交互,但在零拷贝mmap或sendfile中工具机制有所区别
6 网卡硬件中断
DMA读到内核缓冲区后发起硬件中断,CPU保存当前用户态里的用户态堆栈信息,然后将指针指向内核态堆栈,然后IRQ去向量表中查当前要处理的是什么中断,知道是80中断之后去读数据

七、代码演示
聊天室案例
BIO聊天(单线程)
缺点:该服务端只能服务一个用户
ServerSocket serverSocket = new ServerSocket(81);
System.out.println("启动服务器"+serverSocket);
try {
Socket socket = serverSocket.accept();
try {
System.out.println("客户端连接"+ socket);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out =
new PrintWriter(new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())), true);//PrintWriter的第二个参数bool值,指出是否在每一次println()结束的时候自动刷新输出缓冲区(但不适用于print()语句每次写人了输出内容后(写进out),它的缓冲区必须刷新,使信息能正式通过网络传递出去。
while (true){
String str = in.readLine();
if (str.equals("END"))
break;
System.out.println(str);
out.println("服务器回复"+str);//服务器回复客户端来信:0
}
}finally {
System.out.println("关闭");
socket.close();
}
}finally {
serverSocket.close();
}
/*
启动服务器ServerSocket[addr=0.0.0.0/0.0.0.0,localport=8080]
客户端连接Socket[addr=/127.0.0.1,port=54036,localport=8080]
客户端来信:0
客户端来信:1
客户端来信:2
客户端来信:3
客户端来信:4
客户端来信:5
客户端来信:6
客户端来信:7
客户端来信:8
客户端来信:9
关闭
* */
public class Client_Socket {
public static void main(String[] args) throws IOException {
InetAddress addr = InetAddress.getByName(null);//null就会默认查找localhost
System.out.println("地址:"+addr);
Socket socket = new Socket(addr, Server_Socket.PORT);
try {
System.out.println("Socket="+socket);
BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter out =
new PrintWriter(new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())),true);
for (int i = 0; i < 10; i++) {
out.println("客户端来信:"+i);// 传给服务端
String str = in.readLine();
System.out.println(str);
}
out.println("END");
}finally {
System.out.println("关闭");
socket.close();
}
}
}
/*
地址:localhost/127.0.0.1
Socket=Socket[addr=localhost/127.0.0.1,port=8080,localport=54036]
服务器回复客户端来信:0
服务器回复客户端来信:1
服务器回复客户端来信:2
服务器回复客户端来信:3
服务器回复客户端来信:4
服务器回复客户端来信:5
服务器回复客户端来信:6
服务器回复客户端来信:7
服务器回复客户端来信:8
服务器回复客户端来信:9
关闭
*/
程序的下一部分是创建流,以便读取和写入,只是InputStream和OutputStream是从Socket对象创建的。
利用两个“转换器”类InputStreamReader和OutputStreamWriter,InputStream和OutputStream对象已经分别转换成为Reader和Writer对象。
也可以直接使用lnputStrearn和OutputStream类,但对输出来说,使用Writer方式具有明显的优势。
这一优势是通过PrintWriter表现出来的,它有一个重载的构造方法,能获取第二个参数:一个布尔值标志,指出是否在每一次println()结束的时候自动刷新输出缓冲区(但不适用于print()语句每次写人了输出内容后(写进out),它的缓冲区必须刷新,使信息能正式通过网络传递出去。对目前这个例子来说,刷新显得尤为重要,因为客户和服务器在采取下一步操作之前都要等待一行文本内容的到达,若刷新没有发生.那么信息不会进人网络,除非缓冲区满(溢出),这会为本程序带来许多问题
编写网络应用程序时,要特别注意自动刷新机制的使用。每次刷新缓冲区时,须创建和发出一个数据包(数据封)。
就目前的情况来说,这正是我们所希望的,因为假如包内包含了还没有发出的文本行,服务器和客户机之间的相互联糸就会停止。
换句话说,一行的末尾就是一条消息的末尾。但在其他许多情况下,消息并不是用行分隔的,所以不如不用自动刷新机制,而用内建的缓冲区判决机制来决定何时发送一个数据包。这样一来,我们可以发出较大的数据包,而且处理进程也能加快。注意,和我们打开的几乎所有数据流一样,它们都要进行缓冲处。无限while循环从BufferedReader in内读取文本行,并将信息写入System.out,然后写人PrintWriter类型的out。注意这可以是任何数据流,它们只是在表曲上同网络连接。客户程序发出包含了“END"的行后,程序会中止循环,并关闭Socket
若客户端没有刷新,那么整个会话都会被挂起,因为用于初始化的“客户端来信”永远不会发生出去(缓冲区不够满,不足以造成发送动作的自动进行)
BIO聊天(线程池)
前面的BIO中的Server_Socket每次只能为一个客户程序提供服务,在服务器中,我们希望同时处理多个用户的请求。解决方案是线程池。
八、源码
预备知识:
0 bitmap
fd set。1024bit,sock值,use include posix types h
// cat usr/include/linux/posix_types.h
/*
0标准输入
1 标准输出
2 标准出错
3 listenfd
4 connfd1
5 connfd2
6 connfd3
。。。
*/
#undef __FD_SETSIZE
#define __FD_SETSIZE 1024
typedef struct {
unsigned long fds_bits[__FD_SETSIZE / (8 * sizeof(long))];
} __kernel_fd_set; // 这就是我们的fd-set。是一个数组,总的bit数为1024 //对应的sock是其中的一位
/* Type of a signal handler. */
typedef void (*__kernel_sighandler_t)(int);
/* Type of a SYSV IPC key. */
typedef int __kernel_key_t;
typedef int __kernel_mqd_t;
#include /* 由于太长时间没看C语言,总觉得像java一样有浅拷贝的问题,但复习了一下C语言, 发现结构体是可以相互赋值的,而且赋值的是成员数据,不是地址。而且每个成员也会深拷贝。 此外,数组在C语言中虽然不可以直接互相赋值,一般用的是mset,但是也可以利用结构体实现直接互相赋值。(利用结构体达到数组深拷贝的小技巧)https://blog.csdn.net/junkeal/article/details/86764461 C语言结构体初始化问题:https://blog.csdn.net/weixin_42445727/article/details/81191327 */ #include "stdio.h" struct date { int i; float x; } d1={10,12.5}; void main() { struct date d2; d2=d1; printf("%d, %f\n",d2.i,d2.x); } // 以下代码编译不通过 int a[5] = {1,2,3,4,5}; int b[5]; b = a; // 以下代码完全城阙,而且是深拷贝 typedef struct{ int a[10]; }S; S s1 = { {1,2,3,4,5,6,7,8,9,0} }, s2; s2 = s1; //分别打印以下s1,s2
查看几个宏:用来设置fd_set的
//man FD_SET
NAME
select, pselect, FD_CLR, FD_ISSET, FD_SET, FD_ZERO - synchronous I/O multiplexing
SYNOPSIS
int select(int nfds,
fd_set *readfds, //读的文件描述符
fd_set *writefds, // 写的文件描述符
fd_set *exceptfds, // 异常的文件描述符
struct timeval *timeout);
void FD_CLR(int fd, fd_set *set);//置0某位
int FD_ISSET(int fd, fd_set *set);//判断某位
void FD_SET(int fd, fd_set *set);//置1某位
void FD_ZERO(fd_set *set);//置0全部
#include
int pselect(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, const struct timespec *timeout,
const sigset_t *sigmask);
1 select函数
man 2 select监听多个文件描述符,知道一个或多个文件描述符准备好IO操作
select() and pselect() allow a program to monitor multiple file descriptors, waiting until one or more of the file descriptors become “ready” for some class of I/O operation (e.g., input possible).
A file descriptor is considered ready if it is possible to perform a corresponding I/O operation (e.g., read(2) without blocking, or a sufficiently small write(2)).
linux select原理图:https://www.processon.com/view/link/5f62b9a6e401fd2ad7e5d6d1
linux select()函数详解
在Linux中,我们可以使用select函数实现I/O端口的复用,传递给select函数的参数会告诉内核:
- 1.我们所关心的文件描述符
- 2.对每个描述符,我们所关心的状态。
- 3.我们要等待多长时间。
内核遍历文件描述符,从select函数返回后,内核告诉我们以下信息:
select()返回值:
- 1.对我们的要求已经做好准备的描述符的个数
- 正数:做好准备的文件描述符的个数,
- 0:超时
- -1:错误
- 2.对于三种条件哪些描述符已经做好准备.(读,写,异常)(有了这些返回信息,我们可以调用合适的I/O函数(通常是read或write),并且这些函数不会再阻塞.)
流程:
- 创建socket的集合文件描述符数组
fd_set,让是一个bitmap结构,是二进制,1024长度 - 把监听的socket和客户端的socket加入集合fd_set
- select(maxfd,fd_set,NULL,NULL,NULL)
- 把FD_ISSET判断fd_set中有事件的socket
- 监听socket有事件,表示由新客户段的连接请求。同时把新的客户端加入到fd_set
- 客户端的socket有事件:
- 有数据可读:去读数据
- socket连接断开的事件:把socket从fd_set中移除。有客户端新连接或断开时fd_set才更新
Lnux select函数接口
select缺点
- ① bitmap只有1024位,
- ② 另外fd置位后,
rset就被修改过了,下一次while时就会情况rset,然后再把rset赋进来,FDset是不可重用的 - ③ 从用户态拷贝到内核态的rset费时
- ④ 返回的时候并不知道具体是哪个,需要遍历,所以O(n)
#includelinux中有一些宏,方便对上面select函数中bitmap进行操作
//相应的,Linux提供了一组宏。来为fdset进行赋值等操作。//其实他本来只是工具,并不是提供给socket的,只是socket可用
#includec++使用select的demo:从下面可以观察到,我们使用select还得每次都清零然后for赋值,select返回后继续遍历进行read

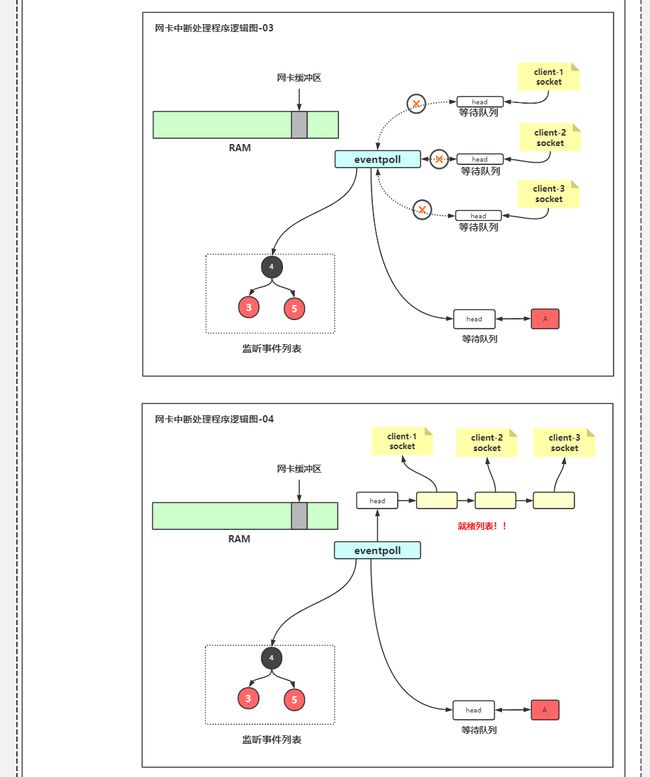
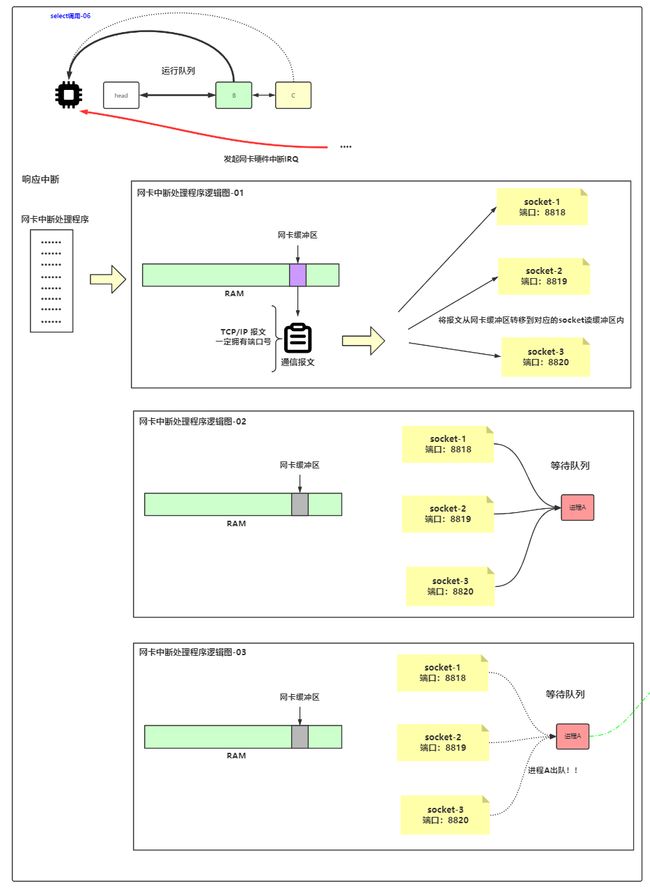
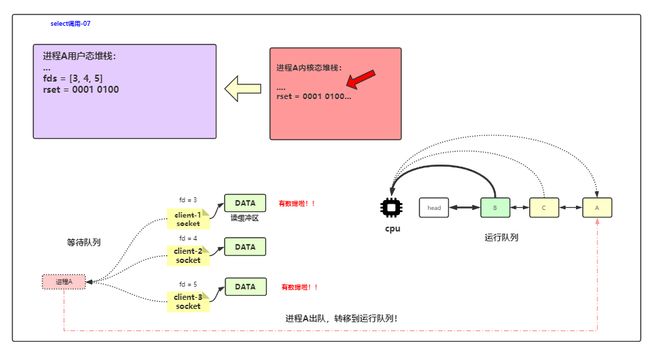
select流程
- 3个连接请求到来,服务器处理accept事件队列,建立连接,然后去读
- 进程A从用户态进入内核态,然后阻塞
- 数据来了之后DMA把数据从网卡读到内核缓冲区,发起硬件中断,CPU进入内核态,
- CPU进入内核态前保存用户态堆栈信息到pd
- 修改CPU寄存器,将堆栈指针指向当前进程内核态堆栈
- 根据IRQ向量到向量表查找合适的中断处理程序
- 执行网卡中断处理程序
- 遍历得到的数组,得到是谁的数据来了,
- 唤醒进程A,进程A转到就绪队列
2 poll
linux epoll函数:https://www.processon.com/view/link/5f6034210791295dccbc1426
- poll和select在本质上没有差别,管理多个文件描述符并且进行轮询,根据描述符的状态进行处理,
- 但是poll没有最大文件描述符数量的限制。
- select采用
bitmap在用户态和内核态之间拷贝,poll采用了数组。 - poll和select同样存在一个缺点就是,文件描述符的数组被整体复制于用户态和内核态的地址空间之间,而不论这些文件描述符是否有事件,它的开销随着文件描述符的数量的增加而线性增大
- 还有poll返回后,也需要遍历整个描述符的数组才能得到有事件的描述符
- 线程不安全
- 就解决了个数量限制问题
int poll(struct pollfd *fds,//结构体数组指针,但也不是无穷大,ulimit -n ,即100001
mfds_t nfds,
int timeout);//单位为微秒
struct pollfd{
int fd;//文件描述符 //如果是负数的话,就会忽略他,所以我们可以初始化数组里全部元素的该属性为-1
short events;//请求事件,在意的事件,如读、写
short revents;//返回事件,回馈,一开始是0
};
//man poll
事件有
POLLIN ,有数据读There is data to read.
POLLPRI
POLLOUT,Writing is now possible, though a write larger that the available space in a socket or pipe will still block (unless O_NONBLOCK is set).
POLLRDHUP
POLLERR
POLLHUP
POLLPRI
There is some exceptional condition on the file descriptor. Possibilities include:
* There is out-of-band data on a TCP socket (see tcp(7)).
* A pseudoterminal master in packet mode has seen a state change on the slave (see ioctl_tty(2)).
* A cgroup.events file has been modified (see cgroups(7)).
while(1){
puts("round again");
poll(pollgds,5,5000);//5个元素,5000超时时间
for(i=0;i<5;i++){
}
}
也是阻塞的
没采用bitmap,采用的是pollfd,
置位是revent,所以可以重用
3 epoll函数
linux epoll原理图:https://www.processon.com/view/link/5f62f98f5653bb28eb434add
epoll是在2.6内核中提出的,是之前的select和poll的增强版本。相对于select和poll来说,epoll更加灵活,没有描述符限制。epoll使用一个文件描述符冒理多个描述符,将用户关心的文件描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一次。
- 返回具体哪个发生了事件,无需遍历fd Set
- 用户关心的文件描述符的事件放到内核中,只需拷贝一次
- 线程安全
epoll接口
epoll操作过程需要三个接口,分别如下:epoll_create、epoll_ctl、epoll_wait
// 比如nginx,先有serverSocket的fd6,然后用epoll_create创建fd8,然后epoll_ctl(8,,6)让8持有6,然后epoll_wait(8)内核会告诉有什么事件到达
#includestruct epoll_event{
_uint32_t events;/*Epoll events*/
epoll_data_t data;/*User data variable*/
};
// man epoll
events可以是以下几个宏的集合:
EPOLLIN、//读
EPOLLOUT、//写
EPOLLPRI、
EPOLLERR、
EPOLLHUP(挂断)、
EPOLLET(边缘触发)、
EPOLLONESHOT(只监听一次,事件触发后从epoll列表自动清除该fd)
epoll里就不需要把监听的集合在用户空间和内核空间来回拷贝了
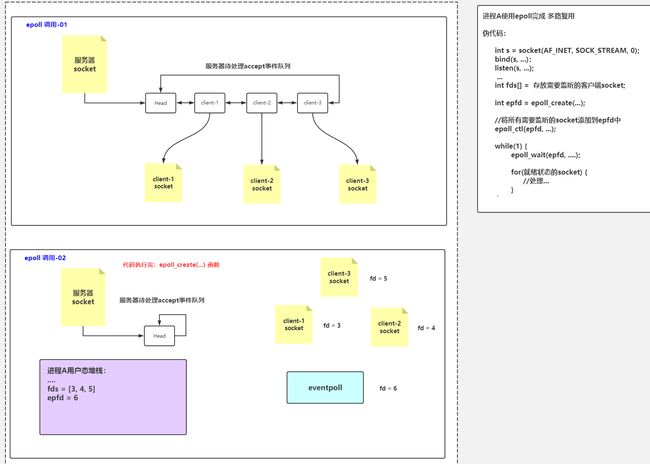
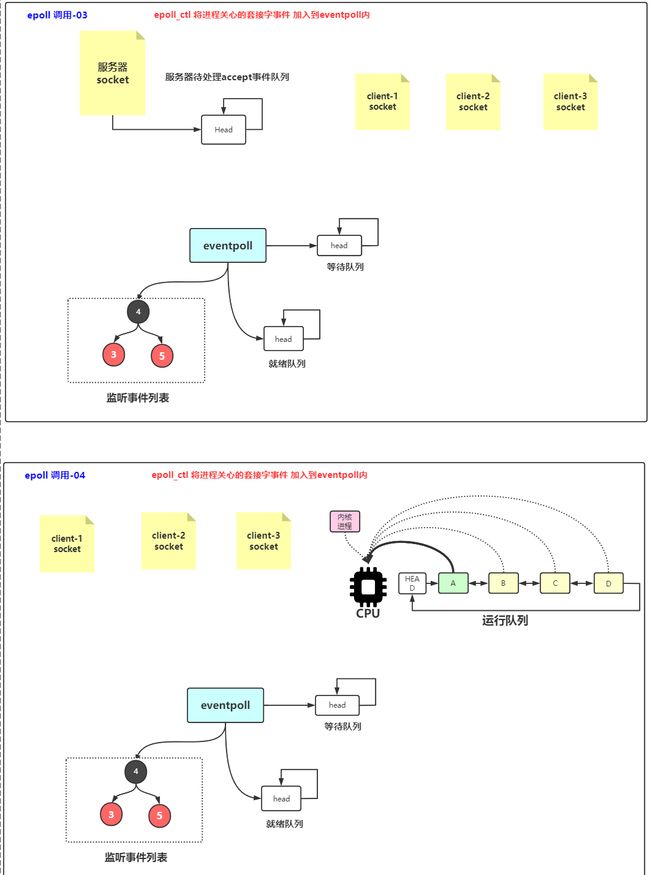
epoll流程
(1)epoll_create函数是一个系统函数,函数将在内核空间内开辟一块新的空间,可以理解为epoll结构空间,返回值为epoll的文件描述符编号,方便后续操作使用。
(2)epoll_ctl是epoll的事件注册函数,epoll与select不同,select函数是调用时指定需要监听的描述符和事件,epoll先将用户感兴趣的描述符事件注册到epoll空间内,此函数是非阻塞函数,作用仅仅是增删改epoll空间内的描述符信息。
-
参数一:epfd,很简单,epoll结构的进程fd编号,函数将依靠该编号找到对应的epoll结构。
-
参数二:op,表示当前请求类型,由三个宏定义
(EPOLL_CTL_ADD:注册新的fd到epfd中).(EPOLL_CTL_MOD:修改已经注册的fd的监听事件)、(EPOLL_CTL_DEL:从epfd中删除一个fd) -
参数三:fd,需要监听的文件描述符。一般指socket_fd
-
参数四:event,告诉内核对该fd资源感兴趣的事件。
(3)epoll_wait等待事件的产生,类似于select()调用。根据参数timeout,来决定是否阻塞。
- 参数一:epfd,指定感兴趣的epoll事件列表。
- 参数二:
*events,是一个指针,须指向一个epoll_event结构数组,当函数返回时,内核会把就绪状态的数据拷贝到该数组中!携带回发生事件的数据 - 参数三:maxevents,标明参数二epoevent数组最多能接收的数据量,即本次操作最多能获取多少就绪数据
- 参数四:timeout,单位为毫秒。
- 0:表示立即返回,菲咀塞调用。
- -1:阻塞调用,直到有用户感兴趣的事件就绪为止。
>0:阻塞调用,阻塞指定时间内如果有事件就绪则提前返回,否则等待指定时间后返回。
- 返回值:本次就绪的fd个数。
工作模式
epoll对文件描述符的操作有两种模式LT(水平触发)和ET(边缘触发)。LT模式是默认模式,LT模式与ET模式的区别如下
- LT(水平触发):事件就绪后,用户可以选择处理者不处理,如果用户本次未处理,那么下次调用
epoll_wait时仍然会将未处理的事件打包给你。如果报告了fd事件没有被处理或数据没有被全部读取,那么epoll会立即再报告该fd。select和poll都采用水平触发 - ET(边缘触发):事件就绪后,用户必须处理,因为内核不给你兜底了,内核把就绪的事件打包给你后,就把对应的就绪事件清理掉了。如果报告了fd后事件没有被处理或者数据没有被全部读取,那么epoll会下次再报告该fd
- ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。

九、C语言使用示例
①select示例
#include ②poll示例
#include ③epoll示例
#include client
#include 十、零拷贝
https://blog.csdn.net/hancoder/article/details/112149121