python 爬虫请求模块requests
文章目录
-
- requests
-
- requests安装
- requests库的基本使用
- 响应对象response的⽅法
- 状态码
- 请求⽅式
-
- GET请求
- POST请求
- 请求头
-
- requests设置代理
- cookie
- session
- 处理不信任的SSL证书
requests
相比urllib,第三方库requests更加简单人性化,是爬虫工作中常用的库
requests安装
初级爬虫的开始主要是使用requests模块
安装requests模块:
Windows系统:
cmd中:
pip install requests
mac系统中:
终端中:
pip3 install requests
requests库的基本使用
import requests
url = 'https://www.csdn.net/'
reponse = requests.get(url)
#返回unicode格式的数据(str)
print(reponse.text)
响应对象response的⽅法
response.text 返回unicode格式的数据(str)
response.content 返回字节流数据(⼆进制)
response.content.decode(‘utf-8’) ⼿动进⾏解码
response.url 返回url
response.encode() = ‘编码’
状态码
response.status_code: 检查响应的状态码

例如:
200 : 请求成功
301 : 永久重定向
302 : 临时重定向
403 : 服务器拒绝请求
404 : 请求失败(服务器⽆法根据客户端的请求找到资源(⽹⻚))
500 : 服务器内部请求
# 导入requests
import requests
# 调用requests中的get()方法来向服务器发送请求,括号内的url参数就是我们
# 需要访问的网址,然后将获取到的响应通过变量response保存起来
url = 'https://www.csdn.net/' # csdn官网链接链接
response = requests.get(url)
print(response.status_code) # response.status_code: 检查响应的状态码
200
请求⽅式
requests的几种请求方式:
p = requests.get(url)
p = requests.post(url)
p = requests.put(url,data={'key':'value'})
p = requests.delete(url)
p = requests.head(url)
p = requests.options(url)
GET请求
HTTP默认的请求方法就是GET
* 没有请求体
* 数据必须在1K之内!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
POST请求
(1). 数据不会出现在地址栏中
(2). 数据的大小没有上限
(3). 有请求体
(4). 请求体中如果存在中文,会使用URL编码!
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
请求头
当我们打开一个网页时,浏览器要向网站服务器发送一个HTTP请求头,然后网站服务器根据HTTP请求头的内容生成当此请求的内容发送给服务器。
我们可以手动设定请求头的内容:
import requests
header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
url = 'https://www.csdn.net/'
reponse = requests.get(url,headers=header)
#打印文本形式
print(reponse.text)
requests设置代理
使⽤requests添加代理只需要在请求⽅法中(get/post)传递proxies参数就可以了
cookie
cookie :通过在客户端记录的信息确定⽤户身份
HTTP是⼀种⽆连接协议,客户端和服务器交互仅仅限于 请求/响应过程,结束后 断开,下⼀次请求时,服务器会认为是⼀个新的客户端,为了维护他们之间的连接, 让服务器知道这是前⼀个⽤户发起的请求,必须在⼀个地⽅保存客户端信息。
requests操作Cookies很简单,只需要指定cookies参数即可
import requests
#这段cookies是从CSDN官网控制台中复制的
header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'cookie': 'uuid_tt_dd=10_30835064740-1583844255125-466273; dc_session_id=10_1583844255125.696601; __gads=ID=23811027bd34da29:T=1583844256:S=ALNI_MY6f7VlmNJKxrkHd2WKUIBQ34Bbnw; UserName=xdc1812547560; UserInfo=708aa833b2064ba9bb8ab0be63866b58; UserToken=708aa833b2064ba9bb8ab0be63866b58; UserNick=xdc1812547560; AU=F85; UN=xdc1812547560; BT=1590317415705; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_30835064740-1583844255125-466273!5744*1*xdc1812547560; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; log_Id_click=1; Hm_lvt_feacd7cde2017fd3b499802fc6a6dbb4=1595575203; Hm_up_feacd7cde2017fd3b499802fc6a6dbb4=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; Hm_ct_feacd7cde2017fd3b499802fc6a6dbb4=5744*1*xdc1812547560!6525*1*10_30835064740-1583844255125-466273; Hm_up_facf15707d34a73694bf5c0d571a4a72=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; Hm_ct_facf15707d34a73694bf5c0d571a4a72=5744*1*xdc1812547560!6525*1*10_30835064740-1583844255125-466273; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Flive.csdn.net%252Froom%252Fyzkskaka%252Fats4dBdZ%253Futm_source%253D908346557%2522%252C%2522announcementCount%2522%253A0%257D; Hm_lvt_facf15707d34a73694bf5c0d571a4a72=1596946584,1597134917,1597155835,1597206739; searchHistoryArray=%255B%2522%25E8%258F%259C%25E9%25B8%259FIT%25E5%25A5%25B3%2522%252C%2522%25E5%25AE%25A2%25E6%259C%258D%2522%255D; log_Id_pv=7; log_Id_view=8; dc_sid=c0efd34d6da090a1fccd033091e0dc53; TY_SESSION_ID=7d77f76f-a4b1-43ef-9bb5-0aebee8ee475; c_ref=https%3A//www.baidu.com/link; c_first_ref=www.baidu.com; c_first_page=https%3A//www.csdn.net/; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1597245305,1597254589,1597290418,1597378513; c_segment=1; dc_tos=qf1jz2; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1597387359'}
url = 'https://www.csdn.net/'
reponse = requests.get(url,headers=header)
#打印文本形式
print(reponse.text)
session
session :通过在服务端记录的信息确定⽤户身份
这⾥这个session就是⼀个指 的是会话
会话对象是一种高级的用法,可以跨请求保持某些参数,比如在同一个Session实例之间保存Cookie,像浏览器一样,我们并不需要每次请求Cookie,Session会自动在后续的请求中添加获取的Cookie,这种处理方式在同一站点连续请求中特别方便
处理不信任的SSL证书
什么是SSL证书?
SSL证书是数字证书的⼀种,类似于驾驶证、护照和营业执照的电⼦副本。
因为配置在服务器上,也称为SSL服务器证书。SSL 证书就是遵守 SSL协 议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务 器身份验证和数据传输加密功能
我们来爬一个证书不太合格的网站
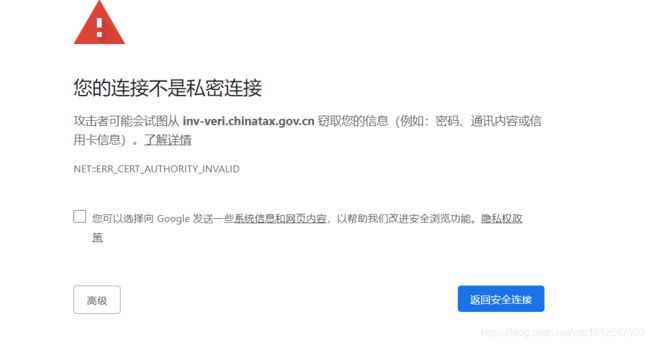
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
resp = requests.get(url)
print(resp.text)
它报了一个错

我们来修改一下代码
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
resp = requests.get(url,verify = False)
print(resp.text)
我们的代码又能成功爬取了
