flink的安装与使用(ubuntu)
组件版本
虚拟机:ubuntu-20.04.6-live-server-amd64.iso
flink:flink-1.18.0-bin-scala_2.12.tgz
jdk:jdk-8u291-linux-x64.tar
flink 下载
1、官网:https://flink.apache.org/downloads/
2、清华镜像:https://mirrors.tuna.tsinghua.edu.cn/apache/flink/
flink 安装
1、上传文件至服务器指定路径
/usr/local/myapp/flink
2、解压文件
tar -zxvf flink-1.18.0-bin-scala_2.12.tgz -C /usr/local/myapp/flink
jdk 安装
1、ubuntu 中自带了 jdk,先将其卸载
sudo apt-get remove *openjdk*
sudo apt-get autoremove
2、上传文件至服务器指定路径
/usr/local/myapp/jdk
3、解压文件
tar -zxvf jdk-8u291-linux-x64.tar -C /usr/local/myapp/jdk
4、配置环境变量
vim /etc/profile
在文末增加配置(路径根据自身情况进行调整)
export JAVA_HOME=/usr/local/myapp/jdk/jdk1.8.0_291
export JRE_HOME=/usr/local/myapp/jdk/jdk1.8.0_291/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
5、测试 jdk
root@vm1:/usr/local/myapp/jdk# java -version
java version "1.8.0_291"
Java(TM) SE Runtime Environment (build 1.8.0_291-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.291-b10, mixed mode)
root@vm1:/usr/local/myapp/jdk# javac -version
javac 1.8.0_291
测试 flink
1、进入到 flink 的安装路径下
cd /usr/local/myapp/flink/flink-1.18.0/
2、修改配置文件
vim conf/flink-conf.yaml
内容
jobmanager.bind-host: 0.0.0.0
3、关闭/禁用防火墙
systemctl stop ufw.service
systemctl disable ufw.service
4、启动 flink
./bin/start-cluster.sh
5、浏览器访问:http://ip:8081/
能看到内容说明正常
设置 flink 的 Standalone 模式集群并上传任务执行
1、机器规划
| 类型 | 主机名 | IP |
|---|---|---|
| JobManager | vm1 | 192.168.141.120 |
| TaskManager | vm2 | 192.168.141.121 |
| TaskManager | vm3 | 192.168.141.122 |
2、设置每个服务器的机器名
vim /etc/hostname
3、设置每个服务器的 hosts 文件
vim /etc/hosts
增加三台服务器的机器名对照
192.168.141.120 vm1
192.168.141.121 vm2
192.168.141.122 vm3
使其立即生效(建议到这一步后,都重新启动下)
source /etc/hosts
4、设置服务器间的免密登录
4.1、自身免密
vm1 执行(vm2/vm3 同理)
ssh-keygen -t rsa
之后的内容全部回车即可
生成后,可在 /root/.ssh/ 中看到 id_rsa.pub 文件
通过命令设置到认证文件中
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
重启服务器,通过命令测试是否可以免密登录自身
ssh vm1
通过 exit 命令可以退出当前的 ssh 登录
4.2、设置相互免密(以 vm1 为演示,其余服务器同理)
在 vm1 服务器中,将生成的自身密钥传输到其余两台服务器上
scp /root/.ssh/id_rsa.pub root@vm2:/root
scp /root/.ssh/id_rsa.pub root@vm3:/root
在 vm2/vm3 服务器中,将传输过来的密钥,通过命令设置到认证文件中
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
vm1 设置完成,通过命令来测试能不能直接登录到 vm2/vm3 中
ssh vm2
ssh vm3
vm2/vm3 同理,都需要执行这些步骤:
A、生成自身密钥,添加到自身的认证文件中
B、将自身密钥传输到其余的服务器中,并在该服务器中通过命令设置自身密钥到其余服务器的认证文件中
注意:vm2 和 vm3 执行时,一个服务器完全执行结束/测试后,再进行下一个,不然会有密钥文件存在被覆盖的风险
5、设置主机时间同步
安装工具
apt-get install -y ntpdate
执行同步
ntpdate -u ntp.sjtu.edu.cn
6、配置 flink
以下以 vm1 为例,其他服务器的配置可将配置好的配置文件同步过去
6.1、masters 文件
vim masters
内容
vm1:8081
6.2、workers 文件
vim workers
内容
vm2
vm3
6.3、flink-conf.yaml 文件
vim flink-conf.yaml
内容(篇幅问题,去掉了注释)
env.java.opts.all: --add-exports=java.base/sun.net.util=ALL-UNNAMED --add-exports=java.rmi/sun.rmi.registry=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED --add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED --add-opens=java.base/java.lang=ALL-UNNAMED --add-opens=java.base/java.net=ALL-UNNAMED --add-opens=java.base/java.io=ALL-UNNAMED --add-opens=java.base/java.nio=ALL-UNNAMED --add-opens=java.base/sun.nio.ch=ALL-UNNAMED --add-opens=java.base/java.lang.reflect=ALL-UNNAMED --add-opens=java.base/java.text=ALL-UNNAMED --add-opens=java.base/java.time=ALL-UNNAMED --add-opens=java.base/java.util=ALL-UNNAMED --add-opens=java.base/java.util.concurrent=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens=java.base/java.util.concurrent.locks=ALL-UNNAMED
jobmanager.rpc.address: vm1
jobmanager.rpc.port: 6123
jobmanager.bind-host: 0.0.0.0
jobmanager.memory.process.size: 1600m
taskmanager.bind-host: 0.0.0.0
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 3
parallelism.default: 1
jobmanager.execution.failover-strategy: region
rest.port: 8081
rest.address: vm1
rest.bind-address: vm1
blob.server.port: 45579
7、启动集群
只需在 vm1 上启动集群模式即可
root@vm1:/usr/local/myapp/flink/flink-1.18.0# ./bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host vm1.
Starting taskexecutor daemon on host vm2.
Starting taskexecutor daemon on host vm3.
可以看到 vm2/vm3 的也会被启动,不需要手动去 vm2/vm3 再启动一次了
可以通过 java 的 jps 命令查看程序是否启动成功了
vm1 上

vm2 上

vm3 上

从图上可以分析出是以 Standalone 的集群模式启动了,其中 vm1 是 JobManager,vm2/vm3 是 TaskManager
8、页面查看状态
浏览器输入地址:http://192.168.141.120:8081/
可看到主页面
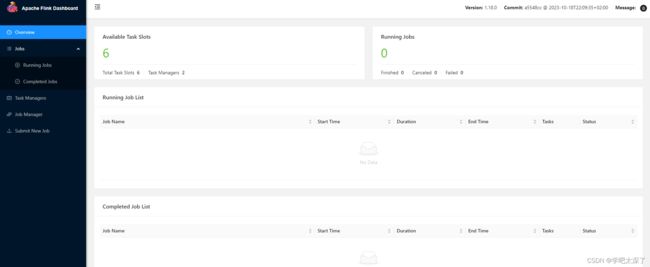
9、自定义一个任务
idea 创建一个 maven 项目
9.1、依赖及插件
<properties>
<flink.version>1.18.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
9.2、程序内容
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
// 无界流
public class UnboundStreamJob {
public static void main(String[] args) throws Exception {
//1 获取flink运行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//2.加载数据源为dataStream ,绑定客户机的9999端口,将这个网络端口发送的数据加载为dataStream
DataStreamSource<String> dataStream = environment.socketTextStream("192.168.141.122", 9999, "\n");
//3.执行多个转换算子 ,SingleOutputStreamOperator是DataStreamSource子类
SingleOutputStreamOperator<Tuple2<String, Integer>> result = dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
//value:表示一个待处理的数据,在这里就是一行字符串
//out: 用于输出结果的工具对象
public void flatMap(String value, Collector<String> out) throws Exception {
//拆分value,通过out输出结果
String[] words = value.split("//s+"); //去除一个或多个空格
for (String word : words) {
out.collect(word);
}
}
}) //执行一行字符串拆分为多个单词
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
}) //将多个单词转换为(单词,1) 这种tuple2对象
.keyBy(0) //根据单词为key分组,0表示tuple2中的第一个属性,也就是单词
.sum(1);//统计每组单词的个数, 1表示tuple2中第2个属性,也就是次数
//4.通过sink算子输出结果
result.print();
//5.发布执行
environment.execute("flinkWordCount"); //为任务起别名
}
}
9.3、程序说明
与 vm3 所在的 IP 为 192.168.141.122 在 9999 端口上进行 socket 通信,程序接收到消息后,进行计算并输出到控制台中
10、在 vm3 上开启一个 socket 通信(这一步一定要在上传任务之前进行)
netcat -lk 9999
11、提交任务(WebUI 方式)
11.1、打包刚才的程序,将打包好的 jar 包复制到某个好找的路径
11.2、打开网页中的 Submit New Job 选项,并点击 Add New
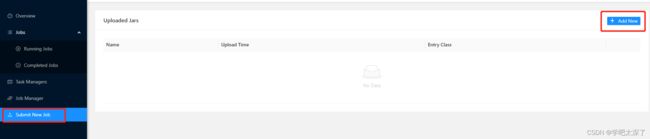
11.3、选择刚才打包的 jar 包进行上传,之后点击该 jar 包,填写启动类的路径,之后点击 Submit 提交按钮

11.4、正常情况下,任务就发布完成了,可以在 Task Managers 查看哪个节点的 Free Slots 相比 All Slots 减少了一个,那么这个节点的服务器就是执行该任务的服务器

12、提交任务(命令方式)
12.1、上传 jar 包到服务器中(任意一个服务器都行)
root@vm1:/usr/local/myapp/flink/task# ls
demo01-1.0-SNAPSHOT.jar
12.2、添加到任务中
../flink-1.18.0/bin/flink run -d -c xx.xx.xx.UnboundStreamJob demo01-1.0-SNAPSHOT.jar
说明:需要指定启动类
12.3、看到下面的信息,说明提交任务完成
Job has been submitted with JobID a893314f5efbb93bf3e6edefa578fd35
13、测试
13.1、点击该服务器,其中的 Stdout 就是控制台输出的地方
我们在 vm3 中开启的 socket 通信中,发送一条消息

13.2、回到页面中,刷新下控制台输出,会发现多了一个输出信息

13.3、至此,测试就完成了