redis 数据类型与持久化
redis命令参考
什么是缓存穿透?击穿?雪崩?如何解决?
java分布式锁使用redisson
1.底层
redis对象与数据结构
-
list 底层是链表
-
set底层是HashTable
-
Redis有序集合zset的底层实现
- 编码
zset的编码有ziplist和skiplist两种。
底层分别使用ziplist(压缩链表)和skiplist(跳表)实现。
什么时候使用ziplist什么时候使用skiplist?
当zset满足以下两个条件的时候,使用ziplist:
保存的元素少于128个
保存的所有元素大小都小于64字节不满足这两个条件则使用skiplist。
(注意:这两个数值是可以通过redis.conf的zset-max-ziplist-entries 和 zset-max-ziplist-value选项 进行修改。) - 编码
2. 场景
大量访问的数据
不经常改动的数据
- 记录帖子的点赞数、评论数和点击数(hash)。
- 记录用户的帖子 ID 列表(排序),便于快速显示用户的帖子列表(zset)。
- 记录帖子的标题、摘要、作者和封面信息,用于列表页展示(hash)。
- 记录帖子的点赞用户 ID 列表,评论 ID 列表,用于显示和去重计数(zset)。
- 缓存近期热帖内容(帖子内容的空间占用比较大),减少数据库压力(hash)。
- 记录帖子的相关文章 ID,根据内容推荐相关帖子(list)。
- 如果帖子 ID 是整数自增的,可以使用 Redis 来分配帖子 ID(计数器)。
- 收藏集和帖子之间的关系(zset)。
- 记录热榜帖子 ID 列表、总热榜和分类热榜(zset)。
- 缓存用户行为历史,过滤恶意行为(zset、hash)
- 固定集合(capped collection):LPUSH+LTRIM
消息队列:LPUSH+BRPOP

1. 缓存
string,hash
2.队列(不适合高可靠)
list(普通级和优先级队列.异步消息队列)
zset(优先级队列,延时队列)
hash(延时队列)
3. 去重
set(小批量数据去重)
string的bitop(可以实现布隆过滤器,实现超大规模数据去重)
HyperLogLog,可以实现超大规模数据去重和计数
4. 积分板
zset,自动排序,排名
5.发布/订阅
Pub/Sub可以实现多对多
3. redis client
1. redigo
- 获取多种类型的值:
redis.Values()
redis.Scan() //获取常见类型 - 获取自定义类型:
c := pool.Get()
defer c.Close()
//c, err := redis.Dial("tcp", ":6379")
//if err != nil {
// fmt.Println("conn redis failed", err)
// return
//}
var types []ArticleType
rel, err := redis.Bytes(c.Do("get", "types"))
if err != nil {
fmt.Println("获取redis数据错误")
return
}
decoder := gob.NewDecoder(bytes.NewReader(rel))
err = decoder.Decode(&types)
if len(types) == 0 {
//从MySQL取数据
var buffer bytes.Buffer
encoder := gob.NewEncoder(&buffer)
err := encoder.Encode(types)
_, err = c.Do("set", "types", buffer.Bytes())
if err != nil {
fmt.Println("redis set failed", err)
return
}
}
java
建议MaxIdle=MaxTotal,减少创建新连接的开销
建议预热MinIdle,减少第一次启动后的新连接开销
springboot集成redis (Lettuce)
目前java操作redis的客户端有jedis跟Lettuce。在springboot1.x系列中,其中使用的是jedis,但是到了springboot2.x其中使用的是Lettuce。
关于jedis跟lettuce的区别:
- Lettuce 和 Jedis 的定位都是Redis的client,所以他们当然可以直接连接redis server。
- Jedis在实现上是直接连接的redis server,如果在多线程环境下是非线程安全的,这个时候只有使用连接池,为每个Jedis实例增加物理连接
- Lettuce的连接是基于Netty的,连接实例(StatefulRedisConnection)可以在多个线程间并发访问,因为StatefulRedisConnection是线程安全的,所以一个连接实例(StatefulRedisConnection)就可以满足多线程环境下的并发访问,当然这个也是可伸缩的设计,一个连接实例不够的情况也可以按需增加连接实例。
//导包
implementation group: 'redis.clients', name: 'jedis', version: '3.5.1'
// https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-redis
implementation group: 'org.springframework.boot', name: 'spring-boot-starter-data-redis', version: '2.4.3'
// https://mvnrepository.com/artifact/org.apache.commons/commons-pool2
//lettuce
implementation group: 'org.apache.commons', name: 'commons-pool2', version: '2.9.0'
code: 一般使用,无需重写. 不重写时,对象存储有问题
@SpringBootTest
class RedisTests {
@Autowired
//不加泛型,中文会乱码
private RedisTemplate<String, String> redisTemplate;
// @Autowired
// @Qualifier("redisTemplate")
// private RedisTemplate redisTemplate;
@Test
void contextLoads() {
//opsForValue操作string
redisTemplate.opsForValue().set("girl","紫颜2");
System.out.println(redisTemplate.opsForValue().get("girl"));
//获取连接
// RedisConnection connection = redisTemplate.getConnectionFactory().getConnection();
}
重写即可
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
redisConfig.java
package com.example.lot.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
//@EnableCaching
public class RedisConfig{
// /**
// * 配置自定义redisTemplate
// * @return
// */
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper mapper = new ObjectMapper();
mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
// mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
// mapper.activateDefaultTyping(LaissezFaireSubTypeValidator.instance ,
// ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
mapper.activateDefaultTyping(mapper.getPolymorphicTypeValidator());
jackson2JsonRedisSerializer.setObjectMapper(mapper);
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer);
redisTemplate.setHashKeySerializer(stringRedisSerializer);
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
// // 设置值(value)的序列化采用Jackson2JsonRedisSerializer。
// redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
// // 设置键(key)的序列化采用StringRedisSerializer。
// redisTemplate.setKeySerializer(new StringRedisSerializer());
// redisTemplate.setHashKeySerializer(new StringRedisSerializer());
//
// redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
4. 深入学习Redis(3):主从复制
Redis 的主从同步,及两种高可用方式
Redis主从复制:容灾处理,密码
info replication:查看主从信息
5. redis数据类型
优先使用hash,能用尽量用.
type 变量:查看数据类型
object encoding 变量名: 查看变量编码

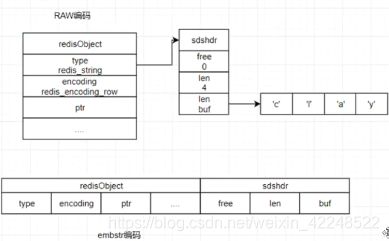
string
内部实现类似于java的Array List
Redis小于等于44个字节的字符串是embstr编码、大于44个字节是raw编码
raw编码(2次分配内存),embstr编码,int编码
<=44B,能转int优先使用int
list
常作为异步队列使用.相当于Linked List
插入和删除的时间复杂度O(1),查找O(n)
ziplist,quicklist编码
ltrim books 1 0相当于清空books
固定集合(capped collection):LPUSH+LTRIM
消息队列:LPUSH+BRPOP
set

HashSet
zset
hash
编码:ziplist,hashtable
存储对象. 存储消耗高于单个string. 渐进式rehash
session使用

bitmap,布隆过滤器的底层实现.
用一个bit位来标记某个元素对应的Value,而Key即是该元素
签到记录
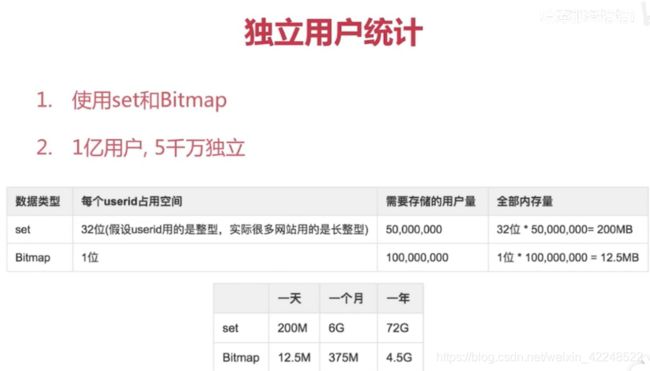


hyperloglog,基数(不重复元素)统计
统计UV(Unique Visitor,独立访客)任务
极小空间
错误率0.81%
不能获取单条数据

GEO

stream,内存版kafka
6. docker
docker run --name myredis -d -p6379:6379 redis
docker exec -it myredis /bin/bash
# 查看redis-cli 版本
redis-cli -v
# 进入redis-cli
docker exec -it a2be30(或myredis) redis-cli
7. 分布式锁
setnx 与 expire 之间会发生异常


不要用于较长时间的任务
set lock:code true ex 5 nx
del lock:code
不推荐可重入锁
阻塞读blpop,brpop在队列没有数据时,会立即进入休眠状态.一旦数据到来,则立刻醒过来
空闲连接问题.编写客户端消费者时,如果捕获异常,还要重试
8.命令
select
flushdb
flushall
info memory
dbsize
object encoding 变量名: 查看变量编码
type 变量: 查看变量类型(5种)
keys一般不在生产环境使用,一般使用热备从节点或scan命令
9. 慢查询



10. pipeline流水线
节省网络时间,非原子操作

11. 发布订阅
角色:发布者,订阅者,频道
无法获取历史消息.所有订阅者都能收到消息
消息队列的接收者只有一个收到消息(抢)
12.持久化
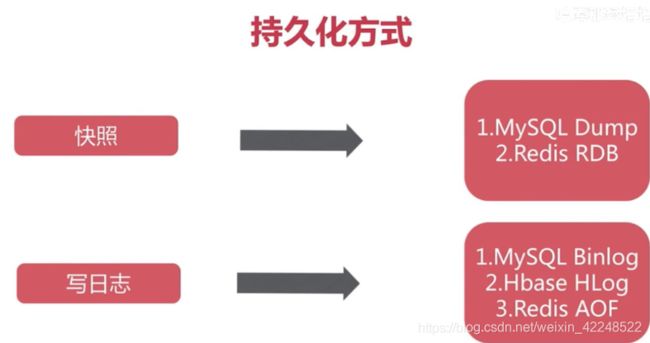
1. rdb
耗时耗性能,不可控丢失数据
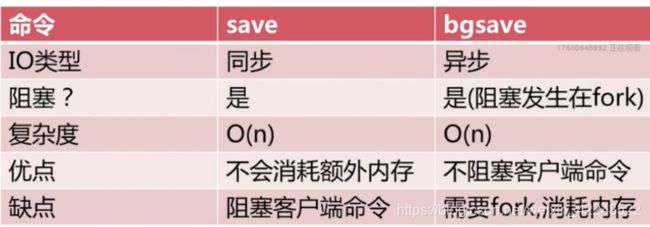
触发方式:save,bgsave,自动
flushall,退出redis也会生成rdb文件
适合大规模数据恢复
对数据完整性要求不高


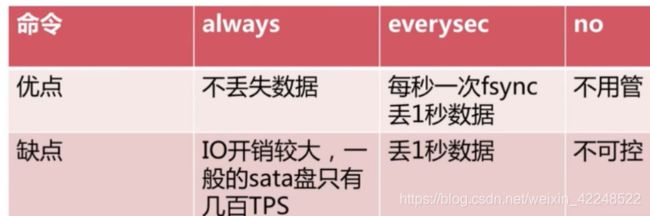
2. AOF
always,everysec(默认),no(os决定)
1. aof重写:
减少硬盘占用量,加速恢复速度
两种方式:BGREWRITEAOF,aof重写配置



3. 比较
同时开启时,默认启动aof

- 最佳策略

主从复制时,主需要bgsave




触发AOF

13. 开发运维
修复
redis-check-aof --fix aof文件
1. fork




14.数据结构
Redis的数据结构是基于内存的键值对存储模型实现的,底层是使用C语言编写的。下面是对不同数据类型底层实现的简单介绍:
-
String类型:Redis中的String类型是使用动态字符串实现的,底层使用C语言中的char数组来存储字符串数据,支持O(1)时间复杂度的字符串长度计算,同时还支持在字符串中的任意位置添加或删除字符等操作。
-
List类型:Redis中的List类型是使用双向链表实现的,底层使用C语言中的指针来实现节点的插入、删除和移动等操作。同时还支持在List头部和尾部进行高效的添加、删除元素的操作。
-
Hash类型:Redis中的Hash类型使用哈希表来实现,底层使用C语言中的指针数组和链表的结合实现。主要的功能包括快速查找指定Key所对应的Value、支持高效的添加、删除和修改操作。
-
Set类型:Redis中的Set类型是使用哈希表实现的,底层与Hash类型类似,使用C语言中的指针数组和链表的结合实现。主要的功能包括快速查找元素、支持高效的添加、删除操作和集合间的交集、并集、差集等操作。
-
Sorted Set类型:Redis中的Sorted Set类型是使用跳跃表和哈希表等底层技术实现的。跳跃表用来保存有序的元素集合,而哈希表则用来实现O(1)时间复杂度的元素查找功能。跳跃表的技术特点是实现简单、效率高,具有可扩展性。
这些数据结构在Redis中都有着广泛的应用场景,如缓存系统、消息队列、计数器、实时排行榜等。它们的使用场景和优缺点如下:
Redis 7 中实现的数据结构有字符串(string),哈希(hash),列表(list),集合(set),有序集合(sorted set),流(stream)和地理空间索引(geospatial index)等。不同的数据结构适用于不同的场景,它们各自有优点和缺点。
字符串(string:用于保存字符串类型数据,适用于计数器、缓存、分布式锁等场景。优点是存储简单、读写速度快,缺点是只支持操作字符串。
哈希(hash):用于保存一些具有结构化的数据,例如用户信息、配置等。优点是存储结构化、读取和修改特定字段方便,缺点是空间浪费可能较多,不适用于存储大量的小数据。
列表(list):用于保存有序的字符串列表,适用于消息队列、任务队列、历史聊天记录等场景。优点是读写速度快、支持队列操作,缺点是没有索引、无法快速定位到某个位置。
集合(set):用于保存无序且唯一的字符串数据,适用于去重、共同好友、推荐系统、用户标签等场景。优点是去重方便、元素唯一、支持交、并、差运算,缺点是读取时需要遍历整个集合,不支持有序操作。
有序集合(sorted set):用于保存有序且唯一的字符串数据,并可以给每个元素赋予一个分数用于排序,适用于排行榜、实时热门文章、按时间轴存储数据等场景。优点是有序方便、元素唯一、支持分数排序、支持范围查找,缺点是空间占用较大、写入速度慢。
流(stream):用于保存流式的消息数据,可以看作是高级版本的列表。流支持持久化、消费者组等特性,适用于任务分派、日志处理等场景。优点是可持久化、支持多消费者组、支持范围查询,缺点是写入速度相比于列表较慢。
地理空间索引(geospatial index):用于保存地理空间信息,例如地图上的点等。Redis使用桶优化存储空间,支持范围查找、位置计算等操作。优点是方便查询、支持位置计算,缺点是只支持部分地理空间操作。
1.hash和set的区别
Redis中的hash和set数据结构都是基于哈希表实现的。
对于hash表,它的底层使用一个哈希表来存储键值对,每个键值对是一个键值对节点,这个节点包含三个字段,分别是键、值和指向下一个节点的指针。当存储一个键值对时,Redis会先计算哈希值,然后找到对应的桶,在桶中查找是否已经有相同的键,如果有,则更新值;如果没有,则添加一个新的节点。
对于set表,它的底层使用一个没有值的哈希表来存储元素,每个元素也是一个节点,这个节点只包含键,没有值。当存储一个元素时,Redis会计算哈希值,然后找到对应的桶,在桶中查找是否已经有相同的元素,如果有,则不进行任何操作;如果没有,则添加一个新的节点。
区别在于,hash表中存储的是键值对,而set表中存储的是元素,即只有键没有值。
Redis中所有的数据结构都有各自的应用场景:
String:适合存储基本类型的数据,如整数、浮点数和字符串等。
Hash:适合存储对象,比如存储一个人的所有属性(姓名、年龄、性别等)。
List:适合存储按照先后顺序排序的数据,比如消息队列。
Set:适合存储无序、不重复的数据集合。
Sorted set:适合存储有序、不重复的数据集合,需要按照分数进行排序,常用于排行榜等场景。
Bitmap:适合存储位图数据,比如用户在线状态的记录。
HyperLogLog:适合进行基数计数,即统计不重复元素的个数。