软件测试进阶篇----接口测试
接口测试
一、接口的概述
-
接口是什么?
在系统与系统之间、子系统与子系统之间数据交互的功能就是接口。
接口就是一个特定功能的函数(方法),有参数,有返回值,调用者需要通过某种方式(网络协议)将参数传递给接口,接口处理完成之后将结果返回给调用者
接口是在前端、后端分离式开发兴起之后,才被重视起来的
-
接口的分类
- api接口:应用程序接口,项目中的大部分都是这种接口,就是方法
- 公共api接口:将某个接口开放给其他开发者使用,天气预报接口
- 按照协议类型划分:
- http接口:最常见的一种接口,增删改用post请求,查用get请求
- rest接口:比较主流的接口,增加用post、更新put、删除delete、查看用get
- soap接口:服务器接口,以文件的形式传递参数和数据
二、接口测试
接口测试就是通过传递给接口不同的输入参数,获取相应结果的过程,包括功能性、安全性和性能验证等多种测试类型,是一套完整测试体系。
接口测试(后端测试,和协议相关)相对的是UI界面测试(前端测试,和页面元素相关)
1、接口测试特点
- 接口测试相比UI界面测试,测试效率更高,接口测试完了,前端可以随便改
- 做自动化和持续集成更方便
- 接口测试是包括安全性测试、性能测试、和功能性测试的一套完整体系
- 接口测试可以发现UI界面上找不到的bug,发现安全性的问题、性能问题等
2、接口测试分类
- 功能测试
- 等价类
- 边界值
- 参数组合
- 场景测试
- ….
- 性能测试
- 安全性测试
三、接口测试文档阅读
对于接口测试实现步骤:
- 获取接口所需要的要素
- 接口的地址:http://39.101.167.251/xxx.html
- http:超文本传输协议,决定着网络上传输的数据的结构
- http://xxx.com//user/register.html
- 39.101.167.251<—>xxx.com:ip地址<—–>域名采用的DNS域名解析协议
- 39.101.167.251:作用指定接受请求的地址
- /qftest/user/:路径
- register:资源
- 请求方式
- 请求头部分
- 请求数据
- 接口的地址:http://39.101.167.251/xxx.html
- 使用接口测试工具实现这些要素
- 执行、判断接口的结果
1、自定义的接口文档
不管将来工作中提供你的接口文档类型是什么样子的(word文档、源码的、日志中、接口文档管理工具swagger)
需要关注的点、获取的要素都是一样的
- 接口说明:接口的功能是什么?
- 接口实现要素获取(核心)
- 接口的地址
- 请求的方式
- get:只想获取,不给出
- post:先给,再索取
- 请求的参数
- query string parameters:查询字符串参数
- data/body:数据
- 请求头部
- Content-Type:指定发送的报文的类型
- ………
- 实现接口工具(postman、jmeter)
- 工具中运行接口并查看结果
2、百度翻译接口
通过阅读百度通用翻译接口的相关文档,获取实现该接口的要素:
- 使用您的百度账号登录百度翻译开放平台(http://api.fanyi.baidu.com);
- 注册成为开发者,获得APPID;
- 进行开发者认证(如仅需标准版可跳过);
- 开通通用翻译API服务;
- 参考技术文档和Demo编写代码
做好了准备,就可以阅读实现该接口了:
-
接口说明
您只需要通过调用翻译API,传入翻译
-
接口地址
- 通用翻译API HTTPS地址:https://fanyi-api.baidu.com/api/trans/vip/translate
-
请求方式:
可使用GET或POST方式,如使用POST方式,Content-Type 请指定为:application/x-www-form-urlencoded
先用GET来实现,后面学完工具之后,再使用post请求方式
-
请求参数(query string parameters)

q:要翻译的字符串,是utf-8编码的,apple
from:翻译原语言,en、zh、fra、wyw等,auto表示自动识别
to:目标语言,en、zh、fra、wyw等
appid:20200610xxxx 密钥:xxxx
salt:随机数,888888
sign:签名,作用是防止别人盗用你的账号和服务。(appid+q+salt+密钥)的md5值(不可逆的)
签名是为了保证调用安全,使用 MD5 算法生成的一段字符串,生成的签名长度为 32 位,签名中的英文字符均为小写格式。
20200610xxxxapple888888xxxx
加密后的签名:xxxx
-
拼接请求
https://fanyi-api.baidu.com/api/trans/vip/translate?q=apple&from=auto&to=zh&appid=20200610xxxx&salt=888888&sign=xxxx
-
常见的错误码

四、常见的网络协议基础
UI测试/UI自动化关注的是:页面元素
接口测试/接口自动化测试:某个协议的报文(按照某个协议的结构组装的数据),是需要借助互联网去发送的。
1、网络模型
互联网中常见的网络模型有两个:OSI七层网络模型、TCP/IP四层网络模型
1、OSI七层模型
Open System Interconnect (OSI),是互联网最早的一个模型,但是在具体落地上不是特别好,更多的是在指导意义上。
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
2、TCP/IP网络模型
对OSI模型进行了简化,更容易在生产环境中落地。
- 应用层
- http/https协议:超文本传输协议(重点)
- ftp协议:文件传输协议
- pop3协议:邮局协议
- smtp协议:简单邮件传输协议(发件)
- DNS协议:域名解析协议(www.baidu.com<——>110.1.1.1)
- 传输层
- TCP协议:传输控制协议(重点)
- UDP协议:用户数据报协议
- 网络层
- IP协议
- ipv4
- ipv6
- IP协议
- 网络接口层
2、传输层协议-TCP协议(重点)
1、网络数据传输过程(了解)

2、TCP协议头字段
tcp协议(传输控制协议),是一种面向连接(建立连接、断开连接)、可靠的(传输数据正确–不丢包、顺序一致)、基于字节流的传输层协议
tcp协议头部的结构:总共有20个字节的固定长度
- 源端口:随机给一个,2个字节
- 目的端口:接收端应用程序的端口号,2个字节
- 序号/编号:是指有效数据分段后的编号,4个字节
- 确认号:4个字节
- 状态位(要么是0、要么是1):
- ack:验证序号有效
- syn:同步序号,建立连接
- fin:发送端完成发送,断开连接的状态
- ……
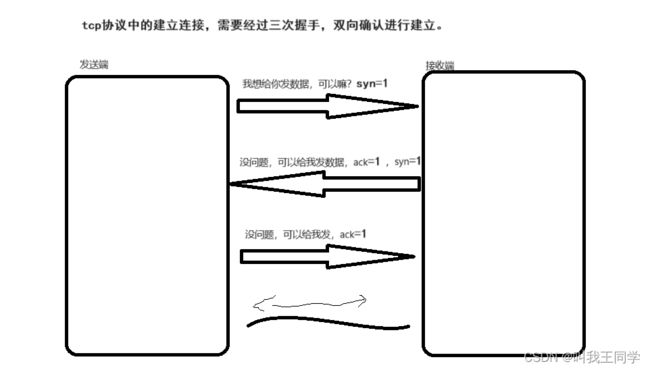
3、三次握手建立连接(掌握)
tcp协议中的建立连接,需要经过三次握手,双向确认进行建立。
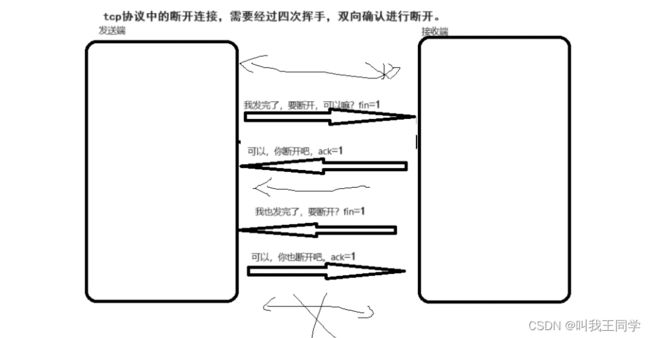
4、四次挥手断开连接(掌握)
tcp协议中的断开连接,需要经过四次挥手,双向确认进行断开。
5、端口
端口是计算机为每个应用程序所开放的一个编号,必须是唯一的(不允许一台电脑上两个应用公用一个端口)
端口号的范围:1~65535, 1~1024之间的端口号,一般都是给系统程序使用的,自定义的时候尽量不要使用
6、冗余的互联网络
冗余是为了安全。
3、传输层协议-UDP协议(了解)
UDP是用户数据报协议,是面向无连接(不需要握手、挥手,建立、断开连接)、面向事务、不可靠(丢包、数据传输顺序也不能保证)的传输服务。
UDP报文结构:
- 2个字节的源端口
- 2个字节的目的端口
- 2个字节的长度
- 2个字节的校验和
- 其他的是数据
TCP和UDP协议的区别(背下来):
- TCP是面向连接的,UDP是面向无连接的
- TCP的报文结构相对复杂(20个字节固定首部)、UDP是较为简单的(8个字节的固定长度)
- TCP是可靠的,UDP是不可靠的
- TCP是基于字节流的,UDP是基于数据报(事务)的
- TCP能保证数据的正确性和顺序,UDP不能
4、网络层协议-IP协议(了解)
IP协议又称互联网协议地址,是为每一台电脑或者网络提供唯一的逻辑地址(简单好记的昵称),是用来屏蔽物理地址的。
IP协议最常见的版本:ipv4和ipv6
-
ipconfig命令(掌握)
是windows下网络查询的命令。Linux系统下使用ip addr
-
ping命令
查看网络连接状态的
-
设置固定IP
在搭建服务器、组网的时候需要固定的ip地址
私人办公使用自动化获取ip即可
-
ipv4的分类
ipv4出现ip危机了,没有足够的ip分配给更多的网络和主机了。
ipv4是4个字节组成分段式的结构,2^32
ipv6是由16个字节组成,128位,所支持的网络数就是天文数字了。
ipv4的分类:11111111.11111111.11111111.11111111
- A类地址:第一个字节是网络号,后边三个字节是主机号
- 0 0000001. ~ 0 1111110.:1~126
- 127是一个特殊的网络地址,是本地回环地址,127.0.0.1,是localhost是相同的功能(10.9.72.243)
- A类地址支持的主机数量:2^24-2
- 国内没有任何一个完整的A类地址
- 10网段是A类地址中的局域网地址
- B类地址:前两个字节是网络号,10开头,后面两个字节是主机号
- 10 000000.00000001 ~ 10 111111.1111110 ==>128.1~191.254,差不多16384个B类网络
- B类地址支持的主机数量:2^16-2
- C类地址:前三个字节是网络号,110开头,最后一个字节是主机号
- 主要是分配给企业使用的,网络数量2090000+个网络
- 每个网络的主机数量有限,2^8-2 ==>254个
- 192.168.1.1:C类地址中的局域网地址
- 其他
- A类地址:第一个字节是网络号,后边三个字节是主机号
5、应用层协议-http协议(重中之重)
1、常见的概念
-
http:超文本传输协议,用于在互联网传输图片、视频、音频、excel文件、html文件等,默认端口80
-
https:安全版本的超文本传输协议,SSL安全套接层和证书来保证传输安全性,默认端口是443
-
http://127.0.0.1:80/xx(本地回环地址)
-
http://127.0.0.1:8088/xx
-
http://localhost:8088/xx
-
http://10.9.72.243:8088/xx
-
web服务器:apache(python、php等)、tomcat(java服务,8080)、iis(.net服务)
-
http协议是无状态的,是不支持重发的、没法记录状态,每一个请求都是独立的
2、http协议请求报文结构
发送端(客户端)给接收端(服务端)发送的http协议的报文是请求报文(request)

1)请求报文结构包括4部分:
- 请求行
- 请求方式
- post
- get
- delete
- put
- …
- 请求地址
- 协议:http
- 域名/IP:localhost
- 端口:8088
- 路径:/verydows/xxx?step=submit
- 参数:query string parameters(查询字符串参数),step=submit
- 请求方式
- 请求头部:是由大量的键值对组成,键名是固定的(每个接口的键的数量可以不一样),值一般都不一样
- Host:指定域名及端口
- Content-Length:请求正文数据的长度
- Content-Type:请求正文数据的类型,固定的常见的几种
- application/x-www-form-urlencoded
- application/json
- form-data
- Referer:可以用于鉴权、防盗链功能
- Cookie:解决http协议无状态的问题
- Authorization:授权功能
- ……
- 空行:回车换行,区分请求头部和请求正文
- 请求正文:
- 键和值都是字符串的键值对
2)请求方式
- get:可以向服务器申请资源(json、html文件等),查看功能,get请求的正文是空的,可以通过地址栏携带(?xx=yy&aa=bb)
- post:是可以影响/改变服务器资源的(增删改都可以),主要是增加功能,请求数据是包含在正文中
- delete:删除
- put:更新
- head:和get基本上一样,但不是要实体,而是要响应报文的头部字段
- …
3)get和post请求的区别
- 一个是向服务器索要资源,一个是可以改变服务器资源
- get请求相比post不太安全
- get的参数是拼接在url地址的后面,post的数据是在请求报文正文中的
- get请求的参数是有长度限制的,post不受限制
3、http协议响应报文结构
发送端(服务端)给接收端(客户端)发送http协议的报文是响应报文(response)
1)响应报文也有4部分组成
- 响应状态行:HTTP/1.1.200 OK
- 协议:HTTP
- 版本:1.1
- 状态码:200,是一个数字
- 状态信息:OK,对应状态码的英文表示形式,是一一对应的
- 响应头部:由多个键值对组成
- Date:Sun,08 Oct 2023 02:49:12 GMT(格林尼治时间)
- Content-Length:1878,响应正文数据的长度
- Content-Type:text/html;charset=UTF-8
- Set–Cookie:写cookie数据到浏览器的cookie管理器中
- 空行
- 响应正文
- 数据要与响应头部中的类型一致
- 数据长度与响应头部的长度一致
2)http协议的响应状态码
响应状态是“古董”级别的技术,由三位数字组成,只有有限的个数。
- 1XX:继续状态
- 2XX:请求成功的状态,服务器正确地处理了请求。
- 200 OK,只是服务器正确地处理了请求,和业务逻辑的正确性没有关系,所以引入了错误码
- 3XX:重定向的问题
- 301 永久重定向,请求的服务器已经不再提供服务,会自动转移到其他地址了
- 302 临时重定向,请求的服务器暂时不提供服务,会自动转移到其他地址了
- 304 资源未改变
- 第一次访问某个web资源(图片、html文件等),会从服务器上把对应的资源下载到本地缓存:200
- 再次访问同一个web资源(图片、html文件等)—>请求头部携带缓存文件的标识名及最后修改时间,就不会从服务器再次下载了,直接使用缓存中的数据
- 如果web服务器上资源未变化,不需要再次下载了,直接从缓存拿数据即可:304
- 如果web服务器的资源发生了变化,重新下载服务器资源:200
- 4XX:客户端错误(地址写错了)
- 401 未授权:
- 访问某个资源,没有相应的账号和密码权限,越权访问了
- 403 目录被禁用:
- 所有web系统的文件夹目录都应该被禁止访问,要是访问了,就应该弹出403状态码
- 404 not found:
- 要么是地址的路径错了
- 要么是服务器资源名称错了
- 401 未授权:
- 5XX:服务器端的错误
- 500:内部服务错误
- 服务器端的数据库不可用了
3)错误码和响应状态码的区别(背下来)
- 响应状态码不是开发工程师可以改的,错误码随便改,是为每个业务逻辑状态设定的一个值
- 84001:签名错误
- 84000:必填参数为空
- 82000:请求成功
- 响应状态码在响应报文的响应状态行中,错误码在响应正文中
- 响应状态码体现的是服务器是否正确处理了请求;错误码是对业务状态的体现、业务逻辑的正确性验证
postman
一、postman简介
postman是一款功能强大的。http协议请求报文打包、发送的接口测试软件。
支持全流程的接口测试业务
- 前端开发:mock测试
- 后端开发:接口调试
- 测试工程师:接口测试
- 运维工程师:接口监控
- 云盘功能
- 还支持http/https协议的各种请求方式。
二、postman的安装和注册
下载postman:https://www.postman.com/downloads/
安装postman:自动安装完成并打开
注册postman账号
三、实现第一个接口测试案例
百度翻译案例–get/post
四、postman接口测试的流程
1、获取接口的要素
1)通过各种手段来获取接口的要素:
- 开发提供的接口api文档:前端和后端在开始项目前需要协商好的
- 抓包:必须有前端页面
- 需要和后端开发协商、沟通(相对较难一点)
- 可能会提供日志
- 可能会提供源码
2)需要获取什么要素(收集全了就可以打包请求)
- 请求地址
- 请求方式
- 请求参数
- 请求头部
- 请求数据
2、根据要素设计测试用例
可以采用等价类、边界值、场景法、参数组合法等设计用例
3、使用postman工具实现测试用例(请求)
将测试用例的要素,填写在postman工具的对应位置
还要给测试用例添加断言。添加Tests模块里面
4、发送请求,查看结果
通过响应结果页面的数据,判断当前请求的运行结果是否正确
5、生成可视化的报告
大量用例运行后,可以生成可视化的报告。
五、使用postman实现单接口案例
常见的请求正文数据的类型(post):
- x–www–form–urlencoded:键值对,都是字符串文本格式
- form–data:键值对,但是他的值可以是字符串,也可以是文件(图片、视频等….)
- application/json:数据就是json格式的
1、视频评论接口-get
请求url地址:https://xxx.com
- 请求方式:get
- 请求参数:已经在url后了
- 请求头部:还不确定
- 请求数据:不需要
本案例的Referer字段必须填,起到防盗链的作用。
2、蜜锋电商前台相关接口
1)注册接口–post
- 请求地址:http://xxx.html
- 请求方式:post
- 请求参数:step:submit
- 请求头部:Content-type:x-www-form-urlencoded
- 请求正文:
- username
- password
- repassword
- agree
2)登录接口–post
- 请求地址:http://xxx.html
- 请求方式:post
- 请求参数:step:submit
- 请求头部:Content-type:x-www-form-urlencoded
- 请求正文:
- username:blue_p_001
- password:加密后的密码
3)资料更新接口–post
- 请求地址:http://xxx.html
- 请求方式:post
- 请求参数:step=update
- 请求数据:
- 请求头部:
- Cookie
- Content-Tpye
4)更新头像接口
- 请求地址:http://xxx
- 请求方式:post
- 请求参数:step=crop
- 请求头部:
- Content-Type: application/x-www-form-urlencoded
- Cookie
- 请求正文:
- streams:是经过base64加密之后的文件
- mine:文件类型
- x
- y
- w
- h
5)退出接口
- 接口的地址:http://xxx.html
- 请求方式:get
- 请求参数:无
- 请求数据:无
- 头部信息:无
3、OA办公系统相关接口
1)登录接口
2)图片上传接口
- 请求地址:http://oa.xxx.php?xxx
- 请求方式:post
- 请求参数:不需要填
- 请求头部:
- Content-Type:form–data
- 请求数据:
- file:binary(二进制)
4、测试过程管理系统
安装过程注意事项:
- python支持的版本是3.8(3.11不支持)
- redis要以管理员的权限运行
- 创建mysql数据库:本地启动mysql服务
- 配置数据库参数:将密码改成123456
- 退出本地的音乐软件
1)登录接口
- 请求地址:http://127.0.0.1:8000/login
- 请求方式:post
- 请求头部:Content–Type:application/json
- 请求数据:{ “username”:“admin”, “password”:“admin123”}
2)查看用户角色
这个接口是需要有登录状态才能查看,是需要**通过token技术实现鉴权。**
-
需要先实现登录接口,获得响应正文,从其中获取token值(登录接口的**tests**功能中实现)
-
获取到token之后可以保存在一个变量中(集合变量)
-
然后实现查看用户角色接口,其中请求头字段需要有Authorization字段,值从上个登录接口获取
-
请求地址:http://127.0.0.1:8000/user/xxx
-
请求方式:get
-
请求头部:
- Authorization:Token token值
-
请求参数:无
-
请求数据:无
3)补充:cookie和token授权技术
关联技术:第一个接口的数据(响应数据)是需要给第二个接口使用(请求数据)的,提取第一个接口中的值交给第二个接口使用(使用的token或者cookie)。
cookie技术:是比较早的一个鉴权技术,解决http协议的无状态的特点,第一个接口的数据(响应数据)是需要给第二个接口使用(请求数据)的,是需要通过提取第一个接口中的数据,借助cookie这个中转技术,传递给第二个接口。
cookie管理器:浏览器或者是postman中提供cookie值管理的功能。
token技术:是比较新的,现在用的比较广泛的技术,也叫令牌技术,是可以跨平台的,PC端的web和移动端APP是可以同步token值的。
4)补充2:断言技术
断言就是判断接口响应结果的正确性,获取响应结果的值和预期结果对比
-
接口的断言非常灵活,有很多方式(3种):
-
响应正文
-
字符串类型的正文:大串包小串
-
json类型的正文:通过jsonpath表达式提取要断言的字段,然后和预期做比较
-
-
响应时间
-
六、runner运行器的用法
通过runner运行器来运行collection集合中请求(用例)的。
提供了调整测试中用例数、用例执行顺序、参数化等功能。
1、基本用法
runner运行设置
runner运行器设置
runner运行结果
2、参数化的实现
postman中支持csv、json文件进行参数化。
1)创建json文件
2)专门用于参数化的请求
3)通过runner运行器加载json文件
3、运行器的自动化运行功能
和postman的monitor监控功能相似
设置定时器
4、runner中执行性能测试(最新版本)
性能测试设置
七、接口测试案例(多接口)
关联技术:第一个接口的数据(响应数据)是需要给第二个接口使用(请求数据)的,提取第一个接口中的值交给第二个接口使用(使用的token或者cookie、其他的数据–订单号、关联值)。
1、电商后台相关接口
1)电商首页接口
- 请求地址 :http://xxx.php?m=backend
- 请求方式:get
- 请求参数
- 请求头部
- 请求数据
2)登录接口
- 请求地址 :http://xxx.php?m=backend&c=main&a=login
- 请求方式:post
- 请求参数:
- 请求头部:
- Content-Type:x-www-urlencoded
- 请求数据
- key:value
- username:student1
- password:xxx
3)添加商品接口
- 请求地址:http://xxx.com/index.php
- 请求方式:post
- 请求参数:
- m:backend
- c:goods
- a:add
- step:submit
- 请求数据:
- goods_name
- cate_idbrand_id
- goods_sn
- now_price
- original_price
- newarrival
- status
- goods imagestock_qty
- goods_weight
- meta_keywords
- meta description
- goods_brief
- 请求头部
- cookie
- Content-Type:x-www-form-urlencoded
4)删除商品接口
5)退出登录
2、云学习平台
1)验证码登录
提供给登录接口两个数据:
- imgAuthCodeToken
- code
2)云学习平台登录接口
下面的接口提供:
- token
3)开始学习接口
八、mock挡板测试
是给请求提供模拟数据的。
1)创建挡板服务
2)设置参数
九、requests接口自动化测试工具
一、request概述
requests:是接口自动化测试工具,是python中的一个第三方模块,可用于爬虫和接口测试
是标准http客户端,支持所有的http的请求方式
1、安装
pip install requests
4、基本用法
# 百度翻译接口,使用get请求方式来实现
# 接口测试就是在打包请求
import requests
# 需要地址就定义url
url = "https://fanyi-api.baidu.com/api/trans/vip/translate?xxx"
# 如果需要正文数据就可以定义payload,参数、正文数据、请求头部要求都定义为字典
payload = {}
headers = {
'Cookie': 'xxx'
}
# requests.request("GET", url, headers=headers, data=payload):拼接请求要素并发送请求,返回相应结果对象
# response:response接收了返回的响应结果对象(就是一个完整的响应报文了)
response = requests.request("GET", url, headers=headers, data=payload)
print(response.text)
# 查看响应状态码
print(response)
print(response.status_code)
# 查看响应头部
print(response.headers)
# 查看cookie
print(response.cookies)
# 查看正文的编码集合
print(response.encoding)
# 查看正文:json()方法的作用是将相应正文转为python中可识别的字典、列表结构
print(response.json())
# text:将正文转为字符串格式
print(response.text)
3、requests支持的请求方法
1)常见方法
- requests.request(“GET”,url,**kwargs):
- requests.get(url,**kwargs)
- requests.post(url,**kwargs)
- requests.put(url,**kwargs)
- requests.delete(url,**kwargs)
2)**kwargs是不定长参数,有好多个参数名:
- data:接收请求数据的(对应x-www-form-urlencoded),给字典数据即可
- headers:接收请求头部字段的,给字典数据即可
- files:接收请求数据的(对应form-data),给字典数据即可
- json:接收请求数据的(对应application/json),给字典数据即可
- params:接收查询字符串参数,也是定义字典即可
二、常见案例实现
1、视频评论接口
# 该接口需要referer字段实现防盗链功能
import requests
# 请求地址定义在url
url = "https://xxx"
# 定义参数,已经写在了url后了
# 请求头部,定义成字典即可
headers = {
"Referer": "https://xxx.com"
}
# 定义请求数据,因为是get请求,这项不需要
# 请求方式为get
# 打包并发送请求,获得相应报文对象
# 第一种写法:response = requests.request("GET")
# 第二种写法
response = requests.get(url, params=None, headers=headers)
# 查看正文数据
jsonData = response.json()
print(type(jsonData))
# print(jsonData)
assert jsonData["result"]["items"][0]["first_comment"] == "讲解的很通俗易懂,0基础小白也能听懂,很赞"
2、百度翻译post实现
import requests
# 定义该请求的要素:请求地址、请求参数、请求数据、请求头部、请求方式-post
url = "https://fanyi-api.baidu.com/api/trans/vip/translate"
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
data = {
"q": "apple",
"from": "auto",
"to": "zh",
"appid": "20200610xxx",
"salt": "888888",
"sign": "xxx"
}
# 开始打包发送
response = requests.post(url,headers=headers,data=data)
# 查看正文数据
print(response.json())
作业:做成一个命令行翻译程序,可以输入要翻译的字符串、要翻译的语言类型,显示翻译结果
技术:while(true)、生成随机数、字符串拼接、md5加密算法
# 百度翻译接口
import requests
import random
import hashlib
# 定义该请求的要素:请求地址、请求参数、请求数据、请求头部、请求方式-post
url = "https://fanyi-api.baidu.com/api/trans/vip/translate"
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
while (True):
print('----------------------欢迎进入Blue翻译平台----------------------')
print(' 1-翻译 2-退出')
print('-' * 61)
choice = int(input('请输入功能菜单编号:'))
if choice == 1:
q = input('输入要翻译的字符串:')
to = input('请输入要翻译的语言类型:')
salt = str(random.randrange(000000, 999999))
sign_yuan = "2020061xxx" + q + salt + "xxx"
def string_to_md5(string):
# 创建MD5对象
md5_obj = hashlib.md5()
# 更新MD5对象的哈希值,以字符串作为输入
md5_obj.update(string.encode('utf-8'))
# 获取经过哈希计算的结果,返回一个128位的十六进制字符串
md5_str = md5_obj.hexdigest()
return md5_str
sign = string_to_md5(sign_yuan)
data = {
"q": q,
"from": "auto",
"to": to,
"appid": "20200610xxx",
"salt": salt,
"sign": sign
}
# 开始打包发送
response = requests.post(url, headers=headers, data=data)
jsondate = response.json()
result = jsondate['trans_result'][0]['dst']
print(f'翻译后的结果是:{result}')
elif choice == 2:
print('-------------欢迎下次使用-------------')
break
else:
print('不好意思,编号输入错误,请重新输入!!')
3、电商相关接口的实现
1)注册接口
# 借助单元测试框架unittest实现
import requests
import unittest
class mifeng_reg_username(unittest.TestCase):
def setUp(self):
self.url = "http://xxx.com/user/register.html"
self.params = {
"step": "submit"
}
self.headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
def test_username_01(self):
'''
用户名为空
:return:
'''
data = {
"username": "",
"email": "[email protected]",
"password": "123456",
"repassword": "123456",
"agree": "on"
}
response = requests.post(self.url, headers=self.headers, params=self.params, data=data)
sj = response.content.decode('utf-8')
yq = '用户名不符合格式要求'
self.assertIn(yq, sj)
def test_username_02(self):
'''
用户名为test
:return:
'''
data = {
"username": "test",
"email": "[email protected]",
"password": "123456",
"repassword": "123456",
"agree": "on"
}
response = requests.post(self.url, headers=self.headers, params=self.params, data=data)
sj = response.content.decode('utf-8')
yq = '用户名不符合格式要求'
self.assertIn(yq, sj)
def test_username_03(self):
'''
用户名为12test
:return:
'''
data = {
"username": "12test",
"email": "[email protected]",
"password": "123456",
"repassword": "123456",
"agree": "on"
}
response = requests.post(self.url, headers=self.headers, params=self.params, data=data)
sj = response.content.decode('utf-8')
yq = '用户名不符合格式要求'
self.assertIn(yq, sj)
def tearDown(self):
pass
if __name__ == '__main__':
unittest.main()
2)登录接口
import requests
url = 'http://xxx.com/user/login.html?step=submit'
headers={
"Content-Type": "application/x-www-form-urlencoded"
}
data = {
"username":"blue_001",
"password":"xxxx(加密后的密码)"
}
response = requests.post(url,headers=headers,data=data)
print(response.content.decode('utf-8'))
3)更新资料接口
import requests
url = "http://xxx.com/user/profile.html?step=update"
data = {
"nickname": "小王同学",
"qq": "2659160222",
"gender": 1,
"birth_year": 2000,
"birth_month": 2,
"birth_day": 20,
"signature": "小王学测试"
}
headers = {
'Cookie': "xxxx",
'Content-Type': 'application/x-www-form-urlencoded'
}
response = requests.post(url, headers=headers, data=data)
print(response.content.decode('utf-8'))
4)session实现cookie共享
# session技术,也叫会话技术,在requests接口自动化中的作用是共享多个接口之间的cookie值
# 使用相同的session会话发送请求,相当于在一个浏览器中操作不同的接口
# 实现先登录,然后更新资料功能
import requests
# 然后创建session对象
session = requests.session()
baseUrl = 'http://xxx.com'
headers = {
"Content-Type": "application/x-www-form-urlencoded"
}
# 先做登录接口:产生登录的cookie
# 登录接口的地址
urlLogin = baseUrl + '/user/login.html?step=submit'
# 登录接口的数据
data = {
"username": "blue_001",
"password": "xxx"
}
# 使用session对象去发送请求
responseLogin = session.post(urlLogin, headers=headers, data=data)
# print(responseLogin.content.decode('utf-8'))
# 2、更新资料
# 更新资料接口的地址
urlUpdate = baseUrl + '/user/profile.html?step=update'
dataUpdate = data = {
"nickname": "小王同学",
"qq": "2659160222",
"gender": 1,
"birth_year": 2000,
"birth_month": 2,
"birth_day": 20,
"signature": "小王学测试"
}
responseUpdate = session.post(urlUpdate, headers=headers, data=dataUpdate)
print(responseUpdate.content.decode('utf-8'))
4、OA办公系统的两个接口
1)登录接口
2)签名接口
import requests
# session对象是在多个接口之间共享cookie的
session = requests.session()
urlLogin="http://xxx.com/?xxx"
headersLogin = {
"Content-Type": "application/x-www-form-urlencoded"
}
dataLogin = {
"rempass":0,
"jmpass":"false",
"device":"xxxx",
"ltype":"0",
"adminuser":"xxx:",
"adminpass":"xxx:",
"yanzm":""
}
responseLogin = session.post(urlLogin,headers=headersLogin,data=dataLogin)
print(responseLogin.content.decode('utf-8'))
# 实现签名上传接口
urlQianMing = "http://xxx.com/index.php?xxx"
headersQianMing = {}
# 请求的数据是字节码文件(图片)
files = {
"file": open(r'd:\aa.jpg','rb')
}
responseQianMing = session.post(urlQianMing,files=files)
print(responseQianMing.content.decode('utf-8'))
5、电商后台相关接口
结合着单元测试框架unittest实现,借助git、gitee、jenkins。
1)电商后台首页
2)后台登录接口(关联技术)
3)后台商品添加接口(cookie共享–session技术)
4)…….
import requests
# session对象是在多个接口之间共享cookie的
session = requests.session()
urlLogin="http://xxx.com/?xxx"
headersLogin = {
"Content-Type": "application/x-www-form-urlencoded"
}
dataLogin = {
"rempass":0,
"jmpass":"false",
"device":"xxx",
"ltype":"0",
"adminuser":"xx:",
"adminpass":"xx:",
"yanzm":""
}
responseLogin = session.post(urlLogin,headers=headersLogin,data=dataLogin)
print(responseLogin.content.decode('utf-8'))
# 实现签名上传接口
urlQianMing = "http://xxx.com/index.php?xxx"
headersQianMing = {}
# 请求的数据是字节码文件(图片)
files = {
"file": open(r'd:\aa.jpg','rb')
}
responseQianMing = session.post(urlQianMing,files=files)
print(responseQianMing.content.decode('utf-8'))
单元测试框架
1、创建单元测试用例
pytest框架对标识符名称的要求:
- 文件名必须以test_开头
- 测试类型必须以Test_开头,并且不能有init方法
- 测试方法必须以test开头
2、断言的用法
assert关键字后面可以接一个表达式,只要表达式的最终结果为True,那么断言通过,用例执行成功,否则用例执行失败
assert xx:判断xx为真
assert not xx:判断xx不为真
assert a in b:判断b包含a
assert a == b:判断a等于b
assert a !=b:判断a不等于b
3、执行参数
pytest.main()方法中的参数如下
- -s:显示程序中的print/logging等内容,输出到控制台
- -v:丰富信息模式,输出更详细的用例执行信息
- -q:安静模式,不输出环境信息
- -x:出现一条测试用例失败就退出测试
- -k:可以使用and、not、or等逻辑运算符,匹配范围(文件名、类名、函数名)
1)main()方法执行
import pytest
def test_01():
a = 12
b = 23
c = a + b
print("我是test_01")
assert a == b
class Test_a():
def test_02(self):
print("我是test_02")
assert True
def test_03(self):
print("我是test_03")
assert True
if __name__ == '__main__':
# pytest.main()
# pytest.main(["-s"])
# pytest.main(["-s","-v","-x"])
pytest.main(["-s", "-v", "-k test_02"])
2)命令行执行
# 执行具体的某一测试文件
pytest 脚本名称.py
# 执行所有的测试文件
pytest -sv
# 执行指定包或者文件夹下面的所有文件
pytest -sv 包名或文件夹名
# 执行测试用例名称包含phone的所有用例
pytest -k phone test_demo.py
# 执行测试用例名称 不包含phone的所有用例
pytest -s -k "not phone" test_demo.py
# 执行测试用例名称包含 phone 或 login 的所有用例
pytest -s -k "phone or login" test_demo.py
# 运行.py模块里面,测试类里面的某个方法
pytest test_demo.py::TestClass::test_one
3)用例执行状态
用例执行完成后,每条用例都有自己的状态,常见的状态有:
- passed:测试通过,一般使用 . 来表示
- failed:断言失败,一般使用 F 来表示
- error:代码错误,一般使用 E 来表示
4、常见的fixture方法
1)一个单元测试用例包括的方法:
- setup()
- test_xx()
- teardown()
jmeter
一、jmeter工具的概述
1、jmeter和postman工具的区别
- jmeter是做http接口测试,但是慢慢的增加了更多的协议类型;postman现在只能做http协议
- jmeter是java开发的程序,兼容性更好,但是UI上不是特别美观;postman界面比较好
- jmeter支持接口测试和性能测试的,现在postman也是支持接口和性能测试
- jmeter是完全开源免费的一个工具(属于apache开源项目之一),postman部分功能收费
- 都支持报告生成
- 两个工具都属于手工的接口测试工具
2、jmeter的安装
-
下载安装
-
配置环境变量
-
核心文件
- jmeter.bat:windows系统下jmeter的启动文件,启动的主控机(master)
- jmeter:Linux或者MacOS系统下的启动文件,启动的主控机(master)
- jmeter-server.bat:windows系统下jmeter的启动文件,启动的是肉鸡(slave)
- jmeter-server:windows系统下jmeter的启动文件,启动的是肉鸡(slave)
- jmeter.properties:核心配置文件,jmeter参数的、功能参数都在该文件中配置
1)配置jmeter软件的语言
2)jmeter进行分布式的性能测试的时候才需要配置该参数
3)sampleresult.default.encoding=utf-8
4)apdex性能指标阈值设置
-
第一个接口实现
二、常见的组件
1、测试计划组件
理解成是一个工程目录,设置一些==全局变量==,添加额外的插件。
2、线程组
设置线程数量(用户数)的
- 进程:一个程序相当于一个进程,计算机会为进程分配固定内存空间
- 线程:多个聊天框,大量的线程共享进程的内存空间
- 进程>线程组>线程
3、采样器
支持不同类型的采样器(请求),以http请求为主。
4、json断言
1)json断言
2)响应断言
5、参数化
使用定义的全局变量、外部文件中的数据参数化到脚本中来。
1)测试计划中的用户定义变量
参数化的格式:${变量名}
2)csv文件参数化
3)函数助手对话框
三、常见的接口案例
1、百度翻译post
2、电商前台相关接口
1)电商注册接口
2)电商登录接口
3)电商资料更新接口
4)电商头像更新接口
5)…
3、OA办公系统相关接口
1)登录接口
2)签名上传接口
4、云学习相关接口
1)后台首页
2)后台登录接口
3)后台商品增加接口
5、测试管理系统相关接口
自行练习
四、脚本录制
接口测试中,我们关注的是协议报文,是可以通过抓包工具获取的
常见的抓包方式(录制方式)有两种:
- 工具抓包并转为脚本
- jmeter代理功能转为脚本
代理技术:
1、badboy录制
要求:录制过程不要太快
案例:电商后台相关的接口
2、jmeter代理录制
所有的http协议项目都能录制
1)jmeter开启代理服务
2)浏览器的代理设置
浏览器上的所有请求,都需要转发到本地jmeter代理服务器(8888)
3)启动jmeter代理服务器
4)在浏览器上访问被测系统
按照步骤在浏览器上操作被测系统,检查jmeter中的脚本
5)关闭浏览器的代理服务
不关闭无法上网
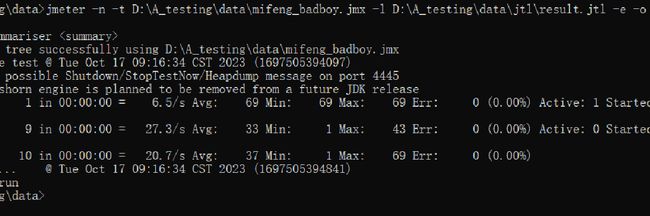
五、命令行运行(非GUI模式运行)
Don’t use GUI mode for load testing !, only for Test creation and Test debugging.
For load testing, use NON GUI Mode:
jmeter -n -t [jmx file] -l [results file] -e -o [Path to web report folder]
- -n:NON,非GUI模式启动jmeter
- -t:后面跟jmx文件
- -l:后面跟的是原始结果数据
- -e:将原始的结果数据转为html格式的可视化报告
- -o:指定可视化的html报告输出的目录
- -r:指定肉鸡的
生成报告:jmeter -n -t D:\A_testing\data\mifeng_badboy.jmx -l D:\A_testing\data\jtl\result.jtl -e -o D:\A_testing\data\html
六、持续集成
jmeter+ant+jenkins实现接口测试的持续集成运行。
1、jmeter+ant集成
3)执行ant命令
4)查看可视化报告
2、ant+jmeter+jenkins集成
1)jenkins中配置环境变量
2)创建定时任务
3)运行结果
七、fiddler工具使用
一、fiddler概述
1、抓包工具
web系统最广泛使用的是http协议,属于应用层协议,常见抓包工具:
- fiddler:免费工具
- 浏览器
- charies:收费
- wireshark
2、fiddler抓包的原理
代理功能:
- 转发请求和响应的作用
- 拦截请求和响应
- 篡改请求和相应
- mock挡板
- 弱网
- 过滤请求
二、fiddler的抓包功能(必须掌握)
1、自动代理
fiddler是自动代理实现,只需要开启fiddler工具,代理就设置好了。
2、响应报文
响应状态行、响应头部、响应正文、空行
3、请求过滤
1)主机过滤
只显示局域网内的主机:
只显示互联网的主机:
指定主机名进行过滤
2)响应状态码过滤
三、fiddler的其他功能
1、篡改请求报文
案例:登录蜜锋电商系统:blue_001;抓到报文之后篡改为blue_002,看页面的显示结果
命令:bpu http://xxx.com/user/xxx.html?step=submit
取消请求拦截的命令:bpu
2、篡改响应报文
案例:登录蜜锋电商系统:blue_001;将其响应结果篡改为404页面
命令:bpafter http://xxx.com/user/xxx.html?step=submit
取消响应报文拦截:bpafter
3、mock挡板测试
1)设置挡板规则
2)查看mock的数据
4、弱网测试
为什么要做弱网测试:网络差的时候,系统会出现一些意想不到的问题。
调整网速(调延时),单位大小的文件上传/下载所需的时间。
相当于上传、下载的网络为5kb/s
在rules—performance—simulate modem speeds