Docker与Linux之间的关系——Namespace,Cgroups, 网络通信总结
文章目录
-
- 一、前言
- 二、Namespace
-
- Namespace Linux内核操作方法
- 容器隔离性与 Linux Namespace 关系
- Linux Namespace 常用操作
- 三、Cgroups
-
- Cgroups 子系统
-
- CPU 子系统
- cpuacct 子系统
- Memory 子系统
- Linux 调度器
- 使用 cgroup 限额实践
- 四、Docker
-
- Docker的文件系统
- OCI 容器标准
- Docker 引擎架构
- 五、容器网络
-
- 单机网络
-
- 通过Null 模式配置容器网络
- 默认模式-网桥和 NAT
- Underlay 网络
- Overlay 网络
- Flannel 网络
一、前言
容器有四大特性:
- 安全性
- 隔离性
- 可配额
- 便携性
该文章从容器与 Linux 系统之间的关系,主要从Namespace,Cgroups等LInux特性以及容器的实践以及Docker 的进一步创新,分析了四大特性的由来。
容器的发展并不是空中花园,一蹴而就,而是站在了Linux 这个巨人的肩膀上,它是对笨重的虚拟技术的不满,而进一步的创新,Docker 的基于分层的文件系统管理整个容器镜像,更是将容器技术推上了浪潮,同时也让Docker 从那个容器争霸的时代获胜,统一霸主地位。
如今机器部署早已成为了历史的产物,容器编排技术k8s的出现,更是将容器技术的发展推上了顶峰。
这里对自己学习的容器的核心技术做个总结,主要包括以下方面:
- 为什么说Linux 中一切皆文件?
- Linux 的核心Namespace与Cgroups是什么,有什么作用,他们与容器的四大特性之间有什么关系?
- 硬件,操作系统,容器之间的关系又是什么样的?
- 为什么Docker 能够获取容器的桂冠?什么是基于分层的文件管理系统,它有哪些好处?Docker是如何利用的?
- 容器标准是什么?Docker 引擎基于容器标准实现的架构是什么样的?
- 容器与主机如何实现网络通信的?不同主机上的容器是如何实现通信的?
二、Namespace
Namespace 技术并不是Docker 本身提出的,而是 Linux 内核自带的, Linux 内核中描述进程的一个结构体如下:
struct task_struct{
...
/*namespace*/
struct nsproxy *nsproxy;
}
struct nsproxy {
atomic_t count; // 引用计数
struct uts_namespace *uts_ns; // 主机名与NIS域名
struct ipc_namespace *ipc_ns; // System V IPC和POSIX message queue
struct mnt_namespace *mnt_ns; // 文件系统挂载点
struct pid_namespace *pid_ns_for_children; // 进程号
struct net *net_ns; // 网络设备、网络栈、端口号等
struct time_namespace *time_ns; // 系统单调时间及REAL_TIME
struct cgroup_namespace *cgroup_ns; // cgroup资源
};
task_struct为描述进程的一个结构体,其中包括一个描述进程命名空间的一个嵌套结构体nsproxy- 每一个进程都有自己的一系列namespace,这样Linux 就保证了进程间的隔离,容器的精髓就是利用了Linux 的namespace 保证了容器的隔离性
- 不同namespace 作用说明:
namespace 类型隔离资源IPCSystem V IPC 和 POSIX 消息队列Network网络设备、网络协议栈、网络端口等PID进程Mount挂载点UTS主机名和域名USR用户和用户组
- linux 在启动的时候会创建第一个进程systemd, 该进程包含自己的各个namespace,后续其他的进程都是通过systemd fork 出来的子进程,在fork 子进程的同时,也会将父进程的namespace 同时Copy过去
这就是为什么在使用Linux的时候感受不到namespace的存在
Namespace Linux内核操作方法
Linux 系统预留了用户对进程namespace的操作
clone
- 在fork 子进程时可以通过该方法指定需要新建哪些namespace
setns
- 调整一个进程的加入已经存在的namespace中
unshare
- 将调用进程移动到新的namespace下
容器隔离性与 Linux Namespace 关系
Pid namespace
- 不同用户的进程就是通过Pid namespace 隔离开的,且不同namespace 中可以有相同pid
- 有了Pid namespace 每个namespace 中的pid 能够相互独立
- 容器也是Linux上运行的一个进程,也是Linux 上的其他进程fork 出来的,拥有和父进程相同的namespace ,所以在容器外部可以通过ps 查看容器内部的进程
但是相同namespace 中容器内部的pid和外部的ps 看到的pid 是不一样的,容器会维护内部pid 与 主机pid的映射关系,容器在启动的时候会有一个ENTRYPOINT进程,这个就是容器自身在主机上的进程,容器内的所有进程都是通过该进程fork 出来的
这样就做到了容器间的进程隔离
net namespace
- 每个net namespace都拥有独立的network devices, IP address, IP routing tables, /proc/net 目录
- Docker 默认采用veth 的方式将container中的虚拟网卡同host 上的一个docker bridge:docker0 连接在一起
这样就做到了容器间的网络隔离
ipc namespace
- Linux进程间交互方法(interprocss communication-IPC), 包括常见的信号量,消息队列和共享内存
而只有相同IPC namespace 的进程才可以相互通信
容器在进程间通信上与Linux 进程间通信方式保持一致,因此需要在IPC资源申请的时候加入namespace 信息,才能保证容器间进程通信
mnt namespace
- mnt namespace 允许不同namespace的进程看到不同的文件目录结构
uts namespace
- UTS(“UNIX Time-sharing System”) namespace允许每个容器拥有独立的hostname和domain name
使其在网络上可以被视为一个独立的节点而非host上的一个进程
user namespace
- 每个容器可以有自己不同的user 和 group id,这样在容器内部执行的用户可以与主机上的用户不保持一致
Linux Namespace 常用操作
- 查看当前系统namespace
lsns -t
## 不指定类型将查询出当前用户已有的所有类型的net ns
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
4026531837 user 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
4026531838 uts 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
4026531839 ipc 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
4026531840 mnt 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
4026531956 net 8 729087 admin /home/admin/.minikube/cache/linux/amd64/v1.25.3/kubectl --context minikube proxy --port 0
## 查看root 用户下的 ns
## 可以发现systemd的ns 为1,为系统启动时的第一个进程,其他所有进程的ns都是继承于它
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo lsns
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 141 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026531837 user 252 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026531838 uts 153 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026531839 ipc 141 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026531840 mnt 139 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026531856 mnt 1 28 root kdevtmpfs
4026531956 net 245 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026532185 mnt 1 1055 chrony /usr/sbin/chronyd
4026532186 mnt 92 1431166 1000 [celeryd: celery@ali-jkt-dc-bnc-airflow-test02:MainProcess] -active- (worker
4026532187 uts 92 1431166 1000 [celeryd: celery@ali-jkt-dc-bnc-airflow-test02:MainProcess] -active- (worker
4026532188 ipc 92 1431166 1000 [celeryd: celery@ali-jkt-dc-bnc-airflow-test02:MainProcess] -active- (worker
- 查看某进程namespace
ls -la /proc/
每一个进程在/proc 目录下都有对应的pid 目录
## 打印出PID 1271557 对应的每个ns的id
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ls -la /proc/1271557/ns/
total 0
dr-x--x--x 2 root root 0 Dec 7 05:25 .
dr-xr-xr-x 9 root root 0 Nov 28 17:33 ..
lrwxrwxrwx 1 root root 0 Dec 7 05:25 ipc -> ipc:[4026532494]
lrwxrwxrwx 1 root root 0 Dec 7 05:25 mnt -> mnt:[4026532492]
lrwxrwxrwx 1 root root 0 Dec 7 05:25 net -> net:[4026532497]
lrwxrwxrwx 1 root root 0 Dec 7 05:25 pid -> pid:[4026532495]
lrwxrwxrwx 1 root root 0 Dec 7 05:25 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Dec 7 05:25 uts -> uts:[4026532493]
- 进入某namespace运行命令
nsenter -t -n ip addr
## 查看net ns 发现启动了一个go 程序
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531956 net 245 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026532227 net 2 1433135 65535 /pause
4026532300 net 2 1433134 65535 /pause
4026532497 net 3 1271557 root /bin/sh -c `go mod tidy`\x0a`go run main.go`\x0a
## 进入该go 程序的net ns 中执行查询ip 命令
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo nsenter -t 1271557 -n ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
462: eth0@if463: mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:15:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.21.0.2/16 brd 172.21.255.255 scope global eth0
valid_lft forever preferred_lft forever
- 使用新的namespace 执行命令
unshare -f -
# 在一个新的net namespace中执行一个sleep 180 命令
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo unshare -fn sleep 180
# 另开 一个窗口查看发现有新的net namespace 生成
# 该ns id为4026532595 包含的新执行命令的PID 3904433
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo lsns -t net
NS TYPE NPROCS PID USER COMMAND
4026531956 net 247 1 root /usr/lib/systemd/systemd --system --deserialize 23
4026532227 net 2 1433135 65535 /pause
4026532300 net 2 1433134 65535 /pause
4026532497 net 3 1271557 root /bin/sh -c `go mod tidy`\x0a`go run main.go`\x0a
4026532595 net 2 3904433 root unshare -fn sleep 180
# 当进程执行完后,/proc/ 下对应的文件会被删除
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo nsenter -t 3904433 -n ip a
nsenter: cannot open /proc/3904433/ns/net: No such file or directory
三、Cgroups
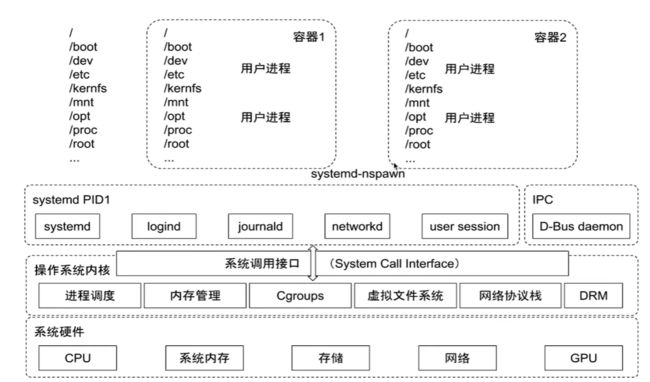
上图展示了容器与操作系统之间的关系,以及操作系统与系统硬件之间的关系
操作系统为运行在硬件上的一个软件,它实现了对硬件各个模块的操作接口,以提供给运行在操系统的上进程调用
操作系统启动运行的第一个进程就是systemd PID1,其他的所有进程都是通过该父进程fork 出来的,不同的进程间通过namespace 实现隔离,容器也是systemd fork 出来的子进程,也通过namespace 实现容器间的隔离
LInux 上通过Cgroups 实现进程对资源的限额配置,同样的容器也是通过Cgroups实现对资源大小的限制
Cgroups 子系统
Cgroups (Control groups), 一个cgroups 可以包含多个子系统,每个子系统就是对应一种资源的配额或者显示
Cgroup 会对其绑定的所有进程执行已有的子系统逻辑,所以想要对进程进行资源限制或者显示资源使用情况,只要和对应cgroup 绑定即可
- blkio: 该子系统限制每个块设备的输入输出控制。例如:磁盘,光盘以及USB等
- cpu: 该子系统使用调度程序为cgroup 任务提供CPU 的访问
- cpuacct: 产生cgroup 任务的CPU资源报告
- cpuset: 如果是多核CPU, 该子系统会为cgroup 任务分配单独的CPU和内存
- devices:允许或拒绝cgroup 任务对设备的访问
- freezer: 暂停和恢复cgroup 任务
- memory: 设置每个cgroup 的内存限制以及产生内存资源报告
- net_cls: 标记每个网络包以供cgroup 方便使用
- ns: 名称空间子系统
- pid: 进程标识子系统
LInux 资源分为可压榨资源与不可压榨资源
可压榨资源:比如说cpu
当对一个进程的CPU进行限制时,进程可以继续正常运行,只是运行的比较慢而已
不可压榨资源:比如说内存memory
当对一个进程的内存进行限制时,进程可能就无法启动,运行中的进程也可能被OOM KILLER
CPU 子系统
Linux的CPU子系统位于/sys/fs/cgroup/cpu目录下

当需要使用到CPU子系统对进程进行CPU限制或者查询CPU使用状况时,只需要在该目录下创建子目录,在创建完子目录后,Linux会自动将对应的配置文件复制一份至该子目录下:

然后需要做什么样的CPU配额,只要在对应的配置文件中配置就行了
配置文件说明
- cpu.shares: 进程能够使用CPU的相对时间
- cpu.cfs_period_us: 配置时间周期长度(微秒)
- cpu.cfs_quota_us: 在对应时间周期长度内最多能使用的CPU时间数,单位微秒,默认-1, 表示不限制
- cpu.stat: 进程使用的CPU时间统计
- nr_periods: 经过cpu.cfs_period_us的时间周期数量
- nr_throttled: 在经过的周期内,有多少次因为进程在指定的时间周期内用光了配额而受到限制
- throttled_time: Cgroup 中的进程被限制使用CPU的总用时,单位是ns(纳秒)

上图为使用相对时间划分CPU限制,Cgroup A 绑定的进程使用33%的CPU, Cgroup B 绑定的进程使用66%的CPU
但是并不是说Cgroup A永远只能使用33%的CPU,当 Cgroup B 的进程执行完毕后,此时如果A中的进程还没有执行完毕,那么A中的进程就可以利用100%的CPU(假设只有A和B两个CGroup的进程)
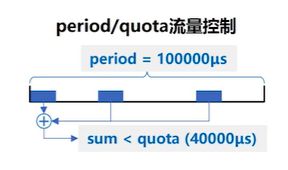
上图为使用时间周期(period)与 绝对时间限额(quota)来控制CPU使用:
该Cgroup下的进程在100000us内使用的CPU时间加起来不能超过40000us
cpuacct 子系统
用于统计 Cgroup 及其子 Cgroup 下进程的CPU的使用情况
- cpuacct.usage: 进程使用CPU的时间
- cpuacct.stat: 进程使用CPU的时间,以及用户态和内核态的时间
Memory 子系统
用于统计 Cgroup 及其子 Cgroup 下进程的内存的使用情况
- memory.usage_in_bytes: 进程使用的内存
- memory.max_usage_in_bytes: 进程使用内存的最大值
- memory.limit_in_bytes: 进程最多能使用的内存。-1 表示不限制
- memory.oom_control: 当进程超出最大限制,将被OOM Killer 处理,默认为开启
Linux 调度器
内核默认提供5个调度器,Linux 内核使用struct sched_class来对调度器进行抽象
-
Stop调度器,stop_sched_class: 优先级最高的调度类,可以抢占其他所有进程,不能被其他进程抢占
-
Deadline调度器,dl_sched_class: 使用红黑树,把进程按照绝对截止期限进行排序,选择最小进程进行调度运行
-
RT调度器,rt_sched_class: 实时调度器,为每个优先级维护一个队列
-
CFS调度器,cfs_sched_class: 完全公平调度器,采用完全公平算法,引入虚拟运行时间概念
- vruntime = 实际运行时间*1024/进程权重
- 进程权重越大,vruntime 运行的就越慢,
-
IDLE-Task调度器,idle_sched_class: 空闲调度器,每个CPU都会有一个idle线程,当没有其他进程可以调度时,调度运行idle线程
CFS调度器与红黑树
- CFS调度器没有将进程维护在运行队列中,而是维护了一个以虚拟运行时间为顺序的红黑树:

-
红黑树特点:
查询速度快log(n),自平衡, 稳定(层级差不超过2)
-
Linux把 vruntime 最小的进程放在最左边,vruntime 最大的进程放在**最右边,**CFS调度器每次选取树的最左边的节点运行
进程优先级越高的进程,vruntime 越小,这样就保证了优先级高的进程先运行
使用 cgroup 限额实践
- 启动一个消耗CPU的进程,这里在linux 上运行一个go 程序:
package main
// 主程序阻塞,将消耗一个CPU
// 主程序中启动一个goroutine 阻塞,将消耗一个CPU
// 加起来将消耗两个CPU
func main() {
go func() {
for {
}
}()
for {
}
}
运行后,再开一个窗口通过top查看该进程消耗的CPU,发现稳定消耗在2个CPU,对应的PID为 4129204 :

在CPU子系统中,对该进程(PID 4129204)进行CPU限额(root 用户才有权限操作)
将该进程添加进刚才在CPU子系统下创建的cpudemo目录下的cgroup.porcs文件中:
[root@ali-jkt-dc-bnc-airflow-test02 cpudemo]# echo 4129204 > cgroup.procs
默认下是没有对CPU限额的:
[root@ali-jkt-dc-bnc-airflow-test02 cpudemo]# cat cpu.cfs_period_us 100000 ## -1 表示不限额 [root@ali-jkt-dc-bnc-airflow-test02 cpudemo]# cat cpu.cfs_quota_us -1
修改在周期内的绝对时间cpu.cfs_quota_us达到限额:
## 修改为和 cpu.cfs_period_us 一样 ## 通过公式CPU = quota/period 计算出最多消耗1个CPU
[root@ali-jkt-dc-bnc-airflow-test02 cpudemo]# echo 100000 > cpu.cfs_quota_us
top 查看发现确实只消耗了一个CPU:

四、Docker
上边总结的Namespace和Cgroups都是Linux 本身就有的,如果说Docker仅仅实现了这些功能,还不能足以说明Docker的强大
在那个容器化大战的时代,使Docker 真正能够横扫六合的是开创了OverlayFS的创举:
- 提出容器镜像的概念
- 基于分层的文件系统管理整个容器镜像
Docker的文件系统
Union FS
Docker 的文件系统利用了Union FS技术:
- 将不同目录挂载到同一个虚拟文件系统下(unit several directories into a single virtual filesystem)
- 支持每一个成员目录(类似Git Branch)设定readonly、readwrite 和 whiteout-able 权限
- 文件系统分层,对 readonly 权限的 branch 可以逻辑上进行修改(增量地,不影响readonly 部分的)
- 通常Union FS 有两个用途,一方面可以将多个 disk 挂到同一个目录下,另一个更常用的就是将一个 readonly 的 branch 和一个 writeable 的 branch 联合在一起
有了 Union FS 技术,就可以将不同来源的不同子目录联合,并且目录都有自己的权限控制,这样就模拟了一个完整的文件系统
容器镜像
Docker 利用 Union FS 技术的实现产物就是容器镜像,同时这也是 Docker 成功的重大原因
Docker 规定可以通过 Dockerfile 这种源代码的方式来创建容器镜像,运行开发人员定义一个面向应用的容器镜像构建的源代码
可以说这是打破了运维与开发边界的第一步,Dockerfile 的简单易上手,迅速吸引了大批的用户
Union FS 在 Dockerfile 中的体现
- Dockerfile 源代码的每一行代表一层文件系统,在构建容器镜像的时候,有多少行就会执行构建多少层
- 从上往下,每一层都是基于上一层构建的,因此在编写 Dockerfile 的时候最好是将不会经常变更的,通用的层级写在上边,会经常变更的层级写在下边
这样在同一台 Linux 主机上多次通过 Dockerfile 构建的时候,会先查找主机上是否已经有相同的层级构建过,如果构建过就会使用已有的,然后继续下一层的构建
Linux 文件系统
Linux 文件系统主要由两部分组成:
-
Bootfs(boot file system)
- Bootloader——引导加载kernel
- Kernel——当 kernel 被加载到内存中后 umount bootfs
-
rootfs (root file system)
- /dev, /proc, /bin, /etc 等标准目录和文件
- 对于不同的 linux 发行版,bootfs (kernel)基本是一致的,但 rootfs 会有差别
Docker 启动
Linux
- 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查,然后将其切换为 readwrite 供用户使用
Docker 启动

- 初始化时也是将 rootfs 以 readonly 方式加载并检查, 然而接下来利用 union mount 的方式将一个 readwrite 文件系统挂载在 readonly 的 rootfs 之上
- 并且运行再次将下层的 FS(file system) 设定为 readonly 并且向上叠加
- 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态,每一个 FS 被称作一个 FS 层
当启动完成之后,就只有最上层是writeable的,下边的层级就都是 readonly
可以发现 Docker 的启动模仿了Linux的启动方式,不过 Docker 妙就妙在可以分层多次构建,在通过Dockerfile 暴露出需要构建的层级,以及每个层级需要构建的内容,这样就实现了配置化构建,根据程序所需的环境依赖,来构建出不同的文件系统,命名为容器镜像
写操作
由于镜像具有共享特性,所以对容器可写层的操作需要依赖存储驱动提供的写时复制和用时分配机制,来支持对容器可写层的修改,进而提高对存储和内存资源的利用率
-
写时复制
当一个镜像被多个容器使用,在主机上不需要保存该镜像的多个副本。在需要对镜像提供的文件进行修改时,该文件会从镜像的文件系统被复制到容器的可写层的文件系统进行修改,而镜像里边的文件不会改变。不同容器对文件的修改都相互独立、互不影响
-
用时分配
按需分配空间,而非提前分配,即当一个文件被创建出来后,才会分配空间
容器存储驱动
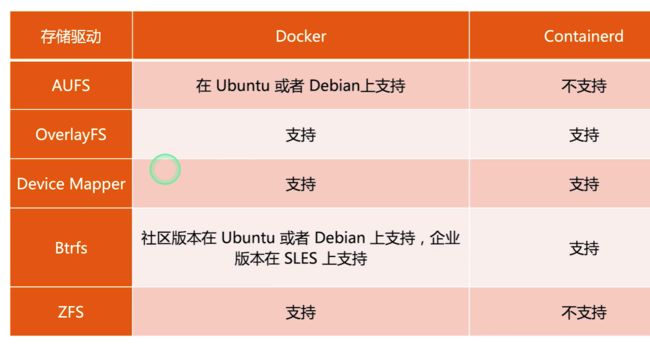
- Device Mapper 为 kernel 自带的容器存储驱动
- 现在用得到存储驱动最多的是OverlayFS
- Containerd 为k8s 支持的容器运行时,由于Docker 与 k8s 的历史纠纷,Docker 后来也内嵌了containerd 作为容器运行时
- 各种存储驱动优缺点对比:

OverlayFS 文件存储驱动
- Overlay 只有两层: upper 层和 lower 层, Lower 层代表镜像层, upper 层代表容器可写层
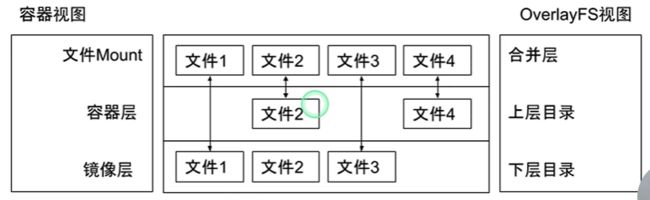
上图的基础镜像层FS包括文件1,2,3
现在有一个容器引用了该镜像并且需要修改可写层,修改镜像的文件2 并且添加文件4
使用overlay 存储驱动就会将Lower 层(基础镜像层)upper 层(容器层)合并为新的FS,这样就保证了基础镜像的FS没有变更,又保证了新的FS(可写层)同时包含基础镜像的文件以及修改后的文件
OCI 容器标准
Open Container Initiative
OCI 组织与2015年创建,是一个致力于定义容器镜像标准和运行时标准的开放式组织
- 镜像标准定义应用如何打包
- 运行时标准定义如何解压应用包并运行
- 分发标准定义如何分发容器镜像
Docker 引擎架构

-
Docker daemon
Docker 服务本身的后台程序,对外提供REST API
-
Docker Commond
输入docker 命令,发送到Docker daemon 中去
-
containerd
Docker 新版都支持了OCI容器标准,Docker daemon 收到commond的命令后通过GRPC发送至containerd
containerd 负责给需要操作的容器进程启动一个父进程shim,将commond 需要操作的进程控制权完全交给shim 进程,然后将shim 进程的管理交给操作系统的init 进程 systemd,这样containerd 就会很轻量级,无需管理大量的进程,只需要创建shim 进程就行了
这样containerd的升级和修改就可以非常简单
containerd 可以独立出为单独的组件,这样就保证了当我们升级Docker 版本的时候,只需要升级Docker daemon 即可,只要containerd 正常运行,在升级的时候就不会影响容器中运行中的进程
-
shim
由 containerd 创建的进程,控制着运行时进程runc的整个生命周期
五、容器网络
单机网络
Docker 支持的几种网络模式
Null(–net=None)
- 把容器放入独立的网络空间但不做任何网络配置
- 用户需要通过运行 docker network 命令完成网络配置
- 当使用容器编排工具的时候,比如说k8s,就希望通过自己的网络插件(如Flannel)去创建容器网络,这个时候就会使用到 Null 模式
Host
- 使用主机网络名空间,复用主机网络
Conrtainer
- 重用其他容器的网络
- 假如一个容器启动一个服务,当使用Container 网络模式的时候,多个服务就在同一个网络 Namespace 中,可以直接通过 localhost 去相互访问
Bridge(–net=bridge)
- Docker 模式使用的网络模式
- 使用 Linux 网桥和 iptables 提供容器互联,Docker 在每台主机上创建一个名叫 docker0 的网桥,通过 veth pair 来连接该主机的每一个 EndPoint
跨主机网络通信
如果将网络分为容器网络与基础架构网络(主机本身网络) ,容器内的网络是没办法直接在基础架构网络间通信的。
上边几种网络模式都是单机的网络模式,也就是实现了容器间网络与所在主机本身网络间的通信,但是跨主机之间的容器网络通信仅仅依赖于上边的是不够的,下边为两个常用的跨主机间的容器网络通信方式:
Overlay(libnetwork, libkv)
- 通过网络封包实现,将源主机发出访问的容器网络相关信息与需要访问的目标主机上对应容器信息封装
Underlay
-
使用现有底层网络,为每一个容器配置可路由的网络IP
-
优点
实现简单直接利用主机IP间通信,不需要封包,解包,网络访问效率相对于 Overlay 较高
缺点
需要自己规划对应IP, 需要一定的管理成本,管理不当容易造成IP失效
通过Null 模式配置容器网络
容器启动后,会在主机上启动一个 docker0 的网络,容器的所有内部网络都是通过docker0 去分配与管理的,现在要配置一个容器内的网络与主机网络互通,流程如下:
- 为容器配置一个网络
# 1. 创建一个目录保存新建的net namespace信息
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ mkdir -p /var/run/netns
# 2. 启动一个不指定网络的 nginx 容器
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ docker run --network=none -d nginx
# 3. 查看容器的进程号
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ docker ps | grep nginx
b3653a372d31 nginx "/docker-entrypoint.…" About a minute ago Up 58 seconds keen_hawking
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ docker inspect b3653a372d31 | grep -i pid
"Pid": 752524,
"PidMode": "",
"PidsLimit": null,
# 3. 进入ns中查看该进程ip 信息
# 目前只有lo回环ip,因为还没有配置相关网络
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo nsenter -t 752524 -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
# 4. 建立进程与新建网络ns 之间的关联关系
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ export pid=752524
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ln -s /proc/$pid/ns/net /var/run/netns/$pid
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ ll /var/run/netns/$pid
lrwxrwxrwx 1 root root 19 Dec 11 07:33 /var/run/netns/752524 -> /proc/752524/ns/net
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ ip netns list
752524
cni-10a27892-3539-fbae-48ce-479c9ec72496 (id: 1)
cni-be8d609e-00db-c086-d971-b5ce84486e43 (id: 0)
# 5. 确认docker0 网络正常
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ ip a | grep docker0
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
inet 172.17.0.1/16 scope global docker0
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ brctl show | grep docker0
docker0 8000.0242a5c49e4d no
- 用一根线将容器内的网络与docker0相连
# 6. 建立一根ip网线 veth pair
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip link add A type veth peer name B
# 7. 为docker0 网络添加interface A
# 将网线A端连接网络doker0
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo brctl addif docker0 A
# 查看下docker0的信息,发现多了个A, 但是此时该接口还无效,需要up
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ brctl show docker0
bridge name bridge id STP enabled interfaces
docker0 8000.0242a5c49e4d no A
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip link set A up
# 8. 配置容器内ip 并且与网线B端相连
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ SETIP=172.17.0.10
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ SETMASK=16
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ GATEWAY=172.17.0.1
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip link set B netns $pid
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip netns exec $pid ip link set dev B name eth0
# 查看下 netns 中该进程的ip信息,发现多了一个网络eth0 和主机上的465网络相连
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo nsenter -t $pid -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
464: eth0@if465: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 9e:94:44:8c:d3:f8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# 查看主机ip发现465网络与docker0相连
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ ip a | grep 465
465: A@if464: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue master docker0 state LOWERLAYERDOWN group default qlen 1000
# 9. 为容器内eth0 网络添加ip并且up
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip netns exec $pid ip link set eth0 up
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip netns exec $pid ip addr add $SETIP/$SETMASK dev eth0
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo ip netns exec $pid ip route add default via $GATEWAY
# 查看容器内网络,发现有了ip并且处于up 状态
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ sudo nsenter -t $pid -n ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
464: eth0@if465: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 9e:94:44:8c:d3:f8 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.10/16 scope global eth0
valid_lft forever preferred_lft forever
# 最后curl 请求验证容器内网络是否与主机网络互通
[admin@ali-jkt-dc-bnc-airflow-test02 ~]$ curl 172.17.0.10
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
默认模式-网桥和 NAT
当使用docker run 命令使用默认网络配置的时候,docker 会使用桥接模式为每一个容器配置一个eth0的网络并且与docker0网络相连,也就是上边我们自己通过Null 模式操作的流程步骤

Underlay 网络
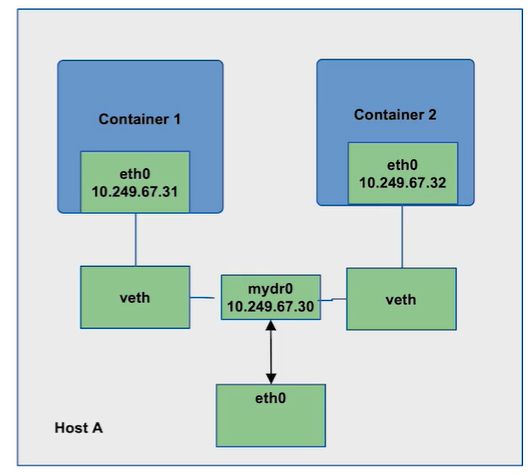
- underlay 网络会创建一个新的网桥mydr0,并把主机网卡的地址配置到网桥,并把默认路由规则转移到网桥 mydr0
- 在每次创建一个容器的时候,都会使用veth 技术一端连接网桥,另一端连接容器内部网络
- 这里网桥的ip 与 容器内的ip 都是与主机网卡ip 在同一个网段下边,也就是说直接将主机的网络ip 分配给了容器。
这样做的好处就是配置简单,但是增加了对ip 的管理成本,否则容易造成ip 浪费,导致ip 不够的问题
Overlay 网络
Docker overlay 网络驱动原生支持多主机网络,Libnetwork 是一个内置的基于VXLAN 的网络驱动
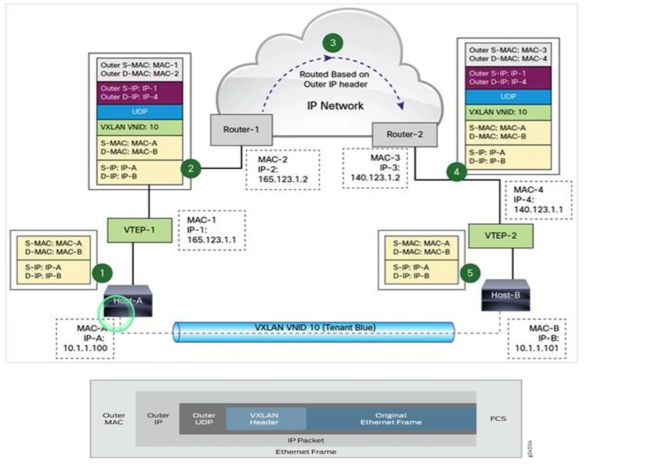
假设如上一台虚拟机A(ip 为10.1.1.100 )运行在主机A上(IP为165.123.1.1),现在需要发送网络请求到主机B(IP为140.123.1.1)的虚拟机B上(IP为10.1.1.101)
- 虚拟机A发送请求消息体包含源虚拟机IP与目标虚拟机IP信息
- VTEP-1设备在原始请求消息体中增加VXLAN包头(包含VXLAN ID的UDP封装),封装了源主机IP与目标主机IP信息
- 主机A发送的消息体通过网络到达主机B
- 主机B的VTEP-2设备接收到该消息体后,发现是个VXLAN请求,就会解包,将请求发送到虚拟机B上
Flannel 网络
Flannel 为k8s的一个网络插件是overlay网络的一种实现方式,将多个主机间Pod网络通信相连
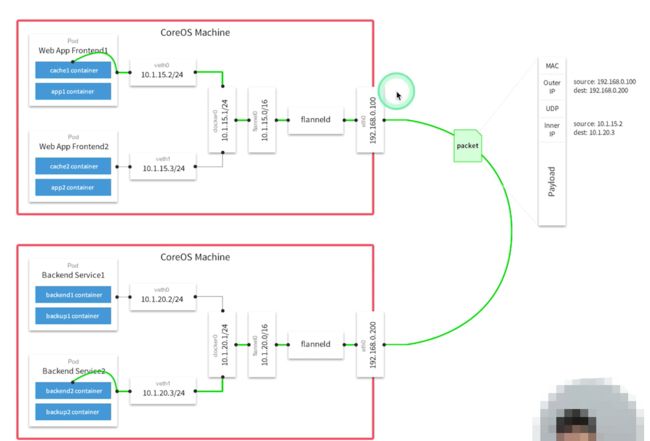
如上有两台机器一台运行着两个前端应用Pod,一台运行着两个后端服务Pod,现在前端需要访问后端地址
- 可以发现在每台机器上都会运行一个flanneld 程序用于封包和解包
- 遵循overlay 规范在内部消息体之上封装了外部消息体
- 一个Pod请求先经过docker0 网络与主机实现通信,然后在通过flannel0网络实现与主机上的flanneld 程序通信,此时flanneld 就可以对Pod 请求进一步封装或者解包
Ping 命令网络抓包
