Flink学习(5)——state(状态)管理
1. 什么是flink state
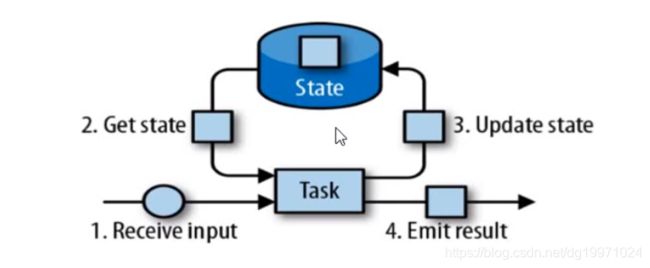
由一个任务维护,并且用来计算某个结果的数据,都属于这个任务的状态,可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。
Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以 便开发人员可以专注于应用程序的逻辑。
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。
两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
具体区别有:
1. 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当横向伸缩,或者说修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
2. 从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
对Managed State继续细分,它又有两种类型:Keyed State和Operator State。
为了自定义Flink的算子,可以重写Rich Function接口类,比如RichFlatMapFunction。使用Keyed State时,通过重写Rich Function接口类,在里面创建和访问状态。对于Operator State,还需进一步实现CheckpointedFunction接口。
2. 算子状态(operator state)
算子状态的作用范围限定为当前算子任务,当前算子任务中的所有数据都可以访问到相同的状态,但不能被另一个算子任务访问,哪怕是处理同一类算子的并行任务。
2.1 算子状态的数据结构
1. 列表状态
即采用List的数据结构,存储多个数据作为状态数据
2. 联合列表状态
也是采用List的数据结构,但和列表状态的区别在于其在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
列表状态在恢复程序的时候,会依据恢复后的并行度,将列表中的状态数据进行拆分,拆分为新的列表状态后在分发给各个并行算子。
而联合列表状态则是将所有的列表状态合并为一个完整的列表状态,然后给每一个新的并行算子任务发送一份作为自身状态。
3. 广播状态:这种情况比较特殊,其适用于各个算子之间要求状态值相同的情况,比如说一些配置参数,各个算子公用一套配置参数,这种情况就比较适合广播状态。
2.2 算子状态api使用
算子状态的api应用较少,比较常见的 operator state 是 source state,例如记录当前 source 的 offset,这个在以kafka作为source的时候非常常用,我们可以通过记录offset来判断kafka中的消息积压情况。
主要是在算子实现类中实现ListCheckpointed接口,就可以实现算子状态的存储和恢复。
还有一种实现CheckpointedFunction接口的,但比较复杂,实现ListCheckpointed比较简单清晰,但通过CheckpointedFunction接口实现会比较灵活。
官方参考链接:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/state.html#listcheckpointed
public class OperatorStateTest1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//从文本文件中按行读取数据
DataStreamSource streamSource = env.readTextFile("word.txt");
SingleOutputStreamOperator> sum = streamSource.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
sum.print();
env.execute();
}
//通过算子状态来记录统计一下处理的数据数量
public static class MyFlatMapper implements FlatMapFunction>, ListCheckpointed {
//其实算子状态很简单,直接定义一个变量就能实现所需要的数据量统计
int count = 0;
//仅通过count这个状态变量我们依据实现了所需要的的统计功能,但是问题在于,当程序异常终止又重新启动后,
//flink要如何恢复这个变量值?
//我们肯定不能重新读取数据,把所有数据重新处理一遍
//所以我们可以通过Flink提供的接口来实现状态数据的快照保存和恢复
//MyFlatMapper实现ListCheckpointed接口即可
public void flatMap(String s, Collector> collector) throws Exception {
//统计一下处理一条数据
count++;
//按空格分词
String[] s1 = s.split(" ");
//遍历所有单词,变成二元组输出
for (String word:s1) {
collector.collect(new Tuple2(word, 1));
}
}
//状态快照,通过这个方法实现将状态数据保存起来
@Override
public List snapshotState(long checkpointId, long timestamp) throws Exception {
return Collections.singletonList(count);
}
//状态恢复,job重新启动的时候,通过该方法恢复状态值
@Override
public void restoreState(List list) throws Exception {
for (Integer num : list) {
count += num;
}
}
}
} 3. 键控状态(keyed state)
根据输入数据流中定义的键(key)来维护和访问。
Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到 同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。
当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。
只能应用于 KeyedStream 的函数与操作中,例如 Keyed UDF, window state。
3.1 键控状态支持的数据结构
1. 值状态(Value state)
ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
2. 列表状态(List state)
ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素;并通过 get() 获得整个列表。
3. 映射状态(Map state)
MapState:维护 Map 类型的状态。
4. 聚合状态(Reducing state & Aggregating State)
ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
3.2 键控状态api使用
键控状态涉及到运行时上下文变量的引用,所以必须是在富函数中使用。这里仅以ValueState做一个示例
public class KeyStateTest1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource streamSource = env.readTextFile("word.txt");
SingleOutputStreamOperator> sum = streamSource.flatMap(new MyFlatMapper())
.keyBy(0)
.reduce(new MyReduceFunction());
sum.print();
env.execute();
}
public static class MyFlatMapper implements FlatMapFunction> {
public void flatMap(String s, Collector> collector) throws Exception {
//按空格分词
String[] s1 = s.split(" ");
//遍历所有单词,变成二元组输出
for (String word:s1) {
collector.collect(new Tuple2(word, 1));
}
}
}
public static class MyReduceFunction extends RichReduceFunction> {
//声明state,用于统计key的出现次数
private transient ValueState keyCountState;
//必须在open方法中进行初始化
@Override
public void open(Configuration parameters) throws Exception {
keyCountState = getRuntimeContext().getState(new ValueStateDescriptor("keyCount", Integer.class));
if (keyCountState.value() == null) {
keyCountState.update(0);
}
}
//在这里进行数据更新
@Override
public Tuple2 reduce(Tuple2 stringIntegerTuple2, Tuple2 t1) throws Exception {
//统计key出现次数
Integer count = keyCountState.value();
count++;
keyCountState.update(count);
int i = stringIntegerTuple2.f1 + t1.f1;
stringIntegerTuple2.f1 = i;
return stringIntegerTuple2;
}
}
}
4. 状态后端(Statebackend)
上面我们知道了如何去使用Flink中的状态变量来管理状态数据,接下来,我们就要知道这些状态数据是如何存储以及恢复的。
(1)每传入一条数据,有状态的算子任务都会读取和更新状态。
(2)由于有效的状态访问对于处理数据的低延迟至关重要,因此每个并行任务都会在本地维护其状态,以确保快速的状态访问
(3)状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend)
(4) 状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
4.1 Flink提供的状态后端类型
Flink中提供了三种Flink状态后端,分别是MemoryStateBackend、FsStateBackend和RocksDBStateBackend。
1. MemoryStateBackend:
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中;
当进行分布式快照时,所有算子子任务将自己内存上的状态同步到JobManager的堆上,一个作业的所有状态要小于JobManager的内存大小。这种方式显然不能存储过大的状态数据,否则将抛出OutOfMemoryError异常。因此,这种方式只适合调试或者实验,不建议在生产环境下使用。下面的代码告知一个Flink作业使用内存作为State Backend,并在参数中指定了状态的最大值,默认情况下,这个最大值是5MB。
优点是读写快速,状态数据读写延迟低;缺点就是不稳定,一旦宕机状态数据就会丢失,一般不会使用。
env.setStateBackend(new MemoryStateBackend(MAX_MEM_STATE_SIZE))2. FsStateBackend:
将 checkpoint 存到远程的持久化文件系统(FileSystem)上,比如hdfs,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。
同时拥有内存级的本地访问速度,和更好的容错保证,一般都会使用这种。
// 使用HDFS作为State Backend
env.setStateBackend(new FsStateBackend("hdfs://namenode:port/flink-checkpoints/chk-17/"))
// 使用阿里云OSS作为State Backend
env.setStateBackend(new FsStateBackend("oss:///"))
// 使用Amazon作为State Backend
env.setStateBackend(new FsStateBackend("s3:///"))
// 关闭Asynchronous Snapshot
env.setStateBackend(new FsStateBackend(checkpointPath, false)) 3. RocksDBStateBackend:
这种方式下,本地状态存储在本地的RocksDB上。RocksDB是一种嵌入式Key-Value数据库,数据实际保存在本地磁盘上。比起FsStateBackend的本地状态存储在内存中,RocksDB利用了磁盘空间,所以可存储的本地状态更大。然而,每次从RocksDB中读写数据都需要进行序列化和反序列化,因此读写本地状态的成本更高。快照执行时,Flink将存储于本地RocksDB的状态同步到远程的存储上,因此使用这种State Backend时,也要配置分布式存储的地址。Asynchronous Snapshot在默认情况也是开启的。
此外,这种State Backend允许增量快照(Incremental Checkpoint),Incremental Checkpoint的核心思想是每次快照时只对发生变化的数据增量写到分布式存储上,而不是将所有的本地状态都拷贝过去。Incremental Checkpoint非常适合超大规模数据量的状态,快照的耗时将明显降低,同时,它的代价是重启恢复的时间更长。默认情况下,Incremental Checkpoint没有开启,需要我们手动开启。
// 开启Incremental Checkpoint env.setStateBackend(new RocksDBStateBackend(checkpointPath, true))
4.2 配置Flink采用的状态后端
可以直接对集群的配置文件进行修改配置,但太麻烦,而且每个Job的情况不一样,不一定全部采用同一种配置,可以使用另一种配置方法,在代码中配置。
//状态后端组件配置
public static void main(String[] args) throws IOException {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置状态后端配置
//1. 纯内存存储状态
env.setStateBackend(new MemoryStateBackend());
//2. 远程文件系统存储(hdfs)+本地内存存储,即状态恢复时会从hdfs读取状态,而运行时的状态读取则从内存中直接读取
env.setStateBackend(new FsStateBackend(""));
//rocksdb存储,状态恢复和运行时状态读取全部从rocksdb中进行
env.setStateBackend(new RocksDBStateBackend(""));
}个人理解其实Flink中所谓的状态,本身也是一个统计计算的数据结果,可以举个例子:
比如说在统计年度销售额的时候,我们就可以通过状态机制来存储计算过程中的销售额,这样即使job程序突然终止了,我们也可以重新启动job,然后恢复checkpoint获取之前已经计算的数据结果,这样就不用重新跑一次数据,只要从checkpoint点恢复就可以了。
5. Checkpoint机制执行流程
什么是 Checkpoint
Checkpoint 即一致性检查点,Checkpoint机制即一致性检查机制,是Flink故障恢复的核心机制,该机制是指触发从 source 到下游所有任务节点状态数据在某个时间点的快照,而这个时间点应该是所有任务节点在处理完同一条数据之后。什么是 State
State 其实就是 Checkpoint 所做的主要持久化备份的主要数据。
5.1 执行流程
首先我们来看一下一个简单的Checkpoint的大致流程:
(1)暂停处理新流入数据,将新数据缓存起来。
(2)将算子子任务的本地状态数据拷贝到一个远程的持久化存储上。
(3)继续处理新流入的数据,包括刚才缓存起来的数据。
Flink是在Chandy–Lamport算法[1]的基础上实现的一种分布式快照算法。在介绍Flink的快照详细流程前,我们先要了解一下检查点分界线(Checkpoint Barrier)的概念。如下图所示,Checkpoint Barrier被插入到数据流中,它将数据流切分成段。Flink的Checkpoint逻辑是,一段新数据流入导致状态发生了变化,Flink的算子接收到Checpoint Barrier后,对状态进行快照。每个Checkpoint Barrier有一个ID,表示该段数据属于哪次Checkpoint。如图所示,当ID为n的Checkpoint Barrier到达每个算子后,表示要对n-1和n之间状态的更新做快照。Checkpoint Barrier有点像Event Time中的Watermark,它被插入到数据流中,但并不影响数据流原有的处理顺序。
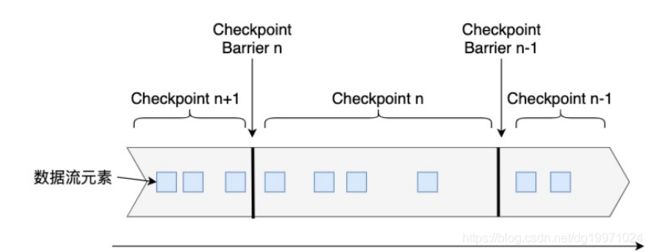
接下来,我们构建一个并行数据流图,用这个并行数据流图来演示Flink的分布式快照机制。这个数据流图有两个Source子任务,数据流会在这些并行算子上从Source流动到Sink。
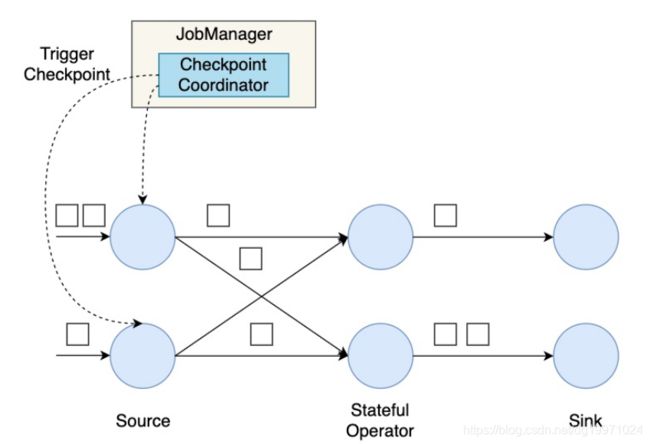
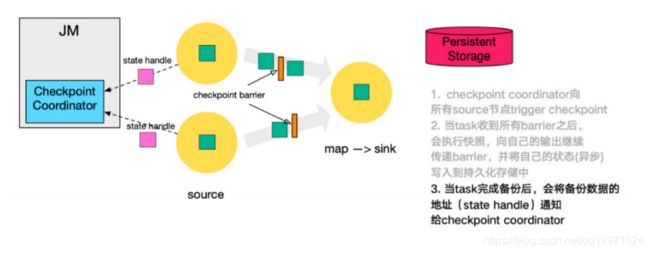
首先,Flink的检查点协调器(Checkpoint Coordinator)触发一次Checkpoint(Trigger Checkpoint),这个请求会发送给Source的各个子任务。
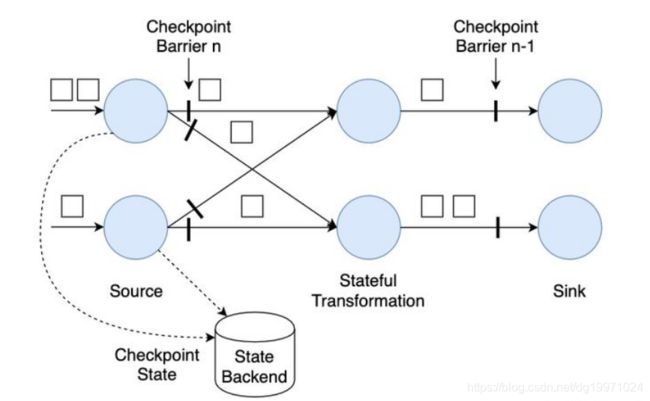
各Source算子子任务接收到这个Checkpoint请求之后,会将自己的状态写入到状态后端,生成一次快照,并且会向下游广播Checkpoint Barrier。
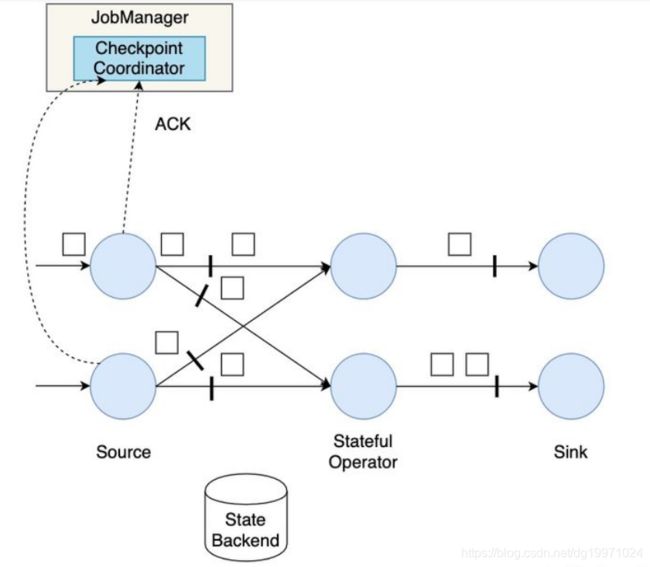
Source算子做完快照后,还会给Checkpoint Coodinator发送一个确认,告知自己已经做完了相应的工作。这个确认中包括了一些元数据,其中就包括刚才备份到State Backend的状态句柄,或者说是指向状态的指针。至此,Source完成了一次Checkpoint。跟Watermark的传播一样,一个算子子任务要把Checkpoint Barrier发送给所连接的所有下游算子子任务。
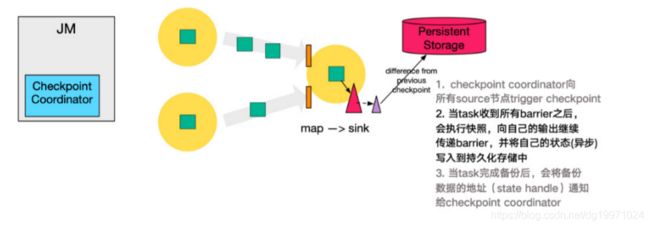
对于下游算子来说,可能有多个与之相连的上游输入,我们将算子之间的边称为通道。Source要将一个ID为n的Checkpoint Barrier向所有下游算子广播,这也意味着下游算子的多个输入里都有同一个Checkpoint Barrier,而且不同输入里Checkpoint Barrier的流入进度可能不同。Checkpoint Barrier传播的过程需要进行对齐(Barrier Alignment),我们从数据流图中截取一小部分来分析Checkpoint Barrier是如何在算子间传播和对齐的。
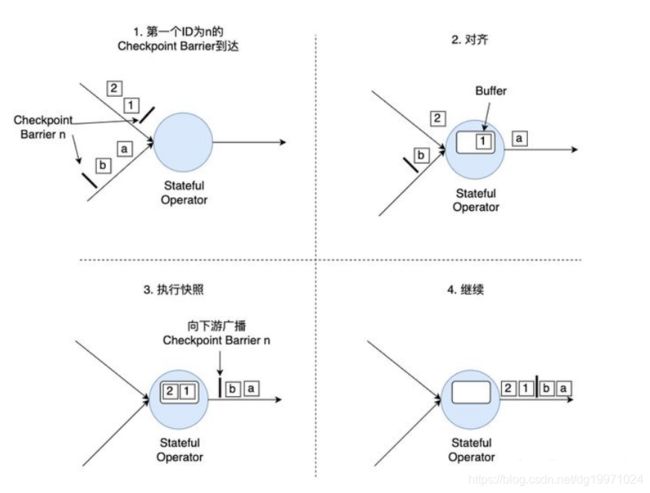
如上图所示,对齐分为四步:
- 算子子任务在某个输入通道中收到第一个ID为n的Checkpoint Barrier,但是其他输入通道中ID为n的Checkpoint Barrier还未到达,该算子子任务开始准备进行对齐。
- 算子子任务将第一个输入通道的数据缓存下来,同时继续处理其他输入通道的数据,这个过程被称为对齐。
- 第二个输入通道的Checkpoint Barrier抵达该算子子任务,该算子子任务执行快照,将状态写入State Backend,然后将ID为n的Checkpoint Barrier向下游所有输出通道广播。
- 对于这个算子子任务,快照执行结束,继续处理各个通道中新流入数据,包括刚才缓存起来的数据。
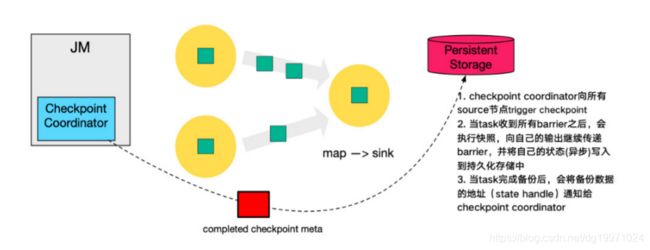
数据流图中的每个算子子任务都要完成一遍上述的对齐、快照、确认的工作,当最后所有Sink算子确认完成快照之后,说明ID为n的Checkpoint执行结束,Checkpoint Coordinator向State Backend写入一些本次Checkpoint的元数据。
之所以要进行对齐,主要是为了保证一个Flink作业所有算子的状态是一致的。也就是说,某个ID为n的Checkpoint Barrier从前到后流入所有算子子任务后,所有算子子任务都能将同样的一段数据写入快照。
对上面的流程在大概梳理一下:
1. 第一步,JobManager中的Checkpoint Coordinator 向所有 source 节点 trigger Checkpoint(触发Checkpoint);
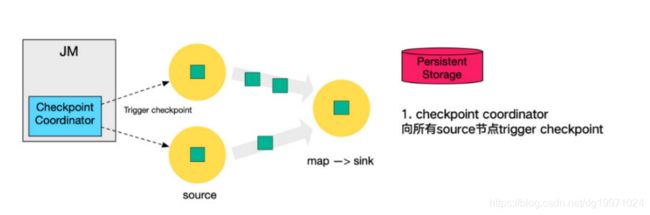
2. 第二步,source 节点向下游广播 barrier,这个 barrier 就是实现 Chandy-Lamport 分布式快照算法的核心,下游的 task 只有收到来自上游所有算子任务的 barrier 才会执行相应的 Checkpoint。
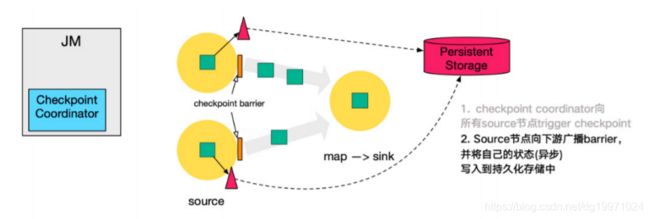
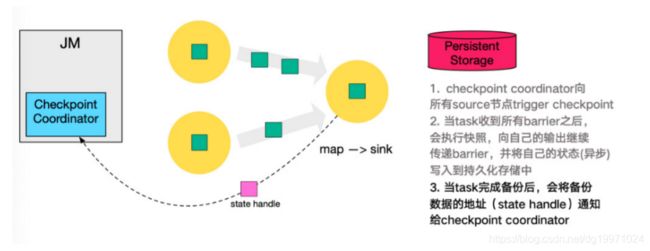
3. 第三步,当 task 完成 state 备份后,会将备份数据的地址(state handle)通知给 Checkpoint coordinator。
4. 第四步,下游的 sink 节点收集齐上游两个 input 的 barrier 之后,会执行本地快照,这里特地展示了 RocksDB incremental Checkpoint 的流程,首先 RocksDB 会全量刷数据到磁盘上(红色大三角表示),然后 Flink 框架会从中选择没有上传的文件进行持久化备份(紫色小三角)。
5. 同样的,sink 节点在完成自己的 Checkpoint 之后,会将 state handle 返 回通知 Coordinator。
6. 最后,当 Checkpoint coordinator 收集齐所有 task 的 state handle,就认为这一次的 Checkpoint 全局完成了,向持久化存储中再备份一个 Checkpoint meta 文件。
5.2 checkpoint配置
默认情况下,Checkpoint机制是关闭的,需要调用env.enableCheckpointing(n)来开启,每隔n毫秒进行一次Checkpoint。Checkpoint是一种负载较重的任务,如果状态比较大,同时n值又比较小,那可能一次Checkpoint还没完成,下次Checkpoint已经被触发,占用太多本该用于正常数据处理的资源。增大n值意味着一个作业的Checkpoint次数更少,整个作业用于进行Checkpoint的资源更小,可以将更多的资源用于正常的流数据处理。同时,更大的n值意味着重启后,整个作业需要从更长的Offset开始重新处理数据。
此外,还有一些其他参数需要配置,这些参数统一封装在了CheckpointConfig里:
CheckpointConfig checkpointConfig = env.getCheckpointConfig();默认的Checkpoint配置是支持Exactly-Once投递的,这样能保证在重启恢复时,所有算子的状态对任一条数据只处理一次。用上文的Checkpoint原理来说,使用Exactly-Once就是进行了Checkpoint Barrier对齐,因此会有一定的延迟。如果作业延迟小,那么应该使用At-Least-Once投递,不进行对齐,但某些数据会被处理多次。
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointingMode(CheckpointingMode.AT_LEAST_ONCE);如果一次Checkpoint超过一定时间仍未完成,直接将其终止,以免其占用太多资源:
checkpointConfig.setCheckpointTimeout(3600*1000);如果两次Checkpoint之间的间歇时间太短,那么正常的作业可能获取的资源较少,更多的资源被用在了Checkpoint上。对这个参数进行合理配置能保证数据流的正常处理。比如,设置这个参数为60秒,那么前一次Checkpoint结束后60秒内不会启动新的Checkpoint。这种模式只在整个作业最多允许1个Checkpoint时适用。
checkpointConfig.setMinPauseBetweenCheckpoints(60*1000);默认情况下一个作业只允许1个Checkpoint执行,如果某个Checkpoint正在进行,另外一个Checkpoint被启动,新的Checkpoint需要挂起等待,可以设置最多并行的Checkpoint数量。
env.getCheckpointConfig.setMaxConcurrentCheckpoints(3)如果这个参数大于1,将与前面提到的最短间隔相冲突。
Checkpoint的初衷是用来进行故障恢复,如果作业是因为异常而失败,Flink会保存远程存储上的数据;如果开发者自己取消了作业,远程存储上的数据都会被删除。如果开发者希望通过Checkpoint数据进行调试,自己取消了作业,同时希望将远程数据保存下来,需要设置为:
// 作业取消后仍然保存Checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)RETAIN_ON_CANCELLATION模式下,用户需要自己手动删除远程存储上的Checkpoint数据。
默认情况下,如果Checkpoint过程失败,会导致整个应用重启,我们可以关闭这个功能,这样Checkpoint失败不影响作业的运行。
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)6. 重启恢复流程
Flink的重启恢复逻辑相对比较简单:
- 重启应用,在集群上重新部署数据流图。
- 从持久化存储上读取最近一次的Checkpoint数据,加载到各算子子任务上。
- 继续处理新流入的数据。
这样的机制可以保证Flink内部状态的Excatly-Once一致性。至于端到端的Exactly-Once一致性,要根据Source和Sink的具体实现而定。当发生故障时,一部分数据有可能已经流入系统,但还未进行Checkpoint,Source的Checkpoint记录了输入的Offset;当重启时,Flink能把最近一次的Checkpoint恢复到内存中,并根据Offset,让Source从该位置重新发送一遍数据,以保证数据不丢不重。像Kafka等消息队列是提供重发功能的。