Flink中的状态管理
1 Flink中的状态
当数据流中的许多操作只查看一个每次事件(如事件解析器),一些操作会跨多个事件的信息(如窗口操作)。这些操作称为有状态。状态由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。可以简单的任务状态就是一个本地变量,可以被任务的业务逻辑访问。

有些算子有些任务是没有状态的,如map操作,只跟输入数据有关。像窗口操作不管是增量窗口函数还是全窗口函数都要保持里面的信息的,一开始在窗口到达结束时间之前是不输出数据的,所以最后输出数据的时候,他的计算是要依赖之前的,全窗口可以认为是把所有数据都作为状态保存下来。增量聚合窗口来一个聚合一次要保存的是中间聚合状态。像ProcessFunction可以有状态也可以没有状态。
无状态流处理和有状态流处理的主要区别:无状态流处理分别接收每条输入数据,根据最新输入的数据生成输出数据;有状态流处理会维护状态,根据每条输入记录进行更新,并基于最新输入的记录和当前的状态值生成输出记录,即综合考虑多个事件之后的结果。
需要状态操作的一些例子如下:
- 应用程序搜索某些事件模式时,状态将存储迄今遇到的事件序列。
- 每分钟/小时/天聚合事件时,将状态保存挂起的聚合。
- 在数据流上训练机器学习模型时,状态保存模型参数的当前版本。
- 需要管理历史数据时,状态允许有效访问过去发生的事件。
2 状态类型
每个状态都是当前任务去管理维护,每个状态都是和当前算子关联在一起的,如果需要Flink真正的把他管理起来的话在运行时的时候Flink就必须要知道当前状态定义的类型是什么,所以一开始必须注册对应的状态,要有所谓的描述器。Flink有两种基本的状态:Operator State算子状态和Keyed State键控状态,他们的主要区别就是作用范围不一样,算子状态的作用范围就是限定为算子任务(也就是当前一个分区执行的时候,所有数据来了都能访问到状态)。键控状态中并不是当前分区所有的数据都能访问所有的状态,而是按照keyby之后的key做划分,当前key只能访问自己的状态
2.1 Operator State
每个算子状态绑定到一个并行算子实例,作用范围限定为算子任务,同一并行任务的状态是共享的,并行处理的所有数据都可以访问到相同的状态。Kafka Connector就是使用算子状态的很好的一个例子,Kafka consumer的每个并行实例都维护一个主题分区和偏移,作为算子状态。当并行性发生变化时,算子状态接口支持在并行运算符实例之间重新分配状态。可以有不同的方案来进行这种再分配。
因为同一个并行任务处理的所有数据都可以访问到当前的状态,所以就相当于本地变量
算子状态有3种基本数据结构:①列表状态(List state):状态表示为一组数据的列表②联合列表状态(Union list state):也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。③广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。那就可以访问到别的并行子任务的状态。
算子状态运用的时候可能应用场景没那么多,一般都是keyby之后根据不同的key做分区讨论。如果所有数据来了全部统一处理的话一般还要划分成不同的状态要保存为链表,并行度调整的时候可以根据这个列表拆开,做进一步调整。
联合列表状态与列表状态的区别:主要是并行度调整状态怎样重新分配,列表状态本身分配的时候直接分配;联合列表状态的话就是把所有元素都联合起来,然后由每个任务自己定义最后留下哪些,也就是自己截取要哪一部分。
2.2 Keyed State
Keyed State只能在KeyedStream后使用,键控状态总是相对于键,根据键来维护和访问的
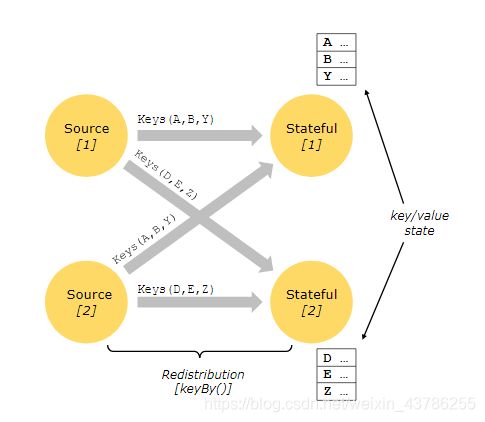
Keyed State很类似于一个分布式的key-value map数据结构,只能用于KeyedStream(keyBy算子处理之后)。键控状态基于每个key去管理,一般keyby进行HashCode重分区后基于它自己独享的内存空间就会针对每一个不同的key分别保存一份独立的存储状态,而且接下来来了一个新的数据只能访问自己的状态,不能访问其他key的,Flink会为每一个key维护一个状态。
Flink的Keyed State支持的数据类型如下:
| 序号 | 类型 | 说明 | 方法 |
|---|---|---|---|
| 1 | ValueState[T] | 用来保存单个的值 | ValueState.update(value: T) ValueState.value() |
| 2 | ListState[T] | 保存一个列表 | ListState.add(value: T) ListState.addAll(values: java.util.List[T]) ListState.update(values: java.util.List[T]) ListState.get()(注意:返回的是Iterable[T]) |
| 3 | MapState[K, V] | 保存Key-Value对 | MapState.get(key: K) MapState.put(key: K, value: V) MapState.contains(key: K) MapState.remove(key: K) |
| 4 | ReducingState[T] | 保留一个值,该值表示添加到状态的所有值的汇总,需要用户提供ReduceFunction | ReducingState.add(value: T) ReducingState.get() |
| 5 | AggregatingState[I, O] | 保留一个值,该值表示添加到状态的所有值的汇总,需要用户提供AggregateFunction | AggregatingState.add(value: T) AggregatingState.get() |
| 6 | FoldingState |
保留一个值,该值表示添加到状态的所有值的汇总,需要用户提供FoldFunction | AggregatingState.add(value: T) AggregatingState.get() |
每个状态都有clear()是清空操作。
在进行状态编程时需要通过RuntimeContext注册StateDescriptor。StateDescriptor以状态state的名字和存储的数据类型为参数。案例如下:
class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] {
private var sum: ValueState[(Long, Long)] = _
override def flatMap(input: (Long, Long), out: Collector[(Long, Long)]): Unit = {
// access the state value
val tmpCurrentSum = sum.value
// If it hasn't been used before, it will be null
val currentSum = if (tmpCurrentSum != null) {
tmpCurrentSum
} else {
(0L, 0L)
}
// update the count
val newSum = (currentSum._1 + 1, currentSum._2 + input._2)
// update the state
sum.update(newSum)
// if the count reaches 2, emit the average and clear the state
if (newSum._1 >= 2) {
out.collect((input._1, newSum._2 / newSum._1))
sum.clear()
}
}
override def open(parameters: Configuration): Unit = {
sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
}
}
object ExampleCountWindowAverage extends App {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.fromCollection(List(
(1L, 3L),
(1L, 5L),
(1L, 7L),
(1L, 4L),
(1L, 2L)
)).keyBy(_._1)
.flatMap(new CountWindowAverage())
.print()
// the printed output will be (1,4) and (1,5)
env.execute("ExampleManagedState")
}
声明状态操作为:
sum = getRuntimeContext.getState(
new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)])
)
读取状态为:
val tmpCurrentSum = sum.value
更新状态为:
sum.update(newSum)
3 状态后端
Flink提供不同的State Backends状态后端,指定如何和在何处存储状态。
(1)MemoryStateBackend
状将键控状态作为内存中的对象进行管理,将它们存储在TaskManager的JVM堆上,将checkpoint存储在JobManager的内存中
(2)FsStateBackend
本地状态存在TaskManager的JVM堆上,checkpoint存到远程的持久化文件系统(FileSystem)上
(3)RocksDBStateBackend
将所有状态序列化后,存入本地的RocksDB中存储。
设置状态后端如下:
val env = StreamExecutionEnvironment.getExecutionEnvironment()
//val checkpointPath: String = checkpoint_Path
//val backend = new RocksDBStateBackend(checkpointPath)
//env.setStateBackend(backend)
env.setStateBackend(new FsStateBackend(YOUR_PATH))
env.enableCheckpointing(1000)
// 配置重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(60, Time.of(10, TimeUnit.SECONDS)))