onnxruntime c++ 代码搜集
1、EfficientDet
EfficientDet.h
#include EfficientDet.cpp
EfficientDetOnnxRT::EfficientDetOnnxRT(std::string onnx_file,unsigned int numClasses) {
Ort::SessionOptions op;
op.SetLogSeverityLevel(ORT_LOGGING_LEVEL_ERROR);
int device_id = 0;
std::cout <<"onnxruntime loading onnx model..." <<std::endl;
#if defined(USE_TENSORRT)
std::cout <<"onnxruntime running with TensorRT..." <<std::endl;
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Tensorrt(op, device_id));
#elif defined(USE_CUDA)
OrtCUDAProviderOptions cuda_options{
0,
OrtCudnnConvAlgoSearch::EXHAUSTIVE,
std::numeric_limits<size_t>::max(),
0,
true
};
Ort::ThrowOnError(op.OrtSessionOptionsAppendExecutionProvider_CUDA(op, &cuda_options));
#endif
session_ = Ort::Session(env_, onnx_file.c_str(), op);
Ort::AllocatorWithDefaultOptions ort_alloc;
char* tmp = session_.GetInputName(0, ort_alloc);
input_names[0] = strdup(tmp);
ort_alloc.Free(tmp);
tmp = session_.GetOutputName(0, ort_alloc);
output_names[0] = strdup(tmp);
ort_alloc.Free(tmp);
tmp = session_.GetOutputName(1, ort_alloc);
output_names[1] = strdup(tmp);
ort_alloc.Free(tmp);
tmp = session_.GetOutputName(2, ort_alloc);
output_names[2] = strdup(tmp);
ort_alloc.Free(tmp);
Ort::TypeInfo info = session_.GetInputTypeInfo(0);
auto tensor_info = info.GetTensorTypeAndShapeInfo();
size_t dim_count = tensor_info.GetDimensionsCount();
std::vector<int64_t> dims(dim_count);
tensor_info.GetDimensions(dims.data(), dims.size());
channels_ = dims[1];
height_ = dims[2];
width_ = dims[3];
input_shape_[0]= dims[0];
input_shape_[1]= channels_;
input_shape_[2]= height_;
input_shape_[3]= width_;
info = session_.GetOutputTypeInfo(0);
auto tensor_info2 = info.GetTensorTypeAndShapeInfo();
dim_count = tensor_info.GetDimensionsCount();
dims.clear();
dims.resize(dim_count);
tensor_info2.GetDimensions(dims.data(), dims.size());
for (int i=0; i< dims.size();i++)
output_shape_regression[i] = dims[i];
info = session_.GetOutputTypeInfo(1);
auto tensor_info3 = info.GetTensorTypeAndShapeInfo();
dim_count = tensor_info3.GetDimensionsCount();
dims.clear();
dims.resize(dim_count);
tensor_info3.GetDimensions(dims.data(), dims.size());
for (int i=0; i< dims.size();i++)
output_shape_classification[i] = dims[i];
numClassScores_ = static_cast<unsigned int>(dims[2]);
output_shape_classification[3] = numClassScores_;
...
info = session_.GetOutputTypeInfo(2);
auto tensor_info4 = info.GetTensorTypeAndShapeInfo();
dim_count = tensor_info4.GetDimensionsCount();
dims.clear();
dims.resize(dim_count);
tensor_info4.GetDimensions(dims.data(), dims.size());
for (int i=0; i< dims.size();i++)
output_shape_anchors[i] = dims[i];
...
int size_anchors = dims[1] * dims[2];
int size_classification = dims[1];
results_regression = new float[size_anchors];
results_classification = new float[size_classification];
results_anchors = new float[size_anchors];
int size_image_data = channels_ * width_ * height_;
input_image_ = new float[size_image_data];
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
input_tensor_ = Ort::Value::CreateTensor<float>(memory_info, input_image_, size_image_data, input_shape_.data(), input_shape_.size());
output_tensor_[0] = Ort::Value::CreateTensor<float>(memory_info, results_regression, size_anchors,
output_shape_regression.data(), output_shape_regression.size());
output_tensor_[1] = Ort::Value::CreateTensor<float>(memory_info, results_classification, size_classification,
output_shape_classification.data(), output_shape_classification.size());
output_tensor_[2] = Ort::Value::CreateTensor<float>(memory_info, results_anchors, size_anchors,
output_shape_anchors.data(), output_shape_anchors.size());
}
...
std::vector<std::vector<float>> EfficientDetOnnxRT::infer(cv::Mat& cv_img, float nms_threshold, float score_threshold ) {
memset(input_image_,0, channels_ * height_ * width_ * sizeof(float));
processInput(input_image_,cv_img);
session_.Run(Ort::RunOptions{nullptr}, &input_names[0], &input_tensor_, 1, &output_names[0], &output_tensor_[0], 3);
return
processOutput(results_regression,results_classification,results_anchors,nms_threshold,score_threshold);
}
...
参考:onnxruntime调用AI模型的python和C++编程
2、squeezenet
// https://github.com/microsoft/onnxruntime/blob/rel-1.6.0/csharp/test/Microsoft.ML.OnnxRuntime.EndToEndTests.Capi/CXX_Api_Sample.cpp
// https://github.com/microsoft/onnxruntime/blob/rel-1.6.0/include/onnxruntime/core/session/onnxruntime_cxx_api.h
#include 参考:https://github.com/leimao/ONNX-Runtime-Inference
3、squeezenet
// Copyright(c) Microsoft Corporation.All rights reserved.
// Licensed under the MIT License.
//
#include >
printf("Number of inputs = %zu\n", num_input_nodes);
// iterate over all input nodes
for (int i = 0; i < num_input_nodes; i++) {
// print input node names
char* input_name = session.GetInputName(i, allocator);
printf("Input %d : name=%s\n", i, input_name);
input_node_names[i] = input_name;
// print input node types
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
printf("Input %d : type=%d\n", i, type);
// print input shapes/dims
input_node_dims = tensor_info.GetShape();
printf("Input %d : num_dims=%zu\n", i, input_node_dims.size());
for (int j = 0; j < input_node_dims.size(); j++)
printf("Input %d : dim %d=%jd\n", i, j, input_node_dims[j]);
}
// Results should be...
// Number of inputs = 1
// Input 0 : name = data_0
// Input 0 : type = 1
// Input 0 : num_dims = 4
// Input 0 : dim 0 = 1
// Input 0 : dim 1 = 3
// Input 0 : dim 2 = 224
// Input 0 : dim 3 = 224
//*************************************************************************
// Similar operations to get output node information.
// Use OrtSessionGetOutputCount(), OrtSessionGetOutputName()
// OrtSessionGetOutputTypeInfo() as shown above.
//*************************************************************************
// Score the model using sample data, and inspect values
size_t input_tensor_size = 224 * 224 * 3; // simplify ... using known dim values to calculate size
// use OrtGetTensorShapeElementCount() to get official size!
std::vector<float> input_tensor_values(input_tensor_size);
std::vector<const char*> output_node_names = {"softmaxout_1"};
// initialize input data with values in [0.0, 1.0]
for (unsigned int i = 0; i < input_tensor_size; i++)
input_tensor_values[i] = (float)i / (input_tensor_size + 1);
// create input tensor object from data values
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
assert(input_tensor.IsTensor());
// score model & input tensor, get back output tensor
auto output_tensors = session.Run(Ort::RunOptions{nullptr}, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
// Get pointer to output tensor float values
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
assert(abs(floatarr[0] - 0.000045) < 1e-6);
// score the model, and print scores for first 5 classes
for (int i = 0; i < 5; i++)
printf("Score for class [%d] = %f\n", i, floatarr[i]);
// Results should be as below...
// Score for class[0] = 0.000045
// Score for class[1] = 0.003846
// Score for class[2] = 0.000125
// Score for class[3] = 0.001180
// Score for class[4] = 0.001317
printf("Done!\n");
return 0;
}
/*
Copyright (C) 2021, Intel Corporation
SPDX-License-Identifier: Apache-2.0
Portions of this software are copyright of their respective authors and released under the MIT license:
- ONNX-Runtime-Inference, Copyright 2020 Lei Mao. For licensing see https://github.com/leimao/ONNX-Runtime-Inference/blob/main/LICENSE.md
*/
#include " << std::endl;
std::cout << "\n To Run using OpenVINO EP.\nExample: ./run_squeezenet --use_openvino squeezenet1.1-7.onnx demo.jpeg synset.txt \n" << std::endl;
std::cout << "\n To Run on Default CPU.\n Example: ./run_squeezenet --use_cpu squeezenet1.1-7.onnx demo.jpeg synset.txt \n" << std::endl;
}
int main(int argc, char* argv[])
{
bool useOPENVINO{true};
const char* useOPENVINOFlag = "--use_openvino";
const char* useCPUFlag = "--use_cpu";
if(argc == 2) {
std::string option = argv[1];
if (option == "--help" || option == "-help" || option == "--h" || option == "-h") {
printHelp();
}
return 0;
} else if(argc != 5) {
std::cout << "[ ERROR ] you have used the wrong command to run your program." << std::endl;
printHelp();
return 0;
} else if (strcmp(argv[1], useOPENVINOFlag) == 0) {
useOPENVINO = true;
} else if (strcmp(argv[1], useCPUFlag) == 0) {
useOPENVINO = false;
}
if (useOPENVINO)
{
std::cout << "Inference Execution Provider: OPENVINO" << std::endl;
}
else
{
std::cout << "Inference Execution Provider: CPU" << std::endl;
}
std::string instanceName{"image-classification-inference"};
std::string modelFilepath = argv[2]; // .onnx file
//validate ModelFilePath
checkModelExtension(modelFilepath);
if(!checkModelExtension(modelFilepath)) {
throw std::runtime_error("[ ERROR ] The ModelFilepath is not correct. Make sure you are setting the path to an onnx model file (.onnx)");
}
std::string imageFilepath = argv[3];
// Validate ImageFilePath
imageFileExtension(imageFilepath);
if(!imageFileExtension(imageFilepath)) {
throw std::runtime_error("[ ERROR ] The imageFilepath doesn't have correct image extension. Choose from jpeg, jpg, gif, png, PNG, jfif");
}
std::ifstream f(imageFilepath.c_str());
if(!f.good()) {
throw std::runtime_error("[ ERROR ] The imageFilepath is not set correctly or doesn't exist");
}
// Validate LabelFilePath
std::string labelFilepath = argv[4];
if(!checkLabelFileExtension(labelFilepath)) {
throw std::runtime_error("[ ERROR ] The LabelFilepath is not set correctly and the labels file should end with extension .txt");
}
std::vector<std::string> labels{readLabels(labelFilepath)};
Ort::Env env(OrtLoggingLevel::ORT_LOGGING_LEVEL_WARNING,
instanceName.c_str());
Ort::SessionOptions sessionOptions;
sessionOptions.SetIntraOpNumThreads(1);
//Appending OpenVINO Execution Provider API
if (useOPENVINO) {
// Using OPENVINO backend
OrtOpenVINOProviderOptions options;
options.device_type = "CPU_FP32"; //Other options are: GPU_FP32, GPU_FP16, MYRIAD_FP16
std::cout << "OpenVINO device type is set to: " << options.device_type << std::endl;
sessionOptions.AppendExecutionProvider_OpenVINO(options);
}
// Sets graph optimization level
// Available levels are
// ORT_DISABLE_ALL -> To disable all optimizations
// ORT_ENABLE_BASIC -> To enable basic optimizations (Such as redundant node
// removals) ORT_ENABLE_EXTENDED -> To enable extended optimizations
// (Includes level 1 + more complex optimizations like node fusions)
// ORT_ENABLE_ALL -> To Enable All possible optimizations
sessionOptions.SetGraphOptimizationLevel(
GraphOptimizationLevel::ORT_DISABLE_ALL);
//Creation: The Ort::Session is created here
Ort::Session session(env, modelFilepath.c_str(), sessionOptions);
Ort::AllocatorWithDefaultOptions allocator;
size_t numInputNodes = session.GetInputCount();
size_t numOutputNodes = session.GetOutputCount();
std::cout << "Number of Input Nodes: " << numInputNodes << std::endl;
std::cout << "Number of Output Nodes: " << numOutputNodes << std::endl;
const char* inputName = session.GetInputName(0, allocator);
std::cout << "Input Name: " << inputName << std::endl;
Ort::TypeInfo inputTypeInfo = session.GetInputTypeInfo(0);
auto inputTensorInfo = inputTypeInfo.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType inputType = inputTensorInfo.GetElementType();
std::cout << "Input Type: " << inputType << std::endl;
std::vector<int64_t> inputDims = inputTensorInfo.GetShape();
std::cout << "Input Dimensions: " << inputDims << std::endl;
const char* outputName = session.GetOutputName(0, allocator);
std::cout << "Output Name: " << outputName << std::endl;
Ort::TypeInfo outputTypeInfo = session.GetOutputTypeInfo(0);
auto outputTensorInfo = outputTypeInfo.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType outputType = outputTensorInfo.GetElementType();
std::cout << "Output Type: " << outputType << std::endl;
std::vector<int64_t> outputDims = outputTensorInfo.GetShape();
std::cout << "Output Dimensions: " << outputDims << std::endl;
//pre-processing the Image
// step 1: Read an image in HWC BGR UINT8 format.
cv::Mat imageBGR = cv::imread(imageFilepath, cv::ImreadModes::IMREAD_COLOR);
// step 2: Resize the image.
cv::Mat resizedImageBGR, resizedImageRGB, resizedImage, preprocessedImage;
cv::resize(imageBGR, resizedImageBGR,
cv::Size(inputDims.at(2), inputDims.at(3)),
cv::InterpolationFlags::INTER_CUBIC);
// step 3: Convert the image to HWC RGB UINT8 format.
cv::cvtColor(resizedImageBGR, resizedImageRGB,
cv::ColorConversionCodes::COLOR_BGR2RGB);
// step 4: Convert the image to HWC RGB float format by dividing each pixel by 255.
resizedImageRGB.convertTo(resizedImage, CV_32F, 1.0 / 255);
// step 5: Split the RGB channels from the image.
cv::Mat channels[3];
cv::split(resizedImage, channels);
//step 6: Normalize each channel.
// Normalization per channel
// Normalization parameters obtained from
// https://github.com/onnx/models/tree/master/vision/classification/squeezenet
channels[0] = (channels[0] - 0.485) / 0.229;
channels[1] = (channels[1] - 0.456) / 0.224;
channels[2] = (channels[2] - 0.406) / 0.225;
//step 7: Merge the RGB channels back to the image.
cv::merge(channels, 3, resizedImage);
// step 8: Convert the image to CHW RGB float format.
// HWC to CHW
cv::dnn::blobFromImage(resizedImage, preprocessedImage);
//Run Inference
/* To run inference using ONNX Runtime, the user is responsible for creating and managing the
input and output buffers. These buffers could be created and managed via std::vector.
The linear-format input data should be copied to the buffer for ONNX Runtime inference. */
size_t inputTensorSize = vectorProduct(inputDims);
std::vector<float> inputTensorValues(inputTensorSize);
inputTensorValues.assign(preprocessedImage.begin<float>(),
preprocessedImage.end<float>());
size_t outputTensorSize = vectorProduct(outputDims);
assert(("Output tensor size should equal to the label set size.",
labels.size() == outputTensorSize));
std::vector<float> outputTensorValues(outputTensorSize);
/* Once the buffers were created, they would be used for creating instances of Ort::Value
which is the tensor format for ONNX Runtime. There could be multiple inputs for a neural network,
so we have to prepare an array of Ort::Value instances for inputs and outputs respectively even if
we only have one input and one output. */
std::vector<const char*> inputNames{inputName};
std::vector<const char*> outputNames{outputName};
std::vector<Ort::Value> inputTensors;
std::vector<Ort::Value> outputTensors;
/*
Creating ONNX Runtime inference sessions, querying input and output names,
dimensions, and types are trivial.
Setup inputs & outputs: The input & output tensors are created here. */
Ort::MemoryInfo memoryInfo = Ort::MemoryInfo::CreateCpu(
OrtAllocatorType::OrtArenaAllocator, OrtMemType::OrtMemTypeDefault);
inputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, inputTensorValues.data(), inputTensorSize, inputDims.data(),
inputDims.size()));
outputTensors.push_back(Ort::Value::CreateTensor<float>(
memoryInfo, outputTensorValues.data(), outputTensorSize,
outputDims.data(), outputDims.size()));
/* To run inference, we provide the run options, an array of input names corresponding to the
inputs in the input tensor, an array of input tensor, number of inputs, an array of output names
corresponding to the the outputs in the output tensor, an array of output tensor, number of outputs. */
session.Run(Ort::RunOptions{nullptr}, inputNames.data(),
inputTensors.data(), 1, outputNames.data(),
outputTensors.data(), 1);
int predId = 0;
float activation = 0;
float maxActivation = std::numeric_limits<float>::lowest();
float expSum = 0;
/* The inference result could be found in the buffer for the output tensors,
which are usually the buffer from std::vector instances. */
for (int i = 0; i < labels.size(); i++) {
activation = outputTensorValues.at(i);
expSum += std::exp(activation);
if (activation > maxActivation)
{
predId = i;
maxActivation = activation;
}
}
std::cout << "Predicted Label ID: " << predId << std::endl;
std::cout << "Predicted Label: " << labels.at(predId) << std::endl;
float result;
try {
result = division(std::exp(maxActivation), expSum);
std::cout << "Uncalibrated Confidence: " << result << std::endl;
}
catch (std::runtime_error& e) {
std::cout << "Exception occurred" << std::endl << e.what();
}
// Measure latency
int numTests{100};
std::chrono::steady_clock::time_point begin =
std::chrono::steady_clock::now();
//Run: Running the session is done in the Run() method:
for (int i = 0; i < numTests; i++) {
session.Run(Ort::RunOptions{nullptr}, inputNames.data(),
inputTensors.data(), 1, outputNames.data(),
outputTensors.data(), 1);
}
std::chrono::steady_clock::time_point end =
std::chrono::steady_clock::now();
std::cout << "Minimum Inference Latency: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - begin).count() / static_cast<float>(numTests)
<< " ms" << std::endl;
return 0;
}
参考:microsoft/onnxruntime
4、squeezenet
#include 参考:madara-tribe/cpp_sample_onnx_inference
5、resnet101
#include results_{};
cv::Mat results_ = cv::Mat::zeros(height_, width_, CV_32F);
#ifdef _WIN32
//const wchar_t* model_path = L"4channels384_640.onnx";
//const wchar_t* model_path = L"D:/pengt/code/Cplus/onnx_model/resnet101_21_384x640.onnx";
const wchar_t* model_path = L"D:/pengt/code/Cplus/onnx_model/resnet101_21_480x640.onnx";
#else
const char* model_path = "4channels384_640.onnx";
#endif
#define USE_CUDA
class ONNX_Model
{
public:
#ifdef _WIN32
ONNX_Model(const wchar_t* model_path)
: m_env{ ORT_LOGGING_LEVEL_ERROR, "" },
m_session{ nullptr },
m_sess_opts{},
m_mem_info{ Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault) }
#else
ONNX_Model(char* model_path)
#endif
{
//option
/* if (true)
m_sess_opts.EnableCpuMemArena();
else
m_sess_opts.DisableCpuMemArena();*/
//end
/*
// DirectML
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_DML(m_sess_opts, 0));
m_sess_opts.DisableMemPattern();
m_sess_opts.SetExecutionMode(ExecutionMode::ORT_SEQUENTIAL);
m_session = Ort::Session(m_env, model_path, m_sess_opts);
*/
// CPU
// Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_CPU(m_sess_opts, 0));
// m_sess_opts.EnableMemPattern();
// m_sess_opts.SetIntraOpNumThreads(8);
//m_sess_opts.SetExecutionMode(ExecutionMode::ORT_SEQUENTIAL);
// m_sess_opts.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// m_session = Ort::Session(m_env, model_path, m_sess_opts);
//tensorrt
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Tensorrt(m_sess_opts,0));
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_CUDA(m_sess_opts, 0));
//m_sess_opts.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_DISABLE_ALL);
m_sess_opts.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
//m_sess_opts.SetOptimizedModelFilePath(out_optimize_path); //save optimize
m_session = Ort::Session(m_env, model_path, m_sess_opts);
//m_session = Ort::Session(m_env, out_optimize_path, m_sess_opts);
//end tensorrt
// CUDA
//Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_CUDA(m_sess_opts, 0));
//m_sess_opts.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_EXTENDED);
//m_session = Ort::Session(m_env, model_path, m_sess_opts);
//
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
input_tensor_ = Ort::Value::CreateTensor<float>(memory_info, input_image_.data(), input_image_.size(), input_shape_.data(), input_shape_.size());
//output_tensor_ = Ort::Value::CreateTensor(memory_info, results_.data(), results_.size(), output_shape_.data(), output_shape_.size());
output_tensor_ = Ort::Value::CreateTensor<float>(memory_info, (float*)results_.data, height_ * width_, output_shape_.data(), output_shape_.size());
}
void Run()
{
m_session.Run(Ort::RunOptions{ nullptr }, input_names.data(), &input_tensor_, 1, output_names.data(), &output_tensor_, 1);
return;
}
std::vector<int64_t> get_input_shape_from_session()
{
Ort::TypeInfo info = m_session.GetInputTypeInfo(0);
auto tensor_info = info.GetTensorTypeAndShapeInfo();
size_t dim_count = tensor_info.GetDimensionsCount();
std::vector<int64_t> dims(dim_count);
tensor_info.GetDimensions(dims.data(), dims.size());
return dims;
}
private:
Ort::Env m_env;
Ort::Session m_session;
Ort::SessionOptions m_sess_opts;
Ort::MemoryInfo m_mem_info;
//std::vector input_names{ "0" };
//std::vector output_names{ "293" }; //Unet
std::vector<const char*> input_names{ "input.1" };
std::vector<const char*> output_names{ "1207" }; //resnet101
//std::vector input_names{ "input.1" };
//std::vector output_names{ "1683" }; //resnet152
Ort::Value input_tensor_{ nullptr };
std::array<int64_t, 4> input_shape_{ 1, channel, height_,width_ };
Ort::Value output_tensor_{ nullptr };
std::array<int64_t, 4> output_shape_{ 1, 1, height_,width_ };
};
// data need
//rgbm = rgbm / 255.
//mean = [0.485, 0.456, 0.406, 0]
//std = [0.229, 0.224, 0.225, 1]
//rgbm = rgbm - mean
//rgbm = rgbm / std
//x.transpose(2, 0, 1).astype('float32')
#if 0
void fill_data(cv::Mat input_img, cv::Mat pre_mask, float* output, const int index = 0)
{
cv::Mat dst_img;
cv::Mat dst_pre;
cv::Scalar mean = cv::Scalar(0.485, 0.456, 0.406);
cv::Scalar std = cv::Scalar(0.229, 0.224, 0.225);
float scale = 0.00392;
//cv::Scalar mean_ = cv::Scalar(109.125, 102.6, 91.35);
//cv::Scalar std_ = cv::Scalar(0.0171, 0.01884, 0.01975);
//if (images.depth() == CV_8U && ddepth == CV_32F)
// images.convertTo(images[i], CV_32F);
//std::swap(mean[0], mean[2]);
input_img.convertTo(dst_img, CV_32F, scale);
pre_mask.convertTo(dst_pre, CV_32F, scale);
dst_img -= mean;
dst_img /= std;
//dst_img -= mean_;
//dst_img *= std_;
//std::vector channels;
//split(input_img, channels);//²ð·Ö
//channels.push_back(pre_mask);
//cv::convertTo(img_float, CV_32F, 1.0 / 255);
int row = dst_img.rows;
int col = dst_img.cols;
//cv::Scalar rgb_mean = cv::mean(dst);
//std::cout<< (dst_img.ptr(0, 214)[0]) <
for (int c = 0; c < 3; c++) {
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
//output[c * row * col + i * col + j] = (dst_img.ptr(i)[j * 3 + c]);
//std::cout << "i and j :"<(i,j)[c]) << std::endl;
output[c * row * col + i * col + j] = (dst_img.ptr<float>(i, j)[c]);
}
}
}
if (index % 20 == 0)
{
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
//output[4 * row * col + i * col + j] = (dst_pre.ptr(i)[j]);
output[3 * row * col + i * col + j] = (dst_pre.ptr<float>(i, j)[0]);
}
}
}
return;
}
#else
void fill_data(cv::Mat input_img, cv::Mat pre_mask, float* output, const int index = 0)
{
float mean[3] = { 123.675, 116.28, 103.53 };
float std[3] = { 0.0171, 0.0175, 0.0174 };
float allmul[3] = { 2.1145,2.0349,1.8014 };
float scale = 1;
float* dst_pre = pre_mask.ptr<float>(0, 0);
int row = input_img.rows;
int col = input_img.cols;
int alllen = row * col;
//double timeStart = (double)cv::getTickCount();
//HWC -> CHW
float* inbuf = output;
for (int c = 0; c < 3; c++) {
uchar* img_data = input_img.data;
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
*inbuf = img_data[c] * std[c] - allmul[c];//(dst_img.ptr(i, j)[c]);
img_data += 3;
inbuf++;
}
}
}
//double circle = ((double)cv::getTickCount() - timeStart) / cv::getTickFrequency();
//std::cout << "circle time :" << circle << " sec";
memcpy(inbuf, dst_pre, sizeof(float) * alllen);
return;
}
#endif
using namespace cv;
std::vector<Vec3b> colors;
void colorizeSegmentation(const Mat& score, Mat& segm)
{
const int rows = score.size[2];
const int cols = score.size[3];
const int chns = score.size[1];
if (colors.empty()) {
// Generate colors.
colors.push_back(Vec3b());
for (int i = 1; i < chns; ++i) {
Vec3b color;
for (int j = 0; j < 3; ++j)
color[j] = (colors[i - 1][j] + rand() % 256) / 2;
colors.push_back(color);
}
}
else if (chns != (int)colors.size()) {
CV_Error(Error::StsError, format("Number of output classes does not match "
"number of colors (%d != %zu)", chns, colors.size()));
}
Mat maxCl = Mat::zeros(rows, cols, CV_8UC1);
Mat maxVal(rows, cols, CV_32FC1, score.data);
for (int ch = 1; ch < chns; ch++) {
for (int row = 0; row < rows; row++) {
const float* ptrScore = score.ptr<float>(0, ch, row);
uint8_t* ptrMaxCl = maxCl.ptr<uint8_t>(row);
float* ptrMaxVal = maxVal.ptr<float>(row);
for (int col = 0; col < cols; col++) {
if (ptrScore[col] > ptrMaxVal[col]) {
ptrMaxVal[col] = ptrScore[col];
ptrMaxCl[col] = (uchar)ch;
}
}
}
}
segm.create(rows, cols, CV_8UC3);
for (int row = 0; row < rows; row++) {
const uchar* ptrMaxCl = maxCl.ptr<uchar>(row);
Vec3b* ptrSegm = segm.ptr<Vec3b>(row);
for (int col = 0; col < cols; col++) {
ptrSegm[col] = colors[ptrMaxCl[col]];
}
}
}
// 背景, 前景, mask
cv::Mat replace_and_blend(cv::Mat bkimg, cv::Mat& frame, cv::Mat& mask)
{
cv::Mat result = cv::Mat::zeros(frame.size(), frame.type());
int h = frame.rows;
int w = frame.cols;
int m = 0;
double wt = 0;
int b = 0, g = 0, r = 0;
int b1 = 0, g1 = 0, r1 = 0;
int b2 = 0, g2 = 0, r2 = 0;
for (int row = 0; row < h; row++)
{
uchar* current = frame.ptr<uchar>(row);
uchar* bgrow = bkimg.ptr<uchar>(row);
uchar* maskrow = mask.ptr<uchar>(row);
uchar* targetrow = result.ptr<uchar>(row);
for (int col = 0; col < w; col++)
{
m = *maskrow++;
if (m == 0) //如果是背景 替换为背景数据
{
*targetrow++ = *bgrow++;
*targetrow++ = *bgrow++;
*targetrow++ = *bgrow++;
current += 3;
}
else if (m == 255) //如果是前景 保留原来数据
{
*targetrow++ = *current++;
*targetrow++ = *current++;
*targetrow++ = *current++;
bgrow += 3;
}
else //由于形态学平滑造成的过渡区 颜色采用加权均衡化
{
b1 = *bgrow++;
g1 = *bgrow++;
r1 = *bgrow++;
b2 = *current++;
g2 = *current++;
r2 = *current++;
wt = m / 255.0;
b = b2 * wt + b1 * (1 - wt);
g = g2 * wt + g1 * (1 - wt);
r = b2 * wt + r1 * (1 - wt);
*targetrow++ = b;
*targetrow++ = g;
*targetrow++ = r;
}
}
}
return result; //返回结果
}
#if 0
int main(void)
{
ONNX_Model model;
std::vector<int64_t> dims = model.get_input_shape_from_session();
std::cout << "Input Shape: (";
std::cout << dims[0] << ", " << dims[1] << ", " << dims[2] << ", " << dims[3] << ")" << std::endl;
int inputwidth = 640;
int inputheight = 384;
cv::Mat pre_mask = cv::Mat::zeros(inputheight, inputwidth, CV_8UC1); //height width
cv::Mat frame, image0;
frame = cv::imread("D:/pengt/segmetation/test_pic/1.png");
cv::resize(frame, frame, cv::Size(inputwidth, inputheight)); //width height
cv::cvtColor(frame, image0, cv::COLOR_BGR2RGB);
double timeStart = (double)cv::getTickCount();
float* output = input_image_.data();
std::fill(input_image_.begin(), input_image_.end(), 0.f);
fill_data(image0, pre_mask, output);
model.Run();
double nTime = ((double)cv::getTickCount() - timeStart) / cv::getTickFrequency();
std::cout << "running time £º" << nTime << "sec\n" << std::endl;
cv::Mat segm;
//colorizeSegmentation(results_, segm);
cv::threshold(results_, segm, 0.5, 200, cv::THRESH_BINARY);
cv::imshow("mask", segm);
cv::imshow("pre_image", frame);
cv::waitKey(0);
return 0;
}
#else
int main(void)
{
ONNX_Model model(model_path);
std::vector<int64_t> dims = model.get_input_shape_from_session();
std::cout << "Input Shape: (";
std::cout << dims[0] << ", " << dims[1] << ", " << dims[2] << ", " << dims[3] << ")" << std::endl;
int inputwidth = width_;
int inputheight = height_;
cv::Mat pre_mask = cv::Mat::zeros(height_, width_, CV_32F);//cv::Mat::zeros(inputheight, inputwidth, CV_8UC1); //height width
cv::Mat frame, image0;
cv::Mat backimg = cv::imread("0.jpg");
cv::resize(backimg, backimg, cv::Size(inputwidth, inputheight));
cv::VideoCapture capture(0);
capture.set(cv::CAP_PROP_FRAME_WIDTH, 640);
capture.set(cv::CAP_PROP_FRAME_HEIGHT, 360);
int index = 0;
/// object_rect res_area;
//需顺时针90°旋转时,transpose(src, tmp) + flip(tmp, dst, 1)
//需逆时针90°旋转时,transpose(src, tmp) + flip(tmp, dst, 0)
while (true)
{
index += 1;
capture >> frame;
//cv::transpose(frame, rotef);
//cv::Mat rodst;
//cv::rotate(frame, rodst, 0); //顺时针90
//cv::rotate(frame, rodst, 2); //顺时针270
cv::Mat sizeFrame;
double timeStart = (double)cv::getTickCount();
//resize_uniform(frame, sizeFrame, cv::Size(inputwidth, inputheight), res_area);
cv::resize(frame, sizeFrame, cv::Size(inputwidth, inputheight)); //width height
cv::cvtColor(sizeFrame, image0, cv::COLOR_BGR2RGB);
float* output = input_image_.data();
// std::fill(input_image_.begin(), input_image_.end(), 0.f); // 暂时去掉
fill_data(image0, pre_mask, output, index);
double midpredict = (double)cv::getTickCount();
double postTime = (midpredict - timeStart) / cv::getTickFrequency();
std::cout << " running time post time :" << postTime << "sec";
model.Run();
double stpreTime = (double)cv::getTickCount();
double preTime = (stpreTime - midpredict) / cv::getTickFrequency();
std::cout << " predict time :" << preTime << "sec";
cv::Mat segm;
const int inputMaskValue = 1;
cv::threshold(results_, segm, 0.5, 1, cv::THRESH_BINARY);
contour
// cv::Mat binary = segm * 255;
// //cv::threshold(segm * 255, binary, 127, 255, cv::THRESH_BINARY);
// cv::Mat ubinary;
// binary.convertTo(ubinary, CV_8U);
///* cv::Canny(ubinary, ubinary, 60, 255,3); //可以修改canny替换所有
// cv::imshow("canny", ubinary);*/
// std::vector> contours;
// std::vector hierarchy;
// cv::findContours(ubinary, contours, hierarchy, cv::RETR_TREE, cv::CHAIN_APPROX_SIMPLE, cv::Point());
// cv::Mat imageContours = cv::Mat::zeros(ubinary.size(), CV_8UC1);
// for (int i = 0; i < contours.size(); i++)
// {
// cv::drawContours(imageContours, contours, i, cv::Scalar(255), 1, 8, hierarchy);
// }
// double preTime = ((double)cv::getTickCount() - midpredict) / cv::getTickFrequency();
//std::cout << "predict time :" << preTime << "sec\n" << std::endl;
//cv::imshow("edge", imageContours);
///
segm.copyTo(pre_mask);
pre_mask = 0.7 * pre_mask;
cv::Mat ucharSegem;
segm = segm * 255;
segm.convertTo(ucharSegem, CV_8U);
///
//图形学处理 平滑mask;
cv::Mat kernel = cv::getStructuringElement(cv::MORPH_RECT, cv::Size(3, 3));
cv::Mat dstmask;
cv::morphologyEx(ucharSegem, dstmask, cv::MORPH_OPEN, kernel);
//cv::imshow("mask1", dstmask);
//高斯处理 边缘更平滑 效果更好看
cv::GaussianBlur(dstmask, dstmask, cv::Size(3, 3), 0, 0);
//cv::imshow("mask2", dstmask);
cv::Mat dst = replace_and_blend(backimg, sizeFrame, dstmask);
//Mat resultdst;
//crop_effect_area(dst, resultdst, frame.size(), res_area);
double lastTime = ((double)cv::getTickCount() - stpreTime) / cv::getTickFrequency();
std::cout << " last prcess time :" << lastTime << "sec\n" << std::endl;
cv::imshow("mask", ucharSegem);
// cv::imshow("resultdst", resultdst);
cv::imshow("dst", dst);
//cv::Mat dst = cv::addWeighted(img1, 0.7, img2, 0.3, 0);
//cv::imshow("mask", segm);
//crop_effect_area(Mat & uniform_scaled, Mat & dst, Size ori_size, object_rect effect_area);
//cv::imshow("pre_image", frame);
cv::waitKey(1);
}
return 0;
}
#endif
参考:ptklx/onnxruntime_segment
6、CenterNet_onnxruntime
#include 参考:ZeroE04/CenterNet_onnxruntime
7、语义分割模型
ONNXRuntime写代码十分简洁
大概分为三部分
- 1.初始化环境,会话等
- 2.会话中加载模型,得到模型的输入和输出节点
- 3.调用API得到模型的返回值
这里以语义分割模型U2Net为例
#include >
printf("Number of inputs = %zu\n", num_input_nodes);
//迭代所有的输入节点
for (int i = 0; i < num_input_nodes; i++) {
//输出输入节点的名称
char* input_name = session.GetInputName(i, allocator);
printf("Input %d : name=%s\n", i, input_name);
input_node_names[i] = input_name;
// 输出输入节点的类型
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
printf("Input %d : type=%d\n", i, type);
input_node_dims = tensor_info.GetShape();
//输入节点的打印维度
printf("Input %d : num_dims=%zu\n", i, input_node_dims.size());
//打印各个维度的大小
for (int j = 0; j < input_node_dims.size(); j++)
printf("Input %d : dim %d=%jd\n", i, j, input_node_dims[j]);
//batch_size=1
input_node_dims[0] = 1;
}
//打印输出节点信息,方法类似
for (int i = 0; i < num_output_nodes; i++)
{
char* output_name = session.GetOutputName(i, allocator);
printf("Output: %d name=%s\n", i, output_name);
output_node_names[i] = output_name;
Ort::TypeInfo type_info = session.GetOutputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
printf("Output %d : type=%d\n", i, type);
auto output_node_dims = tensor_info.GetShape();
printf("Output %d : num_dims=%zu\n", i, output_node_dims.size());
for (int j = 0; j < input_node_dims.size(); j++)
printf("Output %d : dim %d=%jd\n", i, j, output_node_dims[j]);
}
//*************************************************************************
// 使用样本数据对模型进行评分,并检验出入值的合法性
size_t input_tensor_size = 3 * 320 * 320; // simplify ... using known dim values to calculate size
// use OrtGetTensorShapeElementCount() to get official size!
std::vector<float> input_tensor_values(input_tensor_size);
// 初始化一个数据(演示用,这里实际应该传入归一化的数据)
for (unsigned int i = 0; i < input_tensor_size; i++)
input_tensor_values[i] = (float)i / (input_tensor_size + 1);
// 为输入数据创建一个Tensor对象
try
{
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
//assert(input_tensor.IsTensor());
// 推理得到结果
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
// Get pointer to output tensor float values
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
printf("Number of outputs = %d\n", output_tensors.size());
}
catch (Ort::Exception& e)
{
printf(e.what());
}
auto end_time = clock();
printf("Proceed exit after %.2f seconds\n", static_cast<float>(end_time - start_time) / CLOCKS_PER_SEC);
printf("Done!\n");
return 0;
}
输出:
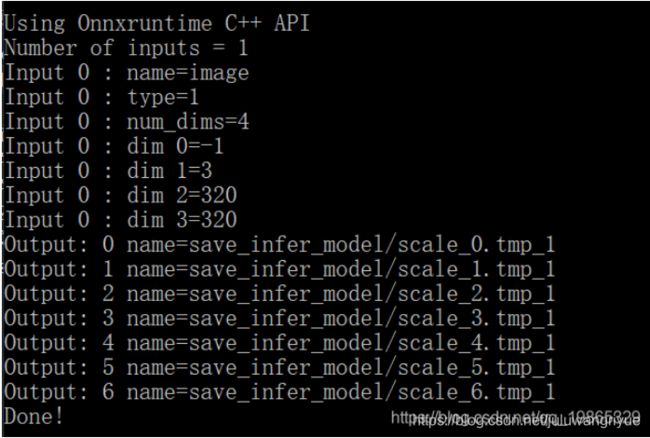
然后我们进一步进行一定程度的封装,方便我们后续使用
class U2NetModel
{
public:
U2NetModel(const wchar_t* onnx_model_path);
float* predict(std::vector<float>input_data,int batch_size=1);
private:
Ort::Env env;
Ort::Session session;
Ort::AllocatorWithDefaultOptions allocator;
std::vector<const char*>input_node_names;
std::vector<const char*>output_node_names;
std::vector<int64_t> input_node_dims;
};
U2NetModel::U2NetModel(const wchar_t* onnx_model_path):session(nullptr),env(nullptr)
{
//初始化环境,每个进程一个环境,环境保留了线程池和其他状态信息
this->env=Ort::Env(ORT_LOGGING_LEVEL_WARNING, "u2net");
//初始化Session选项
Ort::SessionOptions session_options;
session_options.SetInterOpNumThreads(1);
session_options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
// 创建Session并把模型加载到内存中
this->session=Ort::Session(env, onnx_model_path,session_options);
//输入输出节点数量和名称
size_t num_input_nodes = session.GetInputCount();
size_t num_output_nodes = session.GetOutputCount();
for (int i = 0; i < num_input_nodes; i++)
{
auto input_node_name = session.GetInputName(i, allocator);
this->input_node_names.push_back(input_node_name);
Ort::TypeInfo type_info = session.GetInputTypeInfo(i);
auto tensor_info = type_info.GetTensorTypeAndShapeInfo();
ONNXTensorElementDataType type = tensor_info.GetElementType();
this->input_node_dims = tensor_info.GetShape();
}
for (int i = 0; i < num_output_nodes; i++)
{
auto output_node_name = session.GetOutputName(i, allocator);
this->output_node_names.push_back(output_node_name);
}
}
float* U2NetModel::predict(std::vector<float>input_tensor_values,int batch_size)
{
this->input_node_dims[0] = batch_size;
auto input_tensor_size = input_tensor_values.size();
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
float* floatarr = output_tensors.front().GetTensorMutableData<float>();
return floatarr;
}
然后初始化一个示例并调用接口
int main(int argc, char* argv[])
{
auto start_time = std::clock();
U2NetModel u2net(L"u2net.onnx");
size_t input_tensor_size = 3 * 320 * 320;
std::vector<float> input_tensor_values(input_tensor_size);
//初始化一个数据(演示用)
for (unsigned int i = 0; i < input_tensor_size; i++)
{
input_tensor_values[i] = (float)i / (input_tensor_size + 1);
}
float* results = nullptr;
try
{
results = u2net.predict(input_tensor_values);
}
catch (Ort::Exception& e)
{
delete results;
printf("%s\n", e.what());
}
auto end_time = std::clock();
printf("Proceed exits after %.2f seconds", static_cast<float>(end_time - start_time) / 1000);
printf("Done!\n");
return 0;
}
现在模型部分结束了,但问题是我们其实并没法得知我们的模型运行情况
所以我们还需要读入图片和显示图片,也就是
1.读入一张图片
2.模型推理
3.屏幕打印图片
借助OpenCV进行模型推理
首先是重载一个新的predict函数来支持cv::Mat数据
当然这里我新写的版本已经不直接返回float*,而是std::vector
class U2NetModel
{
public:
...
std::vector<float> predict(std::vector<float>& input_data,int batch_size=1,int index=0);
cv::Mat predict(cv::Mat& input_tensor, int batch_size = 1, int index = 0);
...
}
代码实现,增加了对于cv::Mat的处理:
std::vector<float> U2NetModel::predict(std::vector<float>& input_tensor_values,int batch_size,int index)
{
this->input_node_dims[0] = batch_size;
this->output_node_dims[0] = batch_size;
float* floatarr = nullptr;
try
{
std::vector<const char*>output_node_names;
if (index != -1)
{
output_node_names = { this->output_node_names[index] };
}
else
{
output_node_names = this->output_node_names;
}
this->input_node_dims[0] = batch_size;
auto input_tensor_size = input_tensor_values.size();
auto memory_info = Ort::MemoryInfo::CreateCpu(OrtArenaAllocator, OrtMemTypeDefault);
Ort::Value input_tensor = Ort::Value::CreateTensor<float>(memory_info, input_tensor_values.data(), input_tensor_size, input_node_dims.data(), 4);
auto output_tensors = session.Run(Ort::RunOptions{ nullptr }, input_node_names.data(), &input_tensor, 1, output_node_names.data(), 1);
assert(output_tensors.size() == 1 && output_tensors.front().IsTensor());
floatarr = output_tensors.front().GetTensorMutableData<float>();
}
catch (Ort::Exception&e)
{
throw e;
}
int64_t output_tensor_size = 1;
for (auto& it : this->output_node_dims)
{
output_tensor_size *= it;
}
std::vector<float>results(output_tensor_size);
for (unsigned i = 0;i < output_tensor_size; i++)
{
results[i] = floatarr[i];
}
return results;
}
cv::Mat U2NetModel::predict(cv::Mat& input_tensor, int batch_size, int index)
{
int input_tensor_size = input_tensor.cols * input_tensor.rows * 3;
std::size_t counter = 0;//std::vector空间一次性分配完成,避免过多的数据copy
std::vector<float>input_data(input_tensor_size);
std::vector<float>output_data;
try
{
for (unsigned k = 0; k < 3; k++)
{
for (unsigned i = 0; i < input_tensor.rows; i++)
{
for (unsigned j = 0; j < input_tensor.cols; j++)
{
input_data[counter++]=static_cast<float>(input_tensor.at<cv::Vec3b>(i, j)[k]) / 255.0;
}
}
}
}
catch (cv::Exception& e)
{
printf(e.what());
}
try
{
output_data = this->predict(input_data);
}
catch (Ort::Exception& e)
{
throw e;
}
cv::Mat output_tensor(output_data);
output_tensor=output_tensor.reshape(1, { 320,320 })*255.0;
std::cout << output_tensor.rows << " " << output_tensor.cols << "fuck" << std::endl;
return output_tensor;
}
int main(int argc, char* argv[])
{
U2NetModel model(L"u2net.onnx");
cv::Mat image = cv::imread("horse.jpg");
cv::resize(image, image, { 320, 320 },0.0,0.0, cv::INTER_CUBIC);//调整大小到320*320
cv::imshow("image", image); //打印原图片
cv::cvtColor(image, image, cv::COLOR_BGR2RGB); //BRG格式转化为RGB格式
auto result=model.predict(image); //模型预测
cv::imshow("result", result); //打印结果
cv::waitKey(0);
}

到这里模型的部署和结果的展示就OKK了
不过直接把模型输出转化为图片显然结果并不是非常理想
所以现在还需要对数据进行后处理,对图片进行二值化处理
得到一个Mask掩码矩阵
cv::Mat output_tensor(output_data);
output_tensor=255.0-output_tensor.reshape(1, { 320,320 })*255.0;
cv::threshold(output_tensor, output_tensor, 220, 255, cv::THRESH_BINARY_INV);
return output_tensor;
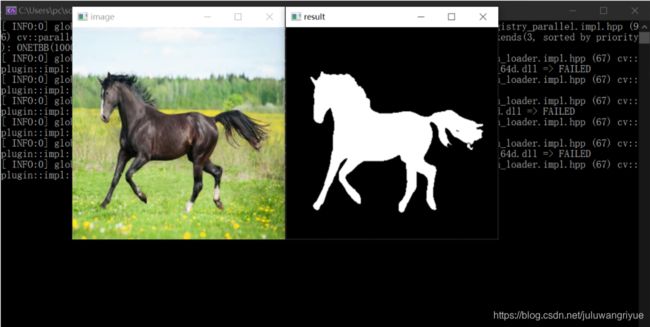
现在结果就已经十分的理想了
完整测试代码
#include 参考:神经网络语义分割模型C++部署(VS2019+ONNXRuntime+OpenCV)