linux 多核 系统时钟,Linux时间子系统之(十五):clocksource
Linux时间子系统之(十五):clocksource
作者:linuxer 发布于:2014-12-1 19:03
分类:时间子系统
一、前言
和洋葱一样,软件也是有层次的,内核往往需要对形形色色的某类型的驱动进行抽象,屏蔽掉其具体的特质,获取该类驱动共同的逻辑,而又根据这些逻辑撰写该类驱动的抽象层。嵌入式系统总是会提供timer的硬件block,软件需要对timer硬件提供的功能进行抽象:linux kernel将timer类型的硬件抽象成两个组件,一是free running的counter,另外一个是指定的counter值上产生中断的能力。本文主要描述第一个组件,在内核中被称作clock source。
二、什么是clocksource?
1、基础概念
我们先回到一个基础的问题上来:什么是时间?时间其实可以抽象成一条直线,没有起点,也没有终点(所以我们叫它timeline)。我们可以以一定的刻度来划分这条直线,例如以1秒的间隔。这样还不行,还需要一个参考点,例如在耶稣诞辰的时间定位0点。OK,大家终于可以时间的定义上统一了,例如我可以和wowo同学约定在68365287秒的时间一起去吃饭,恩,看起来不是那么方便,还是可以对以秒计算的时间进行grouping,因此有了年、月、日、时、分这些概念。
对于内核,它的timeline是怎样的呢?首先时间不是一条直线,因为硬件的计数不可能是无限制的,我们总是使用有限的bit数目的硬件来计数,因此,对于内核(更准确的说对于计算机系统),其时间更像是一个不断重复的线段,最终也是形成一个没有起点也没有终点的timeline。此外,和人不同的是,机器不喜欢grouping,它们更喜欢用一个绝对的数字来标识当前的时间(当然,机器是为人服务的,最终会在人机界面的部分转换成年、月、日、时、分、秒这样的格式)。
2、内核数据结构
所谓clock source就是用来抽象一个在指定输入频率的clock下工作的一个counter。输入频率可以确定以什么样的精度来划分timeline(假设输入counter的频率是1GHz,那么一个cycle就是1ns,也就是说timeline是用1ns来划分的,最大的精度就是1ns),counter的bit数确定了组成timeline上的“线段”的长度。内核中的struct clocksource 定义如下:
struct clocksource {
cycle_t (*read)(struct clocksource *cs);-----------------(1)
cycle_t cycle_last;
cycle_t mask;
u32 mult;
u32 shift;
u64 max_idle_ns;
u32 maxadj;
const char *name;--------------------------(2)
struct list_head list;
int rating;
int (*enable)(struct clocksource *cs);
void (*disable)(struct clocksource *cs);
unsigned long flags;
void (*suspend)(struct clocksource *cs);
void (*resume)(struct clocksource *cs);
#ifdef CONFIG_CLOCKSOURCE_WATCHDOG---------------(3)
struct list_head wd_list;
cycle_t cs_last;
cycle_t wd_last;
#endif
struct module *owner;
} ____cacheline_aligned;
struct clocksource的成员分成3组,我们分别介绍:
(1)这部分的代码是和计时有关的,kernel会频繁的访问这些数据结构,因此最好把它们放到一个cacheline中,struct clocksource这个数据结构有cacheline aligned的属性,任何定义的变量都是对齐到cacheline的,而这些计时相关的成员被放到clocksource数据结构的前面就是为了提高cache hit。一旦访问了read成员,随后的几个成员也就被加载到cacheline中,从而提高的性能。对于clock source抽象的counter而言,其counter value都是针对clock计数的,具体一个clock有多少个纳秒是和输入频率相关的。
通过read获取当前的counter value,这个计数值是基于cycle的(数据类型是cycle_t,U64)。不过,对于用户和其他driver而言,cycle数据是没有意义的,最好统一使用纳秒这样的单位,因此在struct clocksource中就有了mult和shift这两个成员了。我们先看看如何将A个cycles数转换成纳秒,具体公式如下:
转换后的纳秒数目 = (A / F) x NSEC_PER_SEC
这样的转换公式需要除法,绝大部分的CPU都有乘法器,但是有些处理器是不支持除法,当然,对于不支持硬件除法器的CPU上,toolchain中会提供除法的代码库,虽然我们无法将除法操作的代码编译成一条除法的汇编指令,但是也可以用代码库中的其他运算来取代除法。这样做的坏处就是性能会受影响(想到这里的代码会被内核其他模块反复调用,你是不是很心疼那些CPU的MIPS?)。肿么办?要知道,linux kernel的目标是星辰大海,它是打算服务多种CPU体系结构,并且要有优秀性能表现的。把1/F变成浮点数,这样就可以去掉除法了,但是又引入了浮点运算,kernel是不建议使用浮点运算的(为何如此建议,你有考虑过吗?请把答案寄到蜗窝科技大厦,可以赢取内核之旅门票一张,呵呵~~~)。解决方案很简单,使用移位操作,具体可以参考clocksource_cyc2ns的操作:
static inline s64 clocksource_cyc2ns(cycle_t cycles, u32 mult, u32 shift)
{
return ((u64) cycles * mult) >> shift;
}
也就是说,通过clock source的read函数获取了cycle数目,乘以mult这个因子然后右移shift个bit就可以得到纳秒数。这样的操作虽然性能比较好,但是损失了精度,还是那句话,设计是平衡的艺术,看你自己的取舍。 其他的成员我们会在后面的代码分析中给出解释。
(2)这段的代码访问没有那么频繁,主要是和一些系统操作相关。例如list成员。系统将所有已经注册clocksource挂在一个链表中,list就是挂入链表的节点。suspend和resume是和电源管理相关,enable和disable是启停该clock source的callback函数。rating是描述clock source的精度的,毫无疑问,一个输入频率是20MHz的counter精度一定是大于10ms一个cycle的counter。关于rating,内核代码的注释已经足够了,如下:
1-99: Unfit for real use
Only available for bootup and testing purposes.
100-199: Base level usability.
Functional for real use, but not desired.
200-299: Good.
A correct and usable clocksource.
300-399: Desired.
A reasonably fast and accurate clocksource.
400-499: Perfect
The ideal clocksource. A must-use where available.
clock source flag描述一些该clock source的特性,我们会在后面的代码分析中给出更详细的信息。
(3)第三部分的成员和clocksource watch dog相关。大家比较熟悉是系统的watch dog,主要监视系统,如果不及时喂狗,系统就会reset。clocksource watch dog当然是用来监视clock source的运行情况,如果watch dog发现它监视的clocksource的精度有问题,会修改其rating,告知系统。后面我们会有专门一个章节来描述这部分的内容。
三、注册和注销clock source
这个接口主要是提供给底层clock source chip driver使用的,在底层的driver初始化的时候会调用该接口向系统注册clock source。注销clock source是注册的逆过程。
1、注册函数1:调用者已经计算好mult和shift
如果在驱动代码中已经根据输入频率设定好了mult和shift,那么内核的clocksource layer是不需要进行这部分的内容的计算,那么注册clock source就会比较简单,代码如下:
int clocksource_register(struct clocksource *cs)
{
cs->maxadj = clocksource_max_adjustment(cs);---------------(1)
cs->max_idle_ns = clocksource_max_deferment(cs); -------------(2)
mutex_lock(&clocksource_mutex);----------------------(3)
clocksource_enqueue(cs);--------------------------(4)
clocksource_enqueue_watchdog(cs);---------------------(5)
clocksource_select();----------------------------(6)
mutex_unlock(&clocksource_mutex);
return 0;
}
(1)在给定的mult和shift组合下,计算最大的mult调整值。时间是需要校准的,首先counter的输入频率是有误差的,此外,在计算纳秒的时候mult和shift又引入了误差,这些误差可以通过外部的一些基准值进行校准(例如NTP server)。不过由于在将cycle值转换成纳秒值的过程中(((u64) cycles * mult) >> shift),太大的mult值会导致溢出,因此对multi的修正不应该过大,需要有一个限度,maxadj就是这个限度。clocksource_max_adjustment的代码很简单,就是返回clock source中mult成员11%的值(为何是11%呢?)。
此外,需要注意的是:这里有潜在溢出的风险,用户设定的mult是u32的,有可能已经逼近最大值,mult + maxadj有可能导致32bit的溢出(当然,这是在最大调整值的情况下)。
(2)我们前面已经了解了将counter value(cycle值)转换成ns的公式,这个公式是有限制的,cycle值不能太大(再强调一次,cycle值是用U64表示的),如果太大的话,cycles * mult的结果也会超出64bit从而导致溢出。因此,max_idle_ns 就是说明保证从cycle到ms不产生溢出的那个最大的纳秒数。为何其名字中有个idle呢?这是因为最大的cycle值是出现在idle的时候。我们知道,传统的Unix都是有一个周期性的tick,在嵌入式系统中,我们经常设定为10ms,但是linux kernel也允许你配置成NO_HZ,这时候,系统就不存在那个周期性的tick了,如果系统没有任何的动作是否CPU就一直idle下去了呢?不会的,由于counter value和纳秒的转换限制,这个idle的时间不能超过max_idle_ns。具体的计算很简单,这里不再具体描述。计算max_idle_ns的时候,为了安全还设定了12.5%的margin,之所以选择12.5%,是因为可以通过移位(而不是除法)的操作完成,看,kernel工程师永远都是performance至上的。
(3)通过clocksource_mutex保护对clock sourct list这一全局共享资源的访问。
(4)将该clock source按照rating的顺序插入到全局clock source list中
(5)处理clock source watchdog相关的内容,后面会详细介绍
(6)选择一个合适的clock source。kernel当然是选用一个rating最高的clocksource作为当前的正在使用的那个clock source。当注册一个新的clock source的时候当然要调用clocksource_select,毕竟有可能注册了一个精度更高的clock
source。
2、注册函数2:调用者给出输入clock频率,需要在注册过程中计算mult、shift和max_idle_ns
clock source chip driver可以调用clocksource_register_hz或者clocksource_register_khz这两个接口函数来注册一个clocksource。具体的接口定义如下:
static inline int clocksource_register_hz(struct clocksource *cs, u32 hz)
static inline int clocksource_register_khz(struct clocksource *cs, u32 khz)
hz和khz参数是传递counter的输入频率信息。这两个接口函数实际是调用了__clocksource_register_scale函数进行具体的操作,代码如下:
int __clocksource_register_scale(struct clocksource *cs, u32 scale, u32 freq)
{
__clocksource_updatefreq_scale(cs, scale, freq);
将该clocksource挂入全局链表,代码同上。
return 0;
}
最核心的代码就是__clocksource_updatefreq_scale这个函数,代码如下:
void __clocksource_updatefreq_scale(struct clocksource *cs, u32 scale, u32 freq)
{
u64 sec;
sec = (cs->mask - (cs->mask >> 3));-------------------(1)
do_div(sec, freq);
do_div(sec, scale);
if (!sec)
sec = 1;--------限制最小值
else if (sec > 600 && cs->mask > UINT_MAX)
sec = 600; ------------------------------(2)
clocks_calc_mult_shift(&cs->mult, &cs->shift, freq,--------------(3)
NSEC_PER_SEC / scale, sec * scale);
cs->maxadj = clocksource_max_adjustment(cs);---------------(4)
while ((cs->mult + cs->maxadj < cs->mult)
|| (cs->mult - cs->maxadj > cs->mult)) {
cs->mult >>= 1;
cs->shift--;
cs->maxadj = clocksource_max_adjustment(cs);
}
cs->max_idle_ns = clocksource_max_deferment(cs);
}
(1)硬件counter本身就是由有限个bit组成,因此它能表示的时间有一个最大的限制,超过之后counter就溢出了。根据counter的bit数目以及输入频率可以计算出该硬件counter能表示的最大的时间长度。cs->mask最是最大的cycle数目,除以频率就是能表示的最大的时间范围(以秒为单位)。因此,代码至此,我们知道,[0, sec秒]就是该counter能表示的以秒计算的时间范围。这里还引入了12.5%的margin,具体原因在上面clocksource_max_deferment函数中已经说明。
(2)在解析这里的代码之前,我们先考虑这样一个问题:如何获取最佳的mult和shift组合?mult这个因子一定是越大越好了,越大精度越高,但是,我们的运算过程都是64 比特的,也就是说,中间的结果(cycle x mult)不能超过64bit。对于32bit的count,这个要求还好,因为cycle就是32bit的,只要mult不超过32bit就OK了(mult本来就是u32的)。因此,对于那些超过32 bit的count,我们就需要注意了,我们要人为的限制最大时间值,也就是说,虽然硬件counter可以表示出更大的时间值,但是通过mult和shift将这个大的cycle值转成ns值的时候,如果cycle太大,势必导致mult要小一些(否则溢出),而mult较小会导致精度不足,而精度不足(这时候如果要保证转换算法正确,mult需要取一个较小的数值,从而降低了精度)导致转换失去意义,因此,这里给出一个600秒的限制,这个限制也是和max idle ns相关的,具体参考上面的描述。
其实这里仍然是一个设计平衡的问题:一方面希望保持精度,因此mult要大,cycle到ns转换的时间范围就会小。另外一方面,cpuidle模块从电源管理的角度看,当然希望其在没有任务的时候,能够idle的时间越长越好,600秒是一个折衷的选择,让双方都基本满意。
(3)进入真正的mult和shift计算时刻了,代码如下:
void clocks_calc_mult_shift(u32 *mult, u32 *shift, u32 from, u32 to, u32 maxsec)
{
u64 tmp;
u32 sft, sftacc= 32;
tmp = ((u64)maxsec * from) >> 32;-------------------(a)
while (tmp) {
tmp >>=1;
sftacc--;------------------------------(b)
}
for (sft = 32; sft > 0; sft--) {-----------------------(c)
tmp = (u64) to << sft;
tmp += from / 2;
do_div(tmp, from);--------------------------(d)
if ((tmp >> sftacc) == 0)
break;
}
*mult = tmp;
*shift = sft;
}
(a)在这个场景中,from是count的输入频率,maxsec是最大的表示的范围。maxsec * from就是将秒数转换成了cycle数目。对于大于32 bit的counter而言,最大的cycle数目有可能需要超过32个bit来表示,因此这里要进行右移32bit的操作。对于32 bit以下的counter,这时候的tmp右移32bit之后一定会等于0,而对于大于32 bit的counter,tmp是一个非0值。
(b)sftacc保存了左移多少位才会造成最大cycle数(对应最大的时间范围值)的溢出,对于32 bit以下的counter,统一设定为32个bit,而对于大于32 bit的counter,sftacc需要根据tmp值(这时候tmp保存了最大cycle数的高32 bit值)进
行计算。
(c)如何获取最佳的mult和shift组合?我们之前已经回答这个问题了,现在进入实现的层面。当一个公式中有两个可变量的时候,最好的办法就是固定其中一个,求出另外一个,然后带入约束条件进行检验。我们首先固定shift这个参数。mult这个因子一定是越大越好,mult越大也就是意味着shift越大。当然shift总有一个起始值,我们设定为32bit,因此sft从32开始搜索,看看是否满足最大时间范围的要求。如果满足,那么就找到最佳的mult和shift组合,否则要sft递减,进行下一轮搜索。
(d)我们先考虑如何计算mult值。根据公式cycles * mult) >> shift可以得到ns数,由此可以得到计算mult值的公式:
mult = (ns<
如果我们设定ns数是10^9纳秒(也就是1秒)的话,cycles数目就是频率值(所谓频率不就是1秒振荡的次数嘛)。因此上面的公式可以修改为:
mult = (NSEC_PER_SEC<
看看上面的公式,再对照代码,一切就很清晰了,这里的tmp就是得到了一个mult值。这个mult值是否合适?不一定,因此这个mult值有可能导致溢出(转换的时候,我们要保证最大时间范围对应的cycle数目乘以这个mult值不能造成64 bit的溢出),如果溢出的话,只能说明mult值还是要小一点哦,从而进入下一次的loop。如何判断mult值会溢出?我们可以看下面的图片:
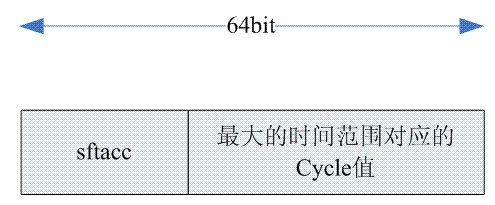
在步骤b中计算得到的sftacc就是multi的最大的bit数目。因此,(tmp >> sftacc)== 0就是判断找到最优mult的条件。
(4)这段代码主要是计算clock source的maxadj成员。由于mult有可能被NTP修改,NTP会根据情况会增加或者减少mult的值。我们设定NTP的修正在11%左右,因此clocksource_max_adjustment很是非常直观的,这里就不再描述了。
(5)检查maxadj设定是否OK,是否会溢出,如果是的话,说明mult值还是太大,那么需要还是要降低。
(6)计算max_idle_ns。
3、注销clocksource
clocksource_unregister函数用来注销一个clocksource,其主要的逻辑都在clocksource_unbind中,代码如下:
static int clocksource_unbind(struct clocksource *cs)
{
if (clocksource_is_watchdog(cs))
return -EBUSY; ----不能注销watchdog机制中的基准clocksource
if (cs == curr_clocksource) {---注销当前clock source的处理
clocksource_select_fallback();----选择一个新的当前clock source
if (curr_clocksource == cs)
return -EBUSY;-----是系统中的唯一的clock source,不能注销
}
clocksource_dequeue_watchdog(cs);-----将该节点从watchdog的全局列表中取下来
list_del_init(&cs->list);--------将该节点从clocksource的全局列表中取下来
return 0;
}
四、如何挑选clock source
1、系统在什么时候会启动选择clock source的过程?
主要context如下:
(1)注册一个新的clock source。有新货到来,总是要再挑挑拣拣吧,说不定会有新发现。
(2)注销clock source。如果注销掉的就是current clock source,总得在剩下的矮子中选一个将军吧
(3)在clock source watchdog中启动。具体参考下一章描述
(4)底层的clock source chip driver调用clocksource_change_rating修改rating。底层的clock source chip driver有可能自废武功,也有可能满血复活,这时候当然要重新选举,否则有可能废材当盟主。
(5)来自用户空间的请求。用户空间的程序可以通过current_clocksource的属性文件强行指定current clocksource。这时候,用户空间程序会给出clock source的名字,内核将用户空间向设定的名字写入override_name buffer,然后调用clocksource_select函数。
2、选举最优clock source的过程
调用clocksource_select函数可以启动选举最优clock source的过程,而该函数实际上是调用__clocksource_select来完成具体的操作,__clocksource_select代码如下:
static void __clocksource_select(bool skipcur)-----传入参数表示是否skip current clock source
{
bool oneshot = tick_oneshot_mode_active();
struct clocksource *best, *cs;
best = clocksource_find_best(oneshot, skipcur);-------------(1)
list_for_each_entry(cs, &clocksource_list, list){--------------(2)
if (skipcur && cs == curr_clocksource)
continue;
if (strcmp(cs->name, override_name) != 0)----不是用户指定的那个,忽略之
continue;
if (!(cs->flags & CLOCK_SOURCE_VALID_FOR_HRES) && oneshot) {
override_name[0] = 0;-------上帝错了,修正之
} else
best = cs;-------OK,用户是上帝,把用户指定的设定为best
break;
}
if (curr_clocksource != best && !timekeeping_notify(best)){----------(3)
curr_clocksource = best;
}
}
(1)找到最好的那个clock source。oneshot这个参数表示本CPU的tick device的工作模式,这个工作模式有两种,一种是周期性tick,也就是大家熟悉的传统的tick。另外一种叫做one shot模式,更详细的信息请参考Linux时间子系统之
(十三):Dynamic tick。由于工作在one shot模式下的tick device对clock source有特别的需求,因此ocksource_find_best函数需要知道本CPU的tick device的工作模式。具体代码如下:
static struct clocksource *clocksource_find_best(bool oneshot, bool skipcur)
{
struct clocksource *cs;
if (!finished_booting || list_empty(&clocksource_list))--------------(a)
return NULL;
list_for_each_entry(cs, &clocksource_list, list) {----------------(b)
if (skipcur && cs == curr_clocksource)
continue;
if (oneshot && !(cs->flags & CLOCK_SOURCE_VALID_FOR_HRES))
continue;
return cs;
}
return NULL;
}
(a)系统中的timer硬件有可能包括多个,这些HW timer的驱动都会向系统注册clock source,这导致在初始化的过程中,current clock source会变来变去。与其这样,不如等到尘埃落定(系统启动完毕,各个clock source chip完成初始
化)的时候再启动clock source的甄选。finished_booting就是启这个作用的。当然,clock source全局列表是空的话也会返回NULL。
(b)实际的选择当然是rating最高的那个clock source(也就是clock sourcelist中最前面的节点)。但是,如果当前是one shot模式,那么clock source是需要设定CLOCK_SOURCE_VALID_FOR_HRES这个flag的。
(2)这段代码是处理用户空间指定current clock source的请求。用户空间程序会将其心仪的clock source的名字放入到override_name中,在clocksourceselect的时候需要scan clock source列表,找到用户指定的那个clock source,
并将其设定为best。注意:这里会覆盖上面clocksource_find_best函数中找到的那个best clock source。当然,用户虽然是上帝,但是用户也许是愚蠢的,他有可能指定错误的clock source。例如其指定的clock source不支持高精度timer和NO HZ的配置,但是当前的系统恰恰是需要这种能力的。这时候,我们当然不能纵然用户。
(3)调用timekeeping_notify函数通知timekeeping模块。
五、clock source watchdog
呵呵~~~有空再写吧。
六、用户空间接口
1、sysfs接口初始化
在系统初始化的时候会调用init_clocksource_sysfs函数来初始化clock source的sys file system接口,如下:
static int __init init_clocksource_sysfs(void)
{
int error = subsys_system_register(&clocksource_subsys, NULL); --------(1)
if (!error)
error = device_register(&device_clocksource);----------------(2)
if (!error)
error = device_create_file(-------------------------(3)
&device_clocksource,
&dev_attr_current_clocksource);
if (!error)
error = device_create_file(&device_clocksource,
&dev_attr_unbind_clocksource);
if (!error)
error = device_create_file(
&device_clocksource,
&dev_attr_available_clocksource);
return error;
}
device_initcall(init_clocksource_sysfs);
(1)一路陪着linux kernel走来的工程师应该对sysdev_class、sys_device、sysdev_driver以及SYSDEV_ATTR这些定义有印象。linux kernel提供了一个pseudo-bus,这条bus主要是用于cpus,中断控制器,timer等系统设备。sysdev_class、sys_device和sysdev_driver组成系统设备三件套,对应设备模型只能够的bus type,device和driver。其实system device模型中需要处理的也是和linux设备模型中类似的逻辑:注册设备、注册driver、driver和设备的匹配等
等。当然也有不同的地方,例如:在电源管理过程中,系统进入suspend状态的时候,优先处理其他的设备,最后处理system设备,唤醒的时候,先唤醒systemdevice,然后是其他普通设备。系统设备是和其他普通设备息息相关的,因此需要首先唤醒,只有这样处理,普通设备在唤醒后才能正常使用系统设备提供的功能。Anyway,虽有不同,但是从high level的层面看还是大部分相同的,用两套逻辑来处理类似的东西还是看起来有些怪异的。因此,3.3的kernel代码废除了systemdevice机制,使用统一设备模型来处理系统设备。
能统一处理当然好,又回到大家熟悉的bus type,device和driver的路子上来。但是,kernel不是活在真空中,大量的AP软件使用了旧的system device机制提供的sysfs接口,为了兼容,subsys_system_register这样的函数被设计出来,调用该接口便创建和旧的system device机制一样的sysfs接口。
(2)OK,回归设备模型当然要定义三件套了,bus type定义如下:
static struct bus_type clocksource_subsys = {
.name = "clocksource",
.dev_name = "clocksource",
};
device定义如下:
static struct device device_clocksource = {
.id = 0,
.bus = &clocksource_subsys,
};
调用device_register就可以把clock source这个device加入到系统中,统一设备模型会帮我们做一切事情(例如设定clock source这个device对象的名字。作为一个object,clock source device需要一个名字,就是其kobject成员的名字。内核允许将设备的名字留空,当调用device_register函数将设备注册到设备模型中后,设备模型会将"bus->dev_name+device ID”的名字赋给该设备对象,看,多么的贴心)。
(3)原来使用SYSDEV_ATTR定义的系统设备属性先改成使用普通的DEVICE_ATTR,具体如下:
static DEVICE_ATTR(current_clocksource, 0644,
sysfs_show_current_clocksources,
sysfs_override_clocksource);
static DEVICE_ATTR(unbind_clocksource, 0200, NULL,
sysfs_unbind_clocksource);
static DEVICE_ATTR(available_clocksource, 0444,
sysfs_show_available_clocksources, NULL);
系统中有多个clocksource,通过available_clocksource这个设备属性可以知道当前系统有多少个可用的clocksource。虽然系统有多个clocksource,但是内核会以一定的策略选择一个(例如rating最高的哪个)作为当前的clocksource,这个可以通过current_clocksource这个属性文件获得当前系统正在使用的clocksource。对该属性文件写可以设定current clock source。unbind_clocksource属性是write only的,该接口可以对某个clocksource进行unbind的操作。
调用device_create_file函数为clocksource设备创建上面定义的三个属性。
七、提供给其他driver计时用的接口函数
1、为何会有timecounter和cyclecounter
在内核的driver中,我们可能有这样的需求:获取drive中的A事件和B事件之间的时间值或者一个event stream过程中,各个event的时刻值。这里,driver不关心绝对的时间点,关心的是事件之间的时长。为了应对这个需求,clock source模块提供了timecounter和cyclecounter。
内核中使用struct cyclecounter 来抽象一个free running的counter,从0开始,不断累加。由于counter的bit数目有限,因此,某个时间后,counter会wraparound,从0继续开始。该数据结构定义如下:
struct cyclecounter {
cycle_t (*read)(const struct cyclecounter *cc);--获取当前的counter value,单位是cycle
cycle_t mask;------------该count有多少个bit?
u32 mult;--------------转换成ns需要的乘积因子
u32 shift; --------------转换成ns需要的右移因子
};
每个cycle counter的counter value都是针对clock计数的,因此,通过read获取的counter value是基于cycle的,而cycle又是和输入频率有关。不过,对于其他driver而言,cycle数据是没有意义的,最好统一使用纳秒这样的单位,因此在
struct cyclecounter 中就有了mult和shift这两个成员了。读到这里,我相信大部分的读者都会怒吼:你这些文字在描述clock source的时候就说过一遍,现在又拿出来骗。呵呵~~稍安勿躁,实际上内核的确把一个HW block抽象成了两个数据结构,具体参考下图:
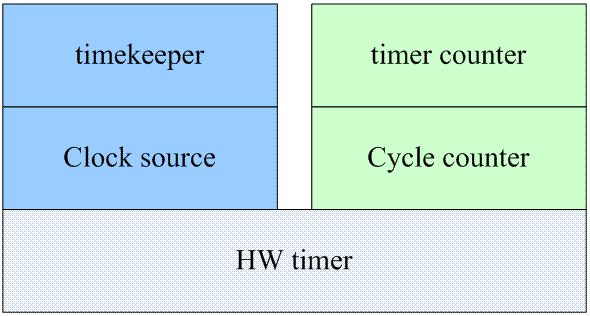
实际上,最开始的时候,内核的确是只有clock source模块,它位于timekeeping模块和硬件之间。但是,其他内核模块也有访问free running counter的需要,这时候,内核开发人员创建了cycle counter和timer counter这样的概念,虽然代码有一点重复,但是这样不会触及clock source代码的改动。
timecounter是构架在cycle counter之上,使用纳秒这样的时间单位而不是cycle数目,这样的设计会让用户接口变得更加友好,毕竟大家还是喜欢直观的纳秒值。timecounter的定义如下:
struct timecounter {
const struct cyclecounter *cc;-----------该timer
counter base的cycle counter
cycle_t cycle_last;----------------上一次访问的
counter value
u64 nsec;--------------------当前的纳秒值
};
2、如何使用timecounter的接口
首先需要初始化,代码如下:
void timecounter_init(struct timecounter *tc, const struct
cyclecounter *cc, u64 start_tstamp)
{
tc->cc = cc;-------------该time counter需要哪一个
cycle counter?
tc->cycle_last = cc->read(cc);-----获取初始化时刻HW counter
的counter value
tc->nsec = start_tstamp;-------设定纳秒的基准值
}
如果start_tstamp等于0的话,在调用timecounter_init这个时刻被定义为0纳秒。之后,驱动代码可以调用timecounter_read函数来获取当前的时间值(基于start_tstamp的),代码如下:
u64 timecounter_read(struct timecounter *tc)
{
u64 nsec;
nsec = timecounter_read_delta(tc);--离上次调用timecounter_init或者timecounter_read过去了
----多少时间了?
nsec += tc->nsec;
tc->nsec = nsec; -----------设定当前时间
return nsec;
}
原创文章,转发请注明出处。蜗窝科技
http://www.wowotech.net/linux_kenrel/clocksource.html
评论:
2017-06-02 16:12
老板,你好!
我想请教个问题:
cycle counter是怎么初始化的?不需要注册吧?它应该与clock source是独立的吧,没什么关系吧?
2016-02-26 11:29
linux kernel将timer类型的硬件抽象成两个组件,一是free running的counter,另外一个是指定的counter值上产生中断的能力.
请教下,“另外一个是指定的counter值上产生中断的能力”在Linux 中是不是对应clockevent,看了关于时间的一系列文章,
觉得对于clocksource clockevent的抽象还是有点模糊,希望wowo再解惑下。
看了驱动中关于这部分的代码,如drivers/clocksource/arm_arch_timer.c,
这里面实现的clocksource timecounter,使用的好像是同一个timer,感觉不解的是如果使用同个timer,clocksource如果suspend或是
disable,那岂不是影响了timecounter的相关功能?
2016-02-26 11:34
@electrlife:另外,在底层的硬件中似乎关于定时的只有一种timer的HW,在linux中,clocksource 与clockevent抽象的是不是都是timer HW,如果是为何使用两种抽象来描述一种HW,在底层的驱动中同一个timer HW会不会即是clocksource 又是clockevent?
2016-02-26 13:13
@electrlife:回答你的问题需要从需求的角度入手,一个HW timer对应的驱动会面临三种需求:
1、来自系统的计时的需求,换句话说系统需要知道现在是xx年xx月xx日xx时xx分xx秒xx纳秒。
2、系统需要软件timer的服务。即从当前时间点开始,到xxx纳秒之后通知我做某些事情
3、对某些事件之间的时间长度进行度量
实际上,linux内核应对上面的三种需求,分别提出了clocksource,clockevent和timercounter的概念。到底底层的HW情况是怎样的,who care?只要能满足需求就足够了。你可以考虑只提供若干个free running的counter A1 A2....,然后提供另外一个能够产生中断的hw timer B1 B2....,可是分开的HW block又能得到什么好处呢?合在一起还能复用某些HW block呢。因此,在单核时代,大部分的HW timer都是free running的counter + 产生中断的HW timer,来到多核时代,实际上这些block又可以分开,例如各个CPU core都有自己的local timer HW block,共享一个系统的HW counter。不过,无论硬件如何变,从软件需求的角度看看往往可以看到更本质的东西。
2016-02-26 16:00
@郭健:可能我主要做的是底层,所以比较关注对于底层的抽象,我的理解,一般底层HW仅是timer,所谓有free running counter也应该是timer HW。不确定是否有存在free running counter? 谢谢你的回答,如果clocksource,clockevent仅仅是依据上层需求来抽象的话,就比较容易理解了!
andyshrk
2015-09-12 17:05
拜读了这一系列文章,获益良多。想请问下,clocksource和clock event里面的rating是根据什么设定的呢?
2015-09-13 00:12
@andyshrk:应该是根据其基于的那个HW timer的精度确定的,例如一个32kHz作为输入时钟源的HW timer精度会小于一个13MHz的hw timer,这些hw timer对应的clocksource和clock event的rating应该保持同样的关系
阿孟
2015-01-22 16:40
"另外一种叫做one shot模式,更详细的信息请参考Linux时间子系统之
(五):tick device"
第五章 不是这个啊。 tick device这个还更吗?
2015-01-22 19:40
@阿孟:应该是在Linux时间子系统之(十三):dynamic tick。不过还没有开始写,每年到过年的时候都是特别忙,我尽量吧
2014-12-01 21:18
沙发.
shift和mult那部分写的很详细,算的上是internet上独一份.
既然刚开始写我就多句嘴。 我觉得时间子系统这部分除了工作机制外,还需要描述clock source和clock event结构的抽象模型(时钟源和硬件定时器),以及它们之间的关系,另外还有 硬件定时器/硬件计时器clock sourceclock eventtick device之间的关系,我认为这几者之间的关系特别容易把人搅晕。
虽然clock source和clock event会存在多个,但对per cpu而言同时只有一个clock source和一个clock event在工作。如果能再描述下linux在嵌入式系统上运行最少需要几个硬件定时器和硬件计时器,那就更美妙了。
期待啊...
2014-12-02 09:07
@puppypyb:多谢您的鼓励和提醒,我们会尽量把这部分内容写的透彻又通俗易懂。
时间子系统之一是综述,我现在不敢落笔,等其他完成后再启动吧。
之三是clock event,之四是底层硬件驱动这是近期的打算。后续tick device、timekeeping、posix timer、hrt等都会登场的,慢慢来吧!
2014-12-01 19:18
Wowo同学,帮我增加一个时间子系统的类别,我搞了好一会儿也搞不定啊
2014-12-01 23:04
@linuxer:已经添加。
PS:今晚我换了一个付费空间,那些乱七八糟的广告没有了。你这一篇文章的图片没有同步过来,你有空再传一下。
2014-12-02 09:03
@wowo:太好了,世界终于清净了
发表评论:
昵称
邮件地址 (选填)
个人主页 (选填)