在上一节我们介绍了块设备驱动的I/O读写流程,以及块设备的注册/卸载、通用磁盘的申请/删除/添加相关的API。
此外还有一部分相关重要的内容没有介绍,那就是通用块层request_queue、bio等相关的内容。
一、通用块层核心数据结构
1.1 request_queue
请求队列是由struct request_queue表示的,每一个gendisk对象都有一个request_queue对象,保存对该gendisk对象的所有请求。定义在include/linux/blkdev.h:


struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
struct blk_queue_stats *stats;
struct rq_qos *rq_qos;
make_request_fn *make_request_fn;
dma_drain_needed_fn *dma_drain_needed;
const struct blk_mq_ops *mq_ops;
/* sw queues */
struct blk_mq_ctx __percpu *queue_ctx;
unsigned int nr_queues;
unsigned int queue_depth;
/* hw dispatch queues */
struct blk_mq_hw_ctx **queue_hw_ctx;
unsigned int nr_hw_queues;
struct backing_dev_info *backing_dev_info;
/*
* The queue owner gets to use this for whatever they like.
* ll_rw_blk doesn't touch it.
*/
void *queuedata;
/*
* various queue flags, see QUEUE_* below
*/
unsigned long queue_flags;
/*
* Number of contexts that have called blk_set_pm_only(). If this
* counter is above zero then only RQF_PM and RQF_PREEMPT requests are
* processed.
*/
atomic_t pm_only;
/*
* ida allocated id for this queue. Used to index queues from
* ioctx.
*/
int id;
/*
* queue needs bounce pages for pages above this limit
*/
gfp_t bounce_gfp;
spinlock_t queue_lock;
/*
* queue kobject
*/
struct kobject kobj;
/*
* mq queue kobject
*/
struct kobject *mq_kobj;
#ifdef CONFIG_BLK_DEV_INTEGRITY
struct blk_integrity integrity;
#endif /* CONFIG_BLK_DEV_INTEGRITY */
#ifdef CONFIG_PM
struct device *dev;
int rpm_status;
unsigned int nr_pending;
#endif
/*
* queue settings
*/
unsigned long nr_requests; /* Max # of requests */
unsigned int dma_drain_size;
void *dma_drain_buffer;
unsigned int dma_pad_mask;
unsigned int dma_alignment;
unsigned int rq_timeout;
int poll_nsec;
struct blk_stat_callback *poll_cb;
struct blk_rq_stat poll_stat[BLK_MQ_POLL_STATS_BKTS];
struct timer_list timeout;
struct work_struct timeout_work;
struct list_head icq_list;
#ifdef CONFIG_BLK_CGROUP
DECLARE_BITMAP (blkcg_pols, BLKCG_MAX_POLS);
struct blkcg_gq *root_blkg;
struct list_head blkg_list;
#endif
struct queue_limits limits;
#ifdef CONFIG_BLK_DEV_ZONED
/*
* Zoned block device information for request dispatch control.
* nr_zones is the total number of zones of the device. This is always
* 0 for regular block devices. seq_zones_bitmap is a bitmap of nr_zones
* bits which indicates if a zone is conventional (bit clear) or
* sequential (bit set). seq_zones_wlock is a bitmap of nr_zones
* bits which indicates if a zone is write locked, that is, if a write
* request targeting the zone was dispatched. All three fields are
* initialized by the low level device driver (e.g. scsi/sd.c).
* Stacking drivers (device mappers) may or may not initialize
* these fields.
*
* Reads of this information must be protected with blk_queue_enter() /
* blk_queue_exit(). Modifying this information is only allowed while
* no requests are being processed. See also blk_mq_freeze_queue() and
* blk_mq_unfreeze_queue().
*/
unsigned int nr_zones;
unsigned long *seq_zones_bitmap;
unsigned long *seq_zones_wlock;
#endif /* CONFIG_BLK_DEV_ZONED */
/*
* sg stuff
*/
unsigned int sg_timeout;
unsigned int sg_reserved_size;
int node;
#ifdef CONFIG_BLK_DEV_IO_TRACE
struct blk_trace *blk_trace;
struct mutex blk_trace_mutex;
#endif
/*
* for flush operations
*/
struct blk_flush_queue *fq;
struct list_head requeue_list;
spinlock_t requeue_lock;
struct delayed_work requeue_work;
struct mutex sysfs_lock;
/*
* for reusing dead hctx instance in case of updating
* nr_hw_queues
*/
struct list_head unused_hctx_list;
spinlock_t unused_hctx_lock;
int mq_freeze_depth;
#if defined(CONFIG_BLK_DEV_BSG)
struct bsg_class_device bsg_dev;
#endif
#ifdef CONFIG_BLK_DEV_THROTTLING
/* Throttle data */
struct throtl_data *td;
#endif
struct rcu_head rcu_head;
wait_queue_head_t mq_freeze_wq;
/*
* Protect concurrent access to q_usage_counter by
* percpu_ref_kill() and percpu_ref_reinit().
*/
struct mutex mq_freeze_lock;
struct percpu_ref q_usage_counter;
struct blk_mq_tag_set *tag_set;
struct list_head tag_set_list;
struct bio_set bio_split;
#ifdef CONFIG_BLK_DEBUG_FS
struct dentry *debugfs_dir;
struct dentry *sched_debugfs_dir;
struct dentry *rqos_debugfs_dir;
#endif
bool mq_sysfs_init_done;
size_t cmd_size;
struct work_struct release_work;
#define BLK_MAX_WRITE_HINTS 5
u64 write_hints[BLK_MAX_WRITE_HINTS];
};
其部分参数含义如下:
- queue_head:通过list_head可以用来构建一个request_queue类型的双向链表;
- make_request_fn:设置bio提交时的回调函数,一般设置为blk_mq_make_request;
- last_merge:指向队列中首次可能合并的请求描述符;
- elevator:指向elevator对象的指针(电梯算法),决定了I/O调度层使用的I/O调度算法;
- mq_ops:块设备驱动mq的操作集合,用于抽象块设备驱动的行为;
- requeue_list:请求队列中保存的request双向链表头节点;
- tag_set:标签集,这个后面介绍;
- tag_set_list:保存blk_mq_tag_set双向链表的头节点;
- queue_ctx:软件队列,这是一个per cpu变量,软件队列数量等于CPU数量;
- nr_queues:软件队列的数量,等于CPU的数量;
- queue_hw_ctx:硬件队列;
1.2 request
request表示经过I/O调度之后的针对一个gendisk的一个请求,是request_queue的一个节点,多个request构成了一个request_queue。request定义在include/linux/blkdev.h:
/*
* Try to put the fields that are referenced together in the same cacheline.
*
* If you modify this structure, make sure to update blk_rq_init() and
* especially blk_mq_rq_ctx_init() to take care of the added fields.
*/
struct request {
struct request_queue *q;
struct blk_mq_ctx *mq_ctx;
struct blk_mq_hw_ctx *mq_hctx;
unsigned int cmd_flags; /* op and common flags */
req_flags_t rq_flags;
int internal_tag;
/* the following two fields are internal, NEVER access directly */
unsigned int __data_len; /* total data len */
int tag;
sector_t __sector; /* sector cursor */
struct bio *bio;
struct bio *biotail;
struct list_head queuelist;
/*
* The hash is used inside the scheduler, and killed once the
* request reaches the dispatch list. The ipi_list is only used
* to queue the request for softirq completion, which is long
* after the request has been unhashed (and even removed from
* the dispatch list).
*/
union {
struct hlist_node hash; /* merge hash */
struct list_head ipi_list;
};
/*
* The rb_node is only used inside the io scheduler, requests
* are pruned when moved to the dispatch queue. So let the
* completion_data share space with the rb_node.
*/
union {
struct rb_node rb_node; /* sort/lookup */
struct bio_vec special_vec;
void *completion_data;
int error_count; /* for legacy drivers, don't use */
};
/*
* Three pointers are available for the IO schedulers, if they need
* more they have to dynamically allocate it. Flush requests are
* never put on the IO scheduler. So let the flush fields share
* space with the elevator data.
*/
union {
struct {
struct io_cq *icq;
void *priv[2];
} elv;
struct {
unsigned int seq;
struct list_head list;
rq_end_io_fn *saved_end_io;
} flush;
};
struct gendisk *rq_disk;
struct hd_struct *part;
/* Time that I/O was submitted to the kernel. */
u64 start_time_ns;
/* Time that I/O was submitted to the device. */
u64 io_start_time_ns;
#ifdef CONFIG_BLK_WBT
unsigned short wbt_flags;
#endif
#ifdef CONFIG_BLK_DEV_THROTTLING_LOW
unsigned short throtl_size;
#endif
/*
* Number of scatter-gather DMA addr+len pairs after
* physical address coalescing is performed.
*/
unsigned short nr_phys_segments;
#if defined(CONFIG_BLK_DEV_INTEGRITY)
unsigned short nr_integrity_segments;
#endif
unsigned short write_hint;
unsigned short ioprio;
unsigned int extra_len; /* length of alignment and padding */
enum mq_rq_state state;
refcount_t ref;
unsigned int timeout;
unsigned long deadline;
union {
struct __call_single_data csd;
u64 fifo_time;
};
/*
* completion callback.
*/
rq_end_io_fn *end_io;
void *end_io_data;
};
其部分参数含义如下:
- q:这个request所属的请求队列;
- tag:为这个reques分配的tag,本质上就是一个索引号,如果没有为-1;
- __sectot:u64类型,当前request读取或写入到块设备起始扇区(每个扇区512 字节);
- __data_len:当前request读取或写入到块设备的字节大小;
- mq_ctx:指定这个请求将会发送到的软件队列;
- bio:组成这个request的bio链表的头指针;
- biotail:组成这个request的bio链表的尾指针;
- hash:内核hash表头指针;
- queuelist:通过list_head可以用来构建一个request类型的双向链表;
1个request中包含了一个或多个bio,为什么要有request这个结构呢?它存在的目的就是为了进行io的调度,通过request这个辅助结构,我们来给bio进行某种调度方法的排序,从而最大化地提高磁盘访问速度。
1.3 bio
bio用来描述单一的I/O请求,它记录了一次I/O操作所必需的相关信息,如用于I/O操作的数据缓存位置,I/O操作的块设备起始扇区,是读操作还是写操作等等。
bio结构包含了一个磁盘存储区标识符(存储磁盘起始扇区和扇区数目)和一个或多个描述与I/O操作相关的内存区段(bio_vec数组)。
bio定义在include/linux/blk_types.h:
/*
* main unit of I/O for the block layer and lower layers (ie drivers and
* stacking drivers)
*/
struct bio {
struct bio *bi_next; /* request queue link */
struct gendisk *bi_disk;
unsigned int bi_opf; /* bottom bits req flags,
* top bits REQ_OP. Use
* accessors.
*/
unsigned short bi_flags; /* status, etc and bvec pool number */
unsigned short bi_ioprio;
unsigned short bi_write_hint;
blk_status_t bi_status;
u8 bi_partno;
/* Number of segments in this BIO after
* physical address coalescing is performed.
*/
unsigned int bi_phys_segments;
struct bvec_iter bi_iter;
atomic_t __bi_remaining;
bio_end_io_t *bi_end_io;
void *bi_private;
#ifdef CONFIG_BLK_CGROUP
/*
* Represents the association of the css and request_queue for the bio.
* If a bio goes direct to device, it will not have a blkg as it will
* not have a request_queue associated with it. The reference is put
* on release of the bio.
*/
struct blkcg_gq *bi_blkg;
struct bio_issue bi_issue;
#endif
union {
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
};
unsigned short bi_vcnt; /* how many bio_vec's */
/*
* Everything starting with bi_max_vecs will be preserved by bio_reset()
*/
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
struct bio_set *bi_pool;
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
*/
struct bio_vec bi_inline_vecs[0];
};
其部分参数含义如下:
- bi_next:指向链表中下一个bio;
- bi_disk:正想当前bio发往的磁盘gendisk;
- bi_opf:低24位为请求标志位,高8位为请求操作位;
- bi_flags:bio状态等信息;
- bi_iter:磁盘存储区标识符,描述了当前bio_vec被处理的情况;
- bi_phys_segments:把病之后bio中物理段的数目;
- bi_end_io:bio的I/O操作结束时调用的函数;
- bi_private:通用块层和块设备驱动程序的I/O完成方法使用的指针;
- bi_vcnt:bio对象包含bio_vec对象的数目;
- bi_max_vecs:这个bio能承载的最大的bio_vec的数目;
- bi_io_vec:存放段的数组,bio中每个段是由一个bio_vec的数据结构描述的,关于什么是“段”下面会有介绍;
- bi_pool:备用的bio内存池;
- bi_inline_vecs:一般一个bio就一个段,bi_inline_vecs就 可满足,省去了再为bi_io_vec分配空间;
一个bio可能有多个bio_vec,多个bio经过I/O调度和合并之后可以形成一个request。
请求操作以及请求标志定义在include/linux/blk_types.h:
/*
* Operations and flags common to the bio and request structures.
* We use 8 bits for encoding the operation, and the remaining 24 for flags.
*
* The least significant bit of the operation number indicates the data
* transfer direction:
*
* - if the least significant bit is set transfers are TO the device
* - if the least significant bit is not set transfers are FROM the device
*
* If a operation does not transfer data the least significant bit has no
* meaning.
*/
#define REQ_OP_BITS 8
#define REQ_OP_MASK ((1 << REQ_OP_BITS) - 1)
#define REQ_FLAG_BITS 24
enum req_opf {
/* read sectors from the device */
REQ_OP_READ = 0,
/* write sectors to the device */
REQ_OP_WRITE = 1,
/* flush the volatile write cache */
REQ_OP_FLUSH = 2,
/* discard sectors */
REQ_OP_DISCARD = 3,
/* securely erase sectors */
REQ_OP_SECURE_ERASE = 5,
/* reset a zone write pointer */
REQ_OP_ZONE_RESET = 6,
/* write the same sector many times */
REQ_OP_WRITE_SAME = 7,
/* write the zero filled sector many times */
REQ_OP_WRITE_ZEROES = 9,
/* SCSI passthrough using struct scsi_request */
REQ_OP_SCSI_IN = 32,
REQ_OP_SCSI_OUT = 33,
/* Driver private requests */
REQ_OP_DRV_IN = 34,
REQ_OP_DRV_OUT = 35,
REQ_OP_LAST,
};
enum req_flag_bits {
__REQ_FAILFAST_DEV = /* no driver retries of device errors */
REQ_OP_BITS,
__REQ_FAILFAST_TRANSPORT, /* no driver retries of transport errors */
__REQ_FAILFAST_DRIVER, /* no driver retries of driver errors */
__REQ_SYNC, /* request is sync (sync write or read) */
__REQ_META, /* metadata io request */
__REQ_PRIO, /* boost priority in cfq */
__REQ_NOMERGE, /* don't touch this for merging */
__REQ_IDLE, /* anticipate more IO after this one */
__REQ_INTEGRITY, /* I/O includes block integrity payload */
__REQ_FUA, /* forced unit access */
__REQ_PREFLUSH, /* request for cache flush */
__REQ_RAHEAD, /* read ahead, can fail anytime */
__REQ_BACKGROUND, /* background IO */
__REQ_NOWAIT, /* Don't wait if request will block */
/* command specific flags for REQ_OP_WRITE_ZEROES: */
__REQ_NOUNMAP, /* do not free blocks when zeroing */
__REQ_HIPRI,
/* for driver use */
__REQ_DRV,
__REQ_SWAP, /* swapping request. */
__REQ_NR_BITS, /* stops here */
};
#define REQ_FAILFAST_DEV (1ULL << __REQ_FAILFAST_DEV)
#define REQ_FAILFAST_TRANSPORT (1ULL << __REQ_FAILFAST_TRANSPORT)
#define REQ_FAILFAST_DRIVER (1ULL << __REQ_FAILFAST_DRIVER)
#define REQ_SYNC (1ULL << __REQ_SYNC)
#define REQ_META (1ULL << __REQ_META)
#define REQ_PRIO (1ULL << __REQ_PRIO)
#define REQ_NOMERGE (1ULL << __REQ_NOMERGE)
#define REQ_IDLE (1ULL << __REQ_IDLE)
#define REQ_INTEGRITY (1ULL << __REQ_INTEGRITY)
#define REQ_FUA (1ULL << __REQ_FUA)
#define REQ_PREFLUSH (1ULL << __REQ_PREFLUSH)
#define REQ_RAHEAD (1ULL << __REQ_RAHEAD)
#define REQ_BACKGROUND (1ULL << __REQ_BACKGROUND)
#define REQ_NOWAIT (1ULL << __REQ_NOWAIT)
#define REQ_NOUNMAP (1ULL << __REQ_NOUNMAP)
#define REQ_HIPRI (1ULL << __REQ_HIPRI)
#define REQ_DRV (1ULL << __REQ_DRV)
#define REQ_SWAP (1ULL << __REQ_SWAP)
#define REQ_FAILFAST_MASK \
(REQ_FAILFAST_DEV | REQ_FAILFAST_TRANSPORT | REQ_FAILFAST_DRIVER)
#define REQ_NOMERGE_FLAGS \
(REQ_NOMERGE | REQ_PREFLUSH | REQ_FUA)
1.4 bio_vec
bio_vec描述指定page中的一块连续的区域,在bio中描述的就是一个page中的一个"段"(segment)。
bio_vec定义在include/linux/bvec.h:
/*
* was unsigned short, but we might as well be ready for > 64kB I/O pages
*/
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
};
其部分参数含义如下:
- bv_page:指向段在页框描述符的指针;
- bv_len:段的字节长度;
- bv_offset:页框中数据的偏移量;
从上面几个参数,我们不难猜出bio段就是描述所有读或写的数据在内存中的位置。
1.5 bvec_iter
用于记录当前bio_vec被处理的情况,用于遍历bio,定义在include/linux/bvec.h:
struct bvec_iter {
sector_t bi_sector; /* device address in 512 byte
sectors */
unsigned int bi_size; /* residual I/O count */
unsigned int bi_idx; /* current index into bvl_vec */
unsigned int bi_bvec_done; /* number of bytes completed in
current bvec */
};
其部分参数含义如下:
- bi_sector:I/O 请求的块设备起始扇区(每个扇区512 字节);
- bi_size:待传输的字节大小;
- bi_idx:bio_vec中当前索引,遍历bio_vec使用;
- bi_bvec_done:当前 bio_vec中已经处理完成的字节数,比那里bio_vec使用;
1.6 request_queue、request、bio关系结构图
下面用一副关系图来描述 request_queue、request、bio之间的一个关系:
在上图中我们可以看到:
- 每一个块设备都对应一个通用磁盘gendick结构;
- 每一个gendisk都有一个工作队列request_queue,保存着若干个准备就绪的request;
- 每一个request代表着块设备可以处理的一次任务单元,一个request由一个bio或者多个扇区相连的bio组成;
- bio代表了一次I/O请求,代表一个块设备的一个扇区或者多个连续扇区的数据请求,扇区是块设备的最小访问单元,bio是文件系统发给Block Layer(块设备层)的,至于系统调用(sys_read、sys_write)到bio的生成过程不在我们这一节的讨论范围内,有兴趣的可以参考IO子系统全流程介绍;
- 每个进程有新的bio到来时:
- 会先检查能不能合并到当前进程plug list里面的某个request中;
- 如果定义了I/O调度器,然后检查能不能合并到I/O调度器队列的某个request中;
- 如果没有定义I/O调度器,然后检查能不能合并到请求队列的某个request中;
- 如果可以就不必申请新的request了,只需要在已经存在的request.bio链表上新增成员就可以了,具体是放在链表头,还是链表尾取决于磁盘的相对位置;如果不行再变成request,然后放到plug list中;然后在等待特定时机释放plug list中的request到I/O调度器,这样可以提高bio处理的效率(如果没有plug,那么每个进程在将request放到请求队列时就会竞争request_queue的锁,有个plug list之后,就可以等到当前进程堆积到一定量的request时再推送到请求队列,就可以一定程度上减少锁的竞争次数);
- I/O调度器会在内部创建自定义的各种队列来存放plug list释放出来的request,然后I/O调度器对这个所有的request进行一个调度,按照特定的规则再分发给request_queue,让块设备处理;同时有了I/O调度器,我们就可以实现所有request的重新排序甚至合并,还可以对不同进程的request进行不同的优先级控制,目前linux支持的scheduler有:CFQ,deadline、Noop等;
注:两个bio描述了一段连续的磁盘空间,如果两个bio在磁盘物理地址正好是相邻的,组合起来也刚好是一段连续的磁盘空间,对于这种情况实际上也只需要给磁盘发送一次请求就够了,不需要将两个bio分别单独发给磁盘,因此可以将这两个bio合并为一个request,相邻的bio通过bio.bi_next构建成一个链表,request.bio记录链表头,request.biotail记录链表尾;
我们对物理存储设备的操作不外乎就是将RAM中的数据写入到物理存储设备,或者将物理存储设备中的数据读取到RAM中去处理。
- 数据传输三个要求:数据源、数据长度以及数据目的地,就是你要从物理存储设备的哪个地址开始读取、读取到 RAM 中的哪个地址处、读取的数据长度是多少。
- bi_iter这个结构体成员变量就是用于描述物理存储设备的地址信息,比如要操作的扇区地址。
- bi_io_vec指向 bio_vec数组首地址,bio_vec数组就是内存信息,比如页地址、页偏移以及长度。
一个bio可能有多个bio_vec(bio段),这些bio段可能在内存上不连续(位于不同的页),但它们在磁盘上对应的位置时连续的;因此我们可以推断出,具体包含多少个bio段取决于物理存储设备这一段连续的磁盘空间映射了多少个不连续的内存空间,一般上层构建bio的时候都是只有一个bio段。
在块I/O操作期间bio的内容一直保持更新,例如,块设备驱动在一次分散聚集DMA操作中不能一次完成全部数据的传送,那么bio的bi_iter.bi_idx就会更新来指向待传送的第一个bio段。
二、Multi-Queue Block IO Queueing Mechanism (blk-mq)
2.1 blk-sq框架
Linux上传统的块设备层(Block Layer)和IO调度器(如完全公平算法)主要是针对HDD(hard disk drivers)设计的。我们知道,HDD设备的随机IO性能很差,吞吐量大约是几百IOPS(IOs per second),延迟在毫秒级,所以当时IO性能的瓶颈在硬件,而不是内核。
Linux上传统块设备使用单队列blk-sq(block simple queue)架构,如图所示:
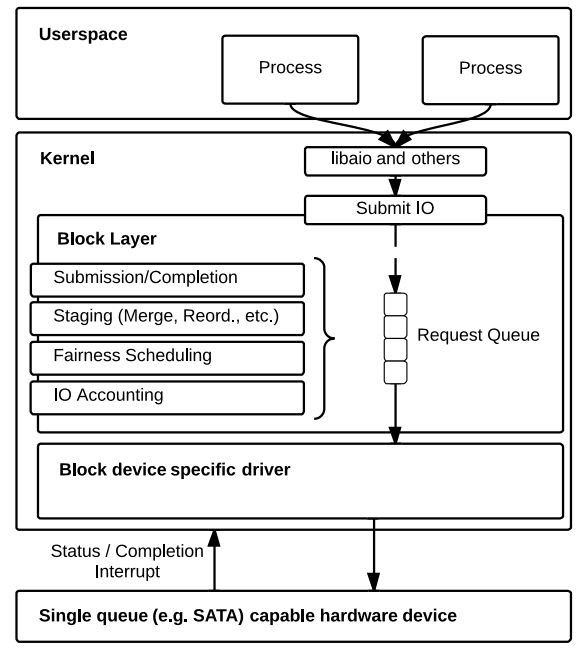
简单来说,块设备层负责管理从用户进程到存储设备的I/O请求,一方面为上层提供访问不同存储设备的统一接口,隐藏存储设备的复杂性和多样性;另一方面,为存储设备驱动程序提供通用服务,让这些驱动程序以最适合的方式接收来自上层的I/O请求。Linux Block Layer主要提供以下几个方面的功能:
- bio的提交和完成处理,上层通过bio来描述单一的块设备I/O请求;
- bio会被合并或者直接转换为request请求;
- request请求合并、排序等;
- I/O调度:如预期算法、最后期限算法、完全公平算法等;
- I/O记账:I/O记账,如统计提交到块设备的I/O总量,I/O延迟等信息;
由于采用单队列(每个块设备1个请求队列)的设计,传统的Block Layer对多核体系的可扩展性(scalability)不佳。
随着高速SSD(Solid State Disk)和没有机械部件的非易失性存储器的发展,支持硬件多队列的存储器件越来越常见(比如NVMe SSD),可以高并发随机随机访问, 百万级甚至千万级IOPS的数据访问已成为一大趋势,传统的块设备层已无法满足这么高的IOPS需求,逐渐成为系统IO性能的瓶颈。多核体系中blk-sq的软件开销主要来自三个方面:
- 请求队列锁竞争:blk-sq使用spinlock(q->queue_lock)来同步对请求队列的访问,每次调度器队列中插入或删除ruquest请求,必须先获取此锁;request排序和调度操作时,也必须先获取此锁。这一系列操作继续之前,必须先获得请求队列锁,在高IOPS场景(多个线程同时提交I/O请求)下,势必引起剧烈的锁竞争,带来不可忽视的软件开销;
- 硬件中断:高的IOPS意味着高的中断数量。在多数情况下,完成一次I/O需要两次中断,一次是存储器件触发的硬件中断,另一次是IPI核间中断用于触发其他CPU上的软中断。
- 远端内存访问:如果提交I/O请求的CPU不是接收硬件中断的CPU且这两个CPU没有共享缓存,那么获取请求队列锁的过程中还存在远端内存访问问题;
为了适配现代存设备(高速SSD等)高IOPS、低延迟的I/O特征,新的块设备层框架Block multi-queue(blk-mq)应运而生。
2.2 blk-mq框架
多队列blk-mq队列框架如下:

blk-mq中使用了两层队列,将单个请求队列锁的竞争分散到多个队列中,极大的提高了Block Layer并发处理IO的能力。两层队列的设计分工明确:
- 软件队列(对应内核struct blk_mq_ctx数据结构):blk-mq中为每个CPU分配一个软件队列(soft context dispatch queue),由于每个CPU有单独的队列,所以每个CPU上的这些I/O操作可以同时进行(需要注意的是:同一个CPU中的进程间依然存在锁竞争的问题),而不存在锁竞争问题;
- 硬件队列(对应内核struct blk_mq_hw_ctx数据结构,更准确的说是硬件派发队列):blk-mq为存储器件的每个硬件队列(目前多数存储器件只有1个)分配一个硬件派发队列(hard context dispatch queue),负责存放软件队列往这个硬件队列派发的I/O请求。在存储设备驱动初始化时,blk-mq会通过固定的映射关系将一个或多个软件队列映射(map)到一个硬件派发队列(同时保证映射到每个硬件队列的软件队列数量基本一致),之后这些软件队列上的I/O请求会往存储器件对应的硬件队列上派发。
blk-mq架构解决了blk-sq架构中请求队列锁竞争和远端内存访问问题,极大的提高了Block Layer的IOPS吞吐量。
2.3 I/O队列流程图
当进程对块设备进行读写操作时,系统调用经过文件系统会生成bio,所有的bio都由submit_bio函数提交到Block Layer,bio的处理大致经过以下队列(下图只是一个示意图,reqeust的分发流程还要结合具体情境分析,比如:request也有可能直接派发到块设备驱动层):
注:值得注意的是在2013年之后的版本中,plug机制已经不能满足硬件需求了,kernel又提供了新的机制来替代它,所以在linux 5.2.8版本中plug并不是必须的,例如sys_read中使用了plug机制,但是sys_write已经不再使用plug机制。具体是否使用取决于代码作者是否在调用submit_bio函数前后调用了blk_start_plug和blk_finish_plug两个函数对struct blk_plug进行初始化;
2.3.1 进程私有的plug list
队列中存放的是request,引入这个缓冲队列的目的是为了性能。进程提交一个bio后,短时间类很可能还会有新的bio,这些bio变成request后被暂存在plug list中,因为这个队列只有本进程能操作,所以不用加锁就可以进行bio merge操作。
2.3.2 调度器队列
multi-queue的调度器有mq-deadline、bfq、kyber。每个调度器有都实现了专门的数据结构管理(链表、红黑树等),这里统以elevator queus称呼。
系统中的调度器队列可能有很多,调度器需要决定先处理哪个队列以及队列中的哪个request。
2.3.3 blk_mq_ctx软件队列
对于multi-queue,linux内核将blk_mq_ctx定义为per_cpu变量,每个request仅可以加到本cpu的blk_mq_ctx链表上。
在另一方面,