linux IO Block layer 解析
早期的 Block 框架是单队列(single-queue)架构,适用于“硬件单队列”的存储设备(比如机械磁盘),随着存储器件技术的发展,支持“硬件多队列”的存储器件越来越常见(比如 NVMe SSD),传统的单队列架构也因此被改成了多队列(multi-queue)架构。早在 3.13 内核就已经加入了多队列代码,但是还不太稳定,经过多年的发展 multi-queue 越来越稳定,linux 5.0+ 已经默认使用 multi-queue。本篇文章介绍 Block 层框架及调度器相关知识,让读者对 Block 层有一个宏观的认识。
一、Block 层的作用
用户发起读写操作时,并不是直接操作存储设备,而是需要经过较长的 IO 栈才能完成数据的读写。读写操作大体上需依次经过虚拟文件系统 vfs、磁盘文件系统、block 层、设备驱动层,最后到达存储器件,器件处理完成后发送中断通知驱动程序,流程见图 1。
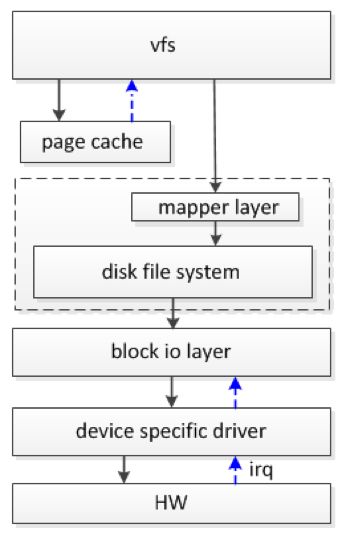
图1 IO 栈
备注:page cache 机制用来提高性能。在内存资源不紧张的情况下,用户访问过的数据不会被丢弃,而是缓存在内存中,下次可以访问快速的内存中数据,无需访问慢速的存储设备。mapper layer 用来将用户操作文件偏移量转换成磁盘文件系统的 block 偏移量。
Block 层连接着文件系统层和设备驱动层,从 submit_bio 开始,bio 就进入了 block 层,这些 bio 被 Block 层抽象成 request 管理,在适当的时候这些 request 离开 Block 层进入设备驱动层。IO 请求完成后,Block 层的软中断负责处理 IO 完成后的工作。Block 层主要负责:
管理 IO 请求
IO 请求暂存、合并,以及决定以何种顺序处理IO请求。这里面涉及到 single-queue、multi-queue 框架以及具体的 IO 调度器。
IO 统计
主要是task io accounting统计各个进程的读写情况,统计信息见struct task_io_accounting。
注意,虽然 Block 层中存放着很多的 request,但正常情况下 Block 层不会主动“下发” request 给设备驱动程序(在线切换 IO 调度器、存储器件 offline 场景会主动下发 request)。当设备空闲时,设备驱动程序从 Block 层的“分发队列”头部依次取 request 进行处理,设备驱动程序拿到 request 后,根据 request 中的信息及器件协议生成 cmd 命令交由器件处理。
二、Block 框架演变
Block 层软件设计与存储器件的特性紧密相关,大致经历了 2 个阶段。
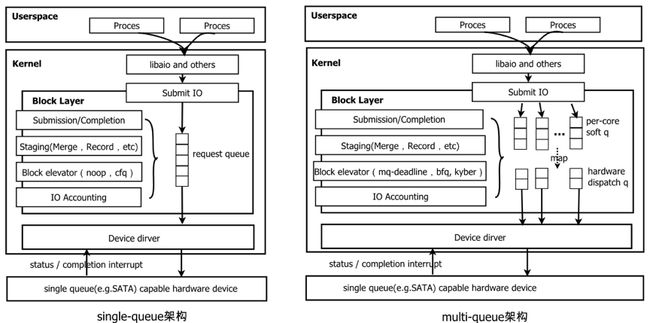
图2 single-queue与multi-queue 架构
*引用自Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
single-queue 框架
早期的存储设备是磁盘,特点是机械运动寻址、且不支持多硬件队列并发处理 io,所以代码逻辑自然地设计了一个软件分发队列,这种软件逻辑上只有一个分发队列的架构称作 single-queue 架构,由于软件本身的开销(多核访问 request queue 需要获取 request_queue->queue_lock 等原因),single-queue 的 IOPS 能达到百万到千万级别的数据量,由于早期存储器件速度慢,百万的 IOPS 已经完全能够满足需求。
multi-queue 架构
当支持多队列的高速存储器件出现后,器件端处理的时间变短,single-queue 引入的软件开销变得突出,软件成为性能瓶颈,导致性能瓶颈的因素有 3 个:
1) 所有 cpu 共享一个 request queue,对 request_queue->queue_lock 的竞争比较多。
2) 大多数情况下,完成一次 io 需要两次中断,一个是硬件中断,一个是 IPI 核间中断用于触发其他 cpu 上的软中断。
3) 如果提交 io 请求的 cpu 不是接收到硬件中断的 cpu,还存在远端内存访问的问题。
Jens Axboe(block maintainer) 针对 single-queue 存在的问题,提出了 multi-queue 架构,这种架构为每个 cpu 分配一个软件队列(称为 soft context dispatch q),又根据存储器件的硬件队列(hardware q)数量分配了相同数量的硬件上下文分发队列(hard context dispatch q,这是软件逻辑上的队列),通过固定的映射关系,将 1 个或多个 soft context dispatch q 映射到 1 个 hard context dispatch q,再将 hard context dispatch q 与存储器件的 hardware q 一一对应起来,达到并发处理的效果,提升 IO 性能。
三、数据结构
相关的数据结构可以分成两大类,一是 IO 请求本身,二是管理 IO 请求用到的队列,理解这些数据结构是了解 block 层设计逻辑的基础,数据结构描述如下。
1. IO 请求
按照 IO 请求的生命周期,IO 请求被抽象成了 bio、request(简称 rq)、cmd,见图 3。访问存储器件上相邻区域的 bio、request 可能会被合并,称为 bio merge、request merge。若 bio 的长度超过软件或者硬件的限制,bio 会被拆分成多个,称为 bio split。Block 层接收到一个 bio 后,这个 bio 将生成一个新的 request,或者合并到已有的 request 中。图 3 中 bio2 被拆分,bio3、bio4 合并到一个 request 中。

图3 IO 请求的生命周期
bio 是描述 io 请求的最小单位,bio 描述了数据的位置属性,表示为:
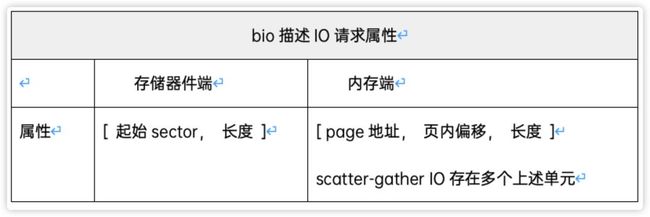
表1 bio结构体说明
POSIX标准定义了scatter-gather I/O,这种IO通过一个读/写系统调用可以往多个不连续的内存段中读/写,从而提高IO性能并且能确保访问多段内存的原子性。linux系统调用readv、writev支持scatter-gather I/O,所以bio的内存端需用多个[ page地址, 页内偏移, 长度 ]描述不连续的内存段,每一个[ page地址, 页内偏移, 长度 ]在linux中称为bio_vector。bio结构体的示意图见下图。
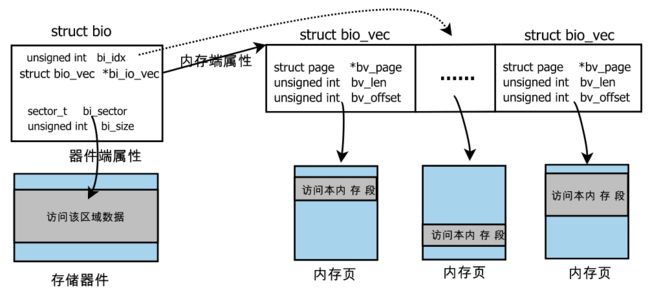
图4 bio 结构体示意图
request是IO调度的最小单位,多个bio访问存储器件上相邻的区域数据并且是同种类型的(读/写),则会被合并到一个request中,所以一个request可能包含多个bio。系统中request数量是有限制的,不是无限多的,否则当io请求太多,而存储器件来不及处理时,就会出现struct request结构体占用太多内存的情况。
在single-queue中用rq资源池管理request的申请释放,一个存储器件的读写请求数量各自限制最多q->nr_requests个(默认的q->nr_requests = BLKDEV_MAX_RQ = 128)。当该器件上待处理的读或写请求数超过![]() =7/8 * q->nr_requests时进入拥塞状态,此时会限制新生成request的速度。比如读请求拥塞时,page_cache_async_readahead函数中关闭预读功能以较少新生成的request。当存储器件待处理读或写的request比
=7/8 * q->nr_requests时进入拥塞状态,此时会限制新生成request的速度。比如读请求拥塞时,page_cache_async_readahead函数中关闭预读功能以较少新生成的request。当存储器件待处理读或写的request比![]() 低时退出拥塞状态。以默认q->nr_requests = 128个请求为例:
低时退出拥塞状态。以默认q->nr_requests = 128个请求为例:

图5 single-queue request 数量管理
在multi-queue中,没有上述的congestion state逻辑,因为multi-queue用于支持多硬件队列存储器件的场景(当然也可以用于单硬件队列的存储器件),这些存储器件的速度很快,不需要过多考虑器件处理慢的问题(但是也不能一味地任由rqeuest增长)。在multi-queue中request最大数量与调度器的tag数量有关,同single-queue一样,默认值也是q->nr_requests = BLKDEV_MAX_RQ = 128,当存储器件待处理的读/写超过调度器tag数量时,申请rq的task睡眠,当有rq处理完成被释放后,再唤醒当前的task。默认的调度器tag数量可以通过sysfs接口修改,内核里通过blk_mq_update_nr_requests更新。
cmd是设备驱动处理的IO请求,设备驱动程序根据器件协议,将request转换成cmd,然后发送给器件处理。cmd已经不属于block层管理了,所以这篇文章不做描述。
2.IO队列
上面的IO请求需要经过多级缓冲队列管理,见图6。
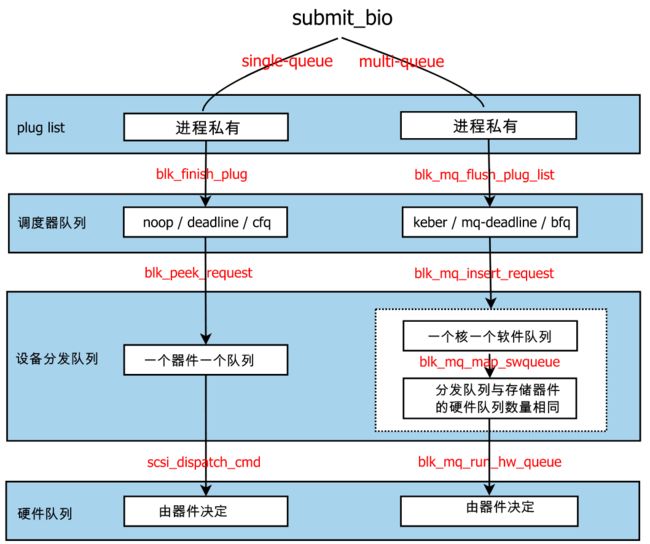
图6 IO队列
注:multi-queue如果器件支持hardware multi q,plug list功能关闭
所有的bio都由submit_bio提交到block层,bio依次经过下面队列:
进程私有的plug list
队列中存放的是io请求(rq),引入这个缓冲队列的目的是为了性能。进程提交一个bio后,短时间类很可能还会有新的bio,这些bio被暂存在plug list中,因为这个队列只有本进程能操作,所以不用加锁就可以进行bio merge操作(在后面提到的调度器队列中做merge需要加锁)。
调度器队列elevator q
队列中存放的是io请求(rq)。single-queue的调度器有noop、cfq;multi-queue的调度器有mq-deadline、bfq、kyber。每个调度器有都实现了专门的数据结构管理rq(链表、红黑树等),这里统以elevator q称呼。
系统中的调度器队列可能有很多,比如cfq为每个进程维护各自的同步请求队列,又为所有进程维护了公用的异步请求队列。调度器需要决定先处理哪个队列以及队列中的哪个rq。一般情况下,调度器不会主动将rq移到设备分发队列中,而是由设备驱动程序主动来取rq。
设备分发队列device dispatch q(也可以称作hardware dispatch q)
这是软件实现的队列。存储器件空闲时,其设备驱动程序主动从调度器中拉取一个rq存在设备分发队列中,分发队列中的rq按照先进先出顺序被封装成cmd下发给器件。
对于multi-queue,设备分发队列包中还额外包含per-core软件队列,它是为硬件分发队列服务的,可以把它理解成设备分发队列中的一部分。
硬件队列HW q
队列中存放的是按器件协议封装的cmd,一些器件是单HW队列,比如UFS内部是一个队列深度为32的HW q,NVMe SSD最大支持的队列数量为64K、队列深度64K。
四、常用调度器
single-queue用到的调度器有noop,deadline,cfq。
multi-queue用到的调度器有none(类似于noop),mq-deadline(类似于deadline),bfq(类似于cfq),kyber。这里选取几个具有代表意义的调度器对比分析。
noop调度器
最简单的调度器,IO请求放入一个FIFO队列,逐个执行这些IO请求(rq)。
noop调度器基本上对rq不做额外,仅仅在将rq插入到调度器队列时,将rq与已有的rq做前向、后向合并(2个rq的sector连续)。从调度器队列中发送一个rq给设备驱动程序代码如下:

cfq调度器(Completely Fair Queuing)
CFQ公平对待每个进程,给每个进程分配相同的“虚拟”时间片,在时间片内进程可以访问存储器件,时间片用完后,选择下一个进程运行。
1)cfq支持“优先级”策略
“虚拟”时间片 = 实际访问存储设备时间*优先级系数,优先级越高实际获得的时间片越长,优先级越低实际获得的时间片越短。
cfqq用完时间片后,通过cfq_resor_rr_list调整cfqq在红黑树中的位置,由于红黑树key值rb_key近似等于jiffies,所以cfqq近似于按照round-roubin执行,代码如下。
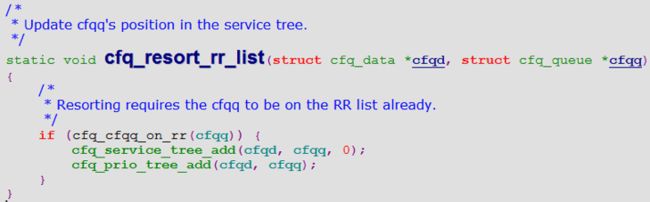


图7 cfqq round-roubin策略
2)cfq支持“权重策略”
多个cfqq可以归属于一个group,这些group按照占用存储设备的时长(cfq中称作vdisktime)组织在红黑树中。当group被调度运行结束后,cfq_group_served更新group 的vdisktime(vdisktime增长量=实际占用disk时间*权重系数),权重越高vdisktime增长的越慢,权重越低vdisktime增长的越快。
cfq优先选择vdisktime小的group执行,所以权重越大,group被调度的越频繁。
cfq_group_served更新vdisktime的代码如下:
vfr表示在group与其他group构成的父group中,group在父group中的权重占比。
cfqg_scale_charge将group使用存储设备的时长(以charge表示)做个虚拟转换,本质上等价于cfqg->vdisktime = charge / vfr

bfq调度器(Budget Fair Queuing)
bfq从cfq演变过来,大部分代码也借鉴cfq的。cfq在各个进程间平分存储器件时间来达到公平,这样做是有问题的,一个随机访问存储设备的进程与一个顺序访问存储设备的进程,虽然占用存储器件的时间是一样的,但二者访问的数据量有很大差距,难以保证公平。
bfq通过budget(就是block sector)确保公平,不管进程占用了存储设备多长时间,只管进程访问存储设备的数据量。
bfq的这种思想带来了一个优势,即提高了交互式进程的响应性。因为交互式进程每次IO的数据量很少,而batch类进程数据量很大,为了确保budget公平(访问相同数量的block sector),必须频繁调度交互式进程运行,从而提高了交互式进程的响应性。
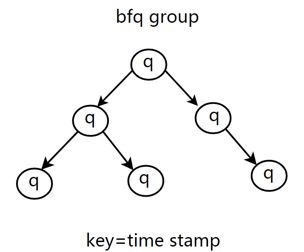
图8 bfqq红黑树
bfq同cfq一样,也为每个进程分配一个队列称作bfqq,通过时间戳维护在红黑树中(cfq是通过vdisktime维护在红黑树中)。与cfqq轮询机制不同,bfqq红黑树中只有eligible状态的bfqq才会被选择调度。我们定义如下变量:


与cfqq权重的作用不一样,cfqq中权重越大时间片越长,但bfqq中权重与时间片无关,与调度频率有关,假设有3个进程P1~P3,每次访问100个budget,权重比例P1:P2:P3 = 2:1:1,bfqq执行效果如下(绿色表示eligible,灰色表示不可选):
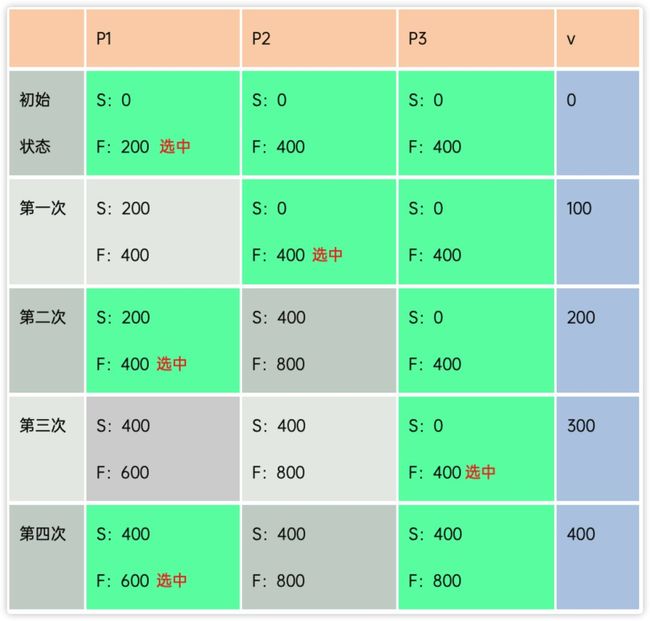
表2 bffq调度
从上面执行步骤可以看出,P权重占比50%,第一次到第三次下来,P1执行2次,P2、P3累计执行2次,执行的频率与各进程的权重占比相等。
以上3个调度器的差异对比如下:

表3 noop/cfq/bfq对比
五、总结
Block主要涉及框架和调度器两部分,都是为了吞吐量合IO响应性设计的。框架代码与存储器件紧密相关,从慢速的存储设备到高速的存储设备,Block框架变成了multi-queue架构,软件、硬件的紧密结合才能把存储器件性能发挥到最大,期待未来新存储器件的出现,将存储性能再提高一个级别。调度器也越来越智能,能够兼顾交互进程的响应性和batch类进程的吞吐量,用户体验在Block新框架、新调度器的支持下将会越来越好。
参考资料
[1] Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
[2] https://kernelnewbies.org/Linux_5.0#Block_layer
 扫描关注
扫描关注
“内核工匠”微信公众号
Linux 内核黑科技 | 技术文章 | 精选教程