高德Go生态建设与研发实践
序
高德在构建Go生态演化过程中,已经实现了QPS从0到峰值千万的飞跃,本篇文章主要介绍在此过程中积累的一些技术决策及性能优化和重构经验。阅读本文读者会有以下3点收获:
1.高德Go生态发展历程及现状分析
2.高德云原生Serverless落地情况&实战
3.高德Go生态项目落地实战( 重构&优化经验 )
一、高德Go生态发展历程及现状分析
为什么要用Go语言开发服务,说起来有些复杂,很多时候语言都不是问题,每种语言都有适应自己的场景和能够充分发挥优势的环境, 每种语言几乎都统治了一个领域或者一段时间。
高德在用Go之前也有Python、PHP、Java、C&C++等服务,接下来我会根据下面大纲来描述为什么高德服务端选择Go来做服务并简单介绍Go生态,而不是继续沿用Java,或者用Python以及新生态语言Rust等,也会从GC、内存模型和并发模型上进行剖析,了解底层原理。
本节大纲:
1.1 云原生生态适应的架构是什么
1.2 天然契合云原生架构的语言
1.3 Java和Go底层原理&云原生匹配度
1.4 Go和ErLang的并发模型区别&选择
1.5 高德Go生态衍生的中间件
1.6 Go的生态介绍
1.1 云原生生态适应的架构是什么
谈到为什么选择,首先交代下当下环境,在云原生架构时代,大家都在上云,互联网也从单体架构->分布式架构->微服务架构( 也包含宏服务 )->云原生架构。
云原生架构这个话题很大,云原生在近一两年让互联网达到了一个新的时代,大家也达成了共识,一起共建云原生基础设施。遵从以下6个特质和4个要点来考量云原生中间件,总结下来就是围绕“稳定、效率、成本”3个点。
6个特质:模块化、可观察、可部署、可测试、可替换、可处理
4个要点:DevOps、持续交付、微服务、容器
先来剖析特质,然后围绕着特质总结下云原生架构要点。
首先,云原生架构是由微服务架构衍生转化,其一定具备微服务的特性,微服务的2大核心特性为:服务单一、模块化。
这两个特性都是来约束微服务要足够小,且是无状态服务,这样在分布式并发场景下,才会游刃有余。
其次,服务具备弹性分布也是不够的,在整个服务的生命周期来看,部署也是运维一大头疼问题,解决部署之后,又要面临决策,什么时候部署,如何部署,这些问题其实也是在质问我们,你的“可观性”做的如何,可观性是相当于给服务做CT一样,直接剖析出服务的问题。
最后当你给服务做CT发现问题后又需要对症下药。一系列操作之后,最终完成部署上线,其实整个操作都在围绕云原生部署的视角,也就是上面4个要点。
1.2 天然契合云原生架构的语言
通过云原生架构内容理解,其实云原生根本没有限制用什么语言,反而还鼓励在对应的生态环境中可以用任何语言。比如现在有很多大家常见的语言。
Rust:视内存&安全如命的语言
Go:自称“很快”的语言
Java:生态圈及其庞大的语言
Python:一个掌控AI&机器学习生态的语言
...
这里没有列出Nodejs和PHP不是不好,而是这两个语言大众都非常了解。一个统治前端,一个曾经统治后端(脑海里还记得曾经那句“PHP是世界上最好的语言”)。
上面的语言简介只是形容优势,不是划定界限,Python在Server端也有很多优秀的框架,Java也可以做大数据等等。下面我们针对罗列的语言简单描述为什么适合云原生。
谈到Rust其实还是有点让人胆怯的,Rust刨除学习成本和编码成本高的前提下,它其实很适合云原生,体积小,内存安全还有很多优秀的异步网络库使得Rust安全、性能又高。强制执行Rall的机制+所有权牢牢把控内存的安全,在云原生共享资源的前提下也提高了安全性,如果再加上Tee架构简直是完美的机制。这也是为什么现在新生区块链项目很多都会选择Rust的初因。
这里简单描述下Rall和Rust如何解决内存安全的。
Rust的RAll(RAII要求,资源的有效期与持有资源的对象的生命周期严格绑定,即由对象的构造函数完成资源的分配「获取」,同时由析构函数完成资源的释放。在这种要求下,只要对象能正确地析构,就不会出现资源泄露问题)。
Rust中分配的每块内存都有其所有者,所有者负责该内存的释放和读写权限,并且每次每个值只能有唯一的所有者
引用(Reference)是Rust 提供的一种指针语义( 这里也可以称为借用,可变和不可变借用有前后要求限制 )。
Rust是如何解决内存安全问题的?
使用未定义内存
Rust中的变量必须初始化以后才可使用,否则无法通过编译器检查。
空指针
开发者没有任何办法去创建一个空指针。Rust中使用Option类型来代替空指针,Option实际是枚举体,包含两个值:Some(T)和None,分别代表两种情况,有和无。这就迫使开发者必须对这两种情况都做处理,以保证内存安全。
悬空指针
悬空指针指的是内存空间在被释放了之后,继续使用。Rust通过所有权和借用机制解决这个问题。
缓冲区溢出
Rust编译器在编译期就能检查出数组越界的问题,从而完美地避免了缓冲区溢出。
非法释放未分配的指针或已经释放过的指针
Rust中不会出现未分配的指针,所以也不存在非法释放的情况。同时,Rust的所有权机制严格地保证了析构函数只会调用一次,所以也不会出现非法释放已释放内存的情况。
通过以上内容+Rall+所有权相关机制,使得Rust内存变得很安全,但是Rust这种机制也起到反作用,有些场景在生命周期短引导下依然是被编译器认为不合法的,需要Unsafe来实现。整个项目代码写起来非常的复杂繁琐,很多人也是学着学着就被Rust给成功劝退了。但是当你掌控Rust之后,你会发现Rust在某些场景下的实现会变得更加简单。
再看Go语言, Go语言发展至今已经迭代过很多版本了,由单纯的MG模型进化为PMG模型,栈也从连续栈变成了拷贝栈,现在申请的内存也会慢慢的归还给操作系统,整体来说没毛病,以动态语言的方式写静态语言,也实现了Runtime帮大家管理GC和内存相关事宜,简直是保姆级别的语言了。很多初学者可以快速上手,以前那些潮流语言(PHP)也可以快速转到Go语言上。
说到Java,其实有点不太敢说,因为公司是主Java技术栈,而且Java的生态很大很全,公司还有很多Java的性能优化与JVM层面的优化来保证Java更加稳定,性能更加好。但是有些基因是语言天生的,就冷启动慢这个问题在云原生高并发服务的场景就不适合。
最后再看下Python吧,这里就简单描述一句,环境真是让人头疼要命,一个全局虚拟机锁(注:这里不叫锁,Python虚拟机约束全局只能有一个控制线程在执行)导致不适合做Server,但是在机器学习和AI领域中确实大放光彩。
说了这么多不太相关的内容其实就是想说明,云原生不会要求大家必须用什么语言,只会告诉大家合理的利用语言,其实我倒是觉得云原生大部分提到的都是微服务+容器的架构,或者是在加上弹性扩容后的Serverless架构。
1.3 Java和Go底层原理&云原生匹配度
1.3.1 GC层面来:
Java的GC迭代
Serial GC:完全串行的标记和整理过程,需要暂停整个程序。
ParNew GC:多线程Serial GC。
CMS (Concurrent Mark Sleep) GC:标记清理算法,并发标记。三色标记法由此开始。
G1 GC:DK9之后的默认GC。它可以设定停顿时间,将最差情况得到一定的改善(引入Region的概念)。
ZGC:ZGC主要新增了两项技术,一个是着色指针Colored Pointer,另一个是读屏障 Load Barrier,还实现了动态Region (ZGC仅支持 64 位平台)。
Go的GC也经历了很多版本的进化。
Go 1.0:完全串行的标记和清除过程,需要暂停整个程序。
Go 1.1:在多核主机并行执行垃圾收集的标记和清除阶段。
Go 1.3:运行时基于只有指针类型的值包含指针的假设,增加了对栈内存的精确扫描支持,实现了真正精确的垃圾收集;将unsafe.Pointer 类型转换成整数类型的值认定为不合法的,可能会造成悬挂指针等严重问题。
Go 1.5:实现了基于三色标记清扫的并发垃圾收集器;大幅度降低垃圾收集的延迟从几百ms降低至10ms以下;计算垃圾收集启动的合适时间并通过并发加速垃圾收集的过程。
Go 1.6:实现了去中心化的垃圾收集协调器;基于显式的状态机使得任意Goroutine都能触发垃圾收集的状态迁移;使用密集的位图替代空闲链表表示的堆内存,降低清除阶段的CPU占用。
Go 1.7:通过并行栈收缩将垃圾收集的时间缩短至2ms以内。
Go 1.8:使用混合写屏障将垃圾收集的时间缩短至0.5ms以内(转折点,停顿由全局变换成了栈GC扫描)。
Go 1.9 :彻底移除暂停程序的重新扫描栈的过程。
Go 1.10:更新了垃圾收集调频器(Pacer)的实现,分离软硬堆大小的目标。
Go 1.12 :使用新的标记终止算法简化垃圾收集器的几个阶段。
Go 1.13 :通过新的Scavenger解决瞬时内存占用过高的应用程序向操作系统归还内存的问题。
Go 1.14:使用全新的页分配器优化内存分配的速度。
Go 1.15:删除了一些GC元数据和一些无用的元数据;(首尾效率提升,分配效率高)。
Go 1.16:内存分配统计粒度更细、更灵活了。GC效率提升从MS到US。(内存策略也从MADV_FREE改回了MADV_DONTNEED)。
Go 1.17:GC上没有变化,但是在调度上有很大的提升(由原来的栈调度变成了基于寄存器的调度)。
Go 1.18:GC的统计新增了“根对象”扫描。
Go 1.19:GC上没有变化,通过“Soft memory limit”的方式减少GC周期频繁的问题。
Go 1.20:仅对GC的内部数据结构进行了微调,新增Arena
…
从2者GC上看其实本质上相差不大,从早期的标记算法(配备清除和整理)到后面的三色标记法+混合屏障技术都是比较高性能的GC算法,而且2者也都有安全点机制来保证回收过程中内存是安全的。那么本质上用GC做决策的优势不够明显。
1.3.2 内存模型上:
1.3.2.1 Java运行时内存模型:《深入理解Java虚拟机(第2版)》中的描述是下面这个样子的
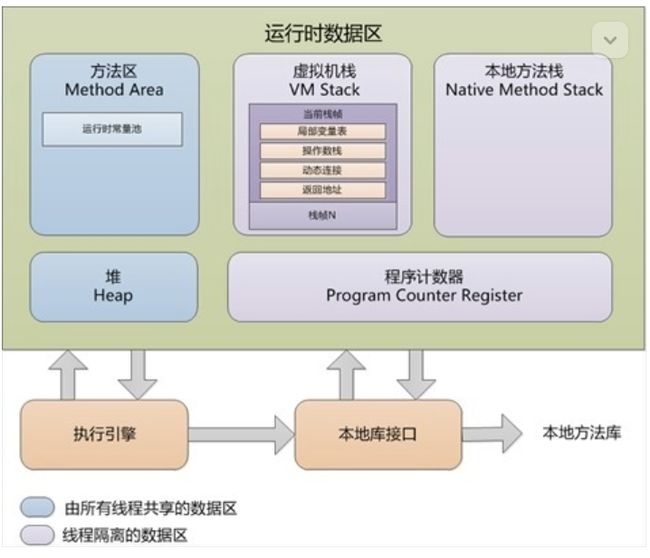
(本图来源于网络)
JVM的内存结构大概分为:
堆(Heap):线程共享。所有的对象实例以及数组都要在堆上分配。回收器主要管理的对象。
方法区(Method Area):线程共享。存储类信息、常量、静态变量、即时编译器编译后的代码。
方法栈(JVM Stack):线程私有。存储局部变量表、操作栈、动态链接、方法出口,对象指针。
本地方法栈(Native Method Stack):线程私有。为虚拟机使用到的Native方法服务。如Java使用C或者C++编写的接口服务时,代码在此区运行。
程序计数器(Program Counter Register):线程私有。有些文章也翻译成PC寄存器(PC Register),同一个东西。它可以看作是当前线程所执行的字节码的行号指示器。指向下一条要执行的指令。
先看一张图,这张图能很清晰的说明JVM内存结构的布局和相应的控制参数:
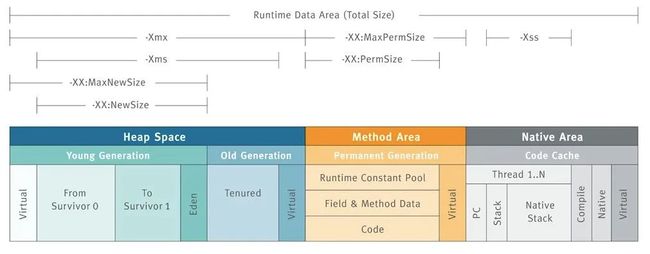
1.3.2.2 GoLang的运行时图解为:
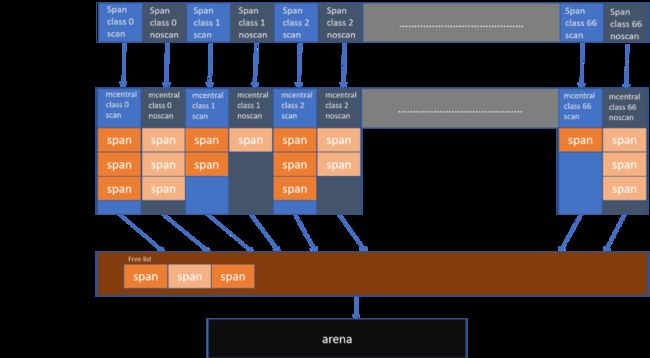
由上图可见区别,Java是由Class为载体,通过加载Class来执行程序,Go则是Span为载体,Object为小单元来进行程序执行,分配对象结构区别如下:
线程初始对象:
Java:1m-8m
Go:1m-8m (线程:2kb,复用线程 )
初始化对象:
Java:Class通过加载机制验证加载
Go:数据结构类型,除引用Interface麻烦,其它类型占用极低
大对象:
Java:老年代分配,需要阈值
Go:直接mheap申请大于32kb的内存
小对象:
Java :线程私有tlab优先,无锁分配
Go:线程私有空间,mcache分配,无锁
内容扩容:
Java:tlab用完直接申请
Go:直接向上级申请,直到成功
分配方式:
Java:指针碰撞 || 空闲链表
Go:空闲链表
内存分配:
Java:划分与对象大小一样的块,内存复用率低,容易引起内存碎片
Go:按照对象大小寻找合适规格的块,内存复用率高,没内存碎片问题,有一定的内存浪费
综上可见Go在Server端开发,资源还是比较节省的,但这也不足以说选择Go就是没问题的。接下来我们看并发模型,通过GC+内存模型+并发模型这3点来支撑我们的决策。
1.3.3 并发模型
首先提出一个问题“并发一定要多线程吗?”。其实不然,有些语言的并发是用多进程+线程来实现的。这里我简单罗列下集中并发的实现方式。
多线程模型:一个进程下,多个线程切换
多进程模型:多个进程下,单个线程 or 多个线程切换
综上总结,无论是多进程还是单进程,都逃脱不了线程这个系统调度的最小单元,那么线程其实也有3种:
1、内核线程:内核线程模型即完全依赖操作系统内核提供的内核线程(Kernel-Level Thread,KLT)来实现多线程。由于内核分用户态和内核态,所以单纯的内存线程需要配置LWP使用。
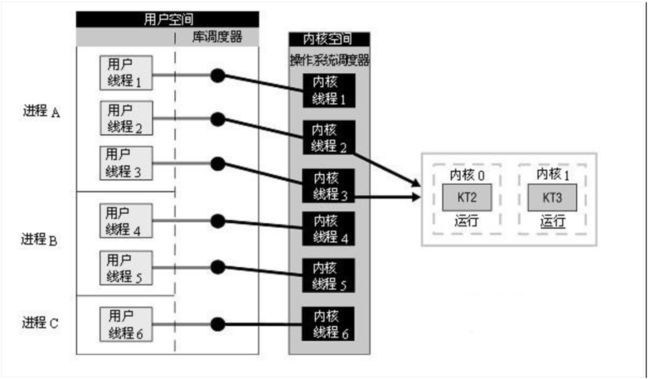
2、用户线程:一个线程只要不是内核线程,就可以认为是用户线程(User Thread,UT)。因此,从这个定义上来讲,轻量级进程也属于用户线程,但轻量级进程的实现始终是建立在内核之上的,许多操作都要进行系统调用,效率会受到限制。

其实这里有个细节。如果完全用UT Thread来实现,就会遇到一个恶心的问题,线程假死。因为他们调度在一个调度器上,相当于伪并发。
3、轻量级进程+用户线程(混合模型):线程除了依赖内核线程实现和完全由用户程序自己实现之外,还有一种将内核线程与用户线程一起使用的实现方式。在这种混合实现下,既存在用户线程,也存在轻量级进程。用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。
而操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级线程来完成,大大降低了整个进程被完全阻塞的风险。在这种混合模式中,用户线程与轻量级进程的数量比是不定的,即为N:M的关系。许多UNIX系列的操作系统,如Solaris、HP-UX等都提供了N:M的线程模型实现。
当然从Java的角度,是Java选择的是混合模型,而且是1对1的模型,大大的依赖操作系统的调度。
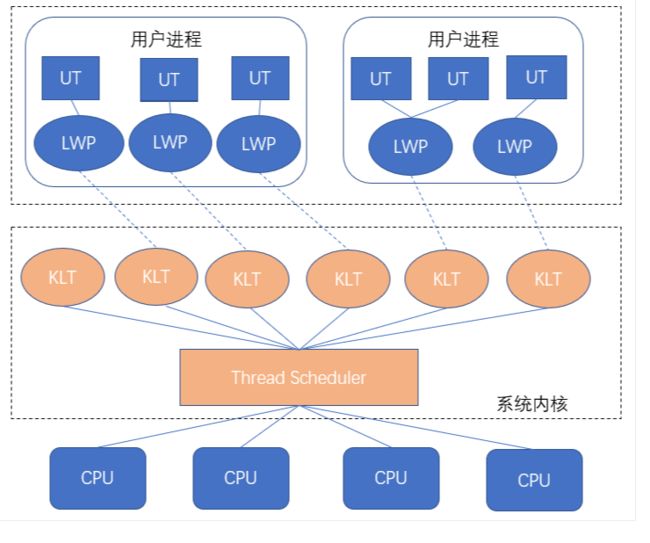
Go实现则不然,但也是类似的M:N模型。Go采用的内核线程+用户线程。因内核感知不到线程状态,故Runtime需要做抢占调度。
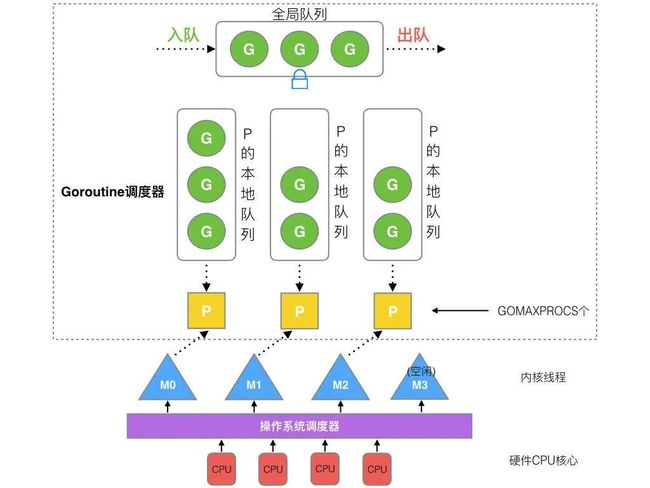
从抽象的角度,Java和Go使用的都是混合式调度,而且选择的都是1:1实现的M:N结构。区别就在于一个JVM管理的由LWP调度的线程。一个是由Runtime管理的协程调度器。初始化栈大小相差数数倍,调度也相差很多。由于初始不用加载Class到内存,Runtime相比JVM也精简了许多。再加上Go执行一个Go Func的成本极低,让Go本身栈扩容和异步变得更加简单轻量,所以调度和执行上就显得快了很多。也就是为什么Java的应用换成Go大部分都会提升很多倍性能。
可能有些读者说这里有考虑到线程池吗?前面说了Go本身创建协程就是语法糖+2kb,不够就销毁新建,瞬时可以创建很多(也会有G溢出的概率),Java相对成本是高一点点,又可能会被问到Reactive Reactor不也可以解决Java并发和吞吐的问题吗。这点我也不否认,Java的响应式架构不比Go差,Go也算是天然的Reactor的语言了,但是Java的响应式门槛很高,不如Go来的轻便。
这里举个调度的例子:当Goroutine有1000,Java的Thread也有1000时,这时不存在新建的场景,为什么Goroutine比Thread快?
首先就Goroutine和Thread来说,切换的成本都差不多的。都是核心的几个寄存器来保存值和恢复(pc&cs:ip...),耗时多的点在于抢占式的线程调度,需要重新计算优先级。
其次从CPU的切换,前面我们也说了都是核心寄存器(PC|BP|SP...等)来保存和恢复,只不过一个是系统Thread,一个是用户态的Goroutine,本质上没有太大的区别。
最后系统级的Thread,是抢占式的。系统的很多中断,都会打断原来的Thread,然后重新计算Thread的优先级,当Thred很多时,就会有很多时间用在计算优先级。
总结:Go因为协程Goroutine的原因,用户态切换成本很少,每个Goroutine 10ms的时间片进行切换,跑在一个Thread上的。系统Thread基本上都是一致跑任务的。但是我们考虑的是3点,从GC+内存+调度这3个角度去分析,这里其实还隐藏了一个点就是贴近云原生的架构。综上所述,我们选择用了Go,大家上手快,写出来的代码只要按照规范和特定的框架就不会出大问题,从效能和降本上收益也很大。
1.4 Go和ErLang的并发模型区别&选择
可能有些心细的小伙伴也会问到,早期还有Erlang这个语言,他在高并发的领域也很出色,当时很多人都拿Erlang和Golang进行对比。这里我说下Erlang号称瞬时创建N多进程(注:Erlang中创建一个进程的开销远远小于在其他语言中创建一个进程。因为Erlang创建进程的过程是在自身虚拟机中实现,底层实现保证了创建进程的快速以及低开销。)这点我觉得也没问题,我们不选择Erlang有这么几点:
学习成本高
会的人太少
…
这里没有提并发模型是因为Go的CSP并发模型和Erlang的Actor有点类似,其实把Erlang看成一个CSP模型也不是不可以(这里对概念较真就不用看成CSP)。
Actor模型和CSP区别图如下:
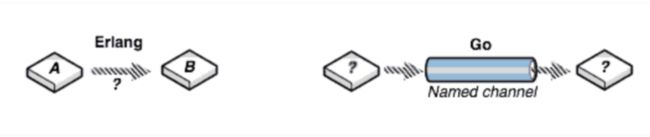
它主要的区别是消息到底由谁来消费, Erlang是a和b通讯,需要确认。Go是Channel消费,无需管理上下游到底是谁,更加松耦合,并发成本更加的低。
1.5 高德Go生态衍生的中间件
其实前期由Java这个完整庞大的社区转到Go这条路上,我们还是走了许多艰辛的路。每当看到“提效,降本,性能”这3个词之后,更加坚持我们的想法,去攻克社区和中间件带来的阻碍。因为服务的特性和基因决定要往前行,于是我们开发了许多中间件和基础库。
我们也会在Go生态中做一些规约,使用【高德技术服务平台】研发支持的中间件客户端,或选用其他来源的组件,需要单独说明理由。
这里约束基础有一个特别重要的点,因编码规范对开发的约束往往很低,只是一个样本和规范,在实施过程中会受到各种阻碍,即使写插件严格控制编码格式也是一样。编码规范要融入骨子里的,针对新鲜血液快速迭代的场景,我们进行了基础库约束,当你使用上述基础库的适合,中间件机制会在中间保证你的代码是符合安全和规范的,工程规范也会收敛进去一部分,至于编码规范只能去发现去更正。
一句话总结:
选择Go的初衷是贴近云原生,学习简单,效率高,底层机制不复杂,学个半年写的东西性能就还不错,因为语言特性非常简单,而且基础库做的非常好,社区也在慢慢庞大起来。
二、高德云原生Serverless落地情况&实战
本节主要介绍下Go生态下Serverless实际落地和收益。
2.1 高德Serverless 发展历程

2.2 Serverless 落地收益

2.3 目前开源贡献及未来开源计划:
参与Rsokcet-go、Rsocket-rust开源贡献,计划开源高德Serverless FaaS Runtime给社区。高德Runtime:Go、C++、Rust,目前会优先开源Go FaaS Runtime。
2.4 精选案例
大家都知道,交易场景还是比较复杂的。这里我们特意选择一个交易场景里的案例给大家展现下。
核心要点:
低代码,高能效
可编排,组装式研发
单元化容灾,异地多活
通用模板化协议,高效渲染

三、高德Go生态项目落地实战
说到高德Go生态落地,团队有许多QPS比较高的项目都切到了Golang上,也取得了显著的成绩。我们在重构方面也积累了一些经验,从降本和提效2个角度作出了贡献。
按照不同分类挑几个来介绍。如:
Mps渲染网关(gmds):经过多次出行大考,峰值百万级QPS
中间件TDDL:目前在生产用了很久,10多万代码量,以成为Go服务的标配,后续会承载百万级QPS
中间件:营销&出行&交易都在用的中间件(每一个项目都用),承载着百万级QPS,非常稳定
...
还有很多没介绍,因为篇幅较多,这里挑2个典型, 一个服务,一个工具做简单介绍。
3.1 Mps渲染网关
3.1.1 背景
说到渲染网关可能大家都很陌生,我这么形容下,当你打开高德地图检索的时候,会出现以下画面:
行前(上图所有的建筑物,名称,路线,地铁站,公交站,红绿灯等等,基本是你能看到所有图面都通过渲染网关透出):
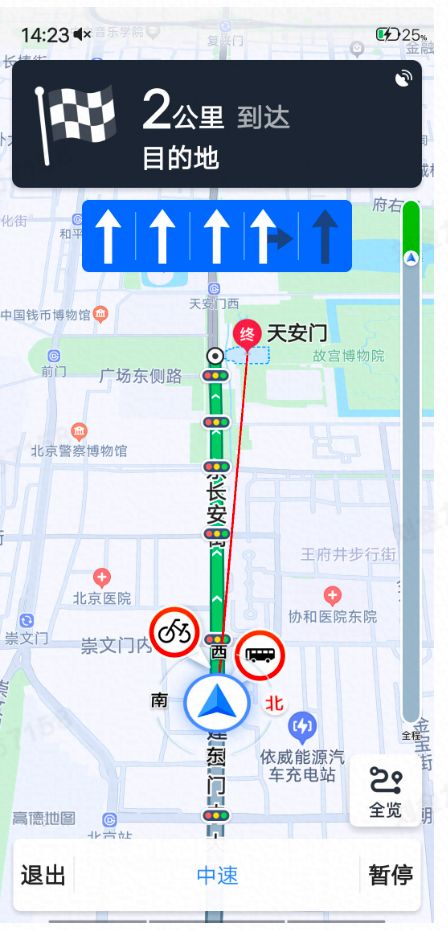
行中(上图所有的建筑物、名称、路线、地铁站、公交站、红绿灯等等,基本是你能看到所有图面都通过渲染网关透出)。还有行后、卫星图、环境地图、景区手绘图(东西太多,不一一列举)。
在重构过程中,重构代码其实是最简单的,复杂的是如何发现问题。我们除了做重构,还做了很多优化,产出了优秀的流量对比工具和灰度工具。流量对比工具在高德10w级QPS日志系统重构中也做出了很大贡献。
我们会从:
流量对比工具:让你无后顾之忧
框架选型:高性能框架选择与原理剖析
3.1.2 流量对比工具 Ln
先提一个问题,做一款实时流量对比工具,我们需要完成哪些功能呢?没错,就是流量复制,流量解析,流量重放,流量比对。其实不止这些,在实际中使用中更多是一个流量回归闭环,如下图

其中流量上传和流量拉取我们目前使用OSS。
流量对比为了保证对比的严谨性,以及排除可能的字符集干扰,我们原生支持了二进制流对比。(注:这里我们不考虑返回结果为Json的对比,因为Json的随机性导致即使Json一样顺序不同也会导致结果不通,这里我们在灰度对比工具里解决了)
问题流量本地重放Debug:在回归流量时,可能会发现部分流量比对不一致,这时我们肯定希望只重放特定流量到指定机器,以便于我们Debug或其他操作,Ln原生支持了此功能。
这里我们仅拿大家可能更感兴趣的流量复制和流量解析来细述技术细节。
3.1.2 .1 流量复制
先说复制流量,有同学会立马想到tcpdump,没错,就是tcpdump。tcpdump出的文件就是实实在在的流量。复制流量这一步已经有着落了,至于实时,我们可以两到三个进程错开时间,时间段首尾互相重叠即可完成实时。
另外,此种流量复制方式非常轻量,对线上机器增加的负载非常小,可以忽略不计。
3.1.2.2 流量解析
再来说流量解析,实际上就是如何解析tcpdump文件,拿到tcp payload,还原出http请求。
这里有两个关键点:
1) 我们如何从tcpdump文件中拿到tcp payload
2) 我们如何把四层的tcp payload重新聚合成七层的http请求
3.1.2.3 tcpdump文件格式
先说如何从tcpdump文件拿到tcp payload,如果我们能知道tcpdump文件的格式,我们就可以知道tcp payload在哪个位置,长度如何了。接下来我们就来看看tcpdump文件格式。
先看tcpdump文件总览
文件头的格式和长度都是固定的,如下![]()
我们可以在读取tcpdump文件后,往后移动23字节,然后开始处理每个数据包。
每个数据包的格式如下:
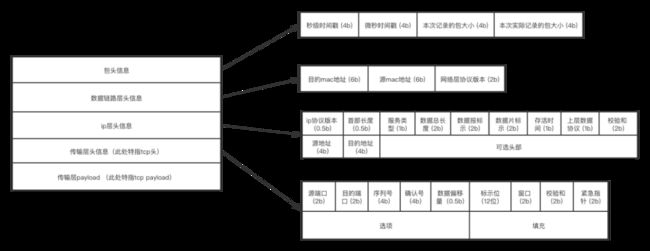
我们处理每个数据包,将前边的包头,数据链路头,ip层头,tcp协议头依次跳过,最终偏移到tcp payload第一个字节位置。
3.1.2.4 tcp payload还原http请求
这一趴我们来说如何将tcp payload还原成http请求,Ln工具中的完整实现是由tcp payload还原出请求及对应的响应,此处为了便于理解,仅讲解如何解析http请求。解析出http请求实际上已可以重新分别请求新老服务,对比响应二进制流。
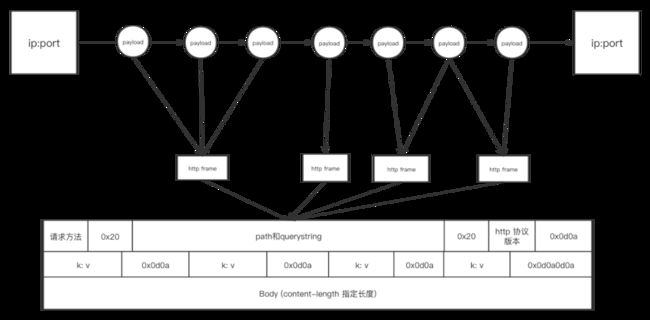
一个socket(
3.1.3 框架选型
有了流量对比工具,我们可以放心大胆的重构了,有问题也会从2进制的角度去发现(当然监控是少不了的),为了提升性能,我们选择了高性能的fasthttp框架。
fasthttp 提升性能的点:
控制异步 Goroutine 的同时处理数量,最大默认是 256 * 1024个;
使用 sync.Pool 来大量的复用对象和切片,减少内存分配;
尽量的避免[]byte到string转换时带来的内存分配和拷贝带来的消耗
Server 方法主要做了以下几件事:
初始化并启动Worker Pool;
接收请求Connection;
将Connection交给Worker Pool处理;
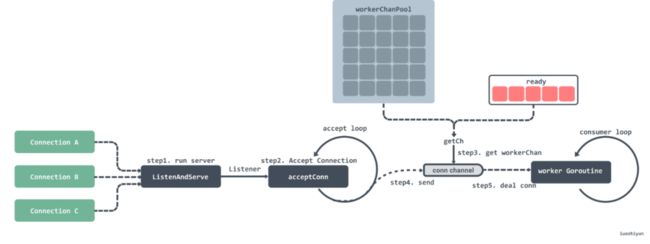
(图片来源于网络)
3.2 TDDL
3.2.1 背景简介
TDDL广泛应用于Java业务开发中,应对各种分库分表得心应手,主从切换毫无感知,实乃行走江湖的必备神器。然而对于我德数量众多的Gopher而言,却一直没有Go版的TDDL实现,访问数据库的时候只能走Corona代理模式,网络上多了那么几跳,总不是滋味。为了实现Go访问分库分表数据库这一朴素而又实际的愿景,热乎乎的Go版TDDL现已加入高德Golang豪华全家桶!
这里我们会介绍:
分库分表的前世今生&TDDl的演化
我们在Go的角度做了哪些优化
Go TDDL踩了哪些坑
3.2.2 分库分表的前世今生&TDDl的演化
早期单体应用,都是MVC架构,数据为单点

但是后来业务开始爆炸式增长,有些表数据量达到了千万级别,这个时候单表架构的问题就暴露出来了,系统开始变得很缓慢,就衍生了手动分库分表。
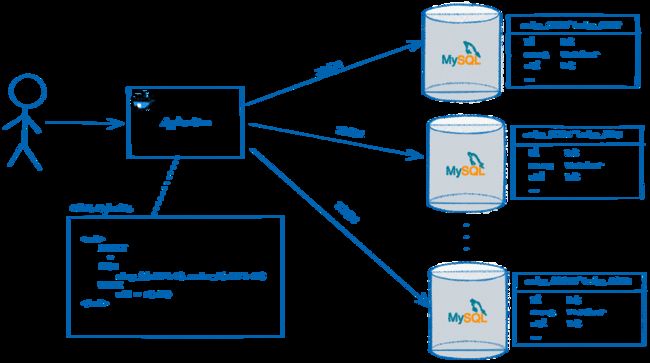
后来业务越来越多,每次都照葫芦画瓢复制一套出来人工修改,效率和人工维护成本很高,于是把原本在ORM层实现的手动分库分表逻辑都移到这个驱动里,驱动里的配置干脆就通过配置中心做成动态的,再加入读写分离,这样使用起来方便多了。管理成本也变得很低,效率很高。
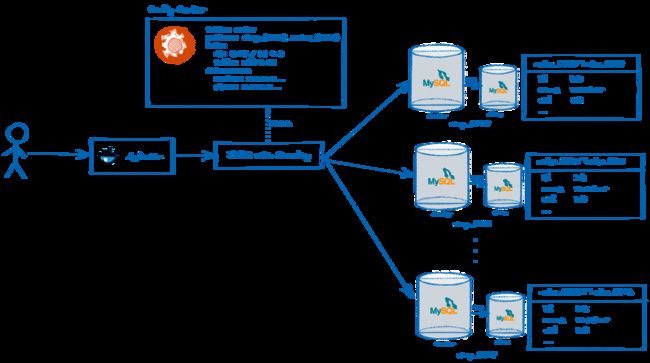
这种ORM代理层也有很多弊端,如公司有很多项目分用不通的语言,导致又回归到手段管理的方式上,于是迫不得已分库分表机制又进化了,返璞归真在驱动层去管理配置。
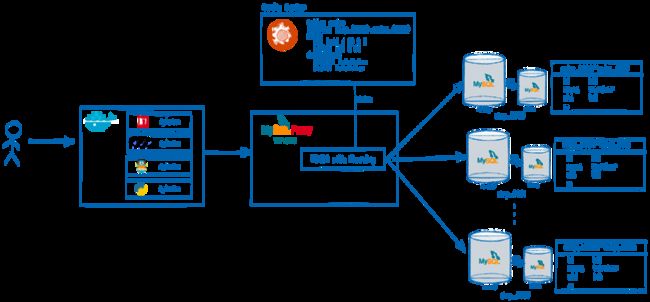
那TDDL就是驱动层的分库分表工具,项目立项之初,考虑到高德目前业务使用的实际情况,我们制定了一些设计目标:
配置兼容性,与现有TDDL的配置100%兼容,读取已有的配置而无需做任何修改,为业务平滑迁移扫平障碍
API完全实现SQL/Database规范,是一个100%的Go SQL Driver
初期只考虑 MySQL,虽然TDDL本身其实可以支持更多类型的上游DB
完成上述功能,我们要考虑到SQL Parser、Groovy的实现。在Java里Groovy被广大项目使用,但是在Go里却没有任何一款,所以我们只能考虑自己造轮子。
3.2.2.1 Groovy诞生记
幸运的是我们需要的只是一个Groovy表达式执行引擎,而并不是一个完整的Groovy虚机,所以只需要一个最小精简的实现即可,最初的思路有这么几个:
基于Antlr,使用Visit模式遍历执行
考虑将Groovy转换为其他脚本语言, 如Javascript或者Lua
考虑将Groovy动态转换成WASM字节码, 通过Wasmer-Go来执行
虽然自我感觉方案3是最完美的,但是权衡利弊 (=评估自身能力) 后选择了1。
Groovy的词法语法Grammar并没有现成的文件, 不过官方有Java和Scala的,可以拿来借鉴抠出个精简版,这个成本不高。而对于运行时来说,额外需要点体力活,手动实现Integer,Long,String等标准库里方法,为此我们模拟了Javascript基于Prototype的方式进行了绑定。
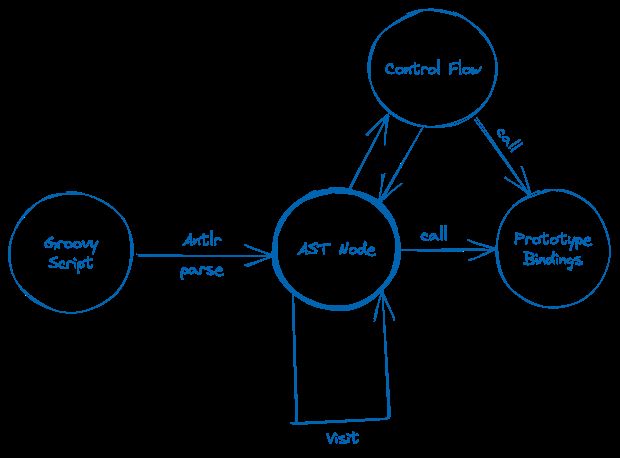
接口代码也很简单:
// Prototype 原型, 山寨了JS的原型
type Prototype interface {
// Multiply 乘运算
Multiply(self interface{}, other *Object) *Object
// Div 除运算
Div(self interface{}, other *Object) *Object
// Plus 加运算
Plus(self interface{}, other *Object) *Object
// Minus 减运算
Minus(self interface{}, other *Object) *Object
// Mod 取模运算
Mod(self interface{}, other *Object) *Object
// Compare 比较器, 相同返回0, 大于返回1, 小于返回-1
Compare(self interface{}, other *Object) int
// Apply 调用方法
Apply(self interface{}, method *CallMethod) *Object
// GetProperty 获取属性
GetProperty(self interface{}, name string) *Object
}
func (s protoString) Apply(self interface{}, method *CallMethod) *Object {
value := self.(string)
switch method.Name {
case "length":
if method.Match() {
return NewInteger(int32(len(value)))
}
case "substring":
// 重载 substring(int)
if method.Match(_integerClass) {
begin := int(method.IndexOf(0).inner.(int32))
return NewString(value[begin:])
}
// 重载 substring(int,int)
if method.Match(_integerClass, _integerClass) {
begin := int(method.IndexOf(0).inner.(int32))
end := int(method.IndexOf(1).inner.(int32))
return NewString(value[begin:end])
}
case "hashCode":
if method.Match() {
// BKDR hash
var h int32
if len(value) > 0 {
for _, it := range bytesconv.StringToBytes(value) {
h = 31*h + int32(it)
}
}
return NewInteger(h)
}
case "endsWith":
//...
case "toString":
//...
case "toLowerCase":
//...
case "toUpperCase":
//...
}
panic(method.NoSuchMethod(TypeString))
}而对于try-catch,在Golang里采用了defer recover的方式进行模拟捕获。另外做了一些优化,比如Java的Integer缓存机制、字符串缓存机制等等,也都加入了进去。经过以上努力,一个MINI版的Groovy引擎终于可以跑起来了!
3.2.2.2 SQL Parser
SQL Parser是整个TDDL实现的基石,其使用了自研的Cobar Parser,在这之上基于Visit模式实现了内部的AST处理。然而Cobar Parser是纯Java的实现,翻译成Golang的成本较高,考虑到目前这块的生态,罗列了一些方案:

起初我们选择了Antlr,Antlr Go的耗时达到了惊人的4.85s, 相比之下Antlr Java仅需要20ms! 于是我们又优化到TiDB Parser,性能从4.85s降低到0.5ms.
3.2.3 TDDL Go做了哪些优化
3.2.3.1 Cache
缓存本身是个老话题了,TDDL本身能利用缓存的地方也很多,比如:
SQL语句到AST的解析
对AST的分析后的结果
SQL函数编译成JS的过程
以上这些都是偏向减少计算密集型的缓存优化,本身实现也很简单基于自己写的一个简单LRU。实际的效果对于一般的场景而言有很明显的提升,后面也在考虑替换为类似Caffeine的W-TinyLFU.
3.2.3.2 Copy-on-write
Copy-on-write是很普遍的手段,Golang标准库的文档也有示例,围绕sync.Mutex 和atomic.Value,针对读多写少的场景,性能比较有优势。TDDL是基于Diamond做配置发现的,而一般来说,这些配置变更的频率极低,天生就符合“读多写极少”的场景。
3.2.3.3 Unsafe的使用
Go的Unsafe包是把利刃,合理使用可以解决很多需要性能或者普通方法无法实现的问题。
撇开性能向的使用场景, 比较普遍的一些类型转换(比如bytes和string),实际开发过程中,碰到较多的是两个普通方法无法解决场景:
未导出字段的获取
私有的结构体初始化
关于第一点, 在TDDL中请求上游MySQL使用的是标准的SQL驱动,封装的时候需要从底层的sql.Rows中抽取列值,这里使用了Unsafe方式去获取,参考以下代码片段:
// sql.Rows的结构
type Rows struct {
// ...
lastcols []driver.Value // <- 目标: 需要获取这个未导出的字段值
}
// 1. 反射获取字段offset
var (
_lastcolsOffset uintptr
_lastcolsOffsetInited sync.Once
)
func getLastColsOffset() uintptr {
_lastcolsOffsetInited.Do(func() {
var r sql.Rows
typ := reflect.TypeOf(r)
f, _ := typ.FieldByName("lastcols")
_lastcolsOffset = f.Offset
})
return _lastcolsOffset
}
// 2. 通过unsafe方式配合以上获取offset来直接获取未导出字段值
lastcolsPtr := unsafe.Pointer(uintptr(unsafe.Pointer(originSqlRows)) + getLastColsOffset())
lastcols := *(*[]driver.Value)(lastcolsPtr)3.2.3.4 隐式事务
隐式事务是指在比如单条写操作可能会跨多个物理子库的情况,需要保证原子性,自动包上一层事务。
比如INSERT语句中VALUES分别为uid=[1,2,3],分片路由计算出需要分别往 student_0001,student_0002,student_0003,假定提交的时候student_0003失败了,需要把student_0001和student_0002也给回滚掉(这里不考虑网络等因素回滚失败的情况)。
3.2.4 踩坑记
3.2.4.1 解密计算
TDDL从Diamond获取到的原始密码是加密的,而加密的方式很奇怪,可以简单理解为是Java的BigInteger转成16进制字符串,Java要从这个字符串还原得到bytes很容易,直接通过BigInteger提供的现成方法即可,但Go这边从这个字符串还原就比较麻烦了,要特殊处理下负数,而且这个还原过程因为bytes长度并不是标准的8/16/32/64,有可能是任意长度字节(比如有可能拿到的加密串是-5a0c2da2912390346e7b7c525916853217052ebf434560d7dca310e3de063d20),所以得自己写代码手动做大整数补码还原。
3.2.4.2 SQL驱动的数据安全拷贝
在做测试的时候发现打印的查询结果出现了乱码,意识到肯定哪块内存区的数据污染了,调试发现只有HOLD数据在本地内存做一些排序聚合计算的时候才会出现这种情况,最终进一步诊断发现了问题所在,MySQL的Go驱动其实内存块是复用的,这也很容易理解,类似个Buffer,如果只是单纯顺序Scan是没什么问题的,但如果把这个原始bytes存下来就有被污染的可能了。这里针对这种情况做一次Clone来解决。
3.2.4.3 协程安全
这个是老话题了,针对协程安全的手段也很多,比如标准库里的各种锁,sync.Map,之前说到的Cow,各种原子操作等。另外我们也用了一些无锁的容器实现,比如lock-free-queue.
注:本文中对编程语言的见解仅代表作者个人观点,欢迎大家一起交流探讨,部分配图源自网络,如有侵权请联系删除。
推荐阅读
实战|抽丝剥茧还原真相,记一次神奇的崩溃
重新认识架构—不只是软件设计
基于车道级数据的导航场景构建与还原仿真
Android高性能高稳定性代码覆盖率技术实践
高德信息业务DDD实战 用领域重构胶水代码
关注「高德技术」,了解更多