Scala中类的继承、抽象类和特质
1. 类的继承
1.1 Scala中的继承结构
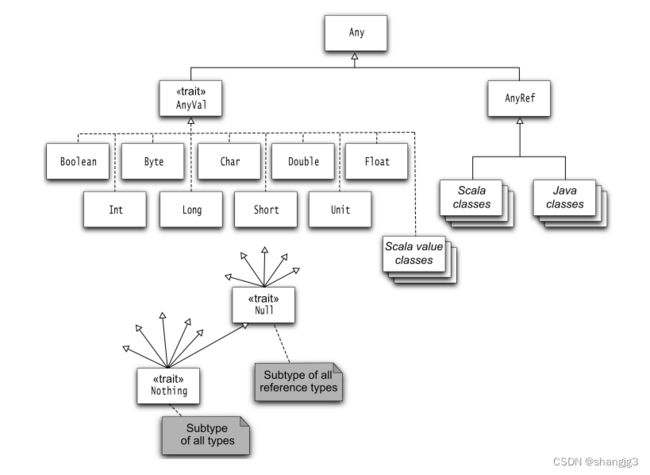
Scala 中继承关系如下图:
+ Any 是整个继承关系的根节点;
+ AnyRef 包含 Scala Classes 和 Java Classes,等价于 Java 中的 java.lang.Object;
+ AnyVal 是所有值类型的一个标记;
+ Null 是所有引用类型的子类型,唯一实例是 null,可以将 null 赋值给除了值类型外的所有类型的变量;
+ Nothing 是所有类型的子类型。
1.2 extends & override
Scala 的集成机制和 Java 有很多相似之处,比如都使用 `extends` 关键字表示继承,都使用 `override` 关键字表示重写父类的方法或成员变量。示例如下:
//父类
class Person {
var name = ""
// 1.不加任何修饰词,默认为 public,能被子类和外部访问
var age = 0
// 2.使用 protected 修饰的变量能子类访问,但是不能被外部访问
protected var birthday = ""
// 3.使用 private 修饰的变量不能被子类和外部访问
private var sex = ""
def setSex(sex: String): Unit = {
this.sex = sex
}
// 4.重写父类的方法建议使用 override 关键字修饰
override def toString: String = name + ":" + age + ":" + birthday + ":" + sex
}使用 `extends` 关键字实现继承:
// 1.使用 extends 关键字实现继承
class Employee extends Person {
override def toString: String = "Employee~" + super.toString
// 2.使用 public 或 protected 关键字修饰的变量能被子类访问
def setBirthday(date: String): Unit = {
birthday = date
}
}测试继承:
object ScalaApp extends App {
val employee = new Employee
employee.name = "shangjack"
employee.age = 20
employee.setBirthday("2019-03-05")
employee.setSex("男")
println(employee)
}
// 输出: Employee~shangjack:20:2019-03-05:男
1.3 调用超类构造器
在 Scala 的类中,每个辅助构造器都必须首先调用其他构造器或主构造器,这样就导致了子类的辅助构造器永远无法直接调用超类的构造器,只有主构造器才能调用超类的构造器。所以想要调用超类的构造器,代码示例如下:
class Employee(name:String,age:Int,salary:Double) extends Person(name:String,age:Int) {
.....
}1.4 类型检查和转换
想要实现类检查可以使用 `isInstanceOf`,判断一个实例是否来源于某个类或者其子类,如果是,则可以使用 `asInstanceOf` 进行强制类型转换。
object ScalaApp extends App {
val employee = new Employee
val person = new Person
// 1. 判断一个实例是否来源于某个类或者其子类 输出 true
println(employee.isInstanceOf[Person])
println(person.isInstanceOf[Person])
// 2. 强制类型转换
var p: Person = employee.asInstanceOf[Person]
// 3. 判断一个实例是否来源于某个类 (而不是其子类)
println(employee.getClass == classOf[Employee])
}1.5 构造顺序和提前定义
1.5.1 构造顺序
在 Scala 中还有一个需要注意的问题,如果你在子类中重写父类的 val 变量,并且超类的构造器中使用了该变量,那么可能会产生不可预期的错误。下面给出一个示例:
// 父类
class Person {
println("父类的默认构造器")
val range: Int = 10
val array: Array[Int] = new Array[Int](range)
}
//子类
class Employee extends Person {
println("子类的默认构造器")
override val range = 2
}
//测试
object ScalaApp extends App {
val employee = new Employee
println(employee.array.mkString("(", ",", ")"))
}这里初始化 array 用到了变量 range,这里你会发现实际上 array 既不会被初始化 Array(10),也不会被初始化为 Array(2),实际的输出应该如下:
父类的默认构造器
子类的默认构造器
()
可以看到 array 被初始化为 Array(0),主要原因在于父类构造器的执行顺序先于子类构造器,这里给出实际的执行步骤:
1. 父类的构造器被调用,执行 `new Array[Int](range)` 语句;
2. 这里想要得到 range 的值,会去调用子类 range() 方法,因为 `override val` 重写变量的同时也重写了其 get 方法;
3. 调用子类的 range() 方法,自然也是返回子类的 range 值,但是由于子类的构造器还没有执行,这也就意味着对 range 赋值的 `range = 2` 语句还没有被执行,所以自然返回 range 的默认值,也就是 0。
这里可能比较疑惑的是为什么 `val range = 2` 没有被执行,却能使用 range 变量,这里因为在虚拟机层面,是先对成员变量先分配存储空间并赋给默认值,之后才赋予给定的值。想要证明这一点其实也比较简单,代码如下:
class Person {
// val range: Int = 10 正常代码 array 为 Array(10)
val array: Array[Int] = new Array[Int](range)
val range: Int = 10 //如果把变量的声明放在使用之后,此时数据 array 为 array(0)
}
object Person {
def main(args: Array[String]): Unit = {
val person = new Person
println(person.array.mkString("(", ",", ")"))
}
}1.5.2 提前定义
想要解决上面的问题,有以下几种方法:
(1) . 将变量用 final 修饰,代表不允许被子类重写,即 `final val range: Int = 10 `;
(2) . 将变量使用 lazy 修饰,代表懒加载,即只有当你实际使用到 array 时候,才去进行初始化;
lazy val array: Array[Int] = new Array[Int](range)(3) . 采用提前定义,代码如下,代表 range 的定义优先于超类构造器。
class Employee extends {
//这里不能定义其他方法
override val range = 2
} with Person {
// 定义其他变量或者方法
def pr(): Unit = {println("Employee")}
}
但是这种语法也有其限制:你只能在上面代码块中重写已有的变量,而不能定义新的变量和方法,定义新的变量和方法只能写在下面代码块中。
类的继承和下文特质 (trait) 的继承都存在这个问题,也同样可以通过提前定义来解决。虽然如此,但还是建议合理设计以规避该类问题。
2. 抽象类
Scala 中允许使用 `abstract` 定义抽象类,并且通过 `extends` 关键字继承它。
定义抽象类:
abstract class Person {
// 1.定义字段
var name: String
val age: Int
// 2.定义抽象方法
def geDetail: String
// 3. scala 的抽象类允许定义具体方法
def print(): Unit = {
println("抽象类中的默认方法")
}
}继承抽象类:
class Employee extends Person {
// 覆盖抽象类中变量
override var name: String = "employee"
override val age: Int = 12
// 覆盖抽象方法
def geDetail: String = name + ":" + age
}3. 特质
3.1 trait & with
Scala 中没有 interface 这个关键字,想要实现类似的功能,可以使用特质 (trait)。trait 等价于 Java 8 中的接口,因为 trait 中既能定义抽象方法,也能定义具体方法,这和 Java 8 中的接口是类似的。
// 1.特质使用 trait 关键字修饰
trait Logger {
// 2.定义抽象方法
def log(msg: String)
// 3.定义具体方法
def logInfo(msg: String): Unit = {
println("INFO:" + msg)
}
}
想要使用特质,需要使用 `extends` 关键字,而不是 `implements` 关键字,如果想要添加多个特质,可以使用 `with` 关键字。
// 1.使用 extends 关键字,而不是 implements,如果想要添加多个特质,可以使用 with 关键字
class ConsoleLogger extends Logger with Serializable with Cloneable {
// 2. 实现特质中的抽象方法
def log(msg: String): Unit = {
println("CONSOLE:" + msg)
}
}
3.2 特质中的字段
和方法一样,特质中的字段可以是抽象的,也可以是具体的:
如果是抽象字段,则混入特质的类需要重写覆盖该字段;
如果是具体字段,则混入特质的类获得该字段,但是并非是通过继承关系得到,而是在编译时候,简单将该字段加入到子类。
trait Logger {
// 抽象字段
var LogLevel:String
// 具体字段
var LogType = "FILE"
}
// 覆盖抽象字段:
class InfoLogger extends Logger {
// 覆盖抽象字段
override var LogLevel: String = "INFO"
}
3.3 带有特质的对象
Scala 支持在类定义的时混入 ` 父类 trait`,而在类实例化为具体对象的时候指明其实际使用的 ` 子类 trait`。示例如下:

trait Logger:
// 父类
trait Logger {
// 定义空方法 日志打印
def log(msg: String) {}
}
// trait ErrorLogger:
// 错误日志打印,继承自 Logger
trait ErrorLogger extends Logger {
// 覆盖空方法
override def log(msg: String): Unit = {
println("Error:" + msg)
}
}
// trait InfoLogger:
// 通知日志打印,继承自 Logger
trait InfoLogger extends Logger {
// 覆盖空方法
override def log(msg: String): Unit = {
println("INFO:" + msg)
}
}
具体的使用类:
// 混入 trait Logger
class Person extends Logger {
// 调用定义的抽象方法
def printDetail(detail: String): Unit = {
log(detail)
}
}
这里通过 main 方法来测试:
object ScalaApp extends App {
// 使用 with 指明需要具体使用的 trait
val person01 = new Person with InfoLogger
val person02 = new Person with ErrorLogger
val person03 = new Person with InfoLogger with ErrorLogger
person01.log("scala") //输出 INFO:scala
person02.log("scala") //输出 Error:scala
person03.log("scala") //输出 Error:scala
}这里前面两个输出比较明显,因为只指明了一个具体的 `trait`,这里需要说明的是第三个输出,因为 trait 的调用是由右到左开始生效的**,所以这里打印出 `Error:scala`。
3.4 特质构造顺序
`trait` 有默认的无参构造器,但是不支持有参构造器。一个类混入多个特质后初始化顺序应该如下:
// 示例
class Employee extends Person with InfoLogger with ErrorLogger {...}
1. 超类首先被构造,即 Person 的构造器首先被执行;
2. 特质的构造器在超类构造器之前,在类构造器之后;特质由左到右被构造;每个特质中,父特质首先被构造;
Logger 构造器执行(Logger 是 InfoLogger 的父类);
InfoLogger 构造器执行;
ErrorLogger 构造器执行;
3. 所有超类和特质构造完毕,子类才会被构造。