YOLOv8将注意力机制融合进入C2f模块
1. 引言
1.1 YOLOv8添加注意力机制方法
yolov8添加注意力机制是一个非常常见的操作,常见的操作直接将注意力机制添加至YOLOv8的某一层之后,这种改进特别常见。
示例如下:
新版yolov8添加注意力机制(以NAMAttention注意力机制为例)
YOLOv8添加注意力机制(ShuffleAttention为例)
知网上常见的添加注意力机制的论文均使用的上述方式,同质化严重。
因此,这里展示一种将注意力机制融合至模块中的方法。
1.2 C2f模块融合注意力机制
C2f模块融合注意力机制,而不是直接放置在某一层后面。
本文使用SE注意力机制融入C2f模块。
1.3 常见的注意力机制
以下是一些常见的注意力机制实现的代码,具体看此贴。
常见注意力机制代码实现
2. 实验
2.1 SE Attention
SE注意力机制的代码如下:
#SE attention
class SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16):
super(SEAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(channel, channel //reduction, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(channel//reduction, channel, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x)
可以将以上注意力机制的代码放到ultralytics/nn/modules/conv.py目录的最后。
2.2 SE_Bottleneck和C2f_SE模块
SE_Bottleneck和C2f_SE模块的代码如下。
class SE_Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.se = SEAttention(c2, 16)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.se(self.cv2(self.cv1(x))) if self.add else self.se(self.cv2(self.cv1(x)))
class C2f_SE(nn.Module):
def __init__(self, c1, c2, shortcut = False, g = 1, n = 1, e = 0.5):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
self.m = nn.ModuleList(SE_Bottleneck(self.c, self.c, shortcut, g, k=((3,3),(3,3)), e = 1.0) for _ in range(n))
def forward(self, x):
y = list(self.cv1(x).chunk(2,1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
可以将以上SE_Bottleneck和C2f_SE模块的代码放到ultralytics/nn/modules/conv.py目录的最后。
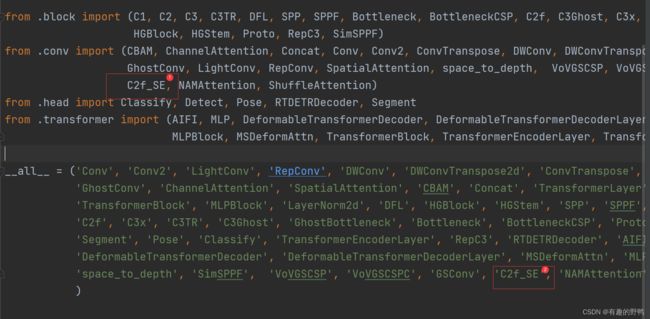
在ultralytics/nn/modules/conv.py文件的最前面添加C2f_SE
在ultralytics/nn/modules/ __ init__.py中,添加C2f_SE模块。
2.3 tasks.py
在ultralytics/nn/tasks.py中,在parse_model(d, ch, verbose=True)方法中,添加C2f_SE即可。

2.4 修改模型
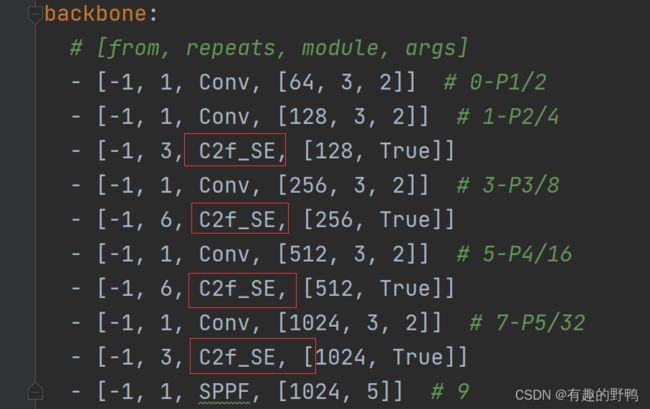
创建模块:ultralytics/cfg/models/v8/yolov8n-C2f_SE.yaml,以yolov8n为例:修改后的模型如下:
# Ultralytics YOLO , GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.25 # scales convolution channels
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_SE, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_SE, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_SE, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_SE, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
这里主要修改了backbone的C2f,其实也可以修改head部分的C2f,模型的大小不变,因此随便改哪个位置都行。