从零开始写Python爬虫---1.1 requests库的安装与使用
什么是爬虫?
爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的。所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来。这个时候就要用到
requests库了。
python下载
所谓工欲善其事必先利其器,在写python之前,我们需要先把安装环境搭建好,我们直接打开python的官方网站:https://www.python.org/,点击download进行安装,现在最新的版本是3.9.3。

如果是windows电脑,点击64-bit进行下载。

在安装的过程中需要勾选将python加入到环境中,然后再点击下载。
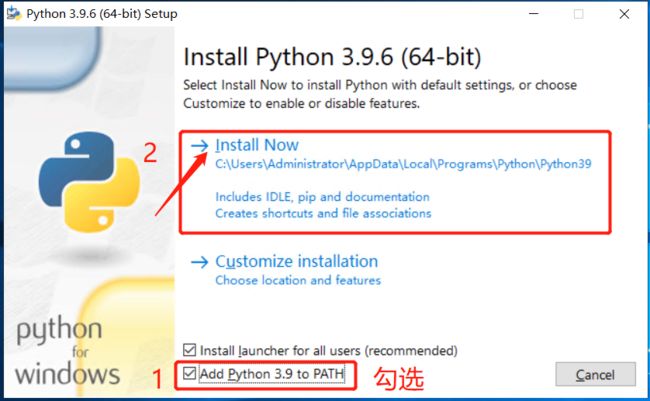
不到一分钟的时间,就下载好了,出现如下页面,表示下载成功。
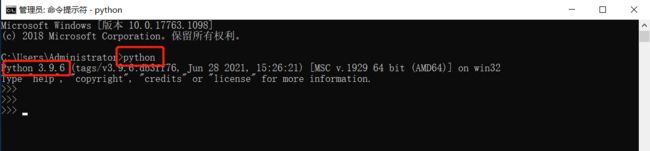
还有一个方法可以验证是否安装成功,打开CMD命令,输入python,如果出现版本号,则表示对应下载成功。
接下来,我们需要安装一些爬虫用到的库,也就是本章需要介绍的requests库。
requests库的安装
requests库本质上就是模拟了我们用浏览器打开一个网页,发起请求是的动作。它能够迅速的把请求的html源文件保存到本地.
他安装的方式非常简单:我们用pip工具在命令行CMD里进行安装
pip install requests
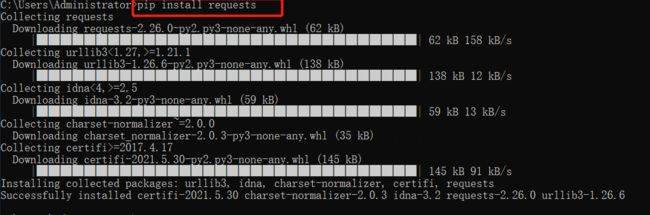
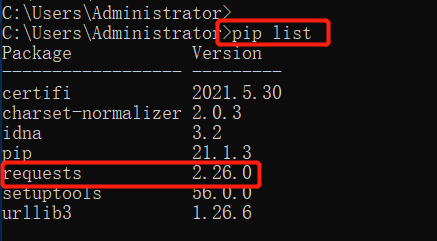
接着我们看一下是否成功安装了requests库
pip list
看一下安装结果,这时候表明已经安装成功了。
requests库的基本使用
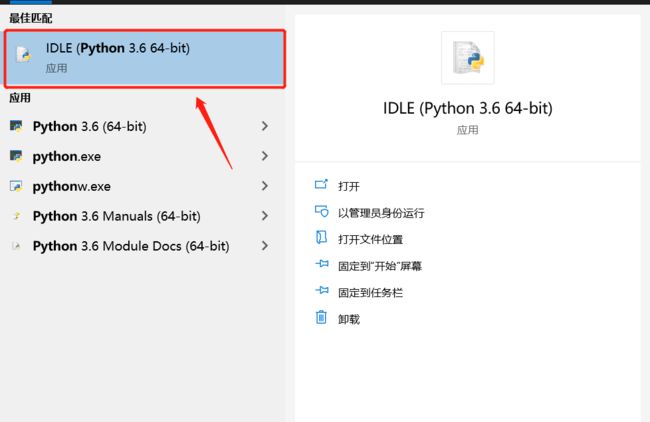
接下来我们就开始写代码了,首先打开编辑器,也就是上面下载的python。
找到IDLE,单机打开
再点击左上角的File,点击New File,我们在这里编辑代码,我们可以先点击File,给文件起个名字,我这里就叫test吧,然后再次打开。
首先我们在python编辑器导入requests这个包
import requests
假设我们这里需要将百度的index页面的html源码抓取到本地,并用r变量保存。
r = requests.get("http://www.baidu.com")
最后将下载到的内容打印一下:
print(r.text)
点击Run,里面有个Run Module,点击,如下面图片可以看到,百度的首页源码文件我们已经把他抓取到本地了。
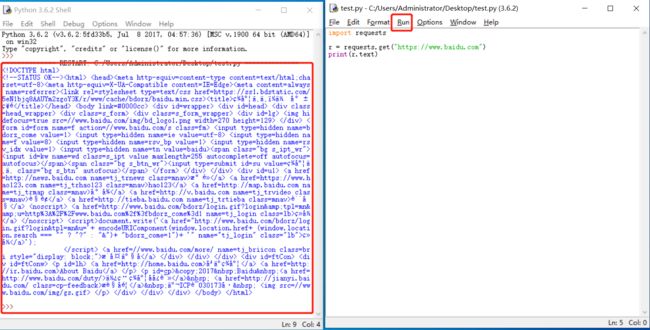
上面的抓取过程中,我们用到了requests库的get方法,这个方法是requests库中最常用的方法之一。
他接受一个参数(url)并返回一个HTTP response对象。与get方法相同的,requests库还有许多其他常用方法:
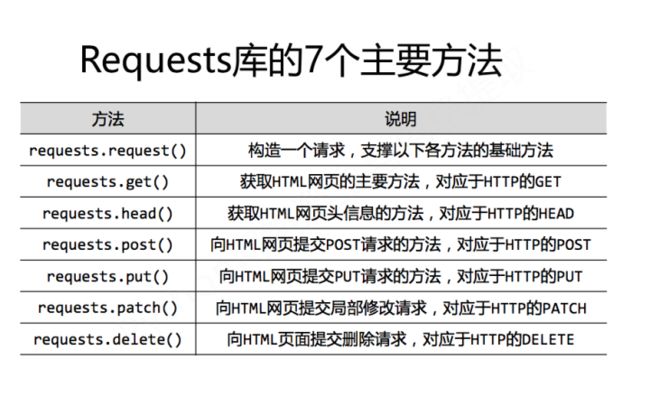
下面我们来详细了解一下 requests.get 这个方法:
这个方法可以接收三个参数,其中第二个默认为None, 第三个可选.
requests.get(url, params=None, **kwargs)
作用是模拟发起GET请求,模拟获取页面的url链接。
下面,我们来着重讲一下 **kwargs 这个参数
-
kwargs: 控制访问的参数,均为可选项 -
params: 字典或字节序列,作为参数增加到url中 -
data: 字典、字节序列或文件对象,作为Request的内容 json : JSON格式的数据,作为Request的内容 -
headers: 字典,HTTP定制头 -
cookies: 字典或CookieJar,Request中的cookie -
auth: 元组,支持HTTP认证功能 -
files: 字典类型,传输文件 -
timeout: 设定超时时间,秒为单位 -
proxies: 字典类型,设定访问代理服务器,可以增加登录认证 -
allow_redirects: True/False,默认为True,重定向开关 -
stream: True/False,默认为True,获取内容立即下载开关 -
verify: True/False,默认为True,认证SSL证书开关 -
cert: 本地SSL证书路径 -
url: 拟更新页面的url链接 -
data: 字典、字节序列或文件,Request的内容 -
json: JSON格式的数据,Request的内容
下面来介绍下,常用的两个控制访问参数:
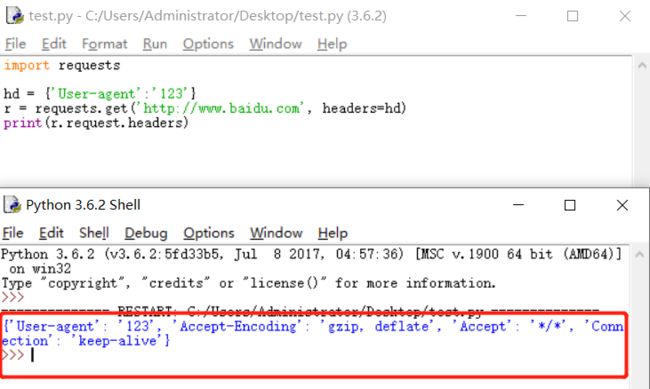
1. 假设我们需要在GET请求里自定义一个header头文件:
import requests
hd = {'User-agent':'123'}
r = requests.get('http://www.baidu.com', headers=hd)
print(r.request.headers)
结果如下
2. 假设我们要自定义一个代理池
为什么有时候需要添加代理池proxies这个参数呢,是因为在爬取网页的过程中,有些网站对访问的IP控制较为严格,我们需要添加很多具有IP的代理机制,这样才可以骗过待爬取的网站。后面有章节会有实战案例,详细讲解这个代理池的用法,先留个坑。
pxs = { 'http': 'http://user:[email protected]:1234',
'https': 'https://10.10.10.1:4321' }
r = requests.get('http://www.baidu.com', proxies=pxs)
接下来,我们详细了解Response对象
import requests
r = requests.get("http://www.baidu.com")
#HTTP请求的返回状态,比如,200表示成功,404表示失败
print (r.status_code)
#HTTP请求中的headers
print (r.headers)
#从header中猜测的响应的内容编码方式
print (r.encoding)
#从内容中分析的编码方式(慢)
print (r.apparent_encoding)
#响应内容的二进制形式
print (r.content)
下面介绍下,requests抓取网页的通用框架,这是一个最简单的爬虫模板,也是我们后面在实战案例中经常用到的基础代码,可以说万变不离其宗。
下面这段代码什么意思呢,我来简单解释下,url代表我们要爬取的网站地址,首先我们用requests去爬取这个地址,给它30秒的时间延迟,如果在30秒内可以访问进去,并且获取的状态码是200,那就返回访问的网页内容,否则就返回一个失败的信息。
import requests
def getHtmlText(url):
try:
r = requests.get(url, timeout=30)
# 如果状态码不是200 则应发HTTOError异常
r.raise_for_status()
# 设置正确的编码方式
r.encoding = r.apparent_encoding
return r.text
except:
return "Something Wrong!"
好了关于requests库我们今天就写到这,这是一个非常强大的库,
更多的功能大家可以去看一下官方的文档:快速上手 - Requests 2.10.0 文档
下一章节,我将讲解另一个常见的爬虫BeautifulSoup库。