Centos7搭建Hadoop集群(V3.3.4)
Centos7搭建Hadoop集群V3.3.4
- 一、准备工作
-
- 1、配置hostname
- 2、hosts映射
- 3、关闭防火墙
- 4、同步时间
- 5、关闭selinux
- 6、配置ssh免密登陆
- 7、重启
- 二、安装所需环境
-
- 1、jdk安装
- 2、hadoop安装
- 三、修改配置
-
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- workers
- 四、初始化并启动
-
- 1、初始化
- 2、启动
- 3、相关说明
- 4、Web页面
- 五、测试hdfs
- 六、Springboot整合Hdfs
本次安装Hadoop版本为3.3.4
安装规划(3台机器)
node01 :192.168.117.20 NameNode DataNode
node02 :192.168.117.21 DataNode
node03 :192.168.117.22 DataNode SecondaryNameNode
一、准备工作
1、配置hostname
hostname分别为node01,node02,node03
# 三台机器分别执行
hostnamectl set-hostname node01
hostnamectl set-hostname node02
hostnamectl set-hostname node03
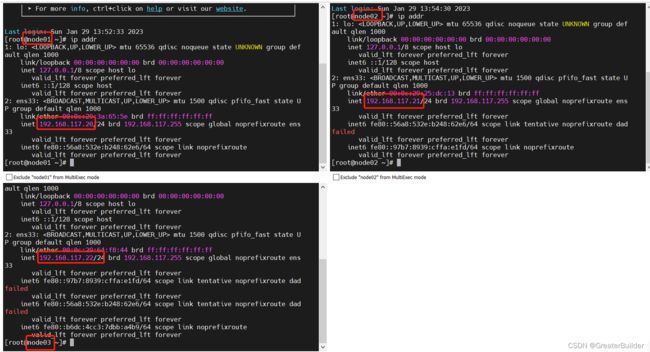
2、hosts映射
# 三台机器均要执行
vim /etc/hosts
192.168.117.20 node01
192.168.117.21 node02
192.168.117.22 node03
3、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
4、同步时间
yum install ntpdate
ntpdate ntp5.aliyun.com

5、关闭selinux
vim /etc/selinux/config
修改为 SELINUX=disabled

6、配置ssh免密登陆
# 三台机器均执行一下命令
ssh-keygen -t rsa
# 将每台机器的公钥拷贝给每台机器
ssh-copy-id node01
ssh-copy-id node02
ssh-copy-id node03
测试

7、重启
reboot
二、安装所需环境
1、jdk安装
# 三台机器均执行
cd /etc/profile.d
vim jdk.sh
# 写入内容
export JAVA_HOME=/opt/button/jdk
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
# 使配置生效
source /etc/profile
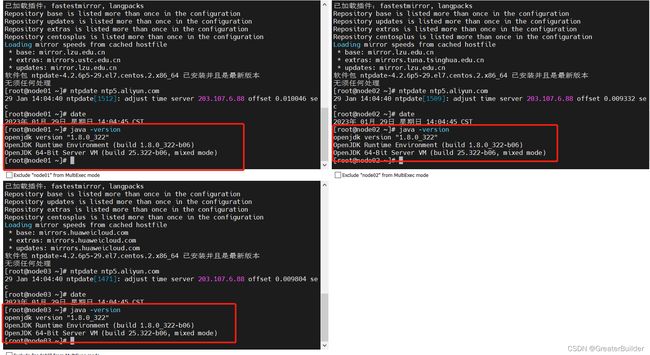
验证
java -version
2、hadoop安装
下载安装包
配置环境变量
# 三台机器均执行
vim /etc/profile.d/hadoop.sh
# 写入内容
export HADOOP_HOME=/opt/button/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使配置生效
source /etc/profile
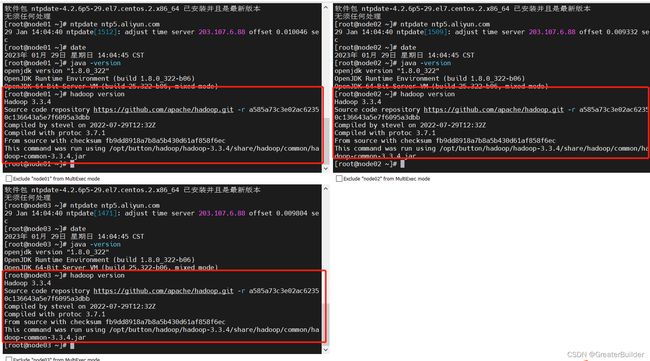
验证
hadoop version
创建hadoop数据目录:
mkdir /opt/button/hadoop/data
cd /opt/button/hadoop
chmod -R 777 ./data/
三、修改配置
配置位于hadoop解压目录etc/hadoop目录下,三台机器配置保持一致

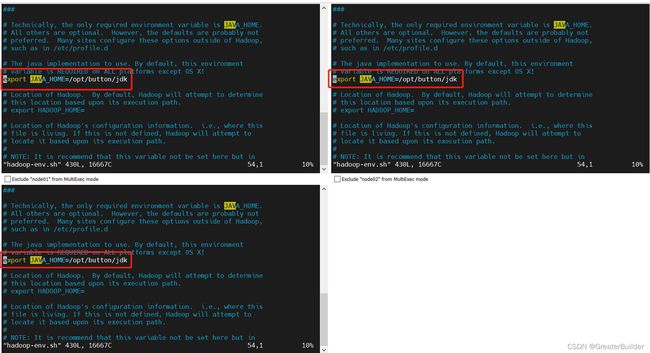
hadoop-env.sh
vim hadoop-env.sh
# jdk修改为自己的路径
export JAVA_HOME=/opt/button/jdk
注:相关配置具体说明可以查看官网
官网地址

core-site.xml
<!-- 指定HADOOP所使用的文件系统schema,NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/button/hadoop/data</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node03:9868</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>org.apache.hadoop.mapreduce.v2.app.MRAppMaster</value>
</property>
workers
vim workers
# 写入如下内容
node01
node02
node03
四、初始化并启动
1、初始化
如果第一次启动集群需格式化NameNode,主节点操作(format首次初始化执行一次即可,后续如果执行除了会造成数据丢失,还会导致hdfs集群主从角色互不识别的问题,三思呀!!!)
hdfs namenode –format
如果该命令格式化无效,可以试试如下命令
hadoop namenode -format
格式化成功的样子如下所示即可
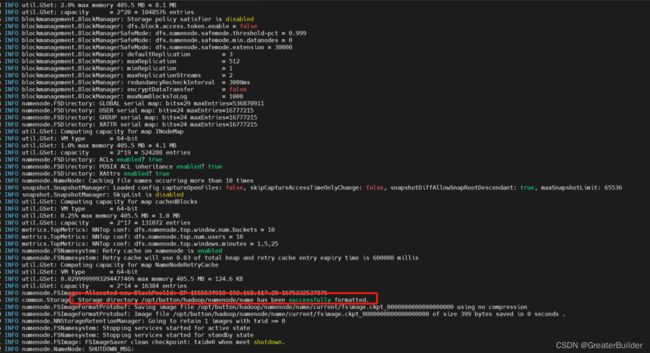
注:如果不是第一次,需要先执行stop-all.sh,然后删除data与logs中的文件再执行初始化命令,此操作不建议执行,可能会遇到很多问题。
2、启动
在node01节点上的sbin目录找到start-all.sh并执行即可
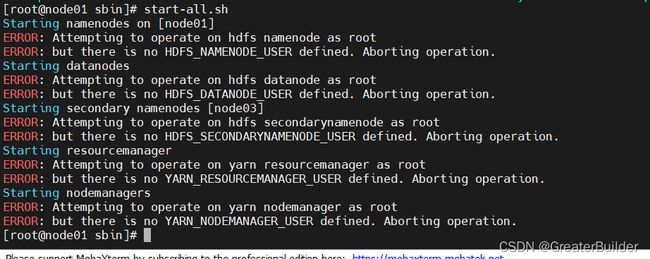
执行如下操作解决此问题
vim /etc/profile.d/my_env.sh
# 添加如下内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# 使配置生效
source /etc/profile
重新执行start-all.sh
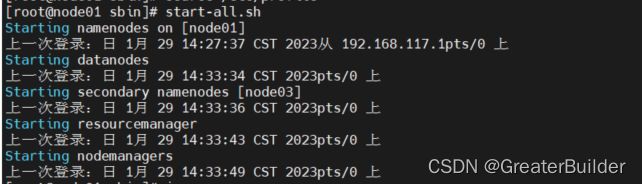
查看启动的服务

3、相关说明
- 这里执行start-all.sh会启动所有服务,如果只想启动自己所需要的服务,可以执行对应的脚本即可。
比如启动hdfs可以执行start-dfs.sh即可。
![]()
- 如果只想操作某个角色的进程,可以使用如下命令
# HDFS
hdfs --daemon start namenode|datanode|secondarynamenode
hdfs --daemon stop namenode|datanode|secondarynamenode
# YARN
yarn --daemon start resourcemanager|nodemanager
yarn --daemon stop resourcemanager|nodemanager
- 如果启动过程没有那么顺利,我们可以通过查看日志来排查问题。当执行启动脚本时,会自动在hadoop目录下帮我们创建logs文件夹,我们可以在logs文件夹下查询对用的日志文件。

4、Web页面
HDFS集群Web UI默认端口9870,ip则为namenode的IP地址
http://192.168.117.20:9870/

注:在windows上使用web ui上传文件时,由于没法识别node01,node02,node03,所以上传文件会失败,只需要在windows的hosts文件加上对应的解析就可以正常操作了
# C:\Windows\System32\drivers\etc
192.168.117.20 node01
192.168.117.21 node02
192.168.117.22 node03
Yarn集群WEB Ui默认端口8088,ip则为resourcemanager的IP地址
http://192.168.117.20:8088/
五、测试hdfs
hadoop fs -mkdir /hfile
hadoop fs -put input.txt /hfile
hadoop fs -ls /hfile

六、Springboot整合Hdfs
Springboot整合hdfs-spring-boot-starter实现基本操作
Springboot整合hdfs-client实现基本操作