Linux - 虚拟网络设备 - bridge,veth,namespace
- 引用
- 轻松理解 Docker 网络虚拟化基础之网络 namespace!
- 轻松理解 Docker 网络虚拟化基础之 veth 设备!
- 深入理解 Linux 上软件实现的“交换机” - Bridge!
- Linux netns 详解
- Linux veth pair 详解
- Linux Bridge 详解
- Linux 虚拟网络设备之bridge
- linux虚拟网络设备网桥-bridge
- linux虚拟网络设备veth-pair
- 一文理解 K8s 容器网络虚拟化
- LINUX内核数据包BRIDGE上转发流程
一. bridge
网桥(Bridge)是早期的两端口二层网络设备,用来连接不同网段。网桥的两个端口分别有一条独立的交换信道,不是共享一条背板总线,可隔离冲突域。网桥比集线器(Hub)性能更好,集线器上各端口都是共享同一条背板总线的。后来,网桥被具有更多端口、同时也可隔离冲突域的交换机(Switch)所取代。 网桥(Bridge)像一个聪明的中继器。中继器从一个网络电缆里接收信号, 放大它们,将其送入下一个电缆。相比较而言,网桥对从关卡上传下来的信息更敏锐一些。网桥是一种对帧进行转发的技术,根据MAC分区块,可隔离碰撞。网桥将网络的多个网段在数据链路层连接起来。 网桥也叫桥接器,是连接两个局域网的一种存储/转发设备,它能将一个大的LAN分割为多个网段,或将两个以上的LAN互联为一个逻辑LAN,使LAN上的所有用户都可访问服务器。 扩展局域网最常见的方法是使用网桥。最简单的网桥有两个端口,复杂些的网桥可以有更多的端口。网桥的每个端口与一个网段相连。
-
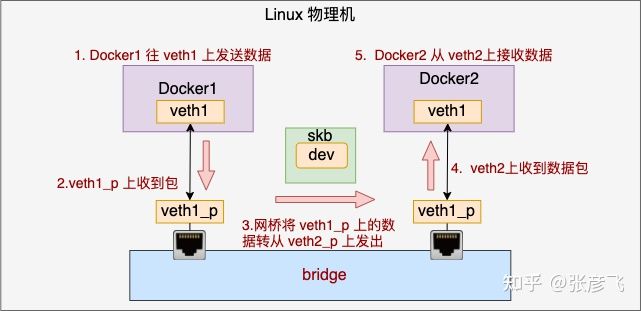
完整的Docker1和Docker2通信的过程:
1.Docker1 往 veth1 上发送数据
2.由于 veth1_p 是 veth1 的 pair, 所以这个虚拟设备上可以收到包
3.veth 收到包以后发现自己是连在网桥上的,于是乎进入网桥处理。在网桥设备上寻找要转发到的端口,这时找到了 veth2_p 开始发送。网桥完成了自己的转发工作
4.veth2 作为 veth2_p 的对端,收到了数据包
5.Docker2 里的就可以从 veth2 设备上收到数据了
-
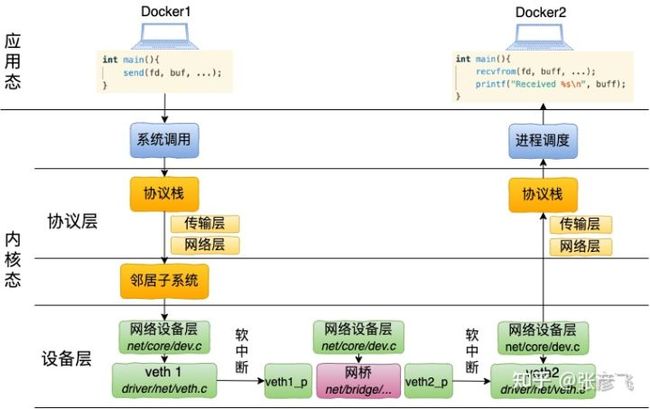
从两个 Docker 的用户态来看:
- Docker 1 在需要发送数据的时候,先通过 send 系统调用发送,这个发送会执行到协议栈进行协议头的封装等处理。经由邻居子系统找到要使用的设备(veth1)后,从这个设备将数据发送出去,veth1 的对端 veth1_p 会收到数据包。
- 收到数据的 veth1_p 是一个连接在 bridge 上的设备,这时候 bridge 会接管该 veth 的数据接收过程。从自己连接的所有设备中查找目的设备。找到 veth2_p 以后,调用该设备的发送函数将数据发送出去。同样 veth2_p 的对端 veth2 即将收到数据。
- 其中 veth2 收到数据后,将和 lo、eth0 等设备一样,进入正常的数据接收处理过程。Docker 2 中的用户态进程将能够收到 Docker 1 发送过来的数据了就。
1.1 bridge内核源码解析
拿 veth 设备来举例,如果它连接到了网桥上的话,在设备层的 __netif_receive_skb_core 函数中和上述过程有所不同。连在 bridge 上的 veth 在收到数据包的时候,不会进入协议栈,而是会进入网桥处理。网桥找到合适的转发口(另一个 veth),通过这个 veth 把数据转发出去。
1. 从 veth1_p 设备的接收看起,所有的设备的接收都一样,都会进入 __netif_receive_skb_core 设备层的关键函数。
//file: net/core/dev.c
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc)
{
...
// tcpdump 抓包点
list_for_each_entry_rcu(...);
// 执行设备的 rx_handler(也就是 br_handle_frame)
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto unlock;
}
}
// 送往协议栈
//...
unlock:
rcu_read_unlock();
out:
return ret;
}在 __netif_receive_skb_core 中先是过了 tcpdump 的抓包点,然后查找和执行了 rx_handler。在上面小节中我们看到,把 veth 连接到网桥上的时候,veth 对应的内核对象 dev 中的 rx_handler 被设置成了 br_handle_frame。所以连接到网桥上的 veth 在收到包的时候,会将帧送入到网桥处理函数 br_handle_frame 中。
另外要注意的是网桥函数处理完的话,一般来说就 goto unlock 退出了。和普通的网卡数据包接收相比,并不会往下再送到协议栈了。
2. 接着来看下网桥是咋工作的吧,进入到 br_handle_frame 中来搜寻。
//file: net/bridge/br_input.c
rx_handler_result_t br_handle_frame(struct sk_buff **pskb)
{
...
forward:
NF_HOOK(NFPROTO_BRIDGE, NF_BR_PRE_ROUTING, skb, skb->dev, NULL,
br_handle_frame_finish);
}3. 对 br_handle_frame 的逻辑进行了充分的简化,简化后它的核心就是调用 br_handle_frame_finish。同样 br_handle_frame_finish 也有点小复杂。本文中,我们主要想了解的 Docker 场景下 bridge 上的 veth 设备转发。所以根据这个场景,我又对该函数进行了充分的简化。
//file: net/bridge/br_input.c
int br_handle_frame_finish(struct sk_buff *skb)
{
// 获取 veth 所连接的网桥端口、以及网桥设备
struct net_bridge_port *p = br_port_get_rcu(skb->dev);
br = p->br;
// 更新和查找转发表
struct net_bridge_fdb_entry *dst;
br_fdb_update(br, p, eth_hdr(skb)->h_source, vid);
dst = __br_fdb_get(br, dest, vid)
// 转发
if (dst) {
br_forward(dst->dst, skb, skb2);
}
}在硬件中,交换机和集线器的主要区别就是它会智能地把数据送到正确的端口上去,而不会像集线器那样给所有的端口都群发一遍。所以在上面的函数中,我们看到了更新和查找转发表的逻辑。这就是网桥在学习,它会根据它的自学习结果来工作。
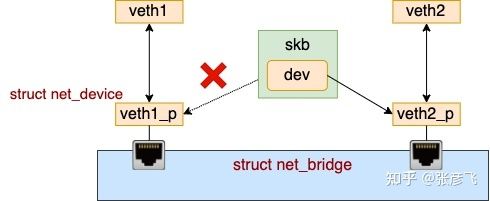
4. 在找到要送往的端口后,下一步就是调用 br_forward => __br_forward 进入真正的转发流程。
//file: net/bridge/br_forward.c
static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)
{
// 将 skb 中的 dev 改成新的目的 dev
skb->dev = to->dev;
NF_HOOK(NFPROTO_BRIDGE, NF_BR_FORWARD, skb, indev, skb->dev,
br_forward_finish);
}在 __br_forward 中,将 skb 上的设备 dev 改为了新的目的 dev。
5. 然后调用 br_forward_finish 进入发送流程。 在 br_forward_finish 里会依次调用 br_dev_queue_push_xmit、dev_queue_xmit。
//file: net/bridge/br_forward.c
int br_forward_finish(struct sk_buff *skb)
{
return NF_HOOK(NFPROTO_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev,
br_dev_queue_push_xmit);
}
int br_dev_queue_push_xmit(struct sk_buff *skb)
{
dev_queue_xmit(skb);
...
}二. veth
网络虚拟化实现的第一步,就是用软件来模拟这个简单的网络连接实现过程。实现的技术就是我们今天的主角 veth,它模拟了在物理世界里的两块网卡,以及一条网线。通过它可以将两个虚拟的设备连接起来,让他们之间相互通信。平时工作中在 Docker 镜像里我们看到的 eth0 设备,其实就是 veth。

2.1 veth内核源码解析
从实现上来看,虚拟设备 veth 和我们日常接触的 lo 设备非常非常的像。只不过和 lo 设备相比,veth 是为了虚拟化技术而生的,所以它多了个结对的概念。在创建函数 veth_newlink 中,一次性就创建了两个网络设备出来,并把对方分别设置成了各自的 peer。在发送数据的过程中,找到发送设备的 peer,然后发起软中断让对方收取就算完事了。
对于回环设备 lo 来说 netdev_ops 是 loopback_ops。那么上面发送过程中调用的 ops->ndo_start_xmit 对应的就是 loopback_xmit。对于 veth 设备来说,它在启动的时候将 netdev_ops 设置成了 veth_netdev_ops。那 ops->ndo_start_xmit 对应的具体发送函数就是 veth_xmit。这就是在整个发送的过程中,唯一和 lo 设备不同的地方所在。

三. namespace
在 Linux 上通过 veth 我们可以创建出许多的虚拟设备。通过 Bridge 模拟以太网交换机的方式可以让这些网络设备之间进行通信。不过虚拟化中还有很重要的一步,那就是隔离。借用 Docker 的概念来说,那就是不能让 A 容器用到 B 容器的设备,甚至连看一眼都不可以。只有这样才能保证不同的容器之间复用硬件资源的同时,还不会影响其它容器的正常运行。Docker1 和 Docker2 都可以分别拥有自己独立的网卡设备,配置自己的路由规则、iptable。从而使得他们的网络功能不会相互影响。
在 Linux 上实现隔离的技术手段就是 namespace。通过 namespace 可以隔离容器的进程 PID、文件系统挂载点、主机名等多种资源。不过我们今天重点要介绍的是网络 namespace,简称 netns。它可以为不同的命名空间从逻辑上提供独立的网络协议栈,具体包括网络设备、路由表、arp表、iptables、以及套接字(socket)等。使得不同的网络空间就都好像运行在独立的网络中一样。
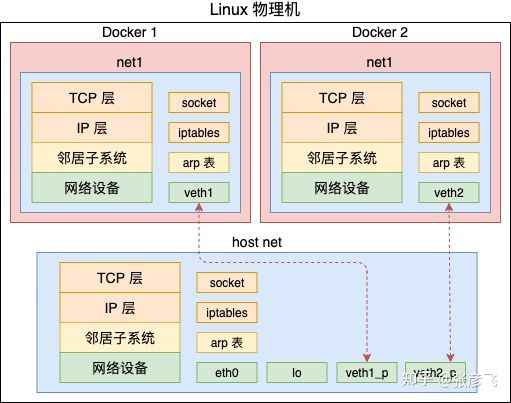
通过为不同空间创建不同的 struct net 对象。每个 struct net 中都有独立的路由表、iptable 等数据结构。每个设备、每个 socket 上也都有指针指明自己归属那个 netns。通过这种方法从逻辑上看起来好像是真的有多个协议栈一样。
