当科技遇上神器:用Streamlit定制AI可视化问答界面
Streamlit是一个开源的Python库,利用Streamlit可以快速构建机器学习应用的用户界面。
本文主要探讨如何使用Streamlit构建大模型+外部知识检索的AI问答可视化界面。
我们先构建了外部知识检索接口,然后让大模型根据检索返回的结果作为上下文来回答问题。
Streamlit-使用说明
下面简单介绍下Streamlit的安装和一些用到的组件。
- Streamlit安装
pip install streamlit
- Streamlit启动
streamlit run xxx.py --server.port 8888
说明:
- 如果不指定端口,默认使用8501,如果启动多个streamlit,端口依次升序,8502,8503,…。
- 设置server.port可指定端口。
- streamlit启动后将会给出两个链接,Local URL和Network URL。
- 相关组件
import streamlit as st
- st.header
streamlit.header(body)
body:字符串,要显示的文本。
- st.markdown
st.markdown(body, unsafe_allow_html=False)
body:要显示的markdown文本,字符串。
unsafe_allow_html: 是否允许出现html标签,布尔值,默认:false,表示所有的html标签都将转义。 注意,这是一个临时特性,在将来可能取消。
- st.write
st.write(*args, **kwargs)
*args:一个或多个要显示的对象参数。
unsafe_allow_html :是否允许不安全的HTML标签,布尔类型,默认值:false。
- st.button
st.button(label, key=None)
label:按钮标题字符串。
key:按钮组件的键,可选。如果未设置的话,streamlit将自动生成一个唯一键。
- st.radio
st.radio(label, options, index=0, format_func=
label:单选框文本,字符串。
options:选项列表,可以是以下类型:
list
tuple
numpy.ndarray
pandas.Series
index:选中项的序号,整数。
format_func:选项文本的显示格式化函数。
key:组件ID,当未设置时,streamlit会自动生成。
- st.sidebar
st.slider(label, min_value=None, max_value=None, value=None, step=None, format=None, key=None)
label:说明文本,字符串。
min_value:允许的最小值,默认值:0或0.0。
max_value:允许的最大值,默认值:0或0.0。
value:当前值,默认值为min_value。
step:步长,默认值为1或0.01。
format:数字显示格式字符串
。
key:组件ID。
- st.empty
st.empty()
填充占位符。
- st.columns
插入并排排列的容器。
st.columns(spec, *, gap="small")
spec: 控制要插入的列数和宽度。
gap: 列之间的间隙大小。
AI问答可视化代码
这里只涉及到构建AI问答界面的代码,不涉及到外部知识检索。
- 导入packages
import streamlit as st
import requests
import json
import sys,os
import torch
import torch.nn as nn
from dataclasses import dataclass, asdict
from typing import List, Optional, Callable
import copy
import warnings
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
from peft import PeftModel
from chatglm.modeling_chatglm import ChatGLMForConditionalGeneration
- 外部知识检索
def get_reference(user_query,use_top_k=True,top_k=10,use_similar_score=True,threshold=0.7):
"""
外部知识检索的方式,使用top_k或者similar_score控制检索返回值。
"""
# 设置检索接口
SERVICE_ADD = ''
ref_list = []
user_query = user_query.strip()
input_data = {}
if use_top_k:
input_data['query'] = user_query
input_data['topk'] = top_k
result = requests.post(SERVICE_ADD, json=input_data)
res_json = json.loads(result.text)
for i in range(len(res_json['answer'])):
ref = res_json['answer'][i]
ref_list.append(ref)
elif use_similar_score:
input_data['query'] = user_query
input_data['topk'] = top_k
result = requests.post(SERVICE_ADD, json=input_data)
res_json = json.loads(result.text)
for i in range(len(res_json['answer'])):
maxscore = res_json['answer'][i]['prob']
if maxscore > threshold:
ref = res_json['answer'][i]
ref_list.append(ref)
return ref_list
- 参数设置
# 设置清除按钮
def on_btn_click():
del st.session_state.messages
# 设置参数
def set_config():
# 设置基本参数
base_config = {"model_name":"","use_ref":"","use_topk":"","top_k":"","use_similar_score":"","max_similar_score":""}
# 设置模型参数
model_config = {'top_k':'','top_p':'','temperature':'','max_length':'','do_sample':""}
# 左边栏设置
with st.sidebar:
model_name = st.radio(
"模型选择:",
["baichuan2-13B-chat", "qwen-14B-chat","chatglm-6B","chatglm3-6B"],
index="0",
)
base_config['model_name'] = model_name
set_ref = st.radio(
"是否使用外部知识库:",
["是","否"],
index="0",
)
base_config['use_ref'] = set_ref
if set_ref=="是":
set_topk_score = st.radio(
'设置选择参考文献的方式:',
['use_topk','use_similar_score'],
index='0',
)
if set_topk_score=='use_topk':
set_topk = st.slider(
'Top_K', 1, 10, 5,step=1
)
base_config['top_k'] = set_topk
base_config['use_topk'] = True
base_config['use_similar_score'] = False
set_score = st.empty()
elif set_topk_score=='use_similar_score':
set_score = st.slider(
"Max_Similar_Score",0.00,1.00,0.70,step=0.01
)
base_config['max_similar_score'] = set_score
base_config['use_similar_score'] = True
base_config['use_topk'] = False
set_topk = st.empty()
else:
set_topk_score = st.empty()
set_topk = st.empty()
set_score = st.empty()
sample = st.radio("Do Sample", ('True', 'False'))
max_length = st.slider("Max Length", min_value=64, max_value=2048, value=1024)
top_p = st.slider(
'Top P', 0.0, 1.0, 0.7, step=0.01
)
temperature = st.slider(
'Temperature', 0.0, 2.0, 0.05, step=0.01
)
st.button("Clear Chat History", on_click=on_btn_click)
# 设置模型参数
model_config['top_p']=top_p
model_config['do_sample']=sample
model_config['max_length']=max_length
model_config['temperature']=temperature
return base_config,model_config
- 设置模型输入格式
# 设置不同模型的输入格式
def set_input_format(model_name):
# ["baichuan2-13B-chat", "baichuan2-7B-chat", "qwen-14B-chat",'chatglm-6B','chatglm3-6B']
if model_name=="baichuan2-13B-chat" or model_name=='baichuan2-7B-chat':
input_format = "{{query}}"
elif model_name=="qwen-14B-chat":
input_format = """
<|im_start|>system
你是一个乐于助人的助手。<|im_end|>
<|im_start|>user
{{query}}<|im_end|>
<|im_start|>assistant"""
elif model_name=="chatglm-6B":
input_format = """{{query}}"""
elif model_name=="chatglm3-6B":
input_format = """
<|system|>
You are ChatGLM3, a large language model trained by Zhipu.AI. Follow the user's instructions carefully. Respond using markdown.
<|user|>
{{query}}
<|assistant|>
"""
return input_format
- 加载模型
# 加载模型和分词器
@st.cache_resource
def load_model(model_name):
if model_name=="baichuan2-13B-chat":
model = AutoModelForCausalLM.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",trust_remote_code=True)
lora_path = ""
tokenizer = AutoTokenizer.from_pretrained("baichuan-inc/Baichuan2-13B-Chat",trust_remote_code=True)
model.to("cuda:0")
elif model_name=="qwen-14B-chat":
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-14B-Chat",trust_remote_code=True)
lora_path = ""
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-14B-Chat",trust_remote_code=True)
model.to("cuda:1")
elif model_name=="chatglm-6B":
model = ChatGLMForConditionalGeneration.from_pretrained('THUDM/chatglm-6b',trust_remote_code=True)
lora_path = ""
tokenizer = AutoTokenizer.from_pretrained('THUDM/chatglm-6b',trust_remote_code=True)
model.to("cuda:2")
elif model_name=="chatglm3-6B":
model = AutoModelForCausalLM.from_pretrained('THUDM/chatglm3-6b',trust_remote_code=True)
lora_path = ""
tokenizer = AutoTokenizer.from_pretrained('THUDM/chatglm3-6b',trust_remote_code=True)
model.to("cuda:3")
# 加载lora包
model = PeftModel.from_pretrained(model,lora_path)
return model,tokenizer
- 推理参数设置
def llm_chat(model_name,model,tokenizer,model_config,query):
response = ''
top_k = model_config['top_k']
top_p = model_config['top_p']
max_length = model_config['max_length']
do_sample = model_config['do_sample']
temperature = model_config['temperature']
if model_name=="baichuan2-13B-chat" or model_name=='baichuan-7B-chat':
messages = []
messages.append({"role": "user", "content": query})
response = model.chat(tokenizer, messages)
elif model_name=="qwen-14B-chat":
response, history = model.chat(tokenizer, query, history=None, top_p=top_p, max_new_tokens=max_length, do_sample=do_sample, temperature=temperature)
elif model_name=="chatglm-6B":
response, history = model.chat(tokenizer, query, history=None, top_p=top_p, max_length=max_length, do_sample=do_sample, temperature=temperature)
elif model_name=="chatglm3-6B":
response, history= model.chat(tokenizer, query, top_p=top_p, max_length=max_length, do_sample=do_sample, temperature=temperature)
return response
- 主程序
if __name__=="__main__":
#对话的图标
user_avator = ""
robot_avator = ""
if "messages" not in st.session_state:
st.session_state.messages = []
torch.cuda.empty_cache()
base_config,model_config = set_config()
model_name = base_config['model_name']
use_ref = base_config['use_ref']
model,tokenizer = load_model(model_name=model_name)
input_format = set_input_format(model_name=model_name)
header_text = f'Large Language Model :{model_name}'
st.header(header_text)
if use_ref=="是":
col1, col2 = st.columns([5, 3])
with col1:
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar=message.get("avatar")):
st.markdown(message["content"])
if user_query := st.chat_input("请输入内容..."):
with col1:
with st.chat_message("user", avatar=user_avator):
st.markdown(user_query)
st.session_state.messages.append({"role": "user", "content": user_query, "avatar": user_avator})
with st.chat_message("robot", avatar=robot_avator):
message_placeholder = st.empty()
use_top_k = base_config['use_topk']
if use_top_k:
top_k = base_config['top_k']
use_similar_score = base_config['use_similar_score']
ref_list = get_reference(user_query,use_top_k=use_top_k,top_k=top_k,use_similar_score=use_similar_score)
else:
use_top_k = base_config['use_topk']
use_similar_score = base_config['use_similar_score']
threshold = base_config['max_similar_score']
ref_list = get_reference(user_query,use_top_k=use_top_k,use_similar_score=use_similar_score,threshold=threshold)
if ref_list:
context = ""
for ref in ref_list:
context = context+ref['para']+"\n"
context = context.strip('\n')
query = f'''
上下文:
【
{context}
】
只能根据提供的上下文信息,合理回答下面的问题,不允许编造内容,不允许回答无关内容。
问题:
【
{user_query}
】
'''
else:
query = user_query
query = input_format.replace("{{query}}",query)
print('输入:',query)
max_len = model_config['max_length']
if len(query)>max_len:
cur_response = f'字数超过{max_len},请调整max_length。'
else:
cur_response = llm_chat(model_name,model,tokenizer,model_config,query)
fs.write(f'输入:{query}')
fs.write('\n')
fs.write(f'输出:{cur_response}')
fs.write('\n')
sys.stdout.flush()
if len(query)<max_len:
if ref_list:
cur_response = f"""
大模型将根据外部知识库回答您的问题:{cur_response}
"""
else:
cur_response = f"""
大模型将根据预训练时的知识回答您的问题,存在编造事实的可能性。因此以下输出仅供参考:{cur_response}
"""
message_placeholder.markdown(cur_response)
st.session_state.messages.append({"role": "robot", "content": cur_response, "avatar": robot_avator})
with col2:
ref_list = get_reference(user_query)
if ref_list:
for ref in ref_list:
ques = ref['ques']
answer = ref['para']
score = ref['prob']
question = f'{ques}--->score: {score}'
with st.expander(question):
st.write(answer)
else:
for message in st.session_state.messages:
with st.chat_message(message["role"], avatar=message.get("avatar")):
st.markdown(message["content"])
if user_query := st.chat_input("请输入内容..."):
with st.chat_message("user", avatar=user_avator):
st.markdown(user_query)
st.session_state.messages.append({"role": "user", "content": user_query, "avatar": user_avator})
with st.chat_message("robot", avatar=robot_avator):
message_placeholder = st.empty()
query = input_format.replace("{{query}}",user_query)
max_len = model_config['max_length']
if len(query)>max_len:
cur_response = f'字数超过{max_len},请调整max_length。'
else:
cur_response = llm_chat(model_name,model,tokenizer,model_config,query)
fs.write(f'输入:{query}')
fs.write('\n')
fs.write(f'输出:{cur_response}')
fs.write('\n')
sys.stdout.flush()
cur_response = f"""
大模型将根据预训练时的知识回答您的问题,存在编造事实的可能性。因此以下输出仅供参考:{cur_response}
"""
message_placeholder.markdown(cur_response)
st.session_state.messages.append({"role": "robot", "content": cur_response, "avatar": robot_avator})
- 可视化界面展示

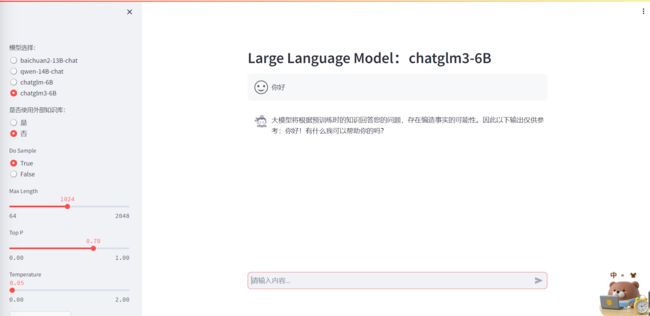
总结
Streamlit工具使用非常方便,说明文档清晰。
这个可视化界面集成了多个大模型+外部知识检索,同时可以在线调整模型参数,使用方便。
完整代码:https://github.com/hjandlm/Streamlit_LLM_QA
参考
[1] https://docs.streamlit.io/
[2] http://cw.hubwiz.com/card/c/streamlit-manual/
[3] https://github.com/hiyouga/LLaMA-Factory/tree/9093cb1a2e16d1a7fde5abdd15c2527033e33143
