Flink笔记
Flink 简介和特点
简介:
Flink 项目的理念是:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
特点:
事件驱动型(Event-driven)
流与批的世界观
分层 api
快速上手
搭建 maven 工程 FlinkTutorial
pom文件添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-javaartifactId>
<version>1.10.1version>
dependency>
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-java_2.12artifactId>
<version>1.10.1version>
dependency>
dependencies>
批处理wordcount
package com.jxtele;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author liuhui
* @version 1.0
* @description: TODO 批处理 wordcount
* @date 2021/11/10 3:39 下午
*/
public class WordCount {
public static void main(String[] args) throws Exception {
// 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 从文件中读取数据
String inputPath = "/Users/liuhui/Documents/bigData/idea/workspace/FlinkTutorial/src/main/resources/hello.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 空格分词打散之后,对单词进行 groupby 分组,然后用 sum 进行聚合
DataSet<Tuple2<String, Integer>> wordCountDataSet =
inputDataSet.flatMap(new MyFlatMapper())
.groupBy(0) //安装第一个位置的word 分组
.sum(1);//将第二个位置的数据求和
// 打印输出
wordCountDataSet.print();
}
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String,
Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws
Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
流处理wordcount
package com.jxtele;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author liuhui
* @version 1.0
* @description: TODO 流处理 wordcount
* @date 2021/11/10 3:44 下午
*/
public class StreamWordCount {
public static void main(String[] args) throws Exception{
//创建流处理执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// // 从文件中读取数据
// String inputPath = "/Users/liuhui/Documents/bigData/idea/workspace/FlinkTutorial/src/main/resources/hello.txt";
// DataStream inputDataStream = env.readTextFile(inputPath);
DataStream<String> inputDataStream = env.socketTextStream("hadoop102", 7777);
DataStream<Tuple2<String, Integer>> wordCountDataStream = inputDataStream
.flatMap( new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
wordCountDataStream.print().setParallelism(1);
env.execute();
}
}
注意 测试方法:利用netcat 模拟流式输入 ,在 linux 系统中用 netcat 命令进行发送测试。
没有netcat命令可安装
##安装
[root@hadoop102 hadoop]# yum install -y nc
##使用
[root@hadoop102 hadoop]# nc -lk 7777

Flink部署
Yarn 模式
(1)Session-cluster模式:
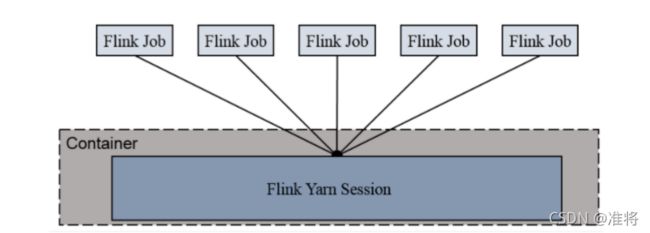
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager;共享资源;适合规模小执行时间短的作业。在 yarn 中初始化一个 flink 集群,开辟指定的资源,以后提交任务都向这里提交。这个 flink 集群会常驻在 yarn 集群中,除非手工停止。
(2)Per-Job-Cluster 模式:

一个 Job 会对应一个集群,每提交一个作业会根据自身的情况,都会单独向 yarn申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请;适合规模大长时间运行的作业。每次提交都会创建一个新的 flink 集群,任务之间互相独立,互不影响,方便管理。任务执行完成之后创建的集群也会消失。
Session-cluster模式
(1)启动hadoop集群
[hadoop@hadoop102 ~]$ myhadoop.sh start
=================== 启动 hadoop 集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop102]
Starting datanodes
Starting secondary namenodes [hadoop104]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
--------------- 启动 historyserver ---------------
(2)安装flink,,启动flink, 启动 yarn-session
##下载,解压flink
[hadoop@hadoop102 module]$ ls
apache-hive-3.1.2-bin hadoop-3.1.3 jdk1.8.0_212 sqoop
flink-1.10.1-bin-scala_2.12.tgz hbase-2.0.5 kafka zookeeper-3.4.5-cdh5.12.1
[hadoop@hadoop102 module]$ tar zxvf flink-1.10.1-bin-scala_2.12.tgz
[hadoop@hadoop102 software]$ cd ../module/
[hadoop@hadoop102 module]$ cd flink-1.10.1/
[hadoop@hadoop102 flink-1.10.1]$ ls
bin conf examples lib LICENSE licenses log NOTICE opt plugins README.txt
##修改 flink/conf/flink-conf.yaml 文件:
[hadoop@hadoop102 flink-1.10.1]$ cd conf/
[hadoop@hadoop102 conf]$ vi flink-conf.yaml
## 修改 /conf/slaves 文件:
[hadoop@hadoop102 conf]$ vi slaves
hadoop103
hadoop104
##分发给另外两台机器
[hadoop@hadoop102 module]$ xsync flink-1.10.1/
## 启动flink
[hadoop@hadoop102 bin]$ ./start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop102.
Starting taskexecutor daemon on host hadoop103.
Starting taskexecutor daemon on host hadoop104.
##启动 yarn-session
[hadoop@hadoop102 bin]$ ./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
-n(–container):TaskManager 的数量。
-s(–slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个
taskmanager 的 slot 的个数为 1,有时可以多一些 taskmanager,做冗余。
-jm:JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。

(3)执行任务
[hadoop@hadoop102 bin]$ ./flink run -c com.jxtele.StreamWordCount /opt/software/FlinkTutorial-1.0-SNAPSHOT.jar
Job has been submitted with JobID 8b47909eeb5b398bb3d3b7aa492d114a
(4)去yarn控制台查看任务状态

(5)测试

(6)取消yarn-session
[hadoop@hadoop102 bin]$ yarn application --kill application_1636546149277_0001
2021-11-10 23:43:30,001 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.56.103:8032
Application application_1636546149277_0001 has already finished
[hadoop@hadoop102 bin]$
Per Job Cluster模式
(1)启动hadoop集群(略)
(2)不启动 yarn-session,直接执行job
[hadoop@hadoop102 bin]$ ./flink run -m yarn-cluster -c com.jxtele.StreamWordCount /opt/software/FlinkTutorial-1.0-SNAPSHOT.jar
2021-11-10 23:49:00,737 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/module/flink-1.10.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-11-10 23:49:00,737 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory ('/opt/module/flink-1.10.1/conf') already contains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file.
2021-11-10 23:49:01,120 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at hadoop103/192.168.56.103:8032
2021-11-10 23:49:01,280 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.YarnClusterDescriptor to locate the jar
2021-11-10 23:49:01,422 WARN org.apache.flink.yarn.YarnClusterDescriptor - Neither the HADOOP_CONF_DIR nor the YARN_CONF_DIR environment variable is set. The Flink YARN Client needs one of these to be set to properly load the Hadoop configuration for accessing YARN.
2021-11-10 23:49:01,476 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskManagerMemoryMB=1728, slotsPerTaskManager=1}
2021-11-10 23:49:05,154 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master application_1636546149277_0002
2021-11-10 23:49:05,201 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1636546149277_0002
2021-11-10 23:49:05,201 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated
2021-11-10 23:49:05,212 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED
2021-11-10 23:49:13,816 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully.
2021-11-10 23:49:13,816 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface hadoop104:33005 of application 'application_1636546149277_0002'.
Job has been submitted with JobID 5fba182fcf6d4b78aa4ea4f0d1957122
(3)测试


附尚硅谷学习资料: 链接: https://pan.baidu.com/s/1BrnKgO59vXq2Cv0uwc9G2Q 密码:
mvqg