数据挖掘十大算法--K-均值聚类算法
一、相异度计算
在正式讨论聚类前,我们要先弄清楚一个问题:如何定量计算两个可比较元素间的相异度。用通俗的话说,相异度就是两个东西差别有多大,例如人类与章鱼的相异度明显大于人类与黑猩猩的相异度,这是能我们直观感受到的。但是,计算机没有这种直观感受能力,我们必须对相异度在数学上进行定量定义。
设 ,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:
,其中X,Y是两个元素项,各自具有n个可度量特征属性,那么X和Y的相异度定义为:
 ,其中R为实数域。也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
,其中R为实数域。也就是说相异度是两个元素对实数域的一个映射,所映射的实数定量表示两个元素的相异度。
下面介绍不同类型变量相异度计算方法。
1、标量
(1)标量也就是无方向意义的数字,也叫标度变量。现在先考虑元素的所有特征属性都是标量的情况。例如,计算X={2,1,102}和Y={1,3,2}的相异度。一种很自然的想法是用两者的欧几里得距离来作为相异度,欧几里得距离的定义如下:

其意义就是两个元素在欧氏空间中的集合距离,因为其直观易懂且可解释性强,被广泛用于标识两个标量元素的相异度。将上面两个示例数据代入公式,可得两者的欧氏距离为:
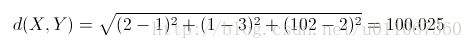
(2)除欧氏距离外,常用作度量标量相异度的还有曼哈顿距离和闵可夫斯基距离,两者定义如下:
曼哈顿距离 : 
(3) 闵可夫斯基距离:

(4)皮尔逊系数(Pearson Correlation Coefficient)
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商.
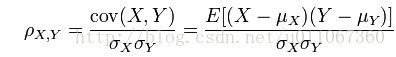
(其中,E为数学期望或均值,D为方差,D开根号为标准差,E{ [X-ux] [Y-uy]}称为随机变量X与Y的协方差,记为Cov(X,Y),即Cov(X,Y) = E{ [X-ux] [Y-ux},而两个变量之间的协方差和标准差的商则称为随机变量X与Y的相关系数,记为 )
)
欧氏距离和曼哈顿距离可以看做是闵可夫斯基距离在p=2和p=1下的特例。另外这三种距离都可以加权,这个很容易理解。
下面要说一下标量的规格化问题。上面这样计算相异度的方式有一点问题,就是取值范围大的属性对距离的影响高于取值范围小的属性。例如上述例子中第三个属性的取值跨度远大于前两个,这样不利于真实反映真实的相异度,为了解决这个问题,一般要对属性值进行规格化。
所谓规格化就是将各个属性值按比例映射到相同的取值区间,这样是为了平衡各个属性对距离的影响。通常将各个属性均映射到[0,1]区间,映射公式为:

其中max(ai)和min(ai)表示所有元素项中第i个属性的最大值和最小值。例如,将示例中的元素规格化到[0,1]区间后,就变成了X’={1,0,1},Y’={0,1,0},重新计算欧氏距离约为1.732。
2、二元变量
所谓二元变量是只能取0和1两种值变量,有点类似布尔值,通常用来标识是或不是这种二值属性。对于二元变量,上一节提到的距离不能很好标识其相异度,我们需要一种更适合的标识。一种常用的方法是用元素相同序位同值属性的比例来标识其相异度。
设有X={1,0,0,0,1,0,1,1},Y={0,0,0,1,1,1,1,1},可以看到,两个元素第2、3、5、7和8个属性取值相同,而第1、4和6个取值不同,那么相异度可以标识为3/8=0.375。一般的,对于二元变量,相异度可用“取值不同的同位属性数/单个元素的属性位数”标识。
上面所说的相异度应该叫做对称二元相异度。现实中还有一种情况,就是我们只关心两者都取1的情况,而认为两者都取0的属性并不意味着两者更相似。例如在根据病情对病人聚类时,如果两个人都患有肺癌,我们认为两个人增强了相似度,但如果两个人都没患肺癌,并不觉得这加强了两人的相似性,在这种情况下,改用“取值不同的同位属性数/(单个元素的属性位数-同取0的位数)”来标识相异度,这叫做非对称二元相异度。如果用1减去非对称二元相异度,则得到非对称二元相似度,也叫Jaccard系数,是一个非常重要的概念。
3、分类变量 分类变量是二元变量的推广,类似于程序中的枚举变量,但各个值没有数字或序数意义,如颜色、民族等等,对于分类变量,用“取值不同的同位属性数/单个元素的全部属性数”来标识其相异度。
4、序数变量
序数变量是具有序数意义的分类变量,通常可以按照一定顺序意义排列,如冠军、亚军和季军。对于序数变量,一般为每个值分配一个数,叫做这个值的秩,然后以秩代替原值当做标量属性计算相异度。
5、向量
对于向量,由于它不仅有大小而且有方向,所以闵可夫斯基距离不是度量其相异度的好办法,一种流行的做法是用两个向量的余弦度量,其度量公式为:

其中||X||表示X的欧几里得范数。要注意,余弦度量度量的不是两者的相异度,而是相似度!
二、聚类问题
所谓聚类问题,就是给定一个元素集合D,其中每个元素具有n个可观察属性,使用某种算法将D划分成k个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相异度尽可能高。其中每个子集叫做一个簇。
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。本文仅介绍一种最简单的聚类算法——k均值(k-means)算法。
1、算法简介
k-means算法,也被称为k-平均或k-均值,是一种得到最广泛使用的聚类算法。 它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,
算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。
2、算法描述
1、为中心向量c1, c2, …, ck初始化k个种子
2、分组:
(1)将样本分配给距离其最近的中心向量
(2)由这些样本构造不相交( non-overlapping )的聚类
3、确定中心:
用各个聚类的中心向量作为新的中心
4、重复分组和确定中心的步骤,直至算法收敛。
3、算法 k-means算法
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇,使平方误差准则最小。
算法步骤:
1.为每个聚类确定一个初始聚类中心,这样就有K 个初始聚类中心。
2.将样本集中的样本按照最小距离原则分配到最邻近聚类
3.使用每个聚类中的样本均值作为新的聚类中心。
4.重复步骤2.3直到聚类中心不再变化。
5.结束,得到K个聚类
PS
1、将样本分配给距离它们最近的中心向量,并使目标函数值减小
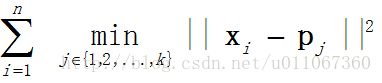
2、更新簇平均值
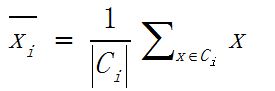
3、计算准则函数E
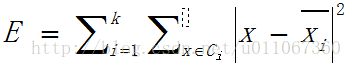 计算准则函数
计算准则函数
E
4、划分聚类方法对数据集进行聚类时包括如下三个要点:
(1)选定某种距离作为数据样本间的相似性度量
上面讲到,k-means聚类算法不适合处理离散型属性,对连续型属性比较适合。因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。下面我再给大家具体介绍一下欧式距离。 平均值
假设给定的数据集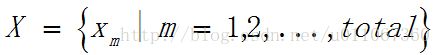 ,X中的样本用d个描述属性A1,A2…Ad来表示,并且d个描述属性都是连续型属性。数据样本xi=(xi1,xi2,…xid),xj=(xj1,xj2,…xjd)其中,xi1,xi2,…xid和xj1,xj2,…xjd分别是样本xi和xj对应d个描述属性A1,A2,…Ad的具体取值。样本xi和xj之间的相似度通常用它们之间的距离d(xi,xj)来表示,距离越小,样本xi和xj越相似,差异度越小;距离越大,样本xi和xj越不相似,差异度越大。
,X中的样本用d个描述属性A1,A2…Ad来表示,并且d个描述属性都是连续型属性。数据样本xi=(xi1,xi2,…xid),xj=(xj1,xj2,…xjd)其中,xi1,xi2,…xid和xj1,xj2,…xjd分别是样本xi和xj对应d个描述属性A1,A2,…Ad的具体取值。样本xi和xj之间的相似度通常用它们之间的距离d(xi,xj)来表示,距离越小,样本xi和xj越相似,差异度越小;距离越大,样本xi和xj越不相似,差异度越大。
欧式距离公式如下:
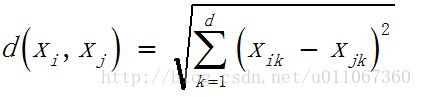
(2)选择评价聚类性能的准则函数
k-means聚类算法使用误差平方和准则函数来 评价聚类性能。给定数据集X,其中只包含描述属性,不包含类别属性。假设X包含k个聚类子集X1,X2,…XK;各个聚类子集中的样本数量分别为n1,n2,…,nk;各个聚类子集的均值代表点(也称聚类中心)分别为m1,m2,…,mk。则误差平方和准则函数公式为:
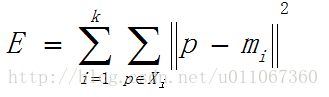
(3)相似度的计算根据一个簇中对象的平均值来进行。
1)将所有对象随机分配到k个非空的簇中。
2)计算每个簇的平均值,并用该平均值代表相应的簇。
3)根据每个对象与各个簇中心的距离,分配给最近的簇。
4)然后转2),重新计算每个簇的平均值。这个过程不断重复直到满足某个准则函数才停止
三、聚类例子

数据对象集合S见上表,作为一个聚类分析的二维样本,要求的簇的数量k=2。
(1)选择 ,
,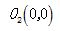 为初始的簇中心,即
为初始的簇中心,即
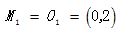 ,
, 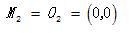 。
。
(2)对剩余的每个对象,根据其与各个簇中心的距离,将它赋给最近的簇
对O3 :
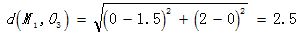
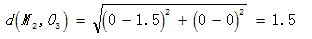
显然 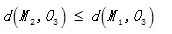 O3,故将C2分配给
O3,故将C2分配给
对于O4:
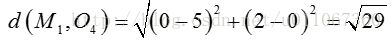
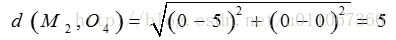
因为: 所以将O4分配给C2
所以将O4分配给C2
对于O5:
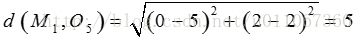

因为: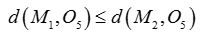 所以讲O5分配给C1
所以讲O5分配给C1
更新,得到新簇 和
和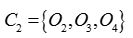
计算平方误差准则,单个方差为
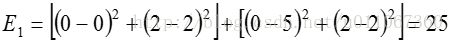
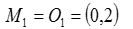
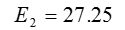
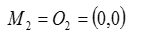
总体平均方差是:

(3)计算新的簇的中心。
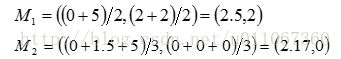
重复(2)和(3),得到O1分配给C1;O2分配给C2,O3分配给C2 ,O4分配给C2,O5分配给C1。更新,得到新簇
 和
和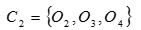 。 中心为
。 中心为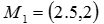 ,
,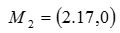 。
。
单个方差分别为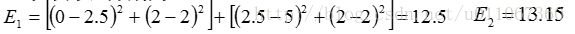
总体平均误差是:
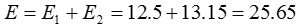
由上可以看出,第一次迭代后,总体平均误差值52.25~25.65,显著减小。由于在两次迭代中,簇中心不变,所以停止迭代过程,算法停止。
PS
1、k-means算法的性能分析
主要优点:
是解决聚类问题的一种经典算法,简单、快速。
对处理大数据集,该算法是相对可伸缩和高效率的。因为它的复杂度是0 (n k t ) , 其中, n 是所有对象的数目, k 是簇的数目, t 是迭代的次数。通常k <
主要缺点
在簇的平均值被定义的情况下才能使用,这对于处理符号属性的数据不适用。
必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
它对于“躁声”和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响。
K-Means算法对于不同的初始值,可能会导致不同结果。解决方法:
1.多设置一些不同的初值,对比最后的运算结果)一直到结果趋于稳定结束,比较耗时和浪费资源
2.很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这也是 K-means 算法的一个不足。有的算法是通过类的自动合并和分裂,得到较为合理的类型数目 K.
2、k-means算法的改进方法——k-prototype算法
k-Prototype算法:可以对离散与数值属性两种混合的数据进行聚类,在k-prototype中定义了一个对数值与离散属性都计算的相异性度量标准。
K-Prototype算法是结合K-Means与K-modes算法,针对混合属性的,解决2个核心问题如下:
1.度量具有混合属性的方法是,数值属性采用K-means方法得到P1,分类属性采用K-modes方法P2,那么D=P1+a*P2,a是权重,如果觉得分类属性重要,则增加a,否则减少a,a=0时即只有数值属性
2.更新一个簇的中心的方法,方法是结合K-Means与K-modes的更新方法。
3、k-means算法的改进方法——k-中心点算法
k-中心点算法:k -means算法对于孤立点是敏感的。为了解决这个问题,不采用簇中的平均值作为参照点,可以选用簇中位置最中心的对象,即中心点作为参照点。这样划分方法仍然是基于最小化所有对象与其参照点之间的相异度之和的原则来执行的。
K-means算法对于不同的初始值,可能会导致不同结果。解决方法:
1.多设置一些不同的初值,对比最后的运算结果,一直到结果趋于稳定结束
2.很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。通过类的自动合并和分裂,得到较为合理的类型数目 K,例如 ISODATA 算法。
K-means算法的其他改进算法如下:
1. k-modes 算法:实现对离散数据的快速聚类,保留了k-means算法的效率同时将k-means的应用范围扩大到离散数据。
2. k-Prototype算法:可以对离散与数值属性两种混合的数据进行聚类,在k-prototype中定义了一个对数值与离散属性都计算的相异性度量标准。