SeaTunnel安装及测试
一. 简介
架构于Spark和Flink之上的分布式的支持海量数据实时同步的高性能分布式数据集成平台
官网:http://seatunnel.incubator.apache.org/
Gitee:https://gitee.com/seatunnel/incubator-seatunnel
日常海量数据同步中常见问题:
1.缺乏统一的数据集成平台:
在类似SeaTunnel数据集成平台出来之前,开发者使用的是 Datax+Azkaban 分别作为数据采集的组件和调度执行的组件,使用 Git 作为代码管理;一个熟手配置一个数据集成任务大约通过 7 步:编辑,Commit,Push,打包,上传,页面操作,数据校验等, 一个任务的开发最起码需要 30~60 分钟,还必须保证这中间不能被打扰,没有出现异常情况,十分麻烦。
2.数据孤岛现象(eg:ClickHouse):
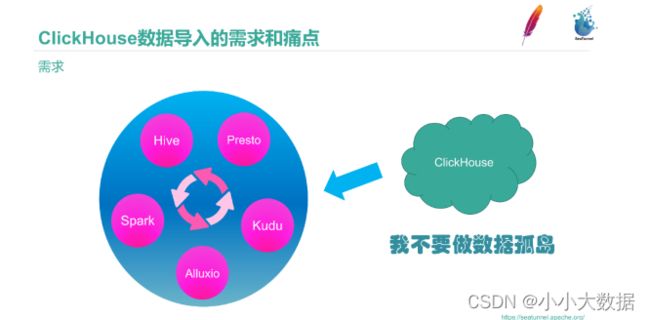
3.数据丢失与重复
4.任务堆积与延迟
5.吞吐量低
6.应用到生产环境周期长
7.缺少应用运行状态监控
特点:
低代码开发,易用性高,易维护
实时流式处理
离线多源数据分析
高性能、海量数据处理能力
模块化和插件化,易于扩展
支持的插件:
Input:File,Hdfs,Kafka,S3,Socket及自行开发的plugin
Filter:SQL,K-V,Json,Add,Drop,Split,Table及自行开发的plugin
Output:ES,File,Hdfs,Kafka,Mysql,S3,JDBC,Stdout及自行开发的plugin
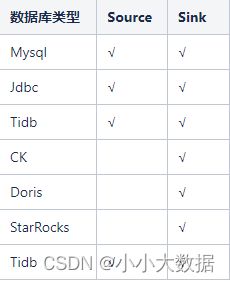
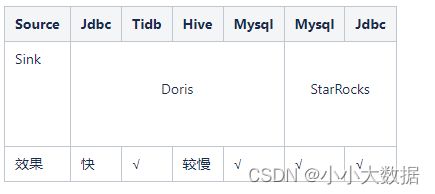
插件支持情况:
Spark插件:
Flink插件:
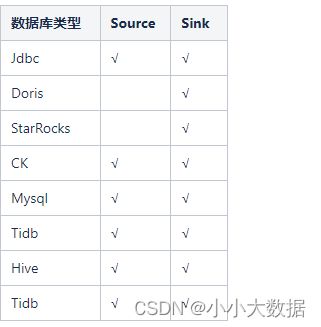
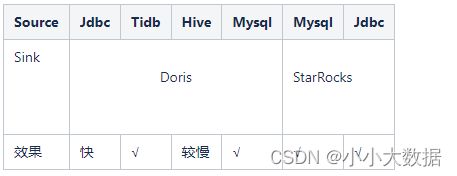
SeaTunnel官网暂不支持Doris,StarRocks作为数据Source端,若有具体业务需求可能需要具体开发;
Doris,StarRocks作为Sink端,在数据格式/质量上基本没有问题,只是不同的插件时间上有差异
日常使用:
会被用来做出仓入仓工具;
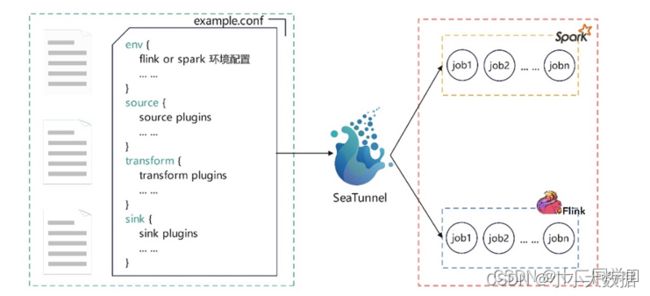
编辑配置文件,然后SeaTunnel将之转换为具体的Spark或Flink任务
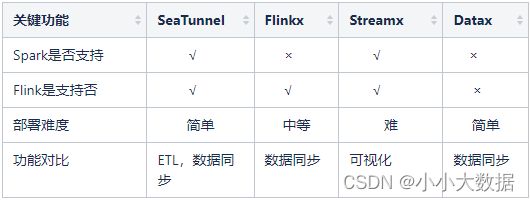
竞品比较:
参考文章:
SeaTunnel在oppo特征平台的集成实践
升级OLAP平台,SeaTunnel在唯品会的实践
二. 基本原理
两个启动脚本:
提交spark任务用 start-seatunnel-spark.sh
提交flink任务则用 start-seatunnel-flink.sh
SeaTunnel配置文件应包含四部分配置组件:
env{} → source{} → transform{} → sink{}
source,transform,sink这三部分可以看做一个pipeline。
在Source和Sink数据同构时,如果业务上也不需要对数据进行转换,那么transform中的内容可以为空,反之transform具体需根据业务情况来定。
env块:
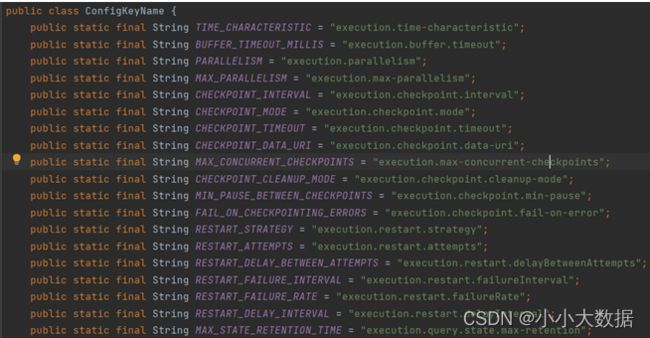
env块中可以直接写spark或flink支持的配置项。比如引擎选择,并行度,检查点间隔时间,检查点hdfs路径等。在SeaTunnel源码的ConfigKeyName类中,声明了env块中所有可用的key。
source块:
用来声明数据源,可以声明多个连接器
source {
hdfs{ ... }
elasticsearch { .... }
jdbc { .... }
}
transform块:
可能根据具体业务进一步处理数据,因此提供转换模块;当然也可以直接从Source到Sink。
可以同时声明多个转换插件:添加校验、转换、日期、删除、Grok、Json、KV、大/小写、删除、重命名、重分区、替换、样本、拆分、Sql、表、截断、Unid,自主开发的过滤器插件等
sink块:
定义如何以及在何处写入数据,将数据从一个位置同步到另一个位置

小结:

三.SeaTunnel本地环境搭建
基础:
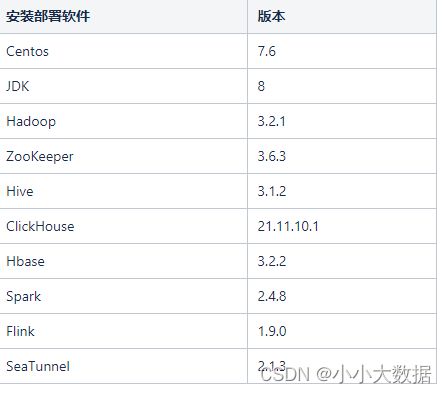
安装:
#下载解压
sudo wget "apache-seatunnel-incubating-2.1.3-bin.tar.gz"
sudo tar -zxvf apache-seatunnel-incubating-2.1.3-bin.tar.gz
#配置环境变量
sudo vim /etc/profile
export SEATUNNEL_HOME=/usr/local/apache-seatunnel-incubating-2.1.3
export PATH=$PATH:${SEATUNNEL_HOME}/bin
#环境变量生效
source /etc/profile
测试:
从Hive中抽数插入到CK中的配置,数据源是Hive的一张表,通过SeaTunnel插件根据id字段进行分片插入CK集群不同分片
#创建测试文件
vim /usr/local/apache-seatunnel-incubating-2.1.3/config/hive-console.conf
#配置Spark参数
spark { spark.sql.catalogImplementation = "hive"
spark.app.name = "hive2clickhouse"
spark.executor.instances = 30
spark.executor.cores = 1
spark.executor.memory = "2g"
spark.ui.port = 13000
}
input {
hive {
pre_sql = "select id,name,create_time from table"
table_name = "table_tmp"
}
}
filter {
convert {
source_field = "data_source"
new_type = "UInt8"
}
org.interestinglab.waterdrop.filter.Slice {
source_table_name = "table_tmp"
source_field = "id"
slice_num = 2
slice_code = 0
result_table_name = "table_8123"
}
org.interestinglab.waterdrop.filter.Slice {
source_table_name = "table_tmp"
source_field = "id"
slice_num = 2
slice_code = 1
result_table_name = "table_8124"
}
}
output {
clickhouse {
source_table_name="table_8123"
host = "ip1:8123"
database = "db_name"
username="username"
password="pwd"
table = "model_score_local"
fields = ["id","name","create_time"]
clickhouse.socket_timeout = 50000
retry_codes = [209, 210]
retry = 3
bulk_size = 500000
}
clickhouse {
source_table_name="table_8124"
host = "ip2:8123"
database = "db_name"
username="username"
password="pwd"
table = "model_score_local"
fields = ["id","name","create_time"]
clickhouse.socket_timeout = 50000
retry_codes = [209, 210]
retry = 3
bulk_size = 500000
}
}
#启动测试
/bin/start-waterdrop.sh --master local --deploy-mode client --config/hive-console.conf
四. 应用案例
Hive数据导入StarRocks
#创建文件任务
vim config/text01.conf
#配置内容
env {
spark.app.name = "ads_product_sale_d"
spark.executor.instances = 1
spark.dynamicAllocation.maxExecutors = 20
spark.executor.cores = 1
spark.executor.memory = "8g"
spark.sql.catalogImplementation = "hive"
spark.sql.hive.verifyPartitionPath = "true"
}
source {
hive {
pre_sql = "select platform_id,cat_id from dws.dws_prd_product_detail_d where day_id ='2022-12- 14‘ "
result_table_name = "ads_product_sale_d"
}
}
transform {
sql {
sql = "select platform_id,cat_id from ads_product_sale_d",
table_name = "ads_product_sale_d"
}
}
sink {
Doris {
fenodes="10.4.102.46:8030"
database="example_db"
table="ads_product_sale_d"
user="root"
password=""
batch_size=10000
doris.column_separator="\t"
doris.columns="platform_id,cat_id"
}
}
#启动任务
bin/start-seatunnel-flink.sh --config config/text01.conf -i age=18
五. 发展前景——企业级服务化之路
基于 SeaTunnel 实现了可视化的数据集成服务,我相信服务化必然,一定,100%是SeaTunnel未来的不可缺少的一部分。
核心目标:
脚本管控:让用户通过 WebUI,以参数的形式配置任务信息而非脚本的方式来表达自己的业务需求,这样无论是对于非专业人员还是开发人员都会节省很大精力
作业及实例管理:任务触发,查看日志记录,重跑,Kill等
整体架构设计:
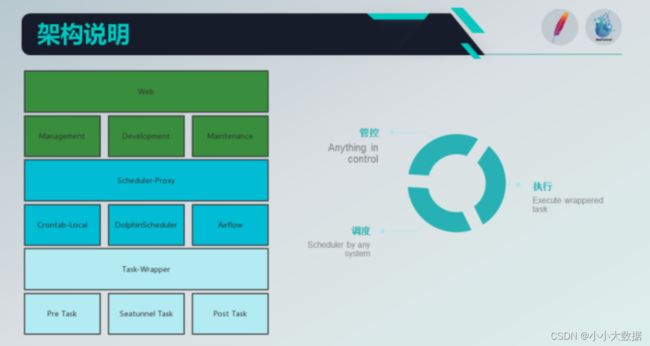
**管控:**对数据源、用户、权限、脚本、作业、实例的管控,任何在 WebUi 上看到的内容都会被管控
管理能力:针对于数据源的增删改查以及连接性测试,数据源的映射、数据探查等的能力;此外,页面上每个能看见的页面、菜单、按钮、数据,资源管理、自定义 connector、trasnform 管理、项目空间等都应该纳入管控
开发能力:基本上就是针对的脚本的增删改查(保存、执行、停止、测试、发布、基本参数展示、调度参数配置、告警参数调整、脚本内容、数据源、transform、并发等)
运维能力:任务的不同时期所要求的内容也不一样,作业运维包括手动触发,暂停等;实例运维则是重跑,Kill,查看日志记录等
调度:
根据配置的不同,负责将任务丢至不同的调度系统中进行调度与执行;上层的作业和实例的管控也依赖于具体的调度系统;
crontabl-local:我们的 SeaTunnel 自成体系,自身就提供了简单的定时调度能力,用户只需要修改下配置,即可快速上手,完成定时数据集成任务的配置与发布
执行(task-wrapper):
1.考虑到仅靠 SeaTunnel 原生的能力是不够的,所以分为两部分: pre-task 和 post-task,与 SeaTunnel 的执行引擎进行组装,变成真正的执行内容
2.完整独立的执行脚本
SeaTunnel WebUi整体项目开发进度
参考文章:
SeaTunnel企业化服务之路