MySQl主从搭建
1.概述
1.1 MySQL主从拓扑图
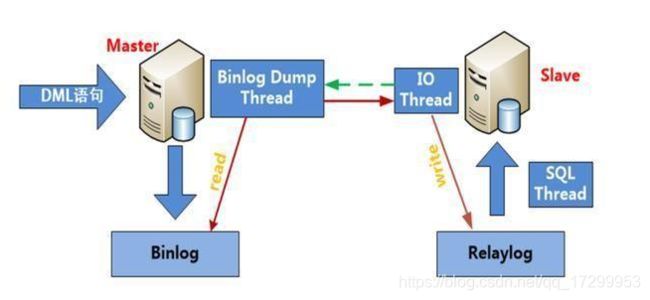
1.2 MySQL配置从库的用处
在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运行。
做数据的热备,主库宕机后能够及时替换主库,保证业务可用性。
架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
1.3 复制数据的步骤
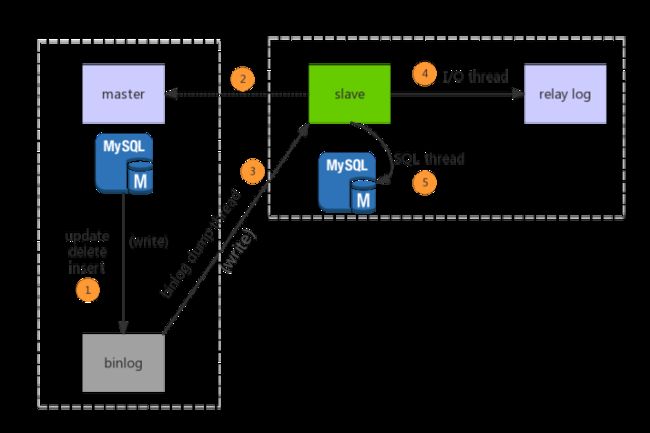
1.主库db的更新事件(update、insert、delete)被写到binlog
2.主库创建一个binlog dump thread,把binlog的内容发送到从库
3.从库启动并发起连接,连接到主库
4.从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
5.从库启动之后,创建一个SQL线程,从relay log里面读取内容,从Exec_Master_Log_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
2.主从搭建步骤
2.1 数据库安装
MySQL数据库的安装可以参照摩天轮其他文章,本文重点是配置主从
| 服务器类别 | IP |
|---|---|
| 主库 | 192.168.180.101 |
| 从库 | 192.168.180.102 |
2.2 主库开启binlog
配置文件[mysqld]下添加如下:
[mysqld]
log-bin=mysql-bin #开启二进制日志
binlog_format=mixed #二进制日志的格式类型
server-id=101 #设置server-id
log-slave-updates=1 #如果主库是其他库的从库的话需要添加此参数,否则从其它库同步的数据不会写入binlog
重启mysql服务
#以下重启方法不是绝对的,各位可以根据自己的安装方法以及安装路径自行重启
mysqladmin -uroot -p -S /u01/my3306/mysql.sock shutdown
/u01/my3306/bin/mysqld_safe --defaults-file=/u01/my3306/my.cnf --user=mysql &
2.3 授权
在主库创建同步账号
CREATE USER 'repl'@'192.168.180.101' IDENTIFIED BY 'test';
grant replication slave, replication client on *.* to 'repl'@'192.168.180.101';
flush privileges;
mysql> CREATE USER 'repl'@'192.168.180.102' IDENTIFIED BY 'test';
Query OK, 0 rows affected (0.01 sec)
mysql> grant replication slave, replication client on *.* to 'repl'@'192.168.180.102';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
2.4 登陆主库查看此时日志状态
mysql> show master status;
+---------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+---------------+----------+--------------+------------------+-------------------+
| binlog.000001 | 256 | | | |
+---------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
2.5 导出主库当前数据
备份此时主库的内容,如果主库为空库则此步骤可以省略
-- 备份之前锁表
mysql> flush table with read lock;
mysqldump -uroot -pabc123 -A -B --events --master-data=2 > /backup/mysql/cw-$(date +%F)-all.sql
-- 备份完成后取消锁
mysql> unlock tables;
2.6 从库指定serverid
配置文件[mysqld]下添加如下:
server-id=102
#从库可以根据自己生产环境的需要来决定是否需要开启二进制日志
server-id不能重复
重启mysql服务
mysqladmin -uroot -p -S /u01/my3306/mysql.sock shutdown
/u01/my3306/bin/mysqld_safe --defaults-file=/u01/my3306/my.cnf --user=mysql &
2.7 从库导入主库数据
通过scp将主库的备份文件同步过来
mysql -uroot -p </backup/mysql/cw-2021-02-11-all.sql
2.8 指定开始同步位置
具体同步位置参考步骤4
mysql> change master to
-> master_host='192.168.180.101',
-> master_user='repl',
-> master_password='test',
-> MASTER_LOG_FILE='binlog.000001',
-> MASTER_LOG_POS=256 ;
Query OK, 0 rows affected, 2 warnings (0.01 sec)
2.9 开启复制
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.180.101
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: binlog.000001
Read_Master_Log_Pos: 256
Relay_Log_File: ipctest-relay-bin.000002
Relay_Log_Pos: 321
Relay_Master_Log_File: binlog.000001
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 256
Relay_Log_Space: 532
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 08260f93-cbe5-11ea-bd0d-000c293fa60d
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set:
Auto_Position: 0
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
Master_public_key_path:
Get_master_public_key: 0
Network_Namespace:
1 row in set (0.00 sec)
3.复制相关参数
| 参数 | 参数用途 |
|---|---|
| Slave_IO_state | 显示当前IO线程的状态,一般情况下就是显示等待主服务器发送二进制日志。 |
| Master_log_file | 显示当前同步的主服务器的二进制日志。 |
| Read_master_log_pos | 显示当前同步到主服务器上二进制日志的偏移量位置。 |
| Relay_master_log_file | 当前中继日志同步的二进制日志。 |
| Relay_log_file | 显示当前写入的中继日志。 |
| Relay_log_pos | 显示当前执行到中继日志的偏移量位置。 |
| Slave_IO_running | 从服务器中IO线程的运行状态,yes代表正常 |
| Slave_SQL_running | 从服务器中sql线程的运行状态,YES代表正常 |
| Exec_Master_log_pos | 表示同步到主服务器的二进制日志的偏移量位置。 |
4.slave启停常用命令
从库执行
| 命令 | 用途 |
|---|---|
| STOP SLAVE IO_THREAD; | 停止IO进程 |
| STOP SLAVE SQL_THREAD; | 停止SQL进程 |
| STOP SLAVE; | 停止IO和SQL进程 |
| START SLAVE IO_THREAD; | 启动IO进程 |
| START SLAVE SQL_THREAD; | 启动SQL进程 |
| START SLAVE; | 启动IO和SQL进程 |
| RESET SLAVE; | 用于让从属服务器忘记其在主服务器的二进制日志中的复制位置, 它会删除master.info和relay-log.info文件,以及所有的中继日志,并启动一个新的中继日志,当你不需要主从的时候可以在从上执行这个操作。 |
| SHOW SLAVE STATUS; | 查看MySQL同步状态 |
| STOP SLAVE;SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;START SLAVE; | 经常会朋友mysql主从同步遇到错误的时候,比如一个主键冲突等,那么我就需要在确保那一行数据一致的情况下临时的跳过这个错误,那就需要使用SQL_SLAVE_SKIP_COUNTER = n命令了,n是表示跳过后面的n个事件 |
| CHANGE MASTER TO MASTER_HOST=‘10.1.1.75’, MASTER_USER=‘replication’, MASTER_PASSWORD=‘123456’, MASTER_LOG_FILE=‘mysql-bin.000006’, MASTER_LOG_POS=106; START SLAVE; | 从指定位置重新同步 |
5.保证主从一致
| 参数 | 参数值 |
|---|---|
| innodb_flush_log_at_trx_commit=1 | 0:log buffer 将每秒一次地写入 log file 中,并且 log file 的 flush (刷到磁盘) 操作同时进行。该模式下在事务提交的时候,不会主动触发写入磁盘的操作。1:每次事务提交时 mysql 都会把 log buffer 的数据写入 log file,并且 flush (刷到磁盘) 中去,该模式为系统默认。2:每次事务提交时 mysql 都会把 log buffer 的数据写入 log file,但是 flush (刷到磁盘) 操作并不会同时进行。该模式下,MySQL 会每秒执行一次 flush (刷到磁盘) 操作 |
| sync_binlog=1 | sync_binlog=0,当事务提交之后,MySQL 不做 fsync 之类的磁盘同步指令刷新 binlog_cache 中的信息到磁盘,而让 Filesystem 自行决定什么时候来做同步,或者 cache 满了之后才同步到磁盘。sync_binlog=n,当每进行 n 次事务提交之后,MySQL 将进行一次 fsync 之类的磁盘同步指令来将 binlog_cache 中的数据强制写入磁盘。 |
| sync_master_info=1 | 每间隔多少事务刷新master.info,如果是table(innodb)设置无效,每个事务都会更新 |
| sync_relay_log_info=1 | 每间隔多少事务刷新relay-log.info,如果是table(innodb)设置无效,每个事务都会更新 |
| sync_relay_log=10000 | 默认为10000,即每10000次sync_relay_log事件会刷新到磁盘。为0则表示不刷新,交由OS的cache控制 |
| master_info_repository=TABLE | 记录主库binlog的信息,可以设置FILE(master.info)或者TABLE(mysql.slave_master_info) |
| relay_log_info_repository=TABLE | 记录备库relaylog的信息,可以设置FILE(relay-log.info)或者TABLE(mysql.slave_relay_log_info) |
6.常见问题
6.1 IO线程出问题
Slave_IO_Running: No
Slave_SQL_Running: Yes
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ‘Could not find first log file name in binary log index file’
问题排查:在主库上
[root@master mysql3306]# cat mysql-bin.index
/home/mysql3306/mysql3306/mysql-bin.000001
发现binlog文件名不正确,需要重新设置。
处理办法
stop slave;
reset slave all;
change master to
master_host=‘192.168.180.101’,
master_user=‘rep’,
master_password=‘rep’,
master_log_file=‘mysql-bin.000001’,
master_log_pos=154,
MASTER_PORT=3306;
start slave;
6.2 SQL线程问题
6.2.1 ERROR 1062
主从数据库不一致的时,slave已经有该条记录,但是我们又在master上插入了同一条记录,此时就会报错.
在从库上执行跳过该insert语句
mysql> stop slave;
mysql> set global sql_slave_skip_counter=1;
mysql> start slave;
问题解决!
6.2.2 ERROR 1032
从库删除一条数据,主库更新该条删除的数据,发生报错
手工把缺失的数据补上
mysql> stop slave;
mysql> set global sql_slave_skip_counter=1;
mysql> start slave;
问题解决!
6.2.3 ERROR 1452
无法在外键的表中插入或者更新参考主键没有的数据
6.2.4 将从库设置为readonly
建议大家线上打开这两个参数,防止主从不一致的产生。
set global read_only=1
只读参数,需要大家注意的对于拥有super权限的用户,该参数不起作用
set global super_read_only=1(5.7新参数)
如果想对拥有super权限用户只读,使用super_read_only,开启该参数后,read_only会自动开启。
6.3 主从延迟问题
6.3.1.从库同步延迟的现象
show slave status显示参数Seconds_Behind_Master不为0,这个数值可能会很大
show slave status显示参数Relay_Master_Log_File和Master_Log_File显示bin-log的编号相差很大,说明bin-log在从库上没有及时同步,所以近期执行的bin-log和当前IO线程所读的bin-log相差很大
MySQL的从库数据目录下存在大量mysql-relay-log日志,该日志同步完成之后就会被系统自动删除,存在大量日志,说明主从同步延迟很厉害
6.3.2.产生原因
当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能承受的范围,那么延时就产生了,当然还有就是可能与slave的大型query语句产生了锁等待。
首要原因:数据库在业务上读写压力太大,CPU计算负荷大,网卡负荷大,硬盘随机IO太高
次要原因:读写binlog带来的性能影响,网络传输延迟。
6.3.3.解决方案
更换从库更快的硬盘
网络,网卡,更换带宽更大的网卡
mysql考虑 从库作为备份数据库来说
增加从库的innodb_buffer_pool_size,可以缓存更多数据防止由于转换造成的IO压力
增加innodb_log_file_size和innodb_log_files_in_group,减少buffer落盘
修改参数innodb_flush_method,提高写入性能(SSD强烈推荐使用)
从库binlog关闭(如果可以) log_slave_updates关闭
修改innodb_flush_log_at_trx_commit为0或者2
修改master_info_repository和relay_log_info_repository为TABLE,防止直接落盘压力